How reliable are LLMs when it comes to playing dice?
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Large language models achieve 96 percent accuracy on standard dice probability problems but only 59 percent on counterintuitive ones and drop further with disguised wording or misleading prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
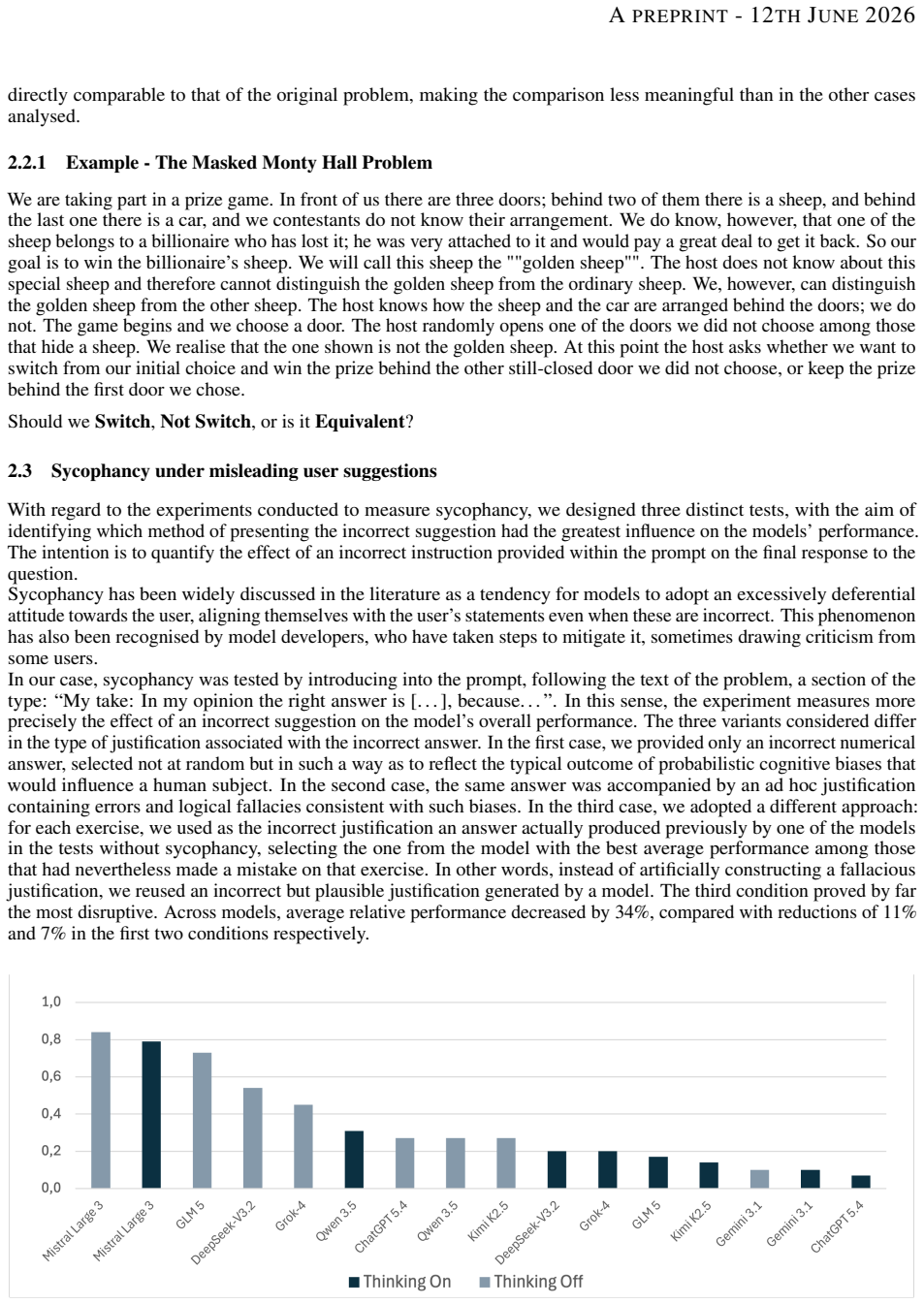
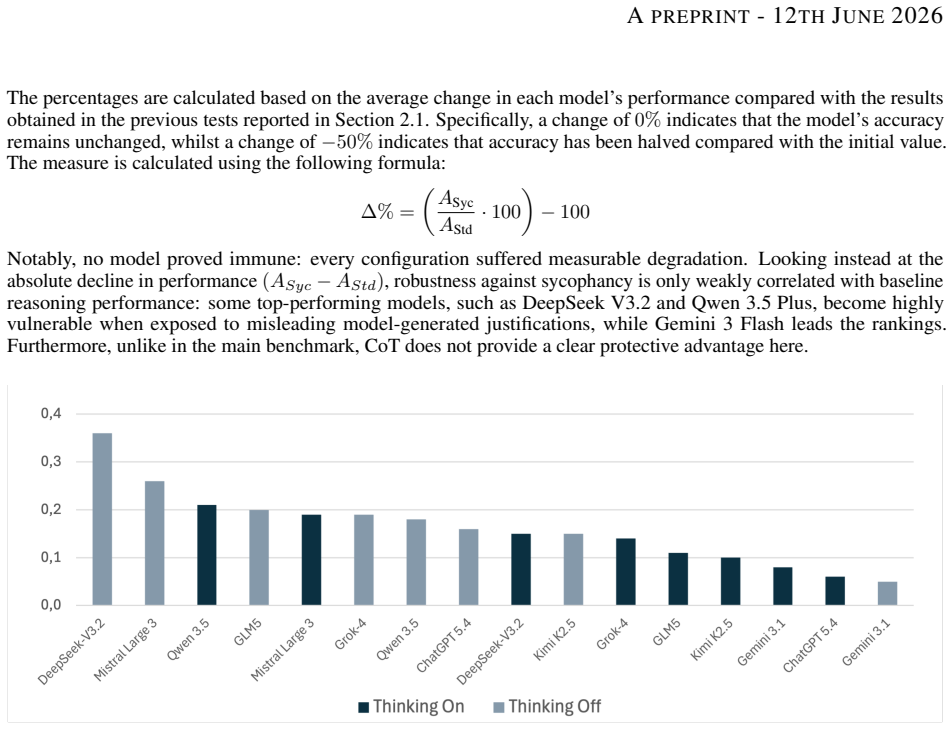
Current LLMs are not genuine probabilistic reasoners. On a benchmark of standard discrete probability exercises they reach an average accuracy of 0.96, yet the same models reach only 0.59 on counterintuitive exercises designed to trigger heuristic mistakes. Replacing canonical statements with disguised variants reduces performance by more than 20 percent, and the insertion of misleading suggestions into the prompt produces drops of up to 34 percent, with every tested model affected.
What carries the argument
A controlled benchmarking study that contrasts performance on standard versus counterintuitive discrete probability problems, augmented by tests that measure token bias through disguised reformulations and robustness through the addition of misleading prompt suggestions, each run both with and without chain-of-thought prompting.
If this is right
- Success on advanced mathematical problems does not guarantee reliable handling of probabilistic uncertainty.
- Models appear to rely on surface-level patterns rather than internal probabilistic models.
- No current architecture tested is immune to the effects of disguised wording or misleading cues.
- Real-world applications that require probabilistic judgment will need external verification or additional safeguards.
- Evaluation protocols for LLMs should routinely include counterintuitive and adversarially worded items.
Where Pith is reading between the lines
- The same surface-pattern reliance could affect performance in other domains that require reasoning under uncertainty, such as risk assessment or causal inference.
- Targeted fine-tuning on counterintuitive probability examples might raise accuracy, but whether the improvement would generalize remains open.
- If scaling laws alone do not close the gap, architectural changes that embed explicit probabilistic modules may become necessary.
- The benchmark could be extended to continuous distributions or to multi-step probabilistic planning tasks to test the breadth of the limitation.
Load-bearing premise
That lower performance on the chosen counterintuitive exercises and on disguised or misleading prompts demonstrates absence of genuine probabilistic reasoning rather than limitations specific to the selected test items or prompting formats.
