Recognition: no theorem link
Rubric-based On-policy Distillation
Pith reviewed 2026-05-11 02:07 UTC · model grok-4.3
The pith
Rubrics induced from teacher-student response contrasts can replace logits for on-policy distillation in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
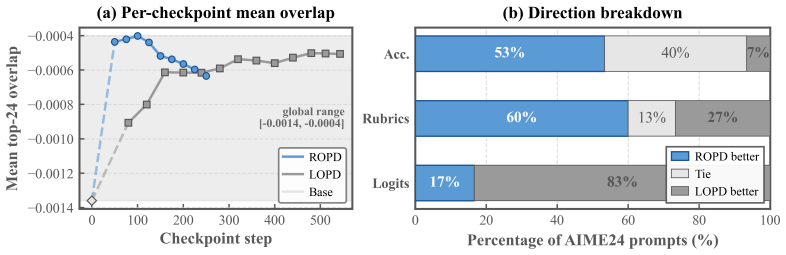
ROPD induces prompt-specific rubrics from contrasts between teacher-generated responses and student rollouts, then applies these rubrics to score the student's on-policy generations for optimization. This rubric-based scoring serves as a scalable substitute for direct teacher logits, enabling effective distillation in black-box settings. Experiments demonstrate that ROPD surpasses advanced logit-based OPD techniques in most tested scenarios while requiring up to ten times fewer samples.
What carries the argument
The ROPD framework, which creates rubrics by contrasting teacher and student outputs for each prompt and then scores student policy rollouts against these rubrics to drive on-policy updates.
If this is right
- Distillation becomes possible from closed-source or proprietary teacher models without internal access.
- Training requires significantly fewer samples, up to a factor of ten improvement in efficiency.
- Provides a unified approach applicable to both open-source and proprietary LLMs.
- Offers a straightforward baseline method that is simple to implement compared to logit-dependent techniques.
Where Pith is reading between the lines
- Rubric-based feedback might generalize to other reinforcement learning from AI feedback setups where direct logit access is unavailable.
- Future work could explore automating rubric generation further or adapting rubrics across related prompts to reduce overhead.
- Testing on a broader set of tasks like reasoning or coding could reveal whether the efficiency gains hold beyond the reported scenarios.
Load-bearing premise
The assumption that contrasts between teacher and student responses yield rubrics that supply feedback as useful or better than the teacher's raw probability distributions for guiding student improvements.
What would settle it
Running ROPD head-to-head against logit-based OPD on the same benchmarks and finding that it matches or exceeds performance only when using equivalent or more samples, or underperforms in most cases, would indicate the rubric approach does not deliver the claimed advantages.
Figures




read the original abstract
On-policy distillation (OPD) is a powerful paradigm for model alignment, yet its reliance on teacher logits restricts its application to white-box scenarios. We contend that structured semantic rubrics can serve as a scalable alternative to teacher logits, enabling OPD using only teacher-generated responses. To prove it, we introduce ROPD, a simple yet foundational framework for rubric-based OPD. Specifically, ROPD induces prompt-specific rubrics from teacher-student contrasts, and then utilizes these rubrics to score the student rollouts for on-policy optimization. Empirically, ROPD outperforms the advanced logit-based OPD methods across most scenarios, and achieving up to a 10x gain in sample efficiency. These results position rubric-based OPD as a flexible, black-box-compatible alternative to the prevailing logit-based OPD, offering a simple yet strong baseline for scalable distillation across proprietary and open-source LLMs. Code is available at https://github.com/Peregrine123/ROPD_official.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ROPD, a framework for rubric-based on-policy distillation (OPD) that induces prompt-specific structured semantic rubrics from teacher-student response contrasts and uses them to score student rollouts for on-policy optimization. This enables OPD without access to teacher logits, positioning it as a black-box alternative. The central empirical claim is that ROPD outperforms advanced logit-based OPD methods across most scenarios while achieving up to 10x gains in sample efficiency.
