A Unified and Reproducible Experimentation Framework for Speech Understanding
Pith reviewed 2026-06-28 21:18 UTC · model grok-4.3
The pith
SURE standardizes prediction formats, normalization, scoring, and training pipelines to enable comparable and reproducible evaluations of speech models across paradigms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
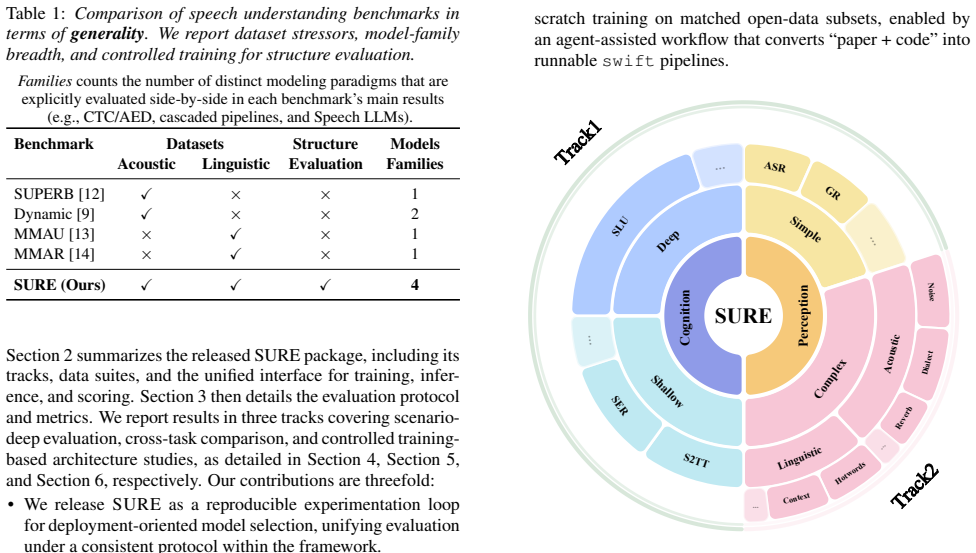
SURE standardizes prediction formats, normalization, and scoring; evaluates strong systems across paradigms on representative tasks under realistic stressors; and introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets, improving comparability and reproducibility for deployment-oriented evaluation.
What carries the argument
The SURE framework, which enforces standardized prediction formats, normalization, and scoring together with an agent-assisted training conversion flow that produces versioned runnable pipelines.
If this is right
- Evaluations of conventional pipelines and Speech LLMs become directly comparable on the same tasks and stressors.
- Training results from different papers can be rerun and verified on identical open-data subsets.
- Model selection for deployment can rest on consistent scoring rather than author-specific post-processing choices.
- The agent-assisted flow turns ad-hoc code releases into maintained, versioned pipelines.
- Systems are assessed under realistic acoustic and linguistic conditions rather than only clean benchmarks.
Where Pith is reading between the lines
- Adoption of SURE could reduce the need for each new paper to re-implement evaluation code from scratch.
- The same standardization approach might transfer to other modalities where post-processing differences currently block fair comparisons.
- Wider use could surface systematic performance gaps between paradigms that only appear under matched conditions.
- Deployment teams could run their own models through the same protocol to benchmark against published results.
Load-bearing premise
Mismatched post-processing and non-reproducible training pipelines are the primary barriers that prevent fair deployment-oriented model selection.
What would settle it
Applying SURE to several published speech systems and still obtaining substantially different relative rankings or scores than the original papers would indicate the standardization does not resolve the comparability problem.
Figures
read the original abstract
Speech foundation models and Speech LLMs have advanced speech understanding, yet deployment-oriented model selection is hindered by non-comparable evaluations caused by mismatched post-processing, and by training results that are hard to reproduce across data scales and pipelines. We present SURE, a unified experimentation framework that standardizes prediction formats, normalization, and scoring. SURE evaluates strong systems across paradigms, from conventional pipelines to Speech LLMs, on representative tasks under realistic acoustic and linguistic stressors. Beyond evaluation, SURE introduces an agent-assisted training conversion flow that maps paper and code into versioned, runnable training pipelines under a unified protocol on matched open-data subsets. Overall, SURE improves comparability and reproducibility for deployment-oriented evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SURE, a unified experimentation framework for speech understanding tasks. It standardizes prediction formats, normalization, and scoring to enable fair evaluation of speech foundation models and Speech LLMs across conventional pipelines and LLM-based paradigms on representative tasks under acoustic and linguistic stressors. Additionally, it proposes an agent-assisted training conversion flow that converts papers and code into versioned, runnable training pipelines on matched open-data subsets under a unified protocol, with the overall goal of improving comparability and reproducibility for deployment-oriented model selection.
