Recognition: unknown
From Black-Box Confidence to Measurable Trust in Clinical AI: A Framework for Evidence, Supervision, and Staged Autonomy
Pith reviewed 2026-05-07 13:14 UTC · model grok-4.3
The pith
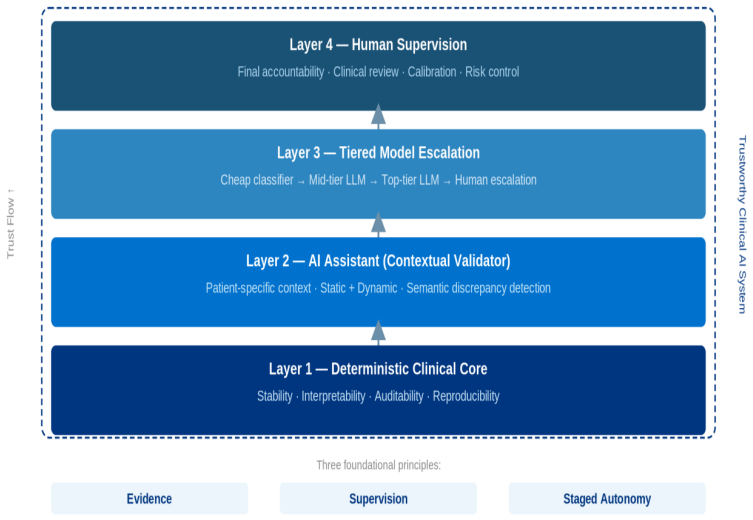
Trustworthy clinical AI emerges as a system architecture outcome embedding evidence trails, human oversight, tiered escalation, and graduated action rights rather than a model property.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Trust in clinical artificial intelligence cannot be reduced to model accuracy, fluency of generation, or overall positive user impression. In medicine, trust must be engineered as a measurable system property grounded in evidence, supervision, and operational boundaries of AI autonomy. The proposed framework combines a deterministic core, a patient-specific AI assistant for contextual validation, a multi-tier model escalation mechanism, and a human supervision layer for verification, escalation, and risk control. Trustworthy clinical AI emerges not as a property of an individual model, but as an architectural outcome of a system into which evidence trails, human oversight, tiered escalation,
What carries the argument
The framework of evidence, supervision, and staged autonomy implemented through a deterministic core, AI assistant, multi-tier escalation, and human supervision layer.
Load-bearing premise
That the integration of deterministic core, AI assistant, multi-tier escalation, and human supervision can be practically implemented at scale while preserving clinical utility and without introducing new failure modes or excessive overhead.
What would settle it
A hospital pilot where the added supervision and escalation layers increase missed diagnoses or decision delays compared to existing methods would show the architecture fails to deliver measurable trust gains.
Figures





read the original abstract
Trust in clinical artificial intelligence (AI) cannot be reduced to model accuracy, fluency of generation, or overall positive user impression. In medicine, trust must be engineered as a measurable system property grounded in evidence, supervision, and operational boundaries of AI autonomy. This article proposes a practical framework for trustworthy clinical AI built around three principles: evidence, supervision, and staged autonomy. Rather than replacing deterministic clinical logic wholesale with end-to-end black-box models, the proposed approach combines a deterministic core, a patient-specific AI assistant for contextual validation, a multi-tier model escalation mechanism, and a human supervision layer for verification, escalation, and risk control. We demonstrate that trust also depends on selective verification of clinically critical findings, bounded clinical context, disciplined prompt architecture, and careful evaluation on realistic cases. Classifier-driven modular prompting is examined as an incremental path to scaling clinical depth without sacrificing prompt performance and without waiting for complete rule-based coverage. To operationalize trust, a set of trust metrics is proposed, built on metrological principles -- measurement uncertainty, calibration, traceability -- enabling quantitative rather than subjective assessment of each architectural layer. In this perspective, trustworthy clinical AI emerges not as a property of an individual model, but as an architectural outcome of a system into which evidence trails, human oversight, tiered escalation, and graduated action rights are embedded from the outset.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a framework for engineering measurable trust in clinical AI as a system-level property rather than an attribute of individual models. It advocates combining a deterministic core with a patient-specific AI assistant, multi-tier escalation mechanisms, and human supervision layers, grounded in three principles: evidence, supervision, and staged autonomy. Trust is to be quantified via metrological metrics (measurement uncertainty, calibration, traceability) and supported by selective verification, bounded context, disciplined prompting, and classifier-driven modular prompting as a scaling strategy. The central claim is that trustworthy clinical AI emerges as an architectural outcome when evidence trails, oversight, tiered escalation, and graduated action rights are embedded from the outset.
