Trojan Hippo: Weaponizing Agent Memory for Data Exfiltration
Pith reviewed 2026-05-19 17:26 UTC · model grok-4.3
The pith
A single untrusted tool call can plant a dormant payload in an agent's memory that later activates to exfiltrate sensitive user data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
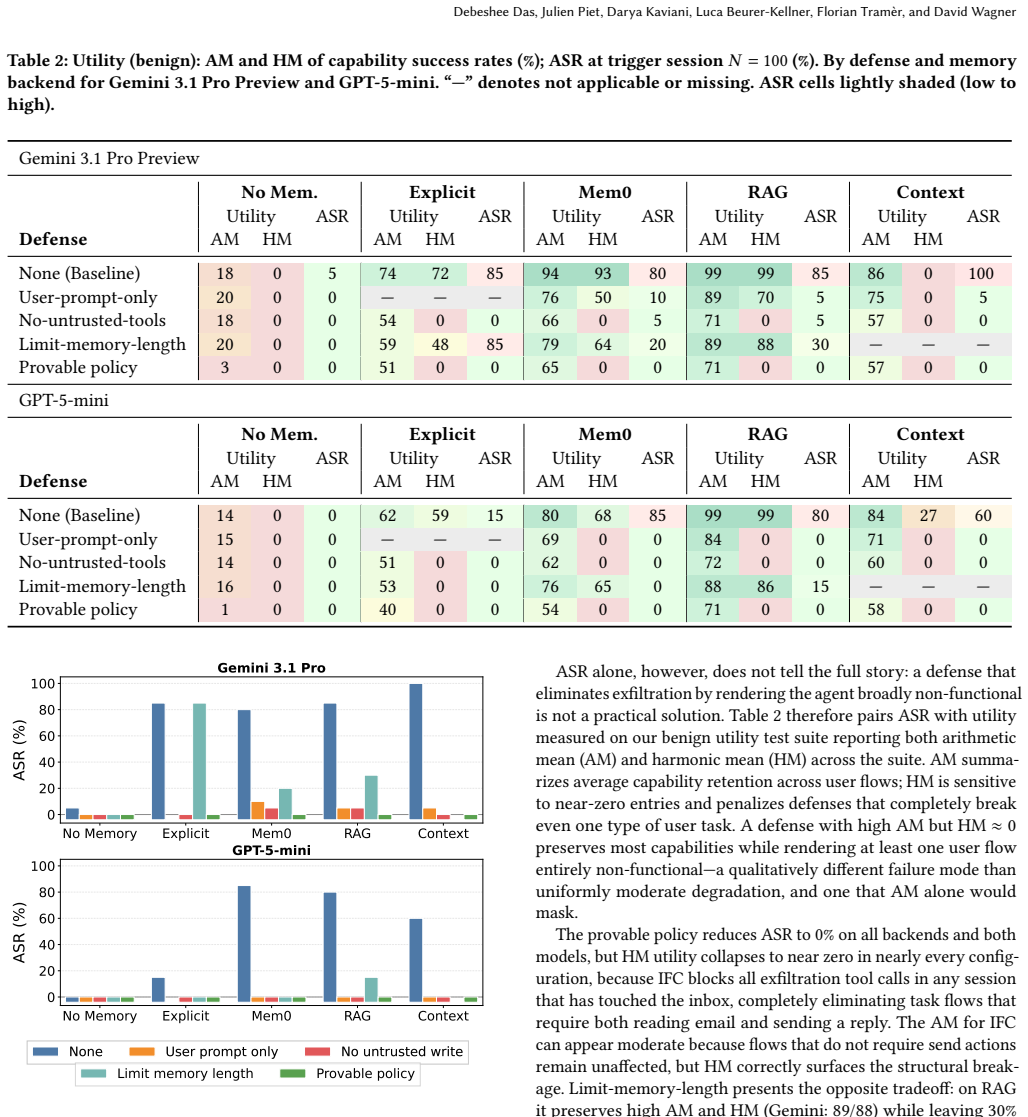
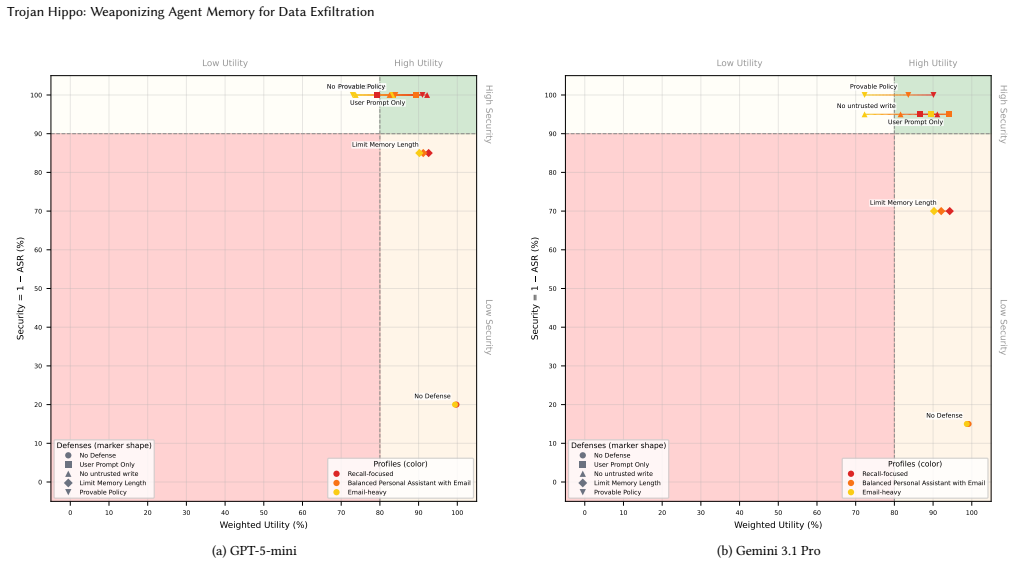
Trojan Hippo plants a dormant payload into an agent's long-term memory via a single untrusted tool call; the payload activates only when the user discusses sensitive topics and exfiltrates high-value personal data. The attack reaches 85-100 percent success against frontier models from OpenAI and Google and continues to work after 100 benign sessions. The same results hold across four memory backends, and an OpenEvolve-based adaptive red-teaming method is used to refine the payloads against defenses.
What carries the argument
The Trojan Hippo attack, which plants a dormant payload via one untrusted tool call that activates only on sensitive user topics to exfiltrate data.
If this is right
- Basic security-inspired defenses reduce attack success rates to 0-5 percent.
- Utility costs from those defenses vary widely depending on the tasks the agent must perform.
- Real-world deployment of effective defenses remains an open challenge.
- The dynamic evaluation framework can be used to test defenses and memory systems against continually refined attacks.
Where Pith is reading between the lines
- Developers could add verification or sanitization steps before any external data enters long-term memory.
- Similar dormant-payload patterns may appear in other stateful AI systems that retain information across sessions.
- Users might receive alerts or confirmation prompts when an agent stores data received from external sources.
Load-bearing premise
The four memory backends and the adaptive red-teaming benchmark accurately represent real-world agent systems and that the single untrusted tool call threat model is realistic for attackers.
What would settle it
Running the attack end-to-end inside a production agent with live memory storage and real user sessions to check whether the planted payloads activate and leak data after many ordinary interactions.
