Exploiting Neural Audio Codec Latents for Adversarial Audio Attacks
Pith reviewed 2026-06-26 15:32 UTC · model grok-4.3
The pith
A conditional generator in neural audio codec latent space produces targeted adversarial waveforms in one pass at under 7 ms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that training a conditional generator to output perturbations in the latent space of a neural audio codec, followed by decoding, yields adversarial audio with targeted success rates up to 99 percent and sub-7 ms inference time, outperforming generative baselines by a latency reduction of 24 times.
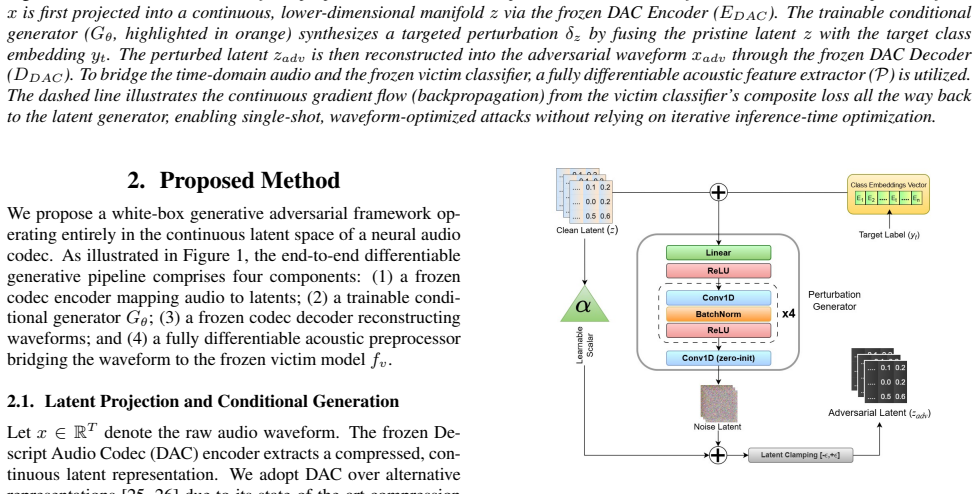
What carries the argument
The conditional generator that produces class-specific perturbations in the continuous latent space of a fixed neural audio codec, which are decoded into adversarial waveforms.
If this is right
- Targeted attacks on automatic speaker verification become feasible in real time without iterative optimization.
- Generative attacks can operate at 24 times lower latency than diffusion or autoregressive alternatives while matching or exceeding their success rates.
- Adversarial synthesis avoids the computational burden of high-dimensional waveform-space updates.
- The approach supports single-shot generation of class-conditional perturbations that remain effective after decoding.
Where Pith is reading between the lines
- The same latent-space generator could be tested on black-box classifiers to check whether the codec representation improves transferability.
- Varying the underlying neural audio codec might change attack strength or artifact levels and could be measured directly.
- The method implies that other audio tasks using codec latents might also admit fast generative attacks if similar conditional training is applied.
Load-bearing premise
Perturbations created in the codec latent space will decode into waveforms that transfer their targeted attack power to the downstream classifier without perceptible artifacts.
What would settle it
Measure whether the decoded adversarial examples retain at least 90 percent targeted success rate when the target classifier is evaluated on the exact output of the codec decoder.
Figures

read the original abstract
Deep learning-based audio classification systems, including automatic speaker verification, are vulnerable to adversarial attacks. Realistic real-time threat assessment remains difficult because optimization-based methods, such as projected gradient descent (PGD) and Carlini-Wagner, require costly iterative updates in the high-dimensional waveform domain. Generative attacks allow single-shot synthesis but often introduce perceptible artifacts or depend on computationally intensive architectures, while diffusion and autoregressive approaches incur high inference latency. To address this gap, we propose a generative attack framework operating in the continuous latent space of a neural audio codec. A conditional generator synthesizes class-specific perturbations in a single forward pass and decodes them into adversarial waveforms. Our method achieves targeted attack success rates up to 99% with sub-7 ms inference, outperforming generative baselines while reducing latency by 24x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a generative adversarial attack framework for audio classifiers that synthesizes class-specific perturbations directly in the continuous latent space of a fixed neural audio codec via a conditional generator. These perturbations are decoded into waveforms in a single forward pass. The central empirical claim is that the approach attains targeted attack success rates up to 99% with sub-7 ms inference time while outperforming generative baselines and reducing latency by a factor of 24 relative to optimization-based methods such as PGD.
