Recognition: unknown
ADAPT: Benchmarking Commonsense Planning under Unspecified Affordance Constraints
Pith reviewed 2026-05-10 11:12 UTC · model grok-4.3
The pith
Explicit affordance reasoning lets planners adapt to changing object manipulability in dynamic scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
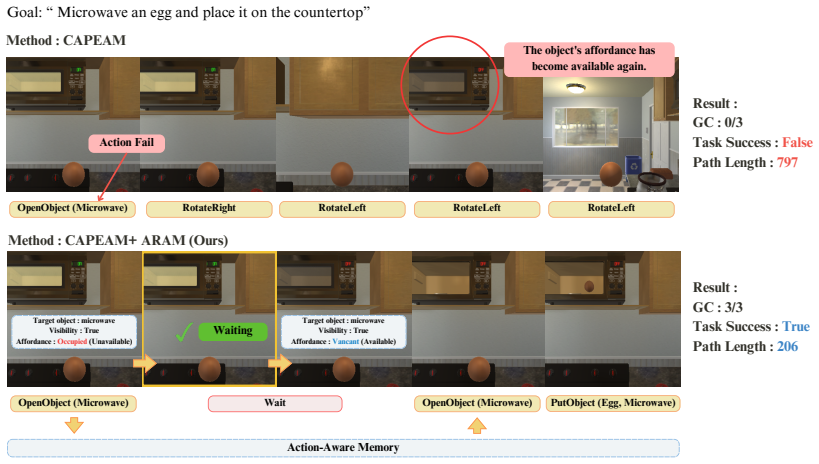
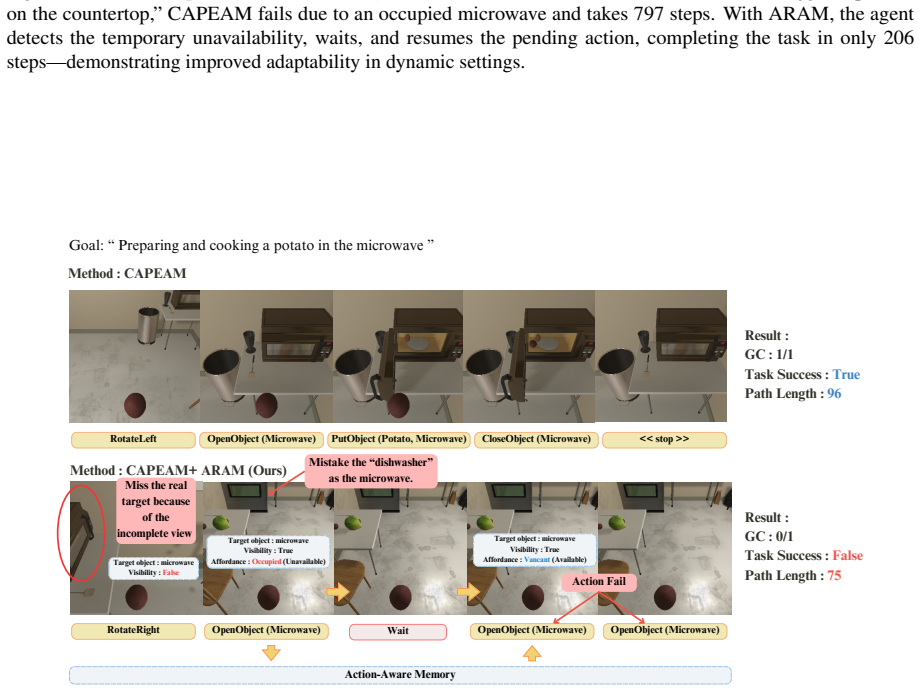
The central claim is that embodied planners improve when given an explicit mechanism to perceive current object states, infer implicit preconditions, and revise actions accordingly; ADAPT supplies this mechanism as a plug-in layer that operates on top of standard planners, and the DynAfford benchmark demonstrates measurable gains in task completion under time-varying, unspecified affordance constraints.
What carries the argument
ADAPT, a plug-and-play module that augments planners with separate affordance inference and adaptation steps using a vision-language backend.
If this is right
- Planners that ignore affordance inference will continue to produce infeasible action sequences when object conditions vary.
- A task-specific fine-tuned vision-language model can serve as a stronger affordance reasoner than an off-the-shelf large language model.
- Agents equipped with ADAPT maintain higher success rates when moved to previously unseen room layouts.
- Benchmark scores on DynAfford correlate with the ability to handle implicit preconditions rather than with raw instruction-following accuracy.
Where Pith is reading between the lines
- The separation of affordance inference from core planning may allow incremental upgrades to existing robotic stacks without full retraining.
- Future simulators could incorporate more continuous state changes (e.g., gradual filling or temperature shifts) to stress-test the inference component further.
- If affordance reasoning proves domain-specific, training separate lightweight adapters for different environments may become standard practice.