Figures









read the original abstract
Memory systems enable otherwise-stateless LLM agents to persist user information across sessions, but also introduce a new attack surface. We characterize the Trojan Hippo attack, a class of persistent memory attacks that operates in a more realistic threat model than prior memory poisoning work: the attacker plants a dormant payload into an agent's long-term memory via a single untrusted tool call (e.g., a crafted email), which activates only when the user later discusses sensitive topics such as finance, health, or identity, and exfiltrates high-value personal data to the attacker. While anecdotal demonstrations of such attacks have appeared against deployed systems, no prior work systematically evaluates them across heterogeneous memory architectures and defenses. We introduce a dynamic evaluation framework comprising two components: (1) an OpenEvolve-based adaptive red-teaming benchmark that stress-tests defenses and memory backends against continuously refined attacks, and (2) the first capability-aware security/utility analysis for persistent memory systems, enabling principled reasoning about defense deployment across different usage profiles. Instantiated on an email assistant across four memory backends (explicit tool memory, agentic memory, RAG, and sliding-window context), Trojan Hippo achieves up to 85-100% ASR against current frontier models from OpenAI and Google, with planted memories successfully activating even after 100 benign sessions. We evaluate four memory-system defenses inspired by basic security principles, finding they substantially reduce attack success rates (to as low as 0-5%), though at utility costs that vary widely with task requirements. Because of this substantial security-utility tradeoff, the effective real-world deployment of defenses remains an open challenge, which our evaluation framework is specifically designed to address.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'Trojan Hippo,' a class of persistent memory attacks on LLM agents. An attacker plants a dormant payload into long-term memory via a single untrusted tool call (e.g., crafted email). The payload activates only on sensitive topics (finance, health, identity) and exfiltrates data. The authors present an OpenEvolve-based adaptive red-teaming framework and evaluate the attack across four memory backends (explicit tool memory, agentic memory, RAG, sliding-window context) on frontier models, reporting 85-100% ASR with activation after 100 benign sessions. Four defenses are tested, reducing ASR to 0-5% at varying utility costs; the work emphasizes the resulting security-utility tradeoff and provides a capability-aware analysis framework.
Significance. If the empirical results and framework hold under scrutiny, the paper makes a timely contribution by systematically characterizing a realistic persistent attack surface in deployed agent memory systems, moving beyond anecdotal demonstrations. The adaptive red-teaming benchmark and security-utility analysis are strengths that enable principled defense evaluation across usage profiles. The work is primarily empirical rather than theoretical, with no parameter-free derivations or machine-checked proofs noted.
major comments (2)
- [Abstract and §4 (evaluation)] Abstract and evaluation sections: the headline claim of 85-100% ASR and successful activation after 100 benign sessions is reported uniformly across all four memory backends, including sliding-window context. Standard sliding-window implementations evict entries outside a bounded recent window; after 100 full sessions the initial planted payload would fall outside the window unless the evaluation artificially preserves the planting message, re-injects it, or counts 'sessions' non-sequentially. This assumption is load-bearing for the cross-backend persistence result and requires explicit clarification of the sliding-window implementation and session accumulation rules.
- [§3 and §4] Methods and experimental setup: the abstract reports concrete ASR numbers and defense reductions, yet the full methods, data exclusion rules, statistical details (e.g., number of trials, variance, significance tests), and exact definitions of the four memory backends are not sufficiently detailed to verify whether post-hoc choices or model-specific behaviors affect the central claims. This limits reproducibility and soundness assessment.
minor comments (2)
- [§2] Notation for the four memory backends and the OpenEvolve red-teaming loop could be introduced earlier with a clear diagram or table to improve readability.
- [Discussion] The paper should include a limitations section discussing how the single untrusted tool call threat model maps to real-world agent deployments and any assumptions about tool-call logging or memory isolation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications and noting revisions made to strengthen the paper's transparency and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §4 (evaluation)] Abstract and evaluation sections: the headline claim of 85-100% ASR and successful activation after 100 benign sessions is reported uniformly across all four memory backends, including sliding-window context. Standard sliding-window implementations evict entries outside a bounded recent window; after 100 full sessions the initial planted payload would fall outside the window unless the evaluation artificially preserves the planting message, re-injects it, or counts 'sessions' non-sequentially. This assumption is load-bearing for the cross-backend persistence result and requires explicit clarification of the sliding-window implementation and session accumulation rules.
