PASQA: Pitch-Accent-Focused Speech Quality Assessment Model Trained on Synthetic Speech with Accent Errors
Pith reviewed 2026-06-26 15:41 UTC · model grok-4.3
The pith
PASQA trained on synthetic accent errors orders Japanese speech by pitch-accent correctness more accurately than conventional naturalness models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By constructing a controlled Japanese accent-error dataset via an accent-controllable TTS system and deriving pseudo accent-quality scores from accent-error rates, then training on self-supervised representations with mora-conditioned fusion, ranking loss, an auxiliary accent-error localization task, and speaker-invariant training, PASQA achieves high ordering accuracy by accent-error severity for both seen and unseen speakers and stronger agreement with human accent-correctness judgments, whereas conventional MOS models fail to preserve such ordering.
What carries the argument
Mora-conditioned fusion of self-supervised speech representations together with ranking loss and an auxiliary accent-error localization task, trained on pseudo scores computed from controlled synthetic accent errors.
If this is right
- Conventional MOS prediction models fail to preserve the ordering of utterances according to accent-error severity.
- PASQA maintains high ordering accuracy by accent-error severity on both seen and unseen speakers.
- PASQA exhibits stronger agreement with human judgments of accent correctness than standard models.
- Training on synthetic data with deliberately introduced accent errors enables learning of accent quality without large-scale human annotations of real errors.
- Speaker-invariant training supports generalization of accent-quality predictions to new speakers.
Where Pith is reading between the lines
- The same synthetic-error construction and ranking approach could be adapted to train detectors for other localized prosodic features such as intonation patterns.
- Embedding PASQA into a TTS pipeline would allow direct optimization of accent correctness during synthesis rather than relying only on overall naturalness scores.
- Pseudo-labeling from error rates offers a scalable template for creating training data on other fine-grained speech defects that are hard to annotate at scale.
Load-bearing premise
The pseudo accent-quality score computed from the accent-error rate in the synthetic dataset accurately reflects human perception of accent correctness.
What would settle it
Human listeners rate accent correctness on the same set of utterances with varying accent errors; check whether PASQA's scores preserve the same severity ordering as the human ratings while conventional models do not.
Figures
read the original abstract
Existing mean opinion score (MOS) prediction models typically predict utterance-level naturalness MOS and can be insensitive to localized pitch-accent errors. We propose Pitch-Accent-focused Speech Quality Assessment (PASQA), which explicitly targets pitch-accent correctness. To train our model, we construct a controlled Japanese accent-error dataset by changing accent patterns using an accent-controllable text-to-speech system, and compute a pseudo accent-quality score from the accent-error rate. PASQA builds on self-supervised representations and employs mora-conditioned fusion, ranking loss, an auxiliary accent-error localization task, and speaker-invariant training. Experiments show that conventional models fail to preserve the ordering by accent-error severity, whereas PASQA achieves high ordering accuracy on both seen and unseen speakers. Further, PASQA shows stronger agreement with human accent-correctness judgments. The code is available at https://github.com/lycorp-jp/PASQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PASQA, a pitch-accent-focused speech quality assessment model for Japanese speech. It constructs a synthetic dataset using an accent-controllable TTS system to introduce controlled accent errors, derives pseudo accent-quality scores from accent-error rates, and trains a model on self-supervised representations with mora-conditioned fusion, a ranking loss, an auxiliary accent-error localization task, and speaker-invariant training. Experiments claim that conventional MOS models fail to preserve ordering by accent-error severity, while PASQA achieves high ordering accuracy on seen and unseen speakers and stronger agreement with human accent-correctness judgments. Code is released at the provided GitHub repository.
Significance. If the central results hold, PASQA would address a recognized limitation of utterance-level MOS predictors by explicitly targeting localized pitch-accent errors, which is relevant for pitch-accent languages. The explicit use of ranking loss and auxiliary localization, combined with public code release, supports reproducibility and potential extension to other languages or error types. The separation of synthetic training labels from a distinct human evaluation set provides some independent grounding, though the strength depends on details of the human protocol and quantitative outcomes.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: The central claims of 'high ordering accuracy' and 'stronger agreement with human accent-correctness judgments' are presented without any reported quantitative metrics, dataset sizes, listener counts, error bars, or statistical tests. This absence makes it impossible to evaluate the magnitude or reliability of the reported improvements over conventional models.