Significance. If the described standardization components are implemented and widely adopted, SURE could reduce inconsistencies arising from mismatched post-processing and non-reproducible training pipelines, facilitating more reliable cross-system comparisons in speech understanding. The agent-assisted conversion flow represents a practical contribution toward reproducible training on open data. However, the significance is limited by the absence of any quantitative validation demonstrating actual improvements in comparability or reproducibility metrics.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claim that SURE 'improves comparability and reproducibility' is asserted without any quantitative results, baseline comparisons, error bars, or metrics (e.g., variance in scores across systems or reproduction success rates) to support it; the evaluation is described but supplies no evidence of the claimed gains over existing practices.
- [Training conversion flow description] Training conversion flow description: The agent-assisted mapping from paper/code to runnable pipelines is presented as addressing reproducibility barriers, but no details are given on failure modes, success rates on the claimed 'strong systems,' or how the unified protocol on matched subsets differs measurably from prior efforts in terms of pipeline fidelity.
minor comments (2)
- [Methods] Notation for prediction formats and normalization steps should be formalized with explicit equations or pseudocode to allow readers to verify the standardization protocol.
- [Evaluation] The list of representative tasks and stressors lacks a table summarizing the exact datasets, acoustic conditions, and linguistic variations used.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for quantitative support for our claims. We address each major comment below, clarifying the scope of the current manuscript while noting where revisions can strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The central claim that SURE 'improves comparability and reproducibility' is asserted without any quantitative results, baseline comparisons, error bars, or metrics (e.g., variance in scores across systems or reproduction success rates) to support it; the evaluation is described but supplies no evidence of the claimed gains over existing practices.
Authors: We agree that the manuscript asserts the improvement in comparability and reproducibility through standardization without providing quantitative metrics such as reduced score variance or reproduction success rates. The evaluation section applies SURE to strong systems across paradigms but does not include before-and-after comparisons against non-standardized pipelines. This is a limitation of the current work, which focuses on describing the framework and its application rather than an empirical study of its impact. We will revise the abstract and evaluation section to qualify the claim (e.g., 'facilitates improved comparability') and add a brief discussion of how the standardized components address known sources of inconsistency, without introducing unsubstantiated metrics. revision: partial
-
Referee: [Training conversion flow description] Training conversion flow description: The agent-assisted mapping from paper/code to runnable pipelines is presented as addressing reproducibility barriers, but no details are given on failure modes, success rates on the claimed 'strong systems,' or how the unified protocol on matched subsets differs measurably from prior efforts in terms of pipeline fidelity.
Authors: The training conversion flow is introduced as a practical mechanism to generate versioned pipelines on matched open-data subsets, but the manuscript provides no quantitative details on success rates, failure modes, or direct comparisons of pipeline fidelity to prior reproducibility efforts. The description emphasizes the agent-assisted process and unified protocol as the contribution. We acknowledge that additional specifics on these aspects would better substantiate the approach and will expand the relevant section with qualitative examples of the conversion process and any observed challenges, while noting that systematic success-rate benchmarks remain future work. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an experimentation framework (SURE) for standardizing formats, normalization, scoring, and training pipelines in speech understanding tasks. No equations, derivations, fitted parameters, or predictions are present that could reduce to their own inputs by construction. Claims rest on the existence and application of the described standardization components rather than any self-referential logical chain, self-citation load-bearing argument, or ansatz. The work is self-contained as a tooling contribution with no internal reduction to fitted or renamed inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A Unified and Reproducible Experimentation Framework for Speech Understanding
Introduction Speech understanding has advanced rapidly with the rise of speech foundation models and speech large language models (Speech LLMs) [1, 2]. These models aim to cover broad speech understanding capabilities, from recognition to understanding and reasoning over spoken content. Despite this progress, the community still lacks a reproducible frame...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
paper + code
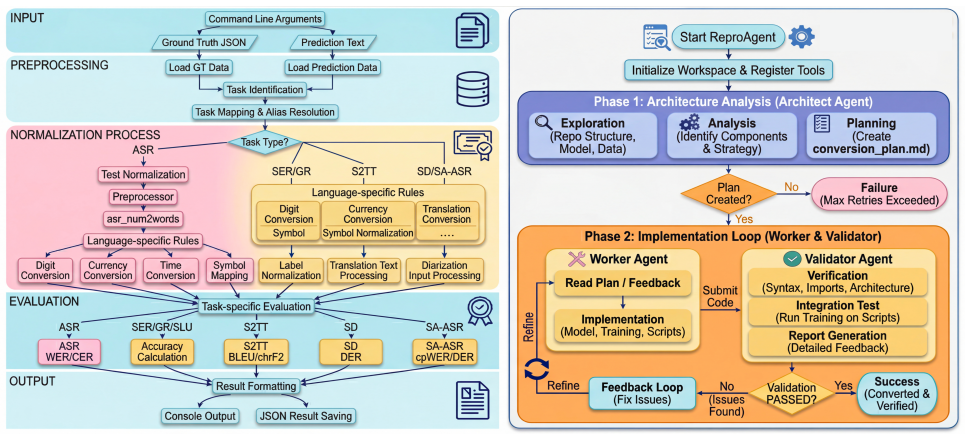
Overview of SURE SURE is an end-to-end experimentation package for repro- ducible speech understanding evaluation, with an agent-assisted conversion workflow for controlled training studies. It provides: •Project websitefor documentation and updates. 1 •Unified evaluation stackwith post-processing and scoring. 2 •Agent assisted pipelinefor training conver...