Load-bearing premise
The DynAfford tasks and environments are representative enough of real unspecified affordance changes that performance gains will transfer outside the tested simulator settings.
What would settle it
Run the ADAPT-augmented planner and the baseline planner on a physical robot in a kitchen where object states (open/closed, full/empty) are altered between trials without updating the instruction, and measure whether the success-rate gap disappears or reverses.
Figures










read the original abstract
Intelligent embodied agents should not simply follow instructions, as real-world environments often involve unexpected conditions and exceptions. However, existing methods usually focus on directly executing instructions, without considering whether the target objects can actually be manipulated, meaning they fail to assess available affordances. To address this limitation, we introduce DynAfford, a benchmark that evaluates embodied agents in dynamic environments where object affordances may change over time and are not specified in the instruction. DynAfford requires agents to perceive object states, infer implicit preconditions, and adapt their actions accordingly. To enable this capability, we introduce ADAPT, a plug-and-play module that augments existing planners with explicit affordance reasoning. Experiments demonstrate that incorporating ADAPT significantly improves robustness and task success across both seen and unseen environments. We also show that a domain-adapted, LoRA-finetuned vision-language model used as the affordance inference backend outperforms a commercial LLM (GPT-4o), highlighting the importance of task-aligned affordance grounding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DynAfford, a benchmark for embodied agents operating in dynamic environments where object affordances change over time and remain unspecified in the given instructions. It proposes ADAPT, a plug-and-play module that augments existing planners with explicit affordance reasoning, typically backed by a vision-language model. The central claims are that integrating ADAPT yields significant gains in robustness and task success on both seen and unseen environments, and that a domain-adapted LoRA-finetuned VLM outperforms GPT-4o as the affordance inference backend.
Significance. If the benchmark faithfully instantiates implicit, time-varying affordances without spurious cues and the reported gains are statistically robust, the work would provide a useful modular approach to commonsense planning and a dedicated evaluation platform. The emphasis on domain-adapted VLMs for grounding could influence future embodied systems, though the impact depends on generalization beyond the tested environments.
major comments (3)
- [DynAfford benchmark] DynAfford benchmark section: the environment generation process, state-transition rules, object diversity, and frequency of affordance changes are not described in sufficient detail to confirm that implicit preconditions cannot be inferred from visual correlations or limited task templates. This directly affects whether performance deltas can be attributed to ADAPT rather than benchmark artifacts.
- [Experiments] Experiments section: the abstract asserts 'significant improvements' and VLM superiority over GPT-4o, yet no quantitative metrics, baseline planners, statistical tests, error analysis, or breakdown by seen/unseen conditions are referenced. Without these, the central empirical claim cannot be evaluated for soundness.
- [Experiments] Unseen environments definition: the distinction between seen and unseen environments, including how affordance distributions differ, is not specified. This undermines the generalization argument that ADAPT improves robustness beyond training conditions.
minor comments (1)
- The abstract would be strengthened by including one or two key quantitative results (e.g., success rate deltas) to support the stated claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the DynAfford benchmark and experimental presentation. We address each major comment point by point below, clarifying existing content where possible and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [DynAfford benchmark] DynAfford benchmark section: the environment generation process, state-transition rules, object diversity, and frequency of affordance changes are not described in sufficient detail to confirm that implicit preconditions cannot be inferred from visual correlations or limited task templates. This directly affects whether performance deltas can be attributed to ADAPT rather than benchmark artifacts.
Authors: We agree that the current level of detail on benchmark construction leaves room for ambiguity regarding potential artifacts. In the revised manuscript we will expand the DynAfford section with an explicit description of the procedural environment generator, the precise state-transition rules (including time-based and action-triggered affordance updates), quantitative measures of object and scene diversity, and the distribution of affordance-change frequencies. These additions will make it clearer that implicit preconditions cannot be reliably inferred from visual correlations alone or from narrow task templates, thereby supporting attribution of gains to ADAPT. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts 'significant improvements' and VLM superiority over GPT-4o, yet no quantitative metrics, baseline planners, statistical tests, error analysis, or breakdown by seen/unseen conditions are referenced. Without these, the central empirical claim cannot be evaluated for soundness.
Authors: The experiments section already reports quantitative success rates for multiple baseline planners (with and without ADAPT), direct head-to-head results between the LoRA-finetuned VLM and GPT-4o, and separate performance figures for seen versus unseen environments. We acknowledge, however, that the prose could more explicitly reference these numbers, tables, and figures, and that statistical tests and expanded error analysis would improve evaluability. We will revise the text to add inline citations to all quantitative results, include significance testing, and enlarge the error analysis and seen/unseen breakdown. revision: partial
-
Referee: [Experiments] Unseen environments definition: the distinction between seen and unseen environments, including how affordance distributions differ, is not specified. This undermines the generalization argument that ADAPT improves robustness beyond training conditions.