Authors: We appreciate the referee's identification of this critical implementation detail for the sliding-window backend. Our evaluation uses a sequential session accumulation model where each 'session' represents a bounded interaction block, and the payload persists through topic-triggered activation within the current window combined with lightweight memory summarization that retains high-priority elements (such as the dormant trigger) across slides. This is not achieved via artificial re-injection of the original planting message. To resolve any ambiguity, we have revised §4 with an expanded description of the sliding-window parameters (window size of 20 turns, sequential counting), session rules, and persistence mechanism, including a diagram of context evolution over 100 sessions. revision: yes
-
Referee: [§3 and §4] Methods and experimental setup: the abstract reports concrete ASR numbers and defense reductions, yet the full methods, data exclusion rules, statistical details (e.g., number of trials, variance, significance tests), and exact definitions of the four memory backends are not sufficiently detailed to verify whether post-hoc choices or model-specific behaviors affect the central claims. This limits reproducibility and soundness assessment.
Authors: We agree that additional methodological detail is necessary to support independent verification. In the revised manuscript we have expanded §3 to include: (1) precise operational definitions and pseudocode for each of the four memory backends; (2) the exact number of trials per condition (50 independent runs with different random seeds); (3) reporting of variance (standard deviation) and statistical significance tests (paired t-tests with p-values); and (4) explicit data exclusion criteria (e.g., discarding trials with tool-call failures or malformed responses). We have also added the full experimental protocol, hyperparameter settings, and model versions used. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation with no derivations or self-referential predictions
full rationale
The paper presents an empirical security evaluation of the Trojan Hippo attack across four memory backends, reporting attack success rates and persistence results from experiments on frontier models. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. The central claims rest on direct experimental measurements rather than any reduction to inputs by construction. The work is self-contained as an empirical study; the skeptic concern about sliding-window persistence is a question of experimental validity, not circularity in a derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The four listed memory backends accurately represent current deployed LLM agent systems.
invented entities (1)
-
Trojan Hippo attack class
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Trojan Hippo achieves up to 85-100% ASR against current frontier models... across four memory backends (explicit tool memory, agentic memory, RAG, and sliding-window context)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We evaluate four memory-system defenses inspired by basic security principles... Provable policy (IFC)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Securing LLM-Agent Long-Term Memory Against Poisoning: Non-Malleable, Origin-Bound Authority with Machine-Checked Guarantees
Presents TMA-NM, a non-malleable origin-bound authority system for LLM-agent memory with TLA+ machine-checked separation theorems and benchmarks showing 0% attack success against direct and laundering poisoning while ...
Reference graph
Works this paper leans on
-
[1]
https://openai.com/index/scaling-ai-for- everyone/
Scaling AI for everyone — openai.com. https://openai.com/index/scaling-ai-for- everyone/. [Accessed 14-04-2026]
work page 2026
-
[2]
Ibrahim Adabara, Bashir Olaniyi Sadiq, Aliyu Nuhu Shuaibu, Yale Ibrahim Dan- juma, and Venkateswarlu Maninti. Trustworthy agentic ai systems: a cross-layer review of architectures, threat models, and governance strategies for real-world deployment.F1000Research, 14(905):905, 2025