-
[3]
paper + code
Evaluation Protocol and Metrics To connect the track design in Section 2 with the reproducibility goal stated in Section 1, we summarize SURE’s evaluation pro- tocol and metrics. To enable reproducible evaluation across the three tracks, we release a unified evaluation pipeline with task- specific scoring rules, and further introduce RPS—a compact indicat...
-
[4]
Track I: Scenario Stress Testing for Front-end Speech Tasks Track I targets front-end speech perception, focusing on whether ASR systems remain reliable under realistic deploy- ment conditions. We introduce this track because many evalu- ations are conducted on narrowly controlled test sets and there- fore fail to characterize system behavior under the co...
-
[5]
Track II: Full-stack Speech Understanding Evaluation Following the scenario stress tests in Track I, Track II performs ahorizontalcomparison across representative speech under- standing tasks under a unified protocol. We benchmark strong systems across paradigms, including end-to-end Speech LLMs and a cascaded pipeline as a complementary reference, and ev...
-
[6]
paper + code
Track III: Initial Exploration of Controlled Training After Tracks I–II, Track III provides an initial exploration of controlled trainingas a step toward more reproducible training- based studies. Rather than claiming broad architecture-level conclusions, our goal is to make “paper + code”executable and comparableunder a unified protocol by releasing an a...
-
[7]
pa- per + code
Conclusions We presented SURE, a unified and reproducible experimenta- tion framework for speech understanding. SURE standardizes prediction formats, normalization, and scoring for consistent comparison across model types, and provides scenario-driven suites under realistic acoustic and linguistic stressors. It also releases an agent-assisted conversion w...
-
[8]
On the landscape of spoken language models: A comprehensive survey,
S. Arora, K.-W. Chang, C.-M. Chien, Y . Peng, H. Wu, Y . Adi, E. Dupoux, H.-Y . Lee, K. Livescu, and S. Watanabe, “On the landscape of spoken language models: A comprehensive survey,”
-
[9]
On The Landscape of Spoken Language Models: A Comprehensive Survey
[Online]. Available: https://arxiv.org/abs/2504.08528
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
A survey on speech large language models for understanding,
J. Peng, Y . Wang, B. Li, Y . Guo, H. Wang, Y . Fang, Y . Xi, H. Li, X. Li, K. Zhang, S. Wang, and K. Yu, “A survey on speech large language models for understanding,”IEEE Journal of Selected Topics in Signal Processing, p. 1–32, 2025. [Online]. Available: http://dx.doi.org/10.1109/JSTSP.2025.3640535
-
[11]
Measuring the accuracy of automatic speech recognition solutions,
K. Kuhn, V . Kersken, B. Reuter, N. Egger, and G. Zimmermann, “Measuring the accuracy of automatic speech recognition solutions,”ACM Trans. Access. Comput., vol. 16, no. 4, Jan
-
[12]
Available: https://doi.org/10.1145/3636513
[Online]. Available: https://doi.org/10.1145/3636513
-
[13]
V . Srivastav, S. Zheng, E. Bezzam, E. L. Bihan, A. Moumen, and S. Gandhi, “Open asr leaderboard: Towards reproducible and transparent multilingual speech recognition evaluation,” 2025. [Online]. Available: https://arxiv.org/abs/2510.06961
-
[14]
Methodologies for the evaluation of speaker diariza- tion and automatic speech recognition in the presence of overlap- ping speech,
O. Galibert, “Methodologies for the evaluation of speaker diariza- tion and automatic speech recognition in the presence of overlap- ping speech,” 08 2013
2013
-
[15]
On the evaluation of speech foundation models for spoken language understanding,
S. Arora, A. Pasad, C.-M. Chien, J. Han, R. Sharma, J. weon Jung, H. Dhamyal, W. Chen, S. Shon, H. yi Lee, K. Livescu, and S. Watanabe, “On the evaluation of speech foundation models for spoken language understanding,” 2024. [Online]. Available: https://arxiv.org/abs/2406.10083
-
[16]
Speechr: A benchmark for speech reasoning in large audio-language models,
W. Yang, Y . Li, Y . Wei, M. Fang, and L. Chen, “Speechr: A benchmark for speech reasoning in large audio-language models,”
-
[17]
Available: https://arxiv.org/abs/2508.02018
[Online]. Available: https://arxiv.org/abs/2508.02018
-
[18]
SUPERB: Speech Processing Universal PERformance Benchmark,
S.-w. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.- H. Huang, W.-C. Tseng, K.-t. Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H.-y. Lee, “SUPERB: Speech Processing Universal PERformance Benchmark,” inProc. Interspeech 2021, 2021, pp. 1194–1198. [Online]. Ava...