Significance. If the results hold under rigorous validation, ROPD could broaden on-policy distillation to proprietary LLMs by replacing logit access with rubric-based rewards, offering a scalable baseline for alignment. The availability of code at the provided GitHub link is a positive step toward reproducibility, though the absence of detailed experimental protocols in the abstract limits immediate assessment of the claimed efficiency gains.
major comments (3)
- [Abstract] Abstract: The central claims of outperformance over logit-based OPD and up to 10x sample efficiency gains lack any supporting details on datasets, evaluation metrics, baselines, number of runs, or statistical significance, rendering it impossible to evaluate whether the results support the claims or if the rubric scoring preserves sufficient ranking information relative to logits.
- [Abstract] The method description states that rubrics are induced from teacher-student contrasts and then used to score rollouts, but provides no formal definition of the rubric construction process, scoring function, or how it approximates the teacher policy's preference ordering; this is load-bearing because the 10x efficiency claim requires the rubric rewards to be at least as informative as full logit distributions for stable policy gradients.
- [Abstract] No ablation studies or analysis of rubric quality across training stages are mentioned, which is critical given that early-training contrasts may be dominated by gross errors while later stages risk overfitting to student-specific mistakes rather than general teacher preferences.
minor comments (2)
- [Abstract] The abstract refers to 'structured semantic rubrics' without clarifying their format (e.g., bullet points, criteria lists) or how they are elicited from the teacher.
- [Abstract] The GitHub link is provided but the manuscript does not indicate whether it includes the exact rubric induction code, experimental configurations, or seeds needed for reproduction.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and have revised the abstract to provide greater clarity on our claims, method, and supporting analyses while respecting length constraints.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of outperformance over logit-based OPD and up to 10x sample efficiency gains lack any supporting details on datasets, evaluation metrics, baselines, number of runs, or statistical significance, rendering it impossible to evaluate whether the results support the claims or if the rubric scoring preserves sufficient ranking information relative to logits.
Authors: The abstract serves as a high-level summary; full details on datasets, metrics, baselines, multiple runs with statistical significance testing, and the comparative informativeness of rubric rewards versus logits appear in the Experiments section. We have revised the abstract to include brief references to the primary evaluation settings and the consistent gains observed across runs. revision: partial
-
Referee: [Abstract] The method description states that rubrics are induced from teacher-student contrasts and then used to score rollouts, but provides no formal definition of the rubric construction process, scoring function, or how it approximates the teacher policy's preference ordering; this is load-bearing because the 10x efficiency claim requires the rubric rewards to be at least as informative as full logit distributions for stable policy gradients.
Authors: A complete formalization of rubric induction from contrasts, the scoring function, and its approximation of teacher preferences is given in Section 3. We have added a concise formal statement to the abstract clarifying how rubric-based rewards enable stable on-policy gradients without logit access. revision: yes
-
Referee: [Abstract] No ablation studies or analysis of rubric quality across training stages are mentioned, which is critical given that early-training contrasts may be dominated by gross errors while later stages risk overfitting to student-specific mistakes rather than general teacher preferences.
Authors: Ablation studies and rubric-quality analyses across training stages, including checks against early-stage noise and later-stage overfitting, are reported in the Experiments section and appendix. We have added a short statement to the abstract noting the observed robustness of rubric rewards throughout training. revision: partial
Circularity Check
No significant circularity; framework and claims are empirically grounded without self-referential reduction
full rationale
The paper proposes ROPD as a new framework that induces prompt-specific rubrics from teacher-student response contrasts and applies them to score student rollouts for on-policy optimization. This is presented as an alternative to logit-based methods, with central claims (outperformance and up to 10x sample efficiency) resting on empirical results across scenarios rather than any derivation that reduces to fitted inputs, self-definitions, or self-citation chains. No equations or steps in the abstract or description equate predictions to inputs by construction, and no load-bearing self-citations or ansatzes are invoked. The approach is self-contained, with code released for independent verification.
Axiom & Free-Parameter Ledger
invented entities (1)
-
structured semantic rubrics
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on capable teachers followed by dense distillation to students beats direct GRPO on students for verifiable math reasoning.
-
Beyond GRPO and On-Policy Distillation: An Empirical Sparse-to-Dense Reward Principle for Language-Model Post-Training
Sparse RL on a strong teacher followed by dense distillation to the student outperforms direct GRPO on the student for math tasks, with a forward-KL + OPD bridge enabling further gains.