- [Dataset construction] Dataset construction (pseudo-score definition): The training targets are pseudo accent-quality scores computed directly from the controlled accent-error rate in the synthetic TTS data. No analysis, correlation study, or ablation is provided to establish that this error-rate proxy aligns with human perception of pitch-accent correctness rather than TTS-specific artifacts or mora-level distortions; this assumption is load-bearing for both the ranking loss and the auxiliary localization task.
minor comments (2)
- [Abstract] The abstract mentions 'mora-conditioned fusion' and 'speaker-invariant training' without a brief definition or pointer to the relevant subsection, which would aid readers unfamiliar with the architecture.
- [Abstract] No mention of the number of speakers, utterances, or accent patterns in the synthetic dataset appears in the provided abstract, which would help contextualize the ordering results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Experiments section] Abstract and Experiments section: The central claims of 'high ordering accuracy' and 'stronger agreement with human accent-correctness judgments' are presented without any reported quantitative metrics, dataset sizes, listener counts, error bars, or statistical tests. This absence makes it impossible to evaluate the magnitude or reliability of the reported improvements over conventional models.
Authors: The Experiments section reports specific quantitative results on ordering accuracy for seen and unseen speakers, correlations with human judgments, dataset sizes for the synthetic training data and human evaluation set, listener counts, and statistical comparisons against baseline MOS models. We agree, however, that the abstract would be strengthened by including key numerical results. We will revise the abstract to report the main quantitative findings (ordering accuracy, human agreement metrics) along with dataset and listener details, and we will ensure the Experiments section explicitly ties all claims to the reported values, error bars, and tests. revision: yes
-
Referee: [Dataset construction] Dataset construction (pseudo-score definition): The training targets are pseudo accent-quality scores computed directly from the controlled accent-error rate in the synthetic TTS data. No analysis, correlation study, or ablation is provided to establish that this error-rate proxy aligns with human perception of pitch-accent correctness rather than TTS-specific artifacts or mora-level distortions; this assumption is load-bearing for both the ranking loss and the auxiliary localization task.
Authors: The pseudo-scores are generated from controlled accent-pattern modifications in an accent-controllable TTS system, providing precise error-rate labels by design. The model is then validated on an independent human evaluation set using accent-correctness judgments, which serves as the primary check against perceptual validity. We will add a dedicated paragraph in the Dataset Construction section explaining the rationale for the proxy (controlled synthesis minimizes uncontrolled TTS artifacts) and referencing the human evaluation protocol as external grounding. No new correlation study between pseudo-scores and human ratings on the training data is feasible without additional annotation, but the separation of synthetic training from human test data directly addresses the concern about TTS-specific artifacts. revision: partial
Circularity Check
No significant circularity; claims rest on independent human judgments
full rationale
The paper constructs synthetic data with controlled accent errors, derives pseudo accent-quality scores directly from accent-error rates for training targets (ranking loss and localization task), and reports high ordering accuracy on held-out synthetic data plus stronger agreement with separate human accent-correctness judgments. No equations, self-citations, or definitions are provided that reduce the reported ordering accuracy or human agreement metrics to the pseudo-score inputs by construction. The human evaluation supplies external grounding independent of the synthetic error-rate proxy. This is a standard self-contained setup against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-supervised speech representations contain sufficient information to distinguish pitch-accent correctness
- domain assumption Accent-error rate in synthetic speech is a suitable proxy for perceptual accent quality
Reference graph
Works this paper leans on
-
[1]
hashi,” which means “chopsticks
Introduction Recent deep neural network (DNN)-based text-to-speech (TTS) systems can generate highly natural speech [1, 2, 3]. The qual- ity of synthesized speech has conventionally been assessed us- ing subjective listening tests, particularly Mean Opinion Score (MOS) evaluations by human raters, which provide accurate assessments. However, such evaluati...
