Recognition: unknown
WebXSkill: Skill Learning for Autonomous Web Agents
Pith reviewed 2026-05-10 14:37 UTC · model grok-4.3
The pith
Web agents improve on long tasks when skills pair executable code with step-by-step natural language explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
WebXSkill extracts reusable action subsequences from synthetic agent trajectories, abstracts them into parameterized skills that each contain both an executable program and step-level natural language descriptions, indexes the skills in a URL-based graph for context-aware retrieval, and deploys them through a grounded mode for direct execution or a guided mode in which the agent follows the natural language steps with its own planner. This formulation closes the grounding gap between opaque code skills and non-executable text skills.
What carries the argument
executable skills that pair a parameterized action program with step-level natural language guidance
If this is right
- Agents can run multi-step web workflows automatically while still accessing step descriptions for recovery from errors.
- Skills learned on one site can be retrieved and adapted on other sites that share similar URL structures.
- The two deployment modes let the same skill library support both fully automatic runs and cases where the agent needs to interleave its own planning.
- Performance gains on long-horizon tasks follow directly from having skills that are both executable and inspectable.
Where Pith is reading between the lines
- The same mining-plus-graph approach could be tested on mobile-app agents if synthetic trajectories are available for those environments.
- Over repeated use the URL graph might allow skills to transfer across related websites, such as different shopping or booking platforms, without retraining.
- Collecting more real user trajectories could enlarge the skill library and reduce reliance on synthetic data.
Load-bearing premise
Useful reusable skills can be mined from generated example paths and retrieved by website address without creating extra errors or slowdowns.
What would settle it
Measure task success on a fresh set of web workflows where the mined skills have no matching subsequences; if success rates remain unchanged from the plain baseline, the contribution of the extracted skills is not supported.