Authors: Seen environments reuse affordance configurations and object sets drawn from the same distribution used during planner and VLM development, whereas unseen environments employ novel object combinations and affordance-change schedules that were never observed in training. We will add an explicit paragraph in the revised experiments section defining these two regimes and describing the sampling procedures that ensure the affordance distributions differ, thereby reinforcing the generalization claims. revision: yes
Circularity Check
No circularity: empirical benchmark and module evaluated via independent task metrics
full rationale
The paper introduces DynAfford as a new benchmark for dynamic affordance constraints and ADAPT as a plug-and-play module, with central claims resting on experimental task-success and robustness deltas across seen/unseen environments. No equations, parameter fits, or self-referential definitions appear in the provided text; reported gains are measured outcomes of planner augmentations rather than quantities defined in terms of themselves or prior self-citations. The evaluation chain is self-contained against the benchmark's stated task templates and state transitions, with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
VLN-NF: Feasibility-Aware Vision-and-Language Navigation with False-Premise Instructions
VLN-NF benchmark adds false-premise instructions to VLN and ROAM hybrid agent improves REV-SPL by combining room navigation with evidence-gathering exploration.
Reference graph
Works this paper leans on
-
[1]
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, and 1 others. 2022. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691
work page internal anchor Pith review arXiv 2022
-
[2]
Valts Blukis, Chris Paxton, Dieter Fox, Animesh Garg, and Yoav Artzi. 2022. A persistent spatial semantic representation for high-level natural language instruction execution. In Conference on Robot Learning, pages 706--717. PMLR
2022
-
[3]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[4]
Ching-Yao Chuang, Jiaman Li, Antonio Torralba, and Sanja Fidler. 2018. Learning to act properly: Predicting and explaining affordances from images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 975--983
2018
-
[5]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171--4186
2019
-
[6]
J \"o rg Hoffmann and Bernhard Nebel. 2001. The ff planning system: Fast plan generation through heuristic search. Journal of Artificial Intelligence Research, 14:253--302
2001
-
[7]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. ICLR, 1(2):3
2022
-
[8]
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, and 1 others. 2022. Inner monologue: Embodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608
work page internal anchor Pith review arXiv 2022
-
[9]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Byeonghwi Kim, Jinyeon Kim, Yuyeong Kim, Cheolhong Min, and Jonghyun Choi. 2023. Context-aware planning and environment-aware memory for instruction following embodied agents. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10936--10946
2023
-
[11]
Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, and 1 others. 2017. Ai2-thor: An interactive 3d environment for visual ai. arXiv preprint arXiv:1712.05474
work page internal anchor Pith review arXiv 2017
-
[12]
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart \' n-Mart \' n, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, and 1 others. 2023. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. In Conference on Robot Learning, pages 80--93. PMLR
2023
-
[13]
Xiaotian Liu, Ali Pesaranghader, Jaehong Kim, Tanmana Sadhu, Hyejeong Jeon, and Scott Sanner. 2025. Activevoo: Value of observation guided active knowledge acquisition for open-world embodied lifted regression planning. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[14]
Lajanugen Logeswaran, Sungryull Sohn, Yiwei Lyu, Anthony Liu, Dong-Ki Kim, Dongsub Shim, Moontae Lee, and Honglak Lee. 2024. https://doi.org/10.18653/v1/2024.naacl-long.317 Code models are zero-shot precondition reasoners . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language ...
- [15]
-
[16]
Alexander Pashevich, Cordelia Schmid, and Chen Sun. 2021. Episodic transformer for vision-and-language navigation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15942--15952
2021
-
[17]
Xavier Puig, Kevin Ra, Marko Boben, Jiaman Li, Tingwu Wang, Sanja Fidler, and Antonio Torralba. 2018. Virtualhome: Simulating household activities via programs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 8494--8502
2018
-
[18]
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740--10749
2020
-
[19]
Kunal Pratap Singh, Suvaansh Bhambri, Byeonghwi Kim, Roozbeh Mottaghi, and Jonghyun Choi. 2021. Factorizing perception and policy for interactive instruction following. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1888--1897
2021
-
[20]
Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M Sadler, Wei-Lun Chao, and Yu Su. 2023. Llm-planner: Few-shot grounded planning for embodied agents with large language models. In Proceedings of the IEEE/CVF international conference on computer vision, pages 2998--3009
2023
-
[21]
Hung-Ting Su, Ting-Jun Wang, Jia-Fong Yeh, Min Sun, and Winston H Hsu. 2026. Vln-nf: Feasibility-aware vision-and-language navigation with false-premise instructions. arXiv preprint arXiv:2604.10533
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, and 1 others. 2020. Sapien: A simulated part-based interactive environment. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097--11107
2020
- [23]
-
[24]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[25]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.