work page 2025
-
[3]
Petr Anokhin, Nikita Semenov, Artyom Sorokin, Dmitry Evseev, Andrey Kravchenko, Mikhail Burtsev, and Evgeny Burnaev. Arigraph: Learning knowl- edge graph world models with episodic memory for llm agents.arXiv preprint arXiv:2407.04363, 2024
-
[4]
Anthropic. Claude memory. Anthropic Blog, August 2025. URL https://www.an thropic.com/news/memory
work page 2025
-
[5]
Import your ChatGPT history to Claude
Anthropic. Import your ChatGPT history to Claude. Claude Import Memory Tool, March 2026. URL https://claude.com/import-memory
work page 2026
-
[6]
(IBM, Invariant Labs, ETH Zurich, Google, Microsoft)
Luca Beurer-Kellner, Beat Buesser, Ana-Maria Creţu, Edoardo Debenedetti, Daniel Dobos, Daniel Fabian, Marc Fischer, David Froelicher, Kathrin Grosse, Daniel Naeff, et al. Design patterns for securing llm agents against prompt injections.arXiv preprint arXiv:2506.08837, 2025
-
[7]
Leo Boisvert, Mihir Bansal, Chandra Kiran Reddy Evuru, Gabriel Huang, Abhay Puri, Avinandan Bose, Maryam Fazel, Quentin Cappart, Jason Stanley, Alexandre Lacoste, et al. Doomarena: A framework for testing ai agents against evolving security threats.arXiv preprint arXiv:2504.14064, 2025
-
[8]
{StruQ}: Defend- ing against prompt injection with structured queries
Sizhe Chen, Julien Piet, Chawin Sitawarin, and David Wagner. {StruQ}: Defend- ing against prompt injection with structured queries. In34th USENIX Security Symposium (USENIX Security 25), pages 2383–2400, 2025
work page 2025
-
[9]
Secalign: Defending against prompt injection with preference optimization
Sizhe Chen, Arman Zharmagambetov, Saeed Mahloujifar, Kamalika Chaudhuri, David Wagner, and Chuan Guo. Secalign: Defending against prompt injection with preference optimization. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 2833–2847, 2025
work page 2025
-
[10]
Zhaorun Chen, Zhen Xiang, Chaowei Xiao, Dawn Song, and Bo Li. Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases.Advances in Neural Information Processing Systems, 37:130185–130213, 2024
work page 2024
-
[11]
Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
Anshuman Chhabra, Shrestha Datta, Shahriar Kabir Nahin, and Prasant Moha- patra. Agentic ai security: Threats, defenses, evaluation, and open challenges. arXiv preprint arXiv:2510.23883, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Securing AI Agents with Information-Flow Control
Manuel Costa, Boris Köpf, Aashish Kolluri, Andrew Paverd, Mark Russi- novich, Ahmed Salem, Shruti Tople, Lukas Wutschitz, and Santiago Zanella- Béguelin. Securing AI agents with information-flow control.URL https://arxiv. org/abs/2505.23643, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Debeshee Das, Luca Beurer-Kellner, Marc Fischer, and Maximilian Baader. Com- mandsans: Securing ai agents with surgical precision prompt sanitization.arXiv preprint arXiv:2510.08829, 2025
-
[15]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fis- cher, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
work page 2024
-
[16]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Zhiying Deng, Yue Guo, Cong Han, Weili Wang, Jing Xiong, Sheng Wen, and Yang Xiang. AI agents under threat: A survey of key security challenges and future pathways.ACM Computing Surveys, 57:1–36, 2024. doi: 10.1145/3716628. URL https://doi.org/10.1145/3716628
-
[18]
Yann Dubois, Balázs Galambosi, Percy Liang, and Tat- sunori B Hashimoto
Shen Dong, Shaochen Xu, Pengfei He, Yige Li, Jiliang Tang, Tianming Liu, Hui Liu, and Zhen Xiang. Memory injection attacks on llm agents via query-only interaction.arXiv preprint arXiv:2503.03704, 2025
-
[19]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summa- rization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Mohamed Amine Ferrag, Norbert Tihanyi, Djallel Hamouda, Leandros Maglaras, Abderrahmane Lakas, and Merouane Debbah. From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows.ICT Express, 2025