Reference graph
Works this paper leans on
-
[1]
Aime 2024: American invitational mathematics examination, 2024
MAA. Aime 2024: American invitational mathematics examination, 2024
work page 2024
-
[2]
Aime 2025: American invitational mathematics examination, 2025
MAA. Aime 2025: American invitational mathematics examination, 2025
work page 2025
-
[3]
Hmmt 2025: Harvard-mit mathematics tournament, 2025
HMMT. Hmmt 2025: Harvard-mit mathematics tournament, 2025
work page 2025
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. In International Conference on Learning Representations, 2024
work page 2024
-
[7]
On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025
Kevin Lu and Thinking Machines Lab. On-policy distillation.Thinking Machines Lab: Connec- tionism, 2025
work page 2025
-
[8]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, 2024
work page 2024
-
[9]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780, 2026
work page internal anchor Pith review arXiv 2026
-
[10]
Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
DeepSeek-AI. Deepseek-v4: Towards highly efficient million-token context intelligence, 2026
work page 2026
-
[11]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
HealthBench: Evaluating Large Language Models Towards Improved Human Health
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, and Joaquin Quiñonero- Candela. Healthbench: Evaluating large language models towards improved human health. arXiv preprint arXiv:2505.08775, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Gemma Team, Google DeepMind. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
OpenAI. Introducing gpt-5.2. https://openai.com/index/introducing-gpt-5-2/ ,
-
[16]
Accessed: 2026-05-06
work page 2026
-
[17]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy dis- tillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models. arXiv preprint arXiv:2604.00626, 2026. 10
work page internal anchor Pith review arXiv 2026
-
[20]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Ovd: On-policy verbal distillation.arXiv preprint arXiv:2601.21968, 2026
Jing Xiong, Hui Shen, Shansan Gong, Yuxin Cheng, Jianghan Shen, Chaofan Tao, Haochen Tan, Haoli Bai, Lifeng Shang, and Ngai Wong. Ovd: On-policy verbal distillation.arXiv preprint arXiv:2601.21968, 2026
-
[22]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643, 2026
-
[23]
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learn- ing beyond teacher: Generalized on-policy distillation with reward extrapolation.CoRR, abs/2602.12125, 2026
-
[24]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models. arXiv preprint arXiv:2603.07079, 2026
-
[26]
Dongxu Zhang, Zhichao Yang, Sepehr Janghorbani, Jun Han, Andrew Ressler II, Qian Qian, Gregory D Lyng, Sanjit Singh Batra, and Robert E Tillman. Fast and effective on-policy distillation from reasoning prefixes.arXiv preprint arXiv:2602.15260, 2026
-
[27]
Yecheng Wu, Song Han, and Hai Cai. Lightning opd: Efficient post-training for large reasoning models with offline on-policy distillation.arXiv preprint arXiv:2604.13010, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
PACED: Distillation and On-Policy Self-Distillation at the Frontier of Student Competence
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, and Zhipeng Wang. Paced: Distillation and on- policy self-distillation at the frontier of student competence.arXiv preprint arXiv:2603.11178, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
SCOPE: Signal-Calibrated On-Policy Distillation Enhancement with Dual-Path Adaptive Weighting
Binbin Zheng, Xing Ma, Yiheng Liang, Jingqing Ruan, Xiaoliang Fu, Kepeng Lin, Benchang Zhu, Ke Zeng, and Xunliang Cai. Scope: Signal-calibrated on-policy distillation enhancement with dual-path adaptive weighting.arXiv preprint arXiv:2604.10688, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
A dual-space framework for general knowledge distillation of large language models
Xue Zhang, Songming Zhang, Yunlong Liang, Fandong Meng, Yufeng Chen, Jinan Xu, and Jie Zhou. A dual-space framework for general knowledge distillation of large language models. arXiv preprint arXiv:2504.11426, 2025
-
[31]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Jiacai Liu, Zhuo Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Aasheesh Singh, Vishal Vaddina, and Dagnachew Birru. Orpo-distill: Mixed-policy preference optimization for cross-architecture llm distillation.arXiv preprint arXiv:2509.25100, 2025
-
[33]
Reinforcement Learning-based Knowledge Distillation with LLM-as-a-Judge
Yiyang Shen, Lifu Tu, and Weiran Wang. Reinforcement learning-based knowledge distillation with llm-as-a-judge.arXiv preprint arXiv:2604.02621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment.arXiv preprint arXiv:2510.07743, 2025
-
[35]
Reinforcement learning with rubric anchors
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, Xijun Gu, Peiyi Tu, Jiaxin Liu, Wenyu Chen, Yuzhuo Fu, Zhiting Fan, Yanmei Gu, Yuanyuan Wang, Zhengkai Yang, Jianguo Li, and Junbo Zhao. Reinforcement learning with rubric anchors.arXiv preprint arXiv:2508.12790, 2025. 11
-
[36]
Rulin Shao, Akari Asai, Shannon Zejiang Shen, Hamish Ivison, Varsha Kishore, Jingming Zhuo, Xinran Zhao, Molly Park, Samuel G. Finlayson, David Sontag, Tyler Murray, Sewon Min, Pradeep Dasigi, Luca Soldaini, Faeze Brahman, Wen-tau Yih, Tongshuang Wu, Luke Zettlemoyer, Yoon Kim, Hannaneh Hajishirzi, and Pang Wei Koh. Dr tulu: Reinforcement learning with ev...