Significance. If the performance claims can be substantiated with reproducible experiments, the work would provide a practical route to low-latency, single-shot adversarial attacks on audio systems such as speaker verification. The use of neural-codec latents for perturbation generation is a technically interesting direction that could reduce the computational burden of real-time threat assessment.
major comments (2)
- [Abstract] Abstract: the performance numbers (99% targeted success, sub-7 ms inference, 24x latency reduction) are stated without any description of datasets, target models, generator training procedure (including loss functions or whether gradients flow through the decoder to the classifier), baselines, or validation protocol. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the results support the method.
- [Abstract] Abstract: the method description does not specify how the conditional generator is trained or whether a surrogate classifier loss is used. Consequently it is impossible to determine whether latent-space perturbations survive decoding to produce targeted adversarial waveforms, which is the key assumption underlying the reported success rates.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the specific neural audio codec employed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that additional context is required to support the reported performance claims and will revise the abstract to include the missing details on datasets, models, training, and protocol while preserving conciseness. The body of the manuscript already contains these elements in Sections 3 and 4.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance numbers (99% targeted success, sub-7 ms inference, 24x latency reduction) are stated without any description of datasets, target models, generator training procedure (including loss functions or whether gradients flow through the decoder to the classifier), baselines, or validation protocol. This absence is load-bearing for the central empirical claim and prevents any assessment of whether the results support the method.
Authors: We acknowledge the validity of this point. The abstract is overly concise and omits essential experimental context. In the revised manuscript we will expand the abstract to briefly specify the datasets (e.g., LibriSpeech for speaker verification), target models, generator training procedure including loss functions and gradient flow through the fixed decoder, baselines, and validation protocol. This will make the central claims evaluable directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract: the method description does not specify how the conditional generator is trained or whether a surrogate classifier loss is used. Consequently it is impossible to determine whether latent-space perturbations survive decoding to produce targeted adversarial waveforms, which is the key assumption underlying the reported success rates.
Authors: We will revise the abstract to state that the conditional generator is trained using a surrogate classifier loss, with gradients flowing through the fixed decoder to the classifier. This training ensures latent perturbations remain effective after decoding, which is confirmed by the reported targeted success rates. The full training objective and architecture are detailed in the methods section. revision: yes
Circularity Check
No circularity: empirical performance claim with no derivations or self-referential reductions
full rationale
The paper presents a generative adversarial attack method operating in neural audio codec latent space, with the central claim being an empirical result (targeted success rates up to 99% at sub-7 ms inference). No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described content. The method is described as a proposed framework whose validity rests on experimental outcomes rather than any internal chain that reduces to its own inputs by construction. This is the most common honest finding for purely empirical papers without mathematical derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Advances in speech and audio processing have enabled the large-scale deployment of intelligent audio systems, rang- ing from automatic speaker verification (ASV) and biomet- ric authentication [1, 2, 3] to environmental sound classifica- tion [4], acoustic scene analysis [5, 6], and sound event detec- tion [7]. These technologies are now deep...
Pith/arXiv arXiv 2026
-
[2]
Proposed Method We propose a white-box generative adversarial framework op- erating entirely in the continuous latent space of a neural audio codec. As illustrated in Figure 1, the end-to-end differentiable generative pipeline comprises four components: (1) a frozen codec encoder mapping audio to latents; (2) a trainable condi- tional generatorG θ; (3) a ...
-
[3]
Google Speech Com- mands [27] contains35one-second spoken words at16kHz (80,000 train / 4,273 test)
Experimental Protocol Datasets: We evaluate our adversarial attack generator on four benchmark datasets spanning speech commands [27], acous- tic scene classification [28], environmental sound classifica- tion [29], and speaker verification [30]. Google Speech Com- mands [27] contains35one-second spoken words at16kHz (80,000 train / 4,273 test). TAU Urban...
2019
-
[4]
Results and Discussion Untargeted (%) Targeted (%) Time (sec) MethodAcc ASR Acc ASR (1 sample) FGSM 91.12 8.88 93.46 3.63 0.9511 PGD 54.35 45.65 85.81 12.63 2.4880 CW 22.40 77.60 32.69 66.22 13.2731 FAPG 18.92 82.08 3.53 80.77 0.0153 CGAN 5.15 93.72 6.4293.560.0158 Ours 3.42 96.58 3.3277.650.0067 Table 1:Performance Comparison under Untargeted and Tar- ge...
-
[5]
Prior generative approaches reduce optimiza- tion cost but remain waveform-bound, task-specific, or lack tar- geted control
Conclusion The widespread deployment of streaming and on-device audio systems demands rigorous evaluation against real-time adver- sarial threats. Prior generative approaches reduce optimiza- tion cost but remain waveform-bound, task-specific, or lack tar- geted control. We introduce an end-to-end differentiable frame- work that generates adversarial exam...