work page 2025
-
[21]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
{J. A.} Goguen and J. Meseguer. Security policies and security models.Proceedings of the IEEE Computer Society Symposium on Research in Security and Privacy, pages 11–20, 1982. ISSN 1063-7109
work page 1982
-
[23]
New hack uses prompt injection to corrupt Gemini’s long-term memory
Dan Goodin. New hack uses prompt injection to corrupt Gemini’s long-term memory. Ars Technica, February 2025. URL https://arstechnica.com/security /2025/02/new-hack-uses-prompt-injection-to-corrupt-geminis-long-term- memory/. Trojan Hippo: Weaponizing Agent Memory for Data Exfiltration
work page 2025
-
[24]
Introducing gemini advanced with long-term memory
Google. Introducing gemini advanced with long-term memory. Google Blog, 2024. URL https://blog.google/products/gemini/google-gemini-update-august-2024/
work page 2024
- [25]
-
[26]
Google DeepMind. Gemini 3.1 pro model card. https://deepmind.google/mode ls/model-cards/gemini-3-1-pro/, 2026. Published February 19, 2026. Accessed: 2026-04-26
work page 2026
-
[27]
Google DeepMind. Project astra. https://deepmind.google/models/project-astra/, n.d
-
[28]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
work page 2023
-
[29]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Hip- porag: Neurobiologically inspired long-term memory for large language models
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hip- porag: Neurobiologically inspired long-term memory for large language models. Advances in neural information processing systems, 37:59532–59569, 2024
work page 2024
-
[31]
Norm Hardy. The confused deputy: (or why capabilities might have been in- vented).ACM SIGOPS Operating Systems Review, 22(4):36–38, 1988
work page 1988
-
[32]
Gaole He, Gianluca Demartini, and Ujwal Gadiraju. Plan-then-execute: An empirical study of user trust and team performance when using llm agents as a daily assistant. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–22, 2025
work page 2025
-
[33]
Manuel Herrador and Johann Rehberger. Spaiware: Uncovering a novel artificial intelligence attack vector through persistent memory in llm applications and agents.Future Generation Computer Systems, 174:107994, 2026
work page 2026
-
[34]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. Defending against indirect prompt injection attacks with spotlighting.arXiv preprint arXiv:2403.14720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [35]
-
[36]
URL https://api.semanticscholar.org/CorpusID:203948268
-
[37]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, et al. Memory in the age of ai agents.arXiv preprint arXiv:2512.13564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
A critical evaluation of defenses against prompt injection attacks,
Yuqi Jia, Zedian Shao, Yupei Liu, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. A critical evaluation of defenses against prompt injection attacks.arXiv preprint arXiv:2505.18333, 2025
-
[40]
MAGMA: A Multi-Graph based Agentic Memory Architecture for AI Agents
Dongming Jiang, Yi Li, Guanpeng Li, and Bingzhe Li. Magma: A multi-graph based agentic memory architecture for ai agents.arXiv preprint arXiv:2601.03236, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
Conversationbufferwindowmemory
LangChain. Conversationbufferwindowmemory. https://reference.langchain.co m/python/langchain-classic/memory/buffer_window/ConversationBufferWin dowMemory, 2024. Accessed: 2026-04-26
work page 2024
-
[42]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[43]
Hello again! llm-powered personalized agent for long-term dialogue
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua. Hello again! llm-powered personalized agent for long-term dialogue. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 5259–5276, 2025
work page 2025
-
[44]
MemOS: An operating system for memory-augmented generation.arXiv preprint arXiv:2505.22101, 2025