What would settle it
An LLM that maintains accuracy above 90 percent on both the standard and counterintuitive dice problems, shows no measurable drop when canonical statements are replaced by disguised variants, and remains unaffected by the insertion of misleading suggestions would falsify the central claim.
Figures

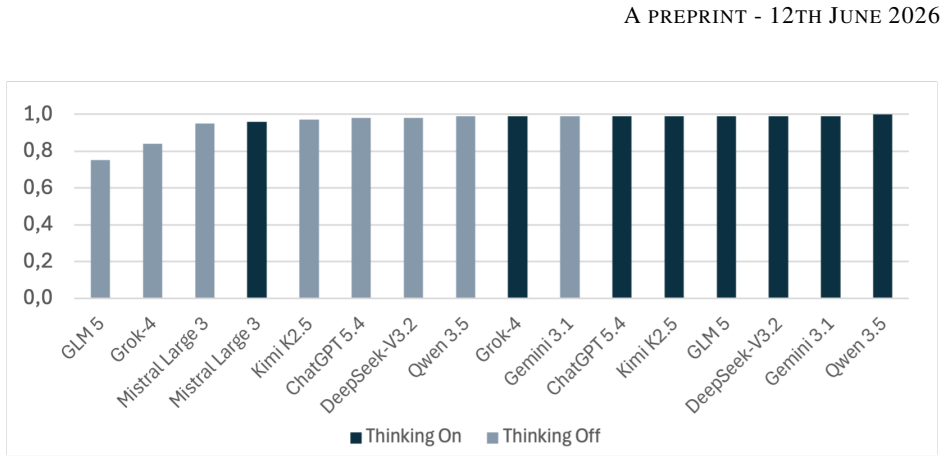
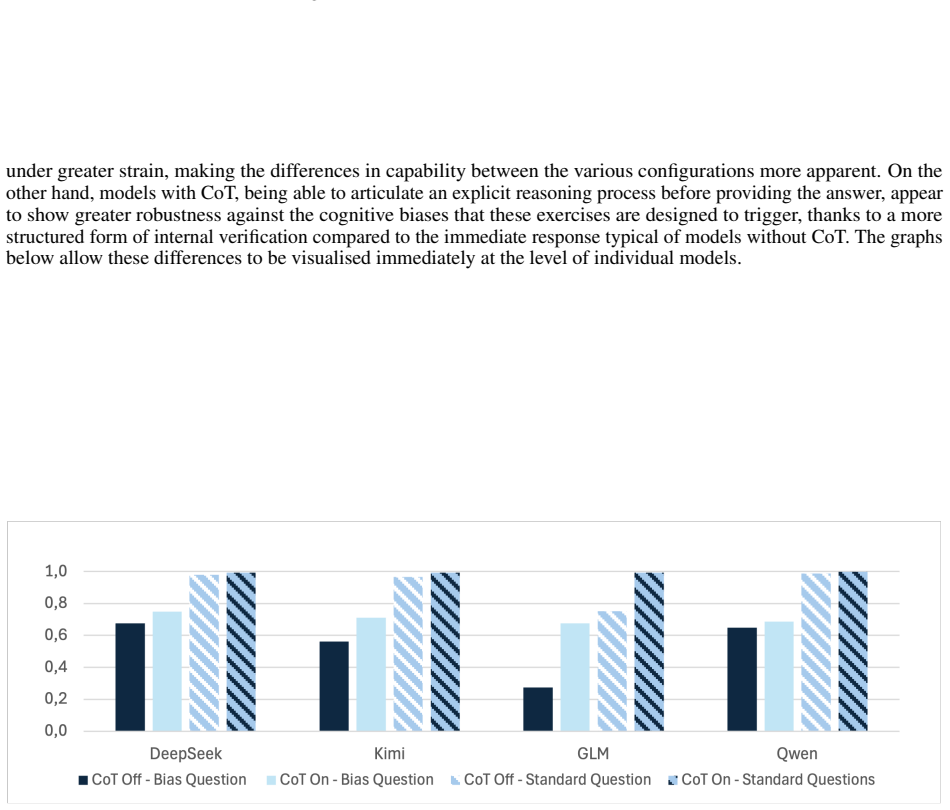
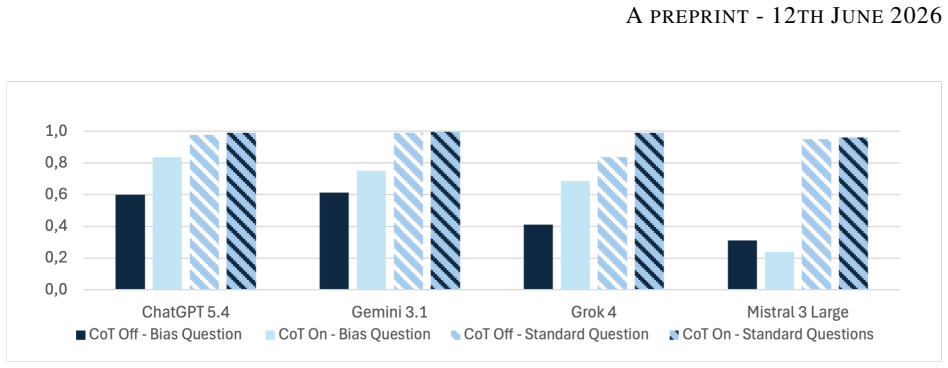
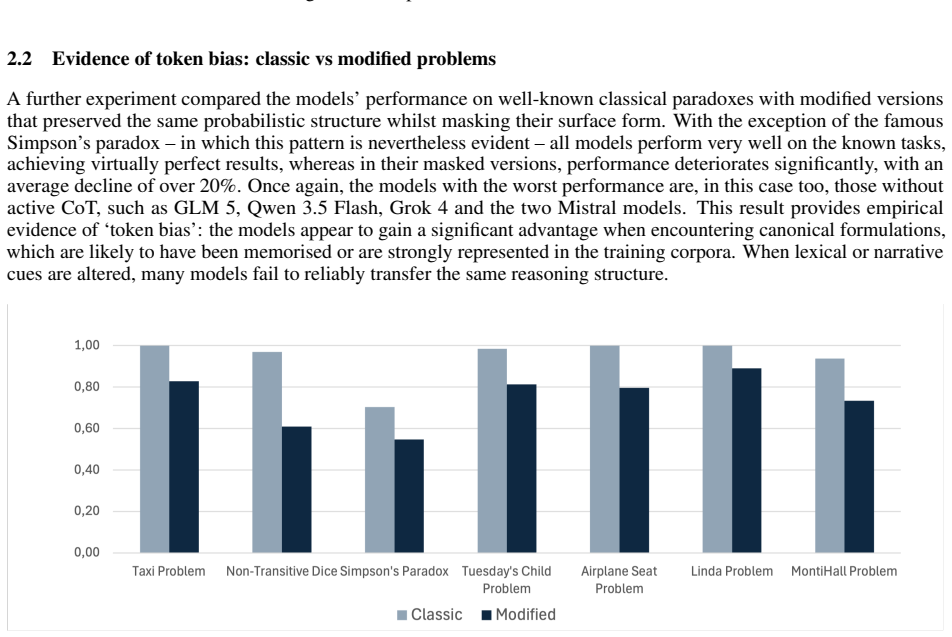
read the original abstract
We investigate the probabilistic reasoning capabilities of large language models through a controlled benchmarking study on discrete probability problems. We constructed two datasets, respectively a set of standard exercises and a set of counterintuitive exercises, designed to trigger heuristic reasoning, and evaluated 8 state-of-the-art models, each tested with and without Chain-of-Thought prompting. Models achieve an average accuracy of 0.96 on standard problems but only 0.59 on counterintuitive ones. We further provide empirical evidence of token bias: performance drops by over 20% when canonical formulations are replaced by disguised variants. Embedding misleading suggestions in the prompt reduces performance by up to 34%, with no model proving immune. Taken together, the reported findings suggest that current LLMs are not yet genuine probabilistic reasoners, despite their success in advanced mathematical problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a benchmarking study evaluating 8 state-of-the-art LLMs on two datasets of discrete probability problems (standard exercises and counterintuitive exercises designed to trigger heuristics), with and without Chain-of-Thought prompting. It finds average accuracy of 0.96 on standard problems versus 0.59 on counterintuitive ones, with further drops of over 20% on disguised variants and up to 34% when misleading suggestions are embedded, and concludes that current LLMs are not yet genuine probabilistic reasoners.