Figures



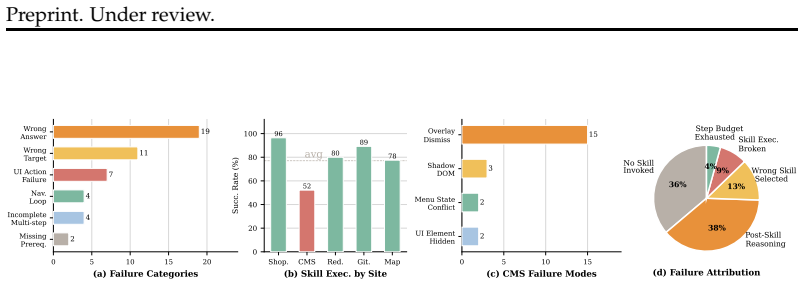

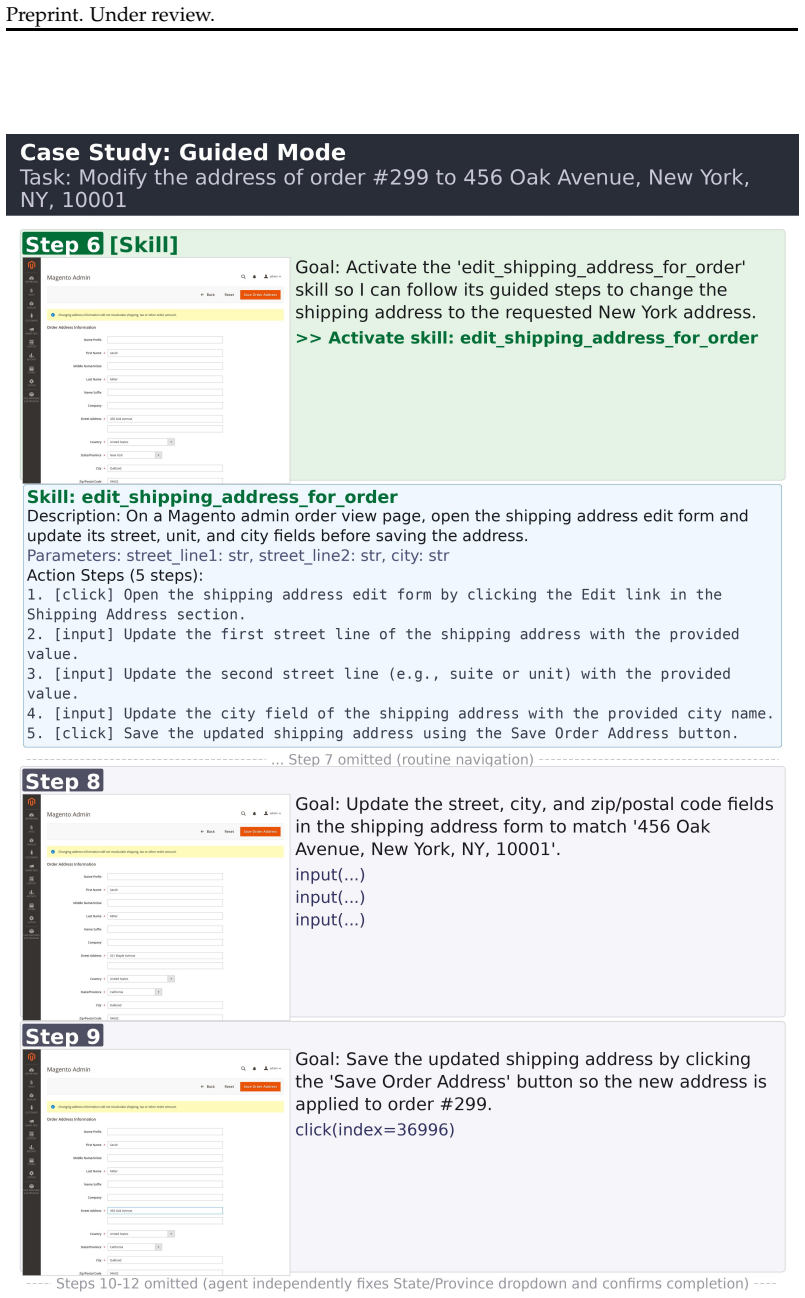
read the original abstract
Autonomous web agents powered by large language models (LLMs) have shown promise in completing complex browser tasks, yet they still struggle with long-horizon workflows. A key bottleneck is the grounding gap in existing skill formulations: textual workflow skills provide natural language guidance but cannot be directly executed, while code-based skills are executable but opaque to the agent, offering no step-level understanding for error recovery or adaptation. We introduce WebXSkill, a framework that bridges this gap with executable skills, each pairing a parameterized action program with step-level natural language guidance, enabling both direct execution and agent-driven adaptation. WebXSkill operates in three stages: skill extraction mines reusable action subsequences from readily available synthetic agent trajectories and abstracts them into parameterized skills, skill organization indexes skills into a URL-based graph for context-aware retrieval, and skill deployment exposes two complementary modes, grounded mode for fully automated multi-step execution and guided mode where skills serve as step-by-step instructions that the agent follows with its native planning. On WebArena and WebVoyager, WebXSkill improves task success rate by up to 9.8 and 12.9 points over the baseline, respectively, demonstrating the effectiveness of executable skills for web agents. The code is publicly available at https://github.com/aiming-lab/WebXSkill.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WebXSkill, a framework for LLM-powered web agents that learns executable skills by extracting parameterized action programs paired with step-level natural language guidance from synthetic trajectories. Skills are indexed in a URL-based graph for context-aware retrieval and deployed via grounded mode (direct multi-step execution) or guided mode (step-by-step instructions for the agent's native planner). Experiments on WebArena and WebVoyager report task success rate gains of up to 9.8 and 12.9 points over baselines, with public code released.