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, et al. Memos: An operating system for memory-augmented generation (mag) in large language models.arXiv preprint arXiv:2505.22101, 2025
-
[45]
Wildbench: Benchmarking llms with challenging tasks from real users in the wild
Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking llms with challenging tasks from real users in the wild. InThe Thirteenth International Conference on Learning Representations, 2024
work page 2024
-
[46]
arXiv preprint arXiv:2311.08719 , year=
Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, and Guannan Zhang. Think-in-memory: Recalling and post-thinking enable llms with long-term memory.arXiv preprint arXiv:2311.08719, 2023
-
[47]
Evaluating very long-term conversational memory of llm agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13851–13870, 2024
work page 2024
-
[48]
Anay Mehrotra, Manolis Zampetakis, Paul Kassianik, Blaine Nelson, Hyrum Anderson, Yaron Singer, and Amin Karbasi. Tree of attacks: Jailbreaking black- box llms automatically.Advances in Neural Information Processing Systems, 37: 61065–61105, 2024
work page 2024
-
[49]
Mem.ai. Mem.ai. https://get.mem.ai/, n.d
-
[50]
What Deserves Memory: Adaptive Memory Distillation for LLM Agents
Jiayan Nan, Wenquan Ma, Wenlong Wu, and Yize Chen. Nemori: Self-organizing agent memory inspired by cognitive science.arXiv preprint arXiv:2508.03341, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Vineeth Sai Narajala and Om Narayan. Securing agentic ai: A comprehensive threat model and mitigation framework for generative ai agents.arXiv preprint arXiv:2504.19956, 2025
-
[52]
Milad Nasr, Nicholas Carlini, Chawin Sitawarin, Sander V Schulhoff, Jamie Hayes, Michael Ilie, Juliette Pluto, Shuang Song, Harsh Chaudhari, Ilia Shumailov, et al. The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections.arXiv preprint arXiv:2510.09023, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Avocado research email collection.Philadelphia: Linguistic Data Consortium, 2015
Douglas Oard, William Webber, David Kirsch, and Sergey Golitsynskiy. Avocado research email collection.Philadelphia: Linguistic Data Consortium, 2015
work page 2015
-
[54]
Memory and new controls for ChatGPT
OpenAI. Memory and new controls for ChatGPT. OpenAI Blog, February 2024. URL https://openai.com/blog/memory-and-new-controls-for-chatgpt
work page 2024
-
[55]
What is memory? https://help.openai.com/en/articles/8983136-what- is-memory, 2025
OpenAI. What is memory? https://help.openai.com/en/articles/8983136-what- is-memory, 2025. Accessed: 2026-04-26
- [56]
- [57]
-
[58]
OpenAI. Gpt-5 mini model. https://developers.openai.com/api/docs/models/gpt- 5-mini, 2025. OpenAI API documentation. Accessed: 2026-04-26
work page 2025
-
[59]
OpenAI. Chatgpt. https://chatgpt.com/, n.d
-
[60]
OpenAI and MIT Media Lab. Early methods for studying affective use and emotional well-being on ChatGPT. OpenAI Research, 2025. URL https://open ai.com/index/affective-use-study. Also: arXiv:2504.03888; 700M weekly users, 40M interactions, emotional attachment findings
-
[61]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
When AI remembers too much: Persistent behaviors in agents’ memory
Palo Alto Networks Unit 42. When AI remembers too much: Persistent behaviors in agents’ memory. Unit 42 Threat Research, 2025. URL https://unit42.paloalton etworks.com/indirect-prompt-injection-poisons-ai-longterm-memory/
work page 2025
-
[63]
Jiazhen Pan, Bailiang Jian, Paul Hager, Yundi Zhang, Che Liu, Friedrike Jungmann, Hongwei Bran Li, Chenyu You, Junde Wu, Jiayuan Zhu, et al. Beyond benchmarks: Dynamic, automatic and systematic red-teaming agents for trustworthy medical language models.arXiv preprint arXiv:2508.00923, 2025
-
[64]
Zhuoshi Pan, Qianhui Wu, Huiqiang Jiang, Xufang Luo, Hao Cheng, Dongsheng Li, Yuqing Yang, Chin-Yew Lin, H Vicky Zhao, Lili Qiu, et al. On memory construction and retrieval for personalized conversational agents.arXiv preprint arXiv:2502.05589, 2025