-
[2]
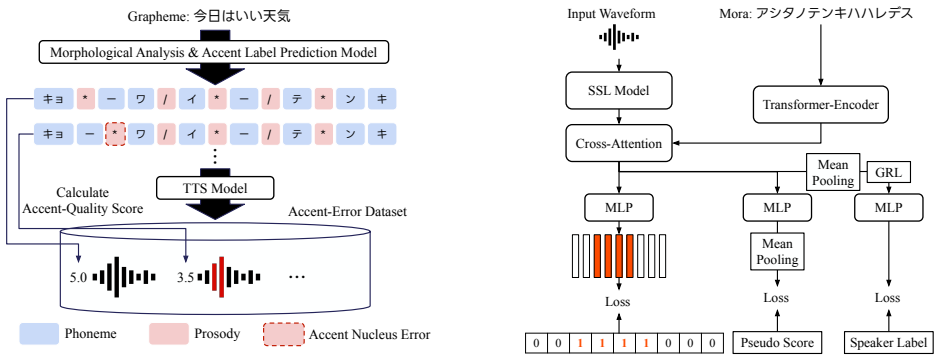
Proposed method 2.1. Accent-error dataset To develop a model that reflects accent errors in its predicted accent-quality scores, we constructed a Japanese speech dataset that includes accent errors. Figure 1 shows the overall pipeline for constructing the accent error dataset. In the figure, “/” denotes accent phrase boundaries, which segment an utter- an...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Experimental evaluation 3.1. Experimental setup Dataset preparation.We generate synthetic Japanese speech with controlled pitch-accent errors using NANSY-TTS [21]. The TTS model was trained on an internal Japanese corpus consisting of 173,987 samples with manually-annotated phone- mic and prosodic labels, totaling 207.96 hours. This corpus in- cluded 17 s...
-
[4]
Using a controllable TTS system, we con- structed a scalable accent-error dataset without manual annota- tion
Conclusion We proposed PASQA, a pitch-accent-focused speech quality as- sessment model. Using a controllable TTS system, we con- structed a scalable accent-error dataset without manual annota- tion. Built on SSL-based acoustic representations, PASQA im- proves accent-quality assessment and outperforms conventional MOS models. In listening tests, it also s...
-
[5]
All (co-)authors have reviewed the final version and are fully responsible and accountable for the scientific con- tent, experimental design, results, and conclusions
Generative AI Use Disclosure In accordance with ISCA policy, generative AI tools were used solely for English language editing and polishing of the manuscript. All (co-)authors have reviewed the final version and are fully responsible and accountable for the scientific con- tent, experimental design, results, and conclusions
-
[6]
NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X.-Y . Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models,” in Proc. ICML, 2024
2024
-
[7]
Vall-e 2: Neural codec language models are hu- man parity zero-shot text to speech synthesizers,
S. Chen, S. Liu, L. Zhou, Y . Liu, X. Tan, J. Li, S. Zhao, Y . Qian, and F. Wei, “V ALL-E 2: Neural codec language models are hu- man parity zero-shot text to speech synthesizers,”arXiv preprint arXiv:2406.05370, 2024
-
[8]
V oicebox: Text-guided multilingual universal speech gen- eration at scale,
M. Le, A. Vyas, B. Shi, B. Karrer, L. Sari, R. Moritz, M. Williamson, V . Manohar, Y . Adi, J. Mahadeokar, and W.-N. Hsu, “V oicebox: Text-guided multilingual universal speech gen- eration at scale,” inProc. NeurIPS, vol. 36, 2023, pp. 14 005– 14 034
2023
-
[9]
A review on subjective and objective evaluation of syn- thetic speech,
E. Cooper, W.-C. Huang, Y . Tsao, H.-M. Wang, T. Toda, and J. Ya- magishi, “A review on subjective and objective evaluation of syn- thetic speech,”Acoustical Science and Technology, vol. 45, no. 4, pp. 161–183, 2024
2024
-
[10]
AutoMOS: Learning a non-intrusive as- sessor of naturalness-of-speech,
B. Patton, Y . Agiomyrgiannakis, M. Terry, K. Wilson, R. A. Saurous, and D. Sculley, “AutoMOS: Learning a non-intrusive as- sessor of naturalness-of-speech,” inProc. NeurIPS 2016 End-to- end Learning for Speech and Audio Processing Workshop, 2016
2016
-
[11]
UTMOS: UTokyo-sarulab system for V oiceMOS challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-sarulab system for V oiceMOS challenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