Significance. If the framework can be concretely specified and empirically validated, it would offer a substantive contribution to clinical AI safety by moving beyond post-hoc confidence scores toward architecturally enforced trust. The metrological approach to metrics and the hybrid deterministic-AI design provide a principled alternative to purely data-driven systems, with potential to improve regulatory acceptance and clinician adoption in high-stakes domains.
major comments (2)
- [The Proposed Framework] The section describing the hybrid architecture (deterministic core + patient-specific AI assistant + multi-tier escalation + human supervision) provides no algorithms, decision thresholds, interaction protocols, or real-time integration mechanisms. This is load-bearing for the central claim that the system can be implemented at clinical scale while preserving utility and avoiding new failure modes.
- [Operationalizing Trust] The trust metrics (uncertainty, calibration, traceability) are defined circularly in terms of the framework's own components (evidence trails, supervision, escalation) with no external benchmarks, independent datasets, or validation studies provided. This directly affects the claim that trust becomes 'measurable' rather than subjective.
minor comments (2)
- [Abstract] The abstract states 'we demonstrate that trust also depends on selective verification...' yet the manuscript offers only conceptual discussion; clarify whether any case studies or illustrative examples constitute the demonstration.
- [Introduction] Terms such as 'staged autonomy' and 'classifier-driven modular prompting' are introduced without initial formal definitions or pointers to related work in clinical decision-support literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review, which highlights important aspects of operationalizing the proposed framework. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript while preserving its perspective nature.
read point-by-point responses
-
Referee: [The Proposed Framework] The section describing the hybrid architecture (deterministic core + patient-specific AI assistant + multi-tier escalation + human supervision) provides no algorithms, decision thresholds, interaction protocols, or real-time integration mechanisms. This is load-bearing for the central claim that the system can be implemented at clinical scale while preserving utility and avoiding new failure modes.
Authors: We agree that the architecture description remains at a high conceptual level in the current draft. The manuscript is positioned as a framework proposal rather than a full systems or implementation paper, which is why detailed algorithms and real-time integration code are not included. To address the concern, we will revise the relevant section to include: (1) pseudocode outlines for the multi-tier escalation logic and human-AI handoff protocols, (2) example decision thresholds tied to clinical risk strata (e.g., low/medium/high uncertainty bands), and (3) a high-level sequence diagram illustrating interaction flows. These additions will make the implementation pathway more concrete without claiming empirical deployment results, which lie beyond the scope of this work. We maintain that the architectural principles themselves provide the necessary foundation for scalable implementation. revision: partial
-
Referee: [Operationalizing Trust] The trust metrics (uncertainty, calibration, traceability) are defined circularly in terms of the framework's own components (evidence trails, supervision, escalation) with no external benchmarks, independent datasets, or validation studies provided. This directly affects the claim that trust becomes 'measurable' rather than subjective.
Authors: The metrics are deliberately derived from metrological standards (measurement uncertainty, calibration, traceability) and then mapped onto the framework components to render them actionable in a clinical system context. We acknowledge that the manuscript does not include external benchmarks, independent datasets, or validation studies, as its contribution is the proposal of the metrics and their architectural grounding rather than their empirical evaluation. In revision, we will add a new subsection under 'Operationalizing Trust' that explicitly discusses validation strategies, including suggested protocols for using held-out clinical datasets to quantify calibration error and traceability chains, along with references to existing AI safety and metrology literature. This will clarify the distinction between the proposed measurement approach and the need for future empirical confirmation. revision: yes
Circularity Check
No circularity: conceptual framework with external metrological grounding
full rationale
The paper advances a high-level architectural proposal for trustworthy clinical AI, defining trust as an emergent system property arising from embedded evidence trails, supervision, and staged autonomy. Trust metrics are explicitly constructed from independent metrological principles (measurement uncertainty, calibration, traceability) rather than from the framework components themselves. No equations, fitted parameters, predictions, or derivations appear that reduce by construction to the paper's own inputs or definitions. The central claim is a design recommendation, not a tautological self-definition or a fitted result renamed as prediction. No load-bearing self-citations or uniqueness theorems are invoked.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Trust in clinical AI can and should be engineered as a measurable system property using metrological principles such as measurement uncertainty, calibration, and traceability.