-
[37]
Yifei Xu, Guilherme Potje, Shivam Shandilya, Tiancheng Yuan, Leonardo de Oliveira Nunes, Rakshanda Agarwal, Saeid Asgari, Adam Atkinson, Emre Kıcıman, Songwu Lu, Ranveer Chandra, and Tusher Chakraborty. Sibylsense: Adaptive rubric learning via memory tuning and adversarial probing.arXiv preprint arXiv:2602.20751, 2026
-
[38]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[39]
Criterion 7: Uses proof by induction – 2/4 teachers support, 2/4 use direct computation
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 1317–1327, 2016. 12 Appendix Appendix Overview §A Related Work (Complete Version) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 §...
work page 2016
-
[40]
Specific and Measurable: Clearly define a concrete answer-quality merit
-
[41]
Binary Evaluable: A verifier should be able to mark it True or False for one response alone
-
[42]
Instructionally Useful: It should point to a meaningful improvement direction for the students
-
[43]
Alternative-Method Safe: A different valid approach that exhibits the same merit should still be rewarded. 17
-
[44]
Distinguishing: Prefer merits that teachers consistently show and students systematically lack
-
[45]
# Required Category Taxonomy Your rubric should be guided by the following three categories
Black-Box Compatible: Prefer criteria that evaluate observable answer behavior and response quality. # Required Category Taxonomy Your rubric should be guided by the following three categories. Use the ‘category‘ field to assign each criterion to exactly one category
-
[46]
Task Completion Whether the response completes the task and produces the required final answer in the correct form. This includes identifying the target quantity, presenting the answer explicitly, and meeting format requirements
-
[47]
Observable Quality Whether the response demonstrates strong observable correctness signals under black-box evaluation. This includes correct intermediate steps, valid factorization or algebraic manipulation, identification of key constraints (\textit{e.g.}, parity obstructions), and absence of hallucinated claims or guessed answers
-
[48]
Use this category when such qualities are genuinely relevant and improve teacher-student separation
General Reasoning Broad reasoning qualities such as logical coherence, step-by-step derivation flow, planning structure, self-checking behavior, clarity, and focus. Use this category when such qualities are genuinely relevant and improve teacher-student separation. # Category Priorities
-
[49]
Preserve general validity of the rubric for the question
-
[50]
Prioritize Task Completion by default---at least one high-weight criterion should verify that the response answers the requested target and presents it in the required form
-
[51]
Prioritize Observable Quality criteria that directly check correctness of intermediate steps, mathematical manipulations, and domain-specific reasoning (\textit{e.g.}, factorization, constraint identification)
-
[52]
Use General Reasoning when genuinely relevant and it improves teacher-student separation, but avoid rewarding superficial stylistic performance
-
[53]
uses the same method as the teacher(s)
Make the rubric produce actionable learning-direction signals for the student. Most of the total points should come from criteria that are likely satisfied by most teacher responses but not by most student responses. # Additional Design Rules - At least one high-value criterion should check whether the response answers the requested final target. - At lea...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.