Significance. If the gains can be attributed to the executable skill formulation (parameterized programs + NL guidance) rather than unisolated implementation choices, the work would address a genuine grounding gap in web agents and support better long-horizon performance and adaptation. The public code release is a clear strength that enables reproducibility.
major comments (3)
- [Abstract / Experiments] Abstract and experimental results: The headline improvements (up to 9.8 points on WebArena, 12.9 on WebVoyager) are presented as direct evidence of the skill formulation's effectiveness, yet the manuscript provides no ablation isolating parameterization, no comparison to non-parameterized skill baselines, and no error analysis or variance reporting. This makes attribution to the core contribution (executable skills mined from trajectories) uncertain and load-bearing for the central claim.
- [Skill Extraction] Skill extraction stage: The claim that reusable parameterized skills are reliably mined from synthetic agent trajectories requires evidence that the abstraction step produces programs that transfer to new tasks beyond what the baseline LLM planner can already achieve via native tool use. If trajectories originate from the baseline agent, the mined skills risk simply replaying existing patterns, undermining the reported gains.
- [Skill Organization / Skill Deployment] Skill organization and deployment: The URL-based graph is presented as enabling context-aware retrieval without discussion of failure modes on dynamic or unseen URLs, retrieval latency overhead, or how the two deployment modes (grounded vs. guided) are chosen per task. These are central to practical effectiveness but unaddressed in the results.
minor comments (2)
- The description of the three stages would benefit from a concrete worked example showing an input trajectory subsequence, the resulting parameterized skill, and its use in both grounded and guided modes.
- Notation for skill parameterization and the graph indexing could be clarified with a small diagram or pseudocode to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and commit to revisions that strengthen the attribution of results and clarify practical aspects of the framework.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental results: The headline improvements (up to 9.8 points on WebArena, 12.9 on WebVoyager) are presented as direct evidence of the skill formulation's effectiveness, yet the manuscript provides no ablation isolating parameterization, no comparison to non-parameterized skill baselines, and no error analysis or variance reporting. This makes attribution to the core contribution (executable skills mined from trajectories) uncertain and load-bearing for the central claim.
Authors: We acknowledge that the current experiments compare the full WebXSkill framework against the baseline LLM planner without isolating the contribution of parameterization or including variance/error analysis. In the revised manuscript we will add an ablation study contrasting parameterized executable skills against non-parameterized skill baselines, report mean success rates with standard deviations over multiple runs, and include a concise error analysis in the appendix to better support attribution to the executable skill formulation. revision: yes
-
Referee: [Skill Extraction] Skill extraction stage: The claim that reusable parameterized skills are reliably mined from synthetic agent trajectories requires evidence that the abstraction step produces programs that transfer to new tasks beyond what the baseline LLM planner can already achieve via native tool use. If trajectories originate from the baseline agent, the mined skills risk simply replaying existing patterns, undermining the reported gains.
Authors: The synthetic trajectories are generated by the baseline agent, as described in Section 3.1. The extraction step abstracts action subsequences into parameterized programs paired with step-level natural language guidance, which supports reuse via parameter instantiation on novel tasks. To address the replay concern, the revised version will include additional transfer experiments on tasks that require parameter values or combinations absent from the original trajectories. revision: yes
-
Referee: [Skill Organization / Skill Deployment] Skill organization and deployment: The URL-based graph is presented as enabling context-aware retrieval without discussion of failure modes on dynamic or unseen URLs, retrieval latency overhead, or how the two deployment modes (grounded vs. guided) are chosen per task. These are central to practical effectiveness but unaddressed in the results.
Authors: We will expand the manuscript to discuss failure modes of the URL graph on dynamic or unseen URLs (e.g., retrieval mismatches), report retrieval latency overhead in the experimental section, and clarify the per-task selection logic between grounded mode (direct multi-step execution) and guided mode (step-by-step instructions for the native planner). revision: yes
Circularity Check
No circularity: empirical framework evaluated on external benchmarks with direct measurements
full rationale
The paper presents WebXSkill as a three-stage framework (skill extraction from synthetic trajectories, URL-graph organization, and dual-mode deployment) whose central claims are improvements in task success rates on WebArena and WebVoyager. These are reported as direct empirical measurements rather than outputs of any internal equations, fitted parameters, or self-referential derivations. No mathematical models, uniqueness theorems, or ansatzes appear in the provided text that could reduce to the inputs by construction. The work is self-contained against external benchmarks and does not rely on load-bearing self-citations or renaming of known results. This is the expected outcome for an applied systems paper whose value rests on reproducible benchmark deltas.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can follow step-level natural language guidance to adapt or recover during skill execution
invented entities (1)
-
WebXSkill executable skill
no independent evidence
Forward citations
Cited by 3 Pith papers
-
From Context to Skills: Can Language Models Learn from Context Skillfully?
