Speaker Identity in Non-Verbal Vocalizations: Conditional Distillation and Mixture of Experts Approach
Pith reviewed 2026-06-26 13:25 UTC · model grok-4.3
The pith
A Mixture of Experts module with conditional distillation reduces speaker verification error on non-verbal vocalizations from 38.93% to 22.66% EER while also lowering speech EER from 13.17% to 9.24%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a frozen Data2Vec front-end feeding an ECAPA-TDNN, augmented by a Mixture of Experts layer with learned domain-aware routing, plus a conditional distillation loss on speech and a contrastive loss across domains, simultaneously improves cross-domain verification and protects in-domain speech accuracy. On the tested data this yields the measured drops in equal error rate for both speech-NVV pairs and speech alone.
What carries the argument
Mixture of Experts module with learned domain-aware routing, used together with a conditional distillation loss applied only to speech inputs.
If this is right
- A single model can now verify speaker identity for both spoken words and non-verbal sounds without separate training runs.
- Adapting to NVVs no longer requires trading away speech verification accuracy.
- Expressive TTS and voice conversion outputs can be checked for identity consistency across verbal and non-verbal segments with one system.
- The same routing and loss combination works across all ten NVV categories examined without per-category models.
Where Pith is reading between the lines
- The routing mechanism could be tested on other audio domain shifts such as accented speech or noisy environments to see whether the same gains appear.
- Adding more NVV categories beyond the original ten would provide a direct check on whether the reported generalization holds.
- The framework could be inserted into existing TTS evaluation pipelines to enforce identity consistency as a standard metric.
Load-bearing premise
The domain-aware routing learned inside the Mixture of Experts and the contrastive alignment will continue to work on NVV types and acoustic conditions different from the ten types used in training.
What would settle it
Running the trained model on a fresh collection of non-verbal vocalization recordings made under different acoustic conditions and measuring whether the speech-NVV EER remains at or below 22.66%.
Figures


read the original abstract
As expressive text-to-speech (TTS) and voice conversion (VC) systems increasingly generate non-verbal vocalizations (NVVs) to enhance naturalness, reliable speaker verification (SV) becomes essential to objectively assess identity consistency across both verbal and non-verbal segments. Yet current SV systems generalize poorly to NVVs, and fine-tuning on NVV data causes catastrophic forgetting of speech performance. We present the first systematic study across 10 NVV types and propose a framework combining frozen Data2Vec self-supervised features with ECAPA-TDNN, enhanced by a Mixture of Experts (MoE) module with learned domain-aware routing. A conditional distillation loss on speech inputs via a pretrained teacher retains speech-to-speech accuracy, while a contrastive loss bridges the speech-NVV domain gap. Our method reduces speech-NVV EER from 38.93% to 22.66% over a pretrained baseline, and improves speech EER from 13.17% to 9.24% via distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the first systematic study of speaker verification across 10 NVV types. It proposes a framework that combines frozen Data2Vec features with an ECAPA-TDNN backbone, augmented by a Mixture of Experts module employing learned domain-aware routing, a conditional distillation loss from a pretrained teacher on speech inputs, and a contrastive loss to bridge the speech-NVV domain gap. The central empirical claims are EER reductions from 38.93% to 22.66% on speech-NVV and from 13.17% to 9.24% on speech.
Significance. If the reported gains prove robust, the work would be significant for speaker verification in expressive TTS and voice conversion pipelines, where reliable identity consistency across verbal and non-verbal segments is required. The combination of self-supervised features, conditional distillation to avoid catastrophic forgetting, and MoE routing offers a concrete template for domain adaptation in this setting.
major comments (3)
- [§5] §5 (experimental results): No evaluation on held-out NVV types, different recording conditions, or out-of-distribution vocalizations is reported. This is load-bearing for the claim that the domain-aware MoE router and contrastive alignment successfully generalize beyond the specific 10 NVV types and conditions used in training.