-
[6]
The research conception, methodology, experimental design, imple- mentation, results, and analysis were entirely conducted by the authors
Generative AI Use Disclosure Generative AI tools were used solely for language refinement, clarity improvement, and minor formatting adjustments. The research conception, methodology, experimental design, imple- mentation, results, and analysis were entirely conducted by the authors. All AI-assisted edits were carefully reviewed, vali- dated, and approved...
-
[7]
Deep speaker: an end-to-end neural speaker embedding system,
C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kan- nan, and Z. Zhu, “Deep speaker: an end-to-end neural speaker embedding system,”arXiv preprint arXiv:1705.02304, 2017
Pith/arXiv arXiv 2017
-
[8]
Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,
X. Xiang, S. Wang, H. Huang, Y . Qian, and K. Yu, “Margin mat- ters: Towards more discriminative deep neural network embed- dings for speaker recognition,” in2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC). IEEE, 2019, pp. 1652–1656
2019
-
[9]
ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,” inProc. Interspeech 2020, 2020, pp. 3830–3834
2020
-
[10]
Learning from between- class examples for deep sound recognition,
Y . Tokozume, Y . Ushiku, and T. Harada, “Learning from between- class examples for deep sound recognition,”arXiv preprint arXiv:1711.10282, 2017
Pith/arXiv arXiv 2017
-
[11]
Acoustic scene classification: Classifying environments from the sounds they produce,
D. Barchiesi, D. Giannoulis, D. Stowell, and M. D. Plumbley, “Acoustic scene classification: Classifying environments from the sounds they produce,”IEEE Signal Processing Magazine, vol. 32, no. 3, pp. 16–34, 2015
2015
-
[12]
Acoustic scene classification: A comprehensive survey,
B. Ding, T. Zhang, C. Wang, G. Liu, J. Liang, R. Hu, Y . Wu, and D. Guo, “Acoustic scene classification: A comprehensive survey,” Expert Systems with Applications, vol. 238, p. 121902, 2024
2024
-
[13]
Polyphonic sound event detection using multi label deep neural networks,
E. Cakir, T. Heittola, H. Huttunen, and T. Virtanen, “Polyphonic sound event detection using multi label deep neural networks,” in 2015 international joint conference on neural networks (IJCNN). IEEE, 2015, pp. 1–7
2015
-
[14]
Smart home per- sonal assistants: a security and privacy review,
J. S. Edu, J. M. Such, and G. Suarez-Tangil, “Smart home per- sonal assistants: a security and privacy review,”ACM Computing Surveys (CSUR), vol. 53, no. 6, pp. 1–36, 2020
2020
-
[15]
Privacy and smart speakers: A multi- dimensional approach,
C. Lutz and G. Newlands, “Privacy and smart speakers: A multi- dimensional approach,”The Information Society, vol. 37, no. 3, pp. 147–162, 2021
2021
-
[16]
The interspeech 2016 computational paralinguistics challenge: Decep- tion, sincerity & native language,
B. Schuller, S. Steidl, A. Batliner, J. Hirschberg, J. K. Burgoon, A. Baird, A. Elkins, Y . Zhang, E. Coutinho, and K. Evanini, “The interspeech 2016 computational paralinguistics challenge: Decep- tion, sincerity & native language,” inProceedings of the Annual Conference of the International Speech Communication Associa- tion Interspeech, vol. 8. ISCA, 2...
2016
-
[17]
Explaining and har- nessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and har- nessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
Pith/arXiv arXiv 2014
-
[18]
Adversarial attacks against face recognition: A comprehensive study,
F. Vakhshiteh, A. Nickabadi, and R. Ramachandra, “Adversarial attacks against face recognition: A comprehensive study,”IEEE Access, vol. 9, pp. 92 735–92 756, 2021
2021
-
[19]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv preprint arXiv:1706.06083, 2017
Pith/arXiv arXiv 2017
-
[20]
Audio adversarial examples: Targeted attacks on speech-to-text,
N. Carlini and D. Wagner, “Audio adversarial examples: Targeted attacks on speech-to-text,” in2018 IEEE security and privacy workshops (SPW). IEEE, 2018, pp. 1–7
2018
-
[21]
A robust ap- proach for securing audio classification against adversarial at- tacks,
M. Esmaeilpour, P. Cardinal, and A. L. Koerich, “A robust ap- proach for securing audio classification against adversarial at- tacks,”IEEE Transactions on information forensics and security, vol. 15, pp. 2147–2159, 2019
2019
-
[22]
Sirenattack: Generating adversarial audio for end-to-end acoustic systems,