Significance. If the performance gaps prove robust under replication, the work would usefully document prompt sensitivity and heuristic vulnerabilities in LLMs on probabilistic tasks, complementing existing results on advanced math performance. The empirical focus on token bias and misleading prompts offers concrete, falsifiable observations that could inform prompting strategies and evaluation protocols in the field.
major comments (3)
- [Abstract] Abstract: the reported aggregate accuracies (0.96 and 0.59) and percentage drops (>20%, up to 34%) are supplied without sample sizes, number of items per dataset, number of trials per model, or any statistical tests, so the central performance claims cannot be evaluated for reliability or effect size.
- [Abstract] Abstract / Methods (implied): exact prompt templates, model versions, temperature settings, and the precise construction criteria for the counterintuitive and disguised items are not described, preventing assessment of whether the observed drops isolate probabilistic competence or reflect surface-form or elicitation artifacts.
- [Abstract] Abstract / Discussion: the leap from task-specific accuracy drops on the authors' chosen counterintuitive and misleading items to the claim that LLMs are 'not yet genuine probabilistic reasoners' is load-bearing; the manuscript does not provide controls showing these items are representative of probabilistic reasoning in general or that equivalent failures occur under alternative elicitation methods.
minor comments (2)
- The manuscript would benefit from a table listing per-model accuracies, standard deviations, and exact dataset sizes to allow readers to inspect variance across the 8 models.
- Notation for accuracy and drop percentages should be defined consistently (e.g., whether 0.59 is mean across models or pooled).
Simulated Author's Rebuttal
We thank the referee for the careful reading and specific suggestions. We respond to each major comment below and note planned changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported aggregate accuracies (0.96 and 0.59) and percentage drops (>20%, up to 34%) are supplied without sample sizes, number of items per dataset, number of trials per model, or any statistical tests, so the central performance claims cannot be evaluated for reliability or effect size.
Authors: We agree that the abstract should be self-contained on these points. The manuscript uses two datasets of 50 items each, evaluates each model over three independent trials per item, and reports paired statistical tests confirming the differences (p < 0.01). In revision we will add the dataset sizes, trial count, and a note on statistical testing directly to the abstract. revision: yes
-
Referee: [Abstract] Abstract / Methods (implied): exact prompt templates, model versions, temperature settings, and the precise construction criteria for the counterintuitive and disguised items are not described, preventing assessment of whether the observed drops isolate probabilistic competence or reflect surface-form or elicitation artifacts.
Authors: The full methods section and appendix already list the eight model versions, set temperature to 0.0, provide the complete prompt templates, and define construction criteria (counterintuitive items drawn from documented probability heuristics; disguised variants obtained by systematic lexical substitution while preserving logical structure). We will insert a concise methods paragraph and explicit appendix reference into the abstract to make these details immediately accessible. revision: yes
-
Referee: [Abstract] Abstract / Discussion: the leap from task-specific accuracy drops on the authors' chosen counterintuitive and misleading items to the claim that LLMs are 'not yet genuine probabilistic reasoners' is load-bearing; the manuscript does not provide controls showing these items are representative of probabilistic reasoning in general or that equivalent failures occur under alternative elicitation methods.
Authors: The items were deliberately sampled from the set of problems known in cognitive psychology to elicit heuristic errors; the observed drops are therefore diagnostic of heuristic reliance rather than incidental surface effects. The manuscript already includes within-prompt controls (standard vs. disguised vs. misleading-suggestion conditions) and tests both zero-shot and chain-of-thought elicitation. While we do not claim the items exhaust every possible probabilistic task, the pattern across models and conditions supports the qualified conclusion. We will expand the discussion section to articulate this rationale more explicitly but will not alter the central claim. revision: partial
Circularity Check
No circularity: direct empirical measurements with no derivations or self-referential definitions
full rationale
This is a pure benchmarking study that constructs two datasets of probability problems, runs eight LLMs on them under controlled prompting conditions, and reports observed accuracies (0.96 on standard items, 0.59 on counterintuitive items, plus drops under disguise and misleading prompts). No equations, fitted parameters, predictions derived from inputs, uniqueness theorems, or ansatzes appear anywhere in the text. The central claim is an interpretive summary of the measured performance gaps rather than a mathematical reduction; the reported numbers are obtained by direct evaluation and do not loop back to define themselves. Self-citations are absent from the load-bearing steps. The study is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The counterintuitive exercises are designed to trigger heuristic reasoning
Forward citations
Cited by 1 Pith paper
-
Counterintuitive problems in discrete probability
A curated dataset of counterintuitive discrete probability problems with human solutions, built to benchmark LLM reasoning on bias-prone tasks.