- [§4.3] §4.3 (MoE module description): The domain-aware supervision signal for the routing network is not accompanied by any analysis of routing entropy, expert utilization statistics, or ablation on held-out classes, leaving open whether the router collapses to type-specific experts.
- [experimental results tables] Table reporting EER numbers (likely Table 2 or 3): The headline improvements are given as single-point estimates without dataset split details, number of runs, variance across seeds, or statistical significance tests, which undermines assessment of whether the gains over the pretrained baseline are reliable.
minor comments (2)
- [Abstract, §3] The abstract and §3 could more explicitly list the 10 NVV types and the source datasets used for training and evaluation.
- [§4.4] Notation for the contrastive loss temperature and distillation weight should be introduced once and used consistently across equations and text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§5] §5 (experimental results): No evaluation on held-out NVV types, different recording conditions, or out-of-distribution vocalizations is reported. This is load-bearing for the claim that the domain-aware MoE router and contrastive alignment successfully generalize beyond the specific 10 NVV types and conditions used in training.
Authors: We agree that evaluations on held-out NVV types would provide stronger support for generalization claims. The current study systematically evaluates the 10 NVV types present in the dataset. In the revised manuscript, we will add an ablation experiment that holds out one NVV type during training and reports performance on the unseen type to directly test the router and alignment components. We will also explicitly discuss the scope and limitations regarding recording conditions and OOD vocalizations. revision: yes
-
Referee: [§4.3] §4.3 (MoE module description): The domain-aware supervision signal for the routing network is not accompanied by any analysis of routing entropy, expert utilization statistics, or ablation on held-out classes, leaving open whether the router collapses to type-specific experts.
Authors: We concur that routing analysis is needed to substantiate the MoE design. The revised manuscript will include new figures and text in §4.3 reporting routing entropy, per-expert utilization statistics across the 10 NVV types, and an ablation that holds out classes during training to demonstrate that the router learns domain-aware rather than purely type-specific behavior. revision: yes
-
Referee: [experimental results tables] Table reporting EER numbers (likely Table 2 or 3): The headline improvements are given as single-point estimates without dataset split details, number of runs, variance across seeds, or statistical significance tests, which undermines assessment of whether the gains over the pretrained baseline are reliable.
Authors: We appreciate this observation on reproducibility. The reported EERs reflect a single training run. In the revision we will add dataset split details, report means and standard deviations over multiple random seeds, and include statistical significance tests comparing our method against the baseline. revision: yes
Circularity Check
No significant circularity; empirical gains measured against external baselines and pretrained teacher.
full rationale
The paper describes a standard ML pipeline: frozen Data2Vec features + ECAPA-TDNN backbone, MoE with domain-aware routing, conditional distillation from a pretrained teacher, and contrastive loss. Reported EER reductions (speech-NVV 38.93%→22.66%, speech 13.17%→9.24%) are obtained by direct comparison to an external pretrained baseline. No equations, fitted parameters, or self-citations are shown to reduce these quantities to quantities defined inside the paper. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- MoE routing network weights
- Distillation temperature or loss weight
axioms (2)
- domain assumption Frozen Data2Vec features remain informative for non-verbal vocalizations
- domain assumption The 10 NVV types studied are representative of real-world non-verbal vocalizations
Reference graph
Works this paper leans on
-
[1]
Introduction Modern Text-to-Speech (TTS) [1, 2, 3, 4] and V oice Con- version (VC) [5] systems achieve near-human naturalness for modal speech, but generating realistic non-verbal vocalizations (NVVs) such as laughter, coughing, and breathing remains an open challenge. Since these generated sounds must maintain speaker identity, objective evaluation deman...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Methodology As illustrated in Figure 1, our proposed framework comprises three core components: (1) a frozen Data2Vec and ECAPA- TDNN backbone; (2) an MoE module for domain-aware feature routing; and (3) a multi-objective training strategy integrating conditional distillation, contrastive bridging, and domain-aware routing constraints. 2.1. Backbone Archi...