2022
-
[12]
DNSMOS: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,” inProc. ICASSP, 2021, pp. 6493–6497
2021
-
[13]
Recognition of spoken words with mis- pronounced lexical prosody in Japanese,
T. Ariga and Y . Hirose, “Recognition of spoken words with mis- pronounced lexical prosody in Japanese,”J. Acoust. Soc. Am., vol. 157, no. 6, p. 4102–4118, 2025
2025
-
[14]
Pitch accent in spoken-word recognition in Japanese,
A. Cutler and T. Otake, “Pitch accent in spoken-word recognition in Japanese,”J. Acoust. Soc. Am., vol. 105, no. 3, p. 1877–1888, 1999
1999
-
[15]
Towards frame-level quality predictions of synthetic speech,
M. Kuhlmann, F. Seebauer, P. Wagner, and R. Haeb-Umbach, “Towards frame-level quality predictions of synthetic speech,” in Proc. Interspeech, 2025, pp. 2300–2304
2025
-
[16]
A unified accent esti- mation method based on multi-task learning for Japanese text-to- speech,
B. Park, R. Yamamoto, and K. Tachibana, “A unified accent esti- mation method based on multi-task learning for Japanese text-to- speech,” inProc. Interspeech, 2022, pp. 1931–1935
2022
-
[17]
Audio- conditioned phonemic and prosodic annotation for building text- to-speech models from unlabeled speech data,
Y . Shirahata, B. Park, R. Yamamoto, and K. Tachibana, “Audio- conditioned phonemic and prosodic annotation for building text- to-speech models from unlabeled speech data,” inProc. Inter- speech, 2024, pp. 2795–2799
2024
-
[18]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Z. Du, Y . Wang, Q. Chen, X. Shi, X. Lv, T. Zhao, Z. Gao, Y . Yang, C. Gao, H. Wanget al., “CosyV oice 2: Scalable stream- ing speech synthesis with large language models,”arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,
Y . Chen, Z. Niu, Z. Ma, K. Deng, C. Wang, J. Zhao, K. Yu, and X. Chen, “F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching,” inProc. ACL, 2025, pp. 6255–6271
2025
-
[20]
Generaliza- tion ability of mos prediction networks,
E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generaliza- tion ability of mos prediction networks,” inProc. ICASSP, 2022, pp. 8442–8446
2022
-
[21]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inProc. NeurIPS, vol. 33, 2020, pp. 12 449–12 460
2020
-
[22]
Domain adversarial for acoustic emotion recognition,
M. Abdelwahab and C. Busso, “Domain adversarial for acoustic emotion recognition,”IEEE/ACM Trans. on Audio, Speech, and Lang. Process., vol. 26, no. 12, pp. 2423–2435, 2018
2018
-
[23]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. u. Kaiser, and I. Polosukhin, “Attention is all you need,” inProc. NeurIPS, vol. 30, 2017
2017
-
[24]
Rank analysis of incomplete block designs: I. the method of paired comparisons,
R. A. Bradley and M. E. Terry, “Rank analysis of incomplete block designs: I. the method of paired comparisons,”Biometrika, vol. 39, no. 3/4, pp. 324–345, 1952
1952
-
[25]
Disentanglement of prosody representations via diffusion mod- els and scheduled gradient reversal,
L. Qu, C. Weber, W. Wang, J. Jin, Y . Gao, T. Li, and S. Wermter, “Disentanglement of prosody representations via diffusion mod- els and scheduled gradient reversal,”IEEE Trans. Neural Netw. Learn. Syst., vol. 36, no. 8, pp. 15 043–15 054, 2025
2025
-
[26]
NANSY++: Unified voice synthesis with neural analysis and synthesis,