2021
-
[19]
Dynamic-SUPERB: Towards a Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech,
C.-y. Huang, K.-H. Lu, S.-H. Wang, C.-Y . Hsiao, C.-Y . Kuan, H. Wu, S. Arora, K.-W. Chang, J. Shi, Y . Peng, R. Sharma, S. Watanabe, B. Ramakrishnan, S. Shehata, and H.-y. Lee, “Dynamic-SUPERB: Towards a Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech,” in Proc. ICASSP 2024, 2024, pp. 12 136–12 140
2024
-
[20]
AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension,
Q. Yang, J. Xu, W. Liu, Y . Chu, Z. Jiang, X. Zhou, Y . Leng, Y . Lv, Z. Zhao, C. Zhou, and J. Zhou, “AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 1979–1998. [Online]. Available: https://aclanth...
2024
-
[21]
AudioBench: A Universal Benchmark for Audio Large Language Models,
B. Wang, X. Zou, G. Lin, S. Sun, Z. Liu, W. Zhang, Z. Liu, A. Aw, and N. F. Chen, “AudioBench: A Universal Benchmark for Audio Large Language Models,” inProceedings of the 2025 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Long Papers), 2025. [Online]. Available: https://aclantholog...
2025
-
[22]
Superb: Speech processing universal performance benchmark,
S. wen Yang, P.-H. Chi, Y .-S. Chuang, C.-I. J. Lai, K. Lakhotia, Y . Y . Lin, A. T. Liu, J. Shi, X. Chang, G.-T. Lin, T.-H. Huang, W.-C. Tseng, K. tik Lee, D.-R. Liu, Z. Huang, S. Dong, S.-W. Li, S. Watanabe, A. Mohamed, and H. yi Lee, “Superb: Speech processing universal performance benchmark,” 2021. [Online]. Available: https://arxiv.org/abs/2105.01051
-
[23]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
S. Sakshi, U. Tyagi, S. Kumar, A. Seth, R. Selvakumar, O. Nieto, R. Duraiswami, S. Ghosh, and D. Manocha, “Mmau: A massive multi-task audio understanding and reasoning benchmark,” 2024. [Online]. Available: https://arxiv.org/abs/2410.19168
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
MMAR: A challenging benchmark for deep reasoning in speech, audio, music, and their mix
Z. Ma, Y . Ma, Y . Zhu, C. Yang, Y .-W. Chao, R. Xu, W. Chen, Y . Chen, Z. Chen, J. Cong, K. Li, K. Li, S. Li, X. Li, X. Li, Z. Lian, Y . Liang, M. Liu, Z. Niu, T. Wang, Y . Wang, Y . Wang, Y . Wu, G. Yang, J. Yu, R. Yuan, Z. Zheng, Z. Zhou, H. Zhu, W. Xue, E. Benetos, K. Yu, E.-S. Chng, and X. Chen, “Mmar: A challenging benchmark for deep reasoning in sp...