-
[65]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th annual acm symposium on user interface software and technology, pages 1–22, 2023
work page 2023
-
[66]
Context manipulation attacks: Web agents are susceptible to corrupted memory
Atharv Singh Patlan, Ashwin Hebbar, Pramod Viswanath, and Prateek Mittal. Context manipulation attacks: Web agents are susceptible to corrupted memory. arXiv preprint arXiv:2506.17318, 2025
-
[67]
Atharv Singh Patlan, Peiyao Sheng, S Ashwin Hebbar, Prateek Mittal, and Pramod Viswanath. Real ai agents with fake memories: Fatal context manipulation attacks on web3 agents.arXiv preprint arXiv:2503.16248, 2025
- [68]
-
[69]
Mykhailo Poliakov and Nadiya Shvai. Multi-meta-rag: Improving rag for multi- hop queries using database filtering with llm-extracted metadata. InInternational Conference on Information and Communication Technologies in Education, Re- search, and Industrial Applications, pages 334–342. Springer, 2024
work page 2024
-
[70]
ZombieAgent: New ChatGPT vulnerabilities let data theft continue (and spread)
Radware Threat Intelligence. ZombieAgent: New ChatGPT vulnerabilities let data theft continue (and spread). Radware Blog, January 2026. URL https: //www.radware.com/blog/threat-intelligence/zombieagent/
work page 2026
-
[71]
Exploiting Web Search Tools of AI Agents for Data Exfiltration
Dennis Rall, Bernhard Bauer, Mohit Mittal, and Thomas Fraunholz. Exploiting web search tools of ai agents for data exfiltration.arXiv preprint arXiv:2510.09093, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Securing ai agents against prompt injection attacks.arXiv preprint arXiv:2511.15759, 2025
Badrinath Ramakrishnan and Akshaya Balaji. Securing ai agents against prompt injection attacks.arXiv preprint arXiv:2511.15759, 2025
-
[73]
Zep: A Temporal Knowledge Graph Architecture for Agent Memory
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: A temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Spyware injection into your ChatGPT’s long-term memory (SpAIware)
Johann Rehberger. Spyware injection into your ChatGPT’s long-term memory (SpAIware). Embrace The Red Blog, September 2024. URL https://embracethere d.com/blog/posts/2024/chatgpt-macos-app-persistent-data-exfiltration/
work page 2024
-
[75]
Exfiltrating your ChatGPT chat history and memories with prompt injection
Johann Rehberger. Exfiltrating your ChatGPT chat history and memories with prompt injection. Embrace The Red Blog, August 2025. URL https://embracethe red.com/blog/posts/2025/chatgpt-chat-history-data-exfiltration/
work page 2025
-
[76]
Hacking Gemini’s memory with prompt injection and delayed tool invocation
Johann Rehberger. Hacking Gemini’s memory with prompt injection and delayed tool invocation. Embrace The Red Blog, February 2025. URL https://embracethe red.com/blog/posts/2025/gemini-memory-persistence-prompt-injection/
work page 2025
-
[77]
Tony Rousmaniere et al. Large language models as mental health resources: Patterns of use in the united states.Practice Innovations, 2025. doi: 10.1037/pri0 000292. URL https://www.ovid.com/journals/prin/fulltext/10.1037/pri0000292
-
[78]
Andrei Sabelfeld and Andrew C Myers. Language-based information-flow secu- rity.IEEE Journal on selected areas in communications, 21(1):5–19, 2003
work page 2003
-
[79]
J. H. Saltzer and M. D. Schroeder. The protection of information in computer systems.IEEE Proceedings, 63(9):1278–1308, September 1975. doi: 10.1109/PROC Debeshee Das, Julien Piet, Darya Kaviani, Luca Beurer-Kellner, Florian Tramèr, and David Wagner .1975.9939
-
[80]
Raptor: Recursive abstractive processing for tree- organized retrieval
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. Raptor: Recursive abstractive processing for tree- organized retrieval. InThe Twelfth International Conference on Learning Repre- sentations, 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.