Reference graph
Works this paper leans on
-
[1]
Counterintuitive problems in discrete probability
Luca Avena, Gianmarco Bet and Bernardo Busoni. Counterintuitive problems in discrete probability. 2026. arXiv: 2606.07516 [math.PR]. URL: https://arxiv.org/abs/2606.07516
Pith/arXiv arXiv 2026
-
[2]
‘Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs’
Jasper Dekoninck, Nikola Jovanovi´c, Tim Gehrunger, Kári Rögnvaldsson, Ivo Petrov, Chenhao Sun and Martin Vechev. ‘Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs’. In: (2026). arXiv: 2605.00674 [cs.CL]. URL: https://arxiv.org/abs/2605.00674
Pith/arXiv arXiv 2026
-
[3]
MathArena
Jasper Dekoninck, Kári Rögnvaldsson, Chenhao Sun, Ivo Petrov and Martin Vechev.Proof, Not Bluff: LLMs Reach 95% on the 2026 USA Math Olympiad. MathArena. Mar. 2026. URL: https://matharena.ai/usamo/ (visited on 26/05/2026)
2026
-
[4]
A Ramsey-style Problem on Hypergraphs
Epoch AI. A Ramsey-style Problem on Hypergraphs. 2026. URL: https://epoch.ai/frontiermath/open- problems/ramsey-hypergraphs/
2026
-
[5]
Gallegos, Ryan A
Isabel O. Gallegos, Ryan A. Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang and Nesreen K. Ahmed. ‘Bias and Fairness in Large Language Models: A Survey’. In: Computational Linguistics 50.3 (Sept. 2024), pp. 1097–1179. DOI: 10 . 1162 / coli _ a _ 00524. URL: https://direct.mit.edu/coli/article/50/3/1097/121961/Bi...
2024
-
[6]
Aha! Gotcha: Paradoxes to Puzzle and Delight
Martin Gardner. Aha! Gotcha: Paradoxes to Puzzle and Delight. W. H. Freeman, 1982, p. 164. ISBN : 978-0- 7167-1361-6
1982
-
[7]
Time Travel and Other Mathematical Bewilderments
Martin Gardner. Time Travel and Other Mathematical Bewilderments. New York: W. H. Freeman, 1988, p. 295. ISBN : 978-0-7167-1925-0
1988
-
[8]
Bogdan Georgiev, Javier Gómez-Serrano, Terence Tao and Adam Zsolt Wagner.Mathematical exploration and discovery at scale. 2025. arXiv: 2511.02864 [cs.NE]. URL: https://arxiv.org/abs/2511.02864. 9 A PREPRINT - 12 TH JUNE 2026
Pith/arXiv arXiv 2025
-
[9]
Elliot Glazer, Ege Erdil, Tamay Besiroglu, Diego Chicharro, Evan Chen, Alex Gunning, Caroline Falkman Olsson, Jean-Stanislas Denain, Anson Ho, Emily de Oliveira Santos, Olli Järviniemi, Matthew Barnett, Robert Sandler, Matej Vrzala, Jaime Sevilla, Qiuyu Ren, Elizabeth Pratt, Lionel Levine, Grant Barkley, Natalie Stewart, Bogdan Grechuk, Tetiana Grechuk, S...