-
[25]
Meeteval: A toolkit for com- putation of word error rates for meeting transcription systems,
T. von Neumann and other authors, “Meeteval: A toolkit for com- putation of word error rates for meeting transcription systems,” arXiv preprint arXiv:2307.11394, 2023
-
[26]
A call for clarity in reporting BLEU scores,
M. Post, “A call for clarity in reporting BLEU scores,” inProceed- ings of the Third Conference on Machine Translation: Research Papers, 2018, pp. 186–191
2018
-
[27]
C. Wang, M. Rivi `ere, A. Lee, A. Wu, C. Talnikar, D. Haz- iza, M. Williamson, J. Pino, and E. Dupoux, “V oxpopuli: A large-scale multilingual speech corpus for representation learn- ing, semi-supervised learning and interpretation,”arXiv preprint arXiv:2101.00390, 2021
-
[28]
Y . Dai, H. Wang, X. Li, Z. Zhang, S. Wang, L. Xie, X. Xu, H. Guo, S. Zhang, H. Bu, and W. Chen, “Aishell-5: The first open-source in-car multi-channel multi-speaker speech dataset for automatic speech diarization and recognition,” inProc. Interspeech, 2025. [Online]. Available: https://arxiv.org/abs/2505.23036
-
[29]
The AMI meeting corpus,
I. McCowan, J. Carletta, W. Kraaij, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V . Karaiskoset al., “The AMI meeting corpus,” inProceedings of Measuring Behav- ior, 2005
2005
-
[30]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inProc. ICASSP. IEEE, 2022
2022
-
[31]
J. Zhou, Y . Guo, S. Zhao, H. Sun, H. Wang, J. He, A. Kong, S. Wang, X. Yang, Y . Wanget al., “Cs-dialogue: A 104-hour dataset of spontaneous mandarin-english code-switching dia- logues for speech recognition,”arXiv preprint arXiv:2502.18913, 2025
-
[32]
Ke- speech: An open source speech dataset of mandarin and its eight subdialects,
Z. Tang, D. Wang, Y . Xu, J. Sun, X. Lei, S. Zhao, C. Wen, X. Tan, C. Xie, S. Zhou, R. Yan, C. Lv, Y . Han, W. Zou, and X. Li, “Ke- speech: An open source speech dataset of mandarin and its eight subdialects,” inProceedings of the NeurIPS Datasets and Bench- marks Track, 2021
2021
-
[33]
Contextasr-bench: A massive contextual speech recognition benchmark,
H. Wang, L. Ma, D. Guo, X. Wang, L. Xie, J. Xu, and J. Lin, “Contextasr-bench: A massive contextual speech recognition benchmark,”arXiv preprint arXiv:2507.05727, 2025
-
[34]
Vibevoice-asr technical report,
Z. Peng, J. Yu, Y . Chang, Z. Wang, L. Dong, Y . Hao, Y . Tu, C. Yang, W. Wang, S. Xuet al., “Vibevoice-asr technical report,” arXiv preprint arXiv:2601.18184, 2026
-
[35]
Covost 2 and massively multilingual speech translation
C. Wang, A. Wu, J. Gu, and J. Pino, “Covost 2 and massively multilingual speech translation.” inInterspeech, vol. 2021, 2021, pp. 2247–2251
2021
-
[36]
Swift: a scalable lightweight infras- tructure for fine-tuning,
Y . Zhao, J. Huang, J. Hu, X. Wang, Y . Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wanget al., “Swift: a scalable lightweight infras- tructure for fine-tuning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 28, 2025, pp. 29 733–29 735
2025
-
[37]
Iemocap: Interactive emotional dyadic motion capture database,
C. Busso, M. Bulut, C.-C. Lee, A. Kazemzadeh, E. Mower, S. Kim, J. N. Chang, S. Lee, and S. S. Narayanan, “Iemocap: Interactive emotional dyadic motion capture database,”Language resources and evaluation, vol. 42, no. 4, pp. 335–359, 2008
2008
-
[38]
Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,
S. Poria, D. Hazarika, N. Majumder, G. Naik, E. Cambria, and R. Mihalcea, “Meld: A multimodal multi-party dataset for emo- tion recognition in conversations,” inProceedings of the 57th annual meeting of the association for computational linguistics, 2019, pp. 527–536
2019
-
[39]
Slurp: A spoken language understanding resource package,
E. Bastianelli, A. Vanzo, P. Swietojanski, and V . Rieser, “Slurp: A spoken language understanding resource package,” inProceed- ings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 7252–7262
2020
-
[40]
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
D. Wang, J. Wu, J. Li, D. Yang, X. Chen, T. Zhang, and H. Meng, “Mmsu: A massive multi-task spoken language understanding and reasoning benchmark,”arXiv preprint arXiv:2506.04779, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Linet al., “Qwen2-audio technical report,”arXiv preprint arXiv:2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Tasu: Text-only alignment for speech understanding,
J. Peng, Y . Yang, X. Li, Y . Xi, Q. Tang, Y . Fang, J. Li, and K. Yu, “Tasu: Text-only alignment for speech understanding,”
-
[43]
Available: https://arxiv.org/abs/2511.03310
[Online]. Available: https://arxiv.org/abs/2511.03310
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.