H.-S. Choi, J. Yang, J. Lee, and H. Kim, “NANSY++: Unified voice synthesis with neural analysis and synthesis,” inProc. ICLR, 2023
2023
-
[27]
Applying condi- tional random fields to Japanese morphological analysis,
T. Kudo, K. Yamamoto, and Y . Matsumoto, “Applying condi- tional random fields to Japanese morphological analysis,” inProc. EMNLP, 2004, pp. 230–237
2004
-
[28]
RoFormer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: Enhanced transformer with rotary position embedding,”Neuro- computing, vol. 568, p. 127063, 2024
2024
-
[29]
DNSMOS P.835: A non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS P.835: A non-intrusive perceptual objective speech quality metric to evalu- ate noise suppressors,” inProc. ICASSP, 2022, pp. 886–890
2022
-
[30]
An open source implementation of ITU- T recommendation P.808 with validation,
B. Naderi and R. Cutler, “An open source implementation of ITU- T recommendation P.808 with validation,” inProc. Interspeech, 2020, pp. 2862–2866
2020
-
[31]
NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,
G. Mittag, B. Naderi, A. Chehadi, and S. M ¨oller, “NISQA: A deep CNN-self-attention model for multidimensional speech quality prediction with crowdsourced datasets,” inProc. Inter- speech, 2021, pp. 2127–2131
2021
-
[32]
The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,
K. Baba, W. Nakata, Y . Saito, and H. Saruwatari, “The T05 system for the V oiceMOS challenge 2024: Transfer learning from deep image classifier to naturalness MOS prediction of high-quality synthetic speech,” inProc. SLT, 2024, pp. 818–824
2024
-
[33]
SHEET: A multi-purpose open-source speech human evaluation estimation toolkit,
W.-C. Huang, E. Cooper, and T. Toda, “SHEET: A multi-purpose open-source speech human evaluation estimation toolkit,” inProc. Interspeech, 2025, pp. 2355–2359
2025
-
[34]
MOS-Bench: Benchmarking Generalization Abilities of Subjective Speech Quality Assessment Models
——, “MOS-Bench: Benchmarking generalization abilities of subjective speech quality assessment models,”arXiv preprint arXiv:2411.03715, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
VERSA: A versatile evaluation toolkit for speech, audio, and music,
J. Shi, H.-j. Shim, J. Tian, S. Arora, H. Wu, D. Petermann, J. Q. Yip, Y . Zhang, Y . Tang, W. Zhang, D. S. Alharthi, Y . Huang, K. Saito, J. Han, Y . Zhao, C. Donahue, and S. Watanabe, “VERSA: A versatile evaluation toolkit for speech, audio, and music,” inProc. NAACL-HLT (System Demonstrations), 2025, pp. 191–209
2025
-
[36]
ESPnet-Codec: Comprehensive training and eval- uation of neural codecs for audio, music, and speech,
J. Shi, J. Tian, Y . Wu, J.-W. Jung, J. Q. Yip, Y . Masuyama, W. Chen, Y . Wu, Y . Tang, M. Baali, D. Alharthi, D. Zhang, R. Deng, T. Srivastava, H. Wu, A. Liu, B. Raj, Q. Jin, R. Song, and S. Watanabe, “ESPnet-Codec: Comprehensive training and eval- uation of neural codecs for audio, music, and speech,” inProc. SLT, 2024, pp. 562–569
2024
-
[37]
WORLD: A vocoder- based high-quality speech synthesis system for real-time applica- tions,
M. Morise, F. Yokomori, and K. Ozawa, “WORLD: A vocoder- based high-quality speech synthesis system for real-time applica- tions,”IEICE Trans. Inf. Syst., vol. E99-D, no. 7, pp. 1877–1884, 2016
2016
-
[38]
Introducing next-generation audio models in the API,
OpenAI, “Introducing next-generation audio models in the API,” 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.