T. Du, S. Ji, J. Li, Q. Gu, T. Wang, and R. Beyah, “Sirenattack: Generating adversarial audio for end-to-end acoustic systems,” in Proceedings of the 15th ACM Asia conference on computer and communications security, 2020, pp. 357–369
2020
-
[23]
A unified framework for detect- ing audio adversarial examples,
X. Du, C.-M. Pun, and Z. Zhang, “A unified framework for detect- ing audio adversarial examples,” inProceedings of the 28th ACM International Conference on Multimedia, 2020, pp. 3986–3994
2020
-
[24]
Enabling fast and universal audio adversarial attack using generative model,
Y . Xie, Z. Li, C. Shi, J. Liu, Y . Chen, and B. Yuan, “Enabling fast and universal audio adversarial attack using generative model,” inProceedings of the AAAI conference on artificial intelligence, vol. 35, no. 16, 2021, pp. 14 129–14 137
2021
-
[25]
Fast speech adversarial example generation for keyword spotting system with conditional gan,
D. Wang, L. Dong, R. Wang, and D. Yan, “Fast speech adversarial example generation for keyword spotting system with conditional gan,”Computer Communications, vol. 179, pp. 145–156, 2021
2021
-
[26]
Unrestricted adversarial examples,
T. B. Brown, N. Carlini, C. Zhang, C. Olsson, P. Christiano, and I. Goodfellow, “Unrestricted adversarial examples,”arXiv preprint arXiv:1809.08352, 2018
Pith/arXiv arXiv 2018
-
[27]
Synthesis- ing audio adversarial examples for automatic speech recognition,
X. Qu, P. Wei, M. Gao, Z. Sun, Y . S. Ong, and Z. Ma, “Synthesis- ing audio adversarial examples for automatic speech recognition,” inProceedings of the 28th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining, 2022, pp. 1430–1440
2022
-
[28]
Diffusion-based adversarial attack to automatic speech recognition,
Y . Wang, Y . Luo, S. Fu, Z. Qiu, and L. Liu, “Diffusion-based adversarial attack to automatic speech recognition,” inThe 16th Asian Conference on Machine Learning (Conference Track), 2024
2024
-
[29]
R. Ziv, R. Lapid, and M. Sipper, “Breaking audio large language models by attacking only the encoder: A universal targeted latent- space audio attack,”arXiv preprint arXiv:2512.23881, 2025
arXiv 2025
-
[30]
High-fidelity audio compression with improved rvqgan,
R. Kumar, P. Seetharaman, A. Luebs, I. Kumar, and K. Kumar, “High-fidelity audio compression with improved rvqgan,”Ad- vances in Neural Information Processing Systems, vol. 36, pp. 27 980–27 993, 2023
2023
-
[31]
High fidelity neural audio compression,
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv preprint arXiv:2210.13438, 2022
Pith/arXiv arXiv 2022
-
[32]
Soundstream: An end-to-end neural audio codec,
N. Zeghidour, A. Luebs, A. Omran, J. Skoglund, and M. Tagliasacchi, “Soundstream: An end-to-end neural audio codec,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 30, pp. 495–507, 2021
2021
-
[33]
Speech commands: A dataset for limited-vocabulary speech recognition,
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition,”arXiv preprint arXiv:1804.03209, 2018
Pith/arXiv arXiv 2018
-
[34]
A multi-device dataset for urban acoustic scene classification,
A. Mesaros, T. Heittola, and T. Virtanen, “A multi-device dataset for urban acoustic scene classification,”arXiv preprint arXiv:1807.09840, 2018
Pith/arXiv arXiv 2018
-
[35]
A dataset and taxonomy for urban sound research,
J. Salamon, C. Jacoby, and J. P. Bello, “A dataset and taxonomy for urban sound research,” in22nd ACM International Conference on Multimedia (ACM-MM’14), Orlando, FL, USA, Nov. 2014
2014
-
[36]
Lib- rispeech: an ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[37]
Wave-u-net: A multi-scale neural network for end-to-end audio source separation,
D. Stoller, S. Ewert, and S. Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,”arXiv preprint arXiv:1806.03185, 2018
Pith/arXiv arXiv 2018
-
[38]
Banach wasserstein gan,
J. Adler and S. Lunz, “Banach wasserstein gan,”Advances in neu- ral information processing systems, vol. 31, 2018
2018
-
[39]
Ast: Audio spectrogram transformer,
Y . Gong, Y .-A. Chung, and J. Glass, “Ast: Audio spectrogram transformer,”arXiv preprint arXiv:2104.01778, 2021
arXiv 2021
-
[40]
Panns: Large-scale pretrained audio neural networks for audio pattern recognition,
Q. Kong, Y . Cao, T. Iqbal, Y . Wang, W. Wang, and M. D. Plumb- ley, “Panns: Large-scale pretrained audio neural networks for audio pattern recognition,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2880–2894, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.