Ctx2Skill lets language models autonomously evolve context-specific skills via multi-agent self-play, improving performance on context learning tasks without human supervision.
-
SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents
SkillRet benchmark shows fine-tuned retrievers improve NDCG@10 by 13+ points over prior models on large-scale skill retrieval for LLM agents.
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes active external skills in agentic RL via leave-one-skill-out marginal contribution estimates and three lifecycle operations, outperforming baselines by 7.1% on ALFWorld and SearchQA while sh...
Reference graph
Works this paper leans on
-
[1]
Same user goal: An existing skill achieves the same outcome
-
[2]
Large semantic overlap: >=70% overlapping action steps
-
[3]
[...] ## Existing Skill Library {existing_skills_section} ## Trajectory {trajectory_text} ## Your Task
Differ only in final step(s). [...] ## Existing Skill Library {existing_skills_section} ## Trajectory {trajectory_text} ## Your Task
-
[4]
Identify reusable action sequences ({step_threshold}-6 actions) that could be abstracted into skills
-
[5]
Skills should be generic (parameterized), atomic (single logical operation), and reusable across different tasks
-
[6]
skip" - Better version in trajectory ->
Check the existing library first. For each candidate skill: - similarity_score > 0.4 -> very likely overlaps - Same user goal -> "skip" - Better version in trajectory -> "update" - No similar existing skill -> "new" ## meta_url Rules - start_url: The EXACT URL from the trajectory - meta_url: A generalized URL pattern - Use * for variable parts: "gitlab/*/...
-
[7]
click - element_ref: REQUIRED
-
[8]
text","clear
input - element_ref: REQUIRED, params: {"text","clear"}
-
[9]
select_dropdown - element_ref: REQUIRED, params: {"text"}
-
[10]
direction
scroll - element_ref: null, params: {"direction","pages"}
-
[11]
send_keys - element_ref: null, params: {"keys"}
-
[12]
url","new_tab
navigate - element_ref: null, params: {"url","new_tab"} [...] ## Important Rules - guidance is REQUIRED for every action step - Use {{param_name}} syntax for parameterized values - Even failed trajectories may contain useful action sequences Table 8: Skill extraction prompt (2/2): output JSON format, action types reference, and important rules. The LLM ou...
-
[13]
Read the step-by-step guidance carefully
-
[14]
Observe the page to identify the elements described
-
[15]
Execute each step using your browser actions
-
[16]
If a step fails, adapt and continue
-
[17]
Call clear_skill() when done
-
[18]
Table 12: Guided mode system prompt appended to the agent, explaining how to activate and follow skill guidance using native browser actions
IMPORTANT: skill is a general guide, not a strict script; use your judgment to adapt as needed. Table 12: Guided mode system prompt appended to the agent, explaining how to activate and follow skill guidance using native browser actions. 18 Preprint. Under review. Guided Mode: Runtime Skill Injection --- Injected into agent's input message each step --- <...
-
[19]
search_products_from_homepage: Perform a product search using the main search box
-
[20]
navigate_to_category: Navigate to a specific product category from the navigation menu
-
[21]
search_products_
sort_search_results: Sort search results by a criterion. [...] </available_skills> --- After calling use_skill("search_products_...") --- <activated_skill_guidance> Skill: "search_products_from_homepage" Description: Perform a product search using the main search box and submit it with the Search button. Follow these steps using your browser actions: Step...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.