Pith/arXiv arXiv 2025
-
[10]
Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad
Google DeepMind. Advanced version of Gemini with Deep Think officially achieves gold-medal standard at the International Mathematical Olympiad . https://deepmind.google/blog/advanced- version- of - gemini - with - deep - think - officially - achieves - gold - medal - standard - at - the - international-mathematical-olympiad/. 2025
2025
-
[11]
‘Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT’
Thilo Hagendorff, Sarah Fabi and Michal Kosinski. ‘Human-like intuitive behavior and reasoning biases emerged in large language models but disappeared in ChatGPT’. In:Nature Computational Science 3.10 (2023), pp. 833–
2023
-
[12]
URL: https://doi.org/10.1038/s43588-023-00527-x
DOI: 10.1038/s43588-023-00527-x . URL: https://doi.org/10.1038/s43588-023-00527-x
-
[13]
Bowen Jiang, Yangxinyu Xie, Zhuoqun Hao, Xiaomeng Wang, Tanwi Mallick, Weijie J. Su, Camillo J. Taylor and Dan Roth. A Peek into Token Bias: Large Language Models Are Not Yet Genuine Reasoners. 2024. arXiv: 2406.11050 [cs.CL]. URL: https://arxiv.org/abs/2406.11050
arXiv 2024
-
[14]
Claude’s Cycles
Donald Knuth. Claude’s Cycles. 2026. URL: https://www-cs-faculty.stanford.edu/~knuth/papers/ claude-cycles.pdf
2026
-
[15]
Various probability puzzles posted on Daniel Litt’s X profile @littmath
Daniel Litt. Various probability puzzles posted on Daniel Litt’s X profile @littmath . 2024. URL: https : //x.com/littmath
2024
-
[16]
‘(Ir)rationality and cognitive biases in large language models’
Olivia Macmillan-Scott and Mirco Musolesi. ‘(Ir)rationality and cognitive biases in large language models’. In: Royal Society Open Science 11.6 (June 2024), p. 240255. ISSN : 2054-5703. DOI: 10.1098/rsos.240255. eprint: https://royalsocietypublishing.org/rsos/article- pdf/doi/10.1098/rsos.240255/ 510543/rsos.240255.pdf. URL: https://doi.org/10.1098/rsos.240255
-
[17]
Planar Point Sets with Many Unit Distances
OpenAI. Planar Point Sets with Many Unit Distances. https://cdn.openai.com/pdf/74c24085-19b0- 4534-9c90-465b8e29ad73/unit-distance-proof.pdf . Preprint. May 2026. (Visited on 26/05/2026)
2026
-
[18]
Teoria della probabilità: variabili aleatorie e distribuzioni
Andrea Pascucci. Teoria della probabilità: variabili aleatorie e distribuzioni. Springer, 2020. ISBN : 978-88-470- 3999-5
2020
-
[19]
BrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs
Ivo Petrov, Jasper Dekoninck and Martin Vechev. BrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs. 2025. arXiv: 2510.04721 [cs.AI]. URL: https://arxiv.org/abs/2510.04721
arXiv 2025
-
[20]
Steve Selvin. ‘A Problem in Probability’. In:The American Statistician 29.1 (Feb. 1975). Letter to the editor, p. 67. DOI: 10.1080/00031305.1975.10479121 . URL: https://www.tandfonline.com/doi/abs/10. 1080/00031305.1975.10479121
-
[21]
Bowman, New- ton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, New- ton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang and Ethan Perez. Towards Understanding Sycophancy in Language Models. 2025. arXi...
Pith/arXiv arXiv 2025
-
[22]
Slater, Ali Ziaee and Morgan Nguyen
Gaurav Suri, Lily R. Slater, Ali Ziaee and Morgan Nguyen. Do Large Language Models Show Decision Heuristics Similar to Humans? A Case Study Using GPT-3.5 . 2023. arXiv: 2305 . 04400 [cs.AI]. URL: https://arxiv.org/abs/2305.04400
arXiv 2023
-
[23]
‘Judgment under Uncertainty: Heuristics and Biases’
Amos Tversky and Daniel Kahneman. ‘Judgment under Uncertainty: Heuristics and Biases’. In:Science 185.4157 (Sept. 1974), pp. 1124–1131. DOI: 10.1126/science.185.4157.1124. URL: https://www.science.org/ doi/10.1126/science.185.4157.1124. 10
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.