- ad hoc to paper A hybrid architecture combining deterministic logic, AI contextual validation, and human supervision will produce higher trust than black-box models alone.
invented entities (2)
-
staged autonomy
no independent evidence
-
multi-tier model escalation mechanism
no independent evidence
Forward citations
Cited by 1 Pith paper
-
TRACE: A Metrologically-Grounded Engineering Framework for Trustworthy Agentic AI Systems in Operationally Critical Domains
TRACE is a metrologically-grounded four-layer engineering framework for trustworthy agentic AI that enforces an ML-LLM split, stateful policies, human supervision, and a parsimony metric across critical domains.
Reference graph
Works this paper leans on
-
[1]
Ethics and governance of artificial intelligence for health: WHO 11 guidance
World Health Organization. Ethics and governance of artificial intelligence for health: WHO 11 guidance. Technical report, WHO, Geneva, Switzerland, 2021
2021
-
[2]
Food and Drug Administration
U.S. Food and Drug Administration. Artificial intelligence and machine learning (AI/ML)-enabled medical devices. https: //www.fda.gov/medical-devices/software-medical-device-samd/ artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices ,
-
[3]
Accessed: 9 April 2026
2026
-
[4]
Toward clinical generative AI: Conceptual framework.JMIR AI, 3:e55957, 2024
Nicola Luigi Bragazzi and Sergio Garbarino. Toward clinical generative AI: Conceptual framework.JMIR AI, 3:e55957, 2024
2024
-
[5]
Large language models in cardiovascular prevention: A narrative review and governance framework.Diagnostics, 16(3):390, 2026
João Ferreira Santos and Hugo Dores. Large language models in cardiovascular prevention: A narrative review and governance framework.Diagnostics, 16(3):390, 2026. doi: 10.3390/ diagnostics16030390
2026
-
[6]
Harnessing large language models for clinical information extraction: A systematic literature review.ACM Transactions on Computing for Healthcare, 2025
Tiago Rodrigues and Carla Teixeira Lopes. Harnessing large language models for clinical information extraction: A systematic literature review.ACM Transactions on Computing for Healthcare, 2025
2025
-
[7]
FUTURE-AI: International consensus guideline for trust- worthy and deployable artificial intelligence in healthcare.BMJ, 2025
The FUTURE-AI Consortium. FUTURE-AI: International consensus guideline for trust- worthy and deployable artificial intelligence in healthcare.BMJ, 2025. Consensus guideline
2025
-
[8]
Cecchi, and Pattie Maes
Shruthi Shekar, Pat Pataranutaporn, Chetanya Sarabu, Guillermo A. Cecchi, and Pattie Maes. People overtrust AI-generated medical advice despite low accuracy.NEJM AI, 2(6),
-
[9]
doi: 10.1056/AIoa2300015
-
[10]
Human-in-the-loop interactive report generation for chronic disease adherence.arXiv preprint, 2026
Xiaoyu Zhang et al. Human-in-the-loop interactive report generation for chronic disease adherence.arXiv preprint, 2026
2026
-
[11]
Tiered agentic oversight: A hierarchical multi-agent system for healthcare safety.arXiv preprint, 2025
Youngjun Kim et al. Tiered agentic oversight: A hierarchical multi-agent system for healthcare safety.arXiv preprint, 2025
2025
-
[12]
Jia Li, Z. C. Zhou, Z. C. Wang, and H. Lv. Prioritizing human–AI collaboration in healthcare: The TRIAD framework for trustworthy governance, real-world, and integrated adaptive deployment.Military Medical Research, 12:97, 2026. doi: 10.1186/s40779-026-00684-w. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.