-
[3]
Database and Pre-processing To systematically investigate the domain mismatch in SV mod- els, we utilize the NonverbalTTS [21] dataset for our experi- mental evaluations
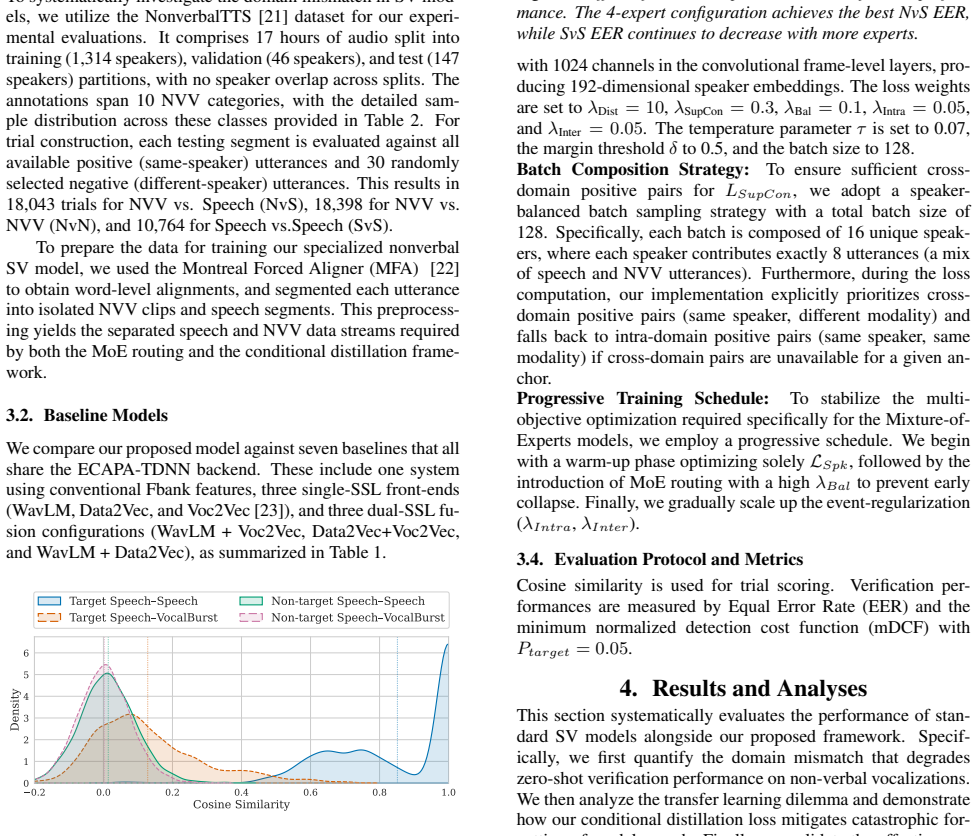
Experiment 3.1. Database and Pre-processing To systematically investigate the domain mismatch in SV mod- els, we utilize the NonverbalTTS [21] dataset for our experi- mental evaluations. It comprises 17 hours of audio split into training (1,314 speakers), validation (46 speakers), and test (147 speakers) partitions, with no speaker overlap across splits. ...
-
[4]
Specifically, each batch is composed of 16 unique speak- ers, where each speaker contributes exactly 8 utterances (a mix of speech and NVV utterances). Furthermore, during the loss computation, our implementation explicitly prioritizes cross- domain positive pairs (same speaker, different modality) and falls back to intra-domain positive pairs (same speak...
-
[5]
Zero-shot
Results and Analyses This section systematically evaluates the performance of stan- dard SV models alongside our proposed framework. Specif- ically, we first quantify the domain mismatch that degrades zero-shot verification performance on non-verbal vocalizations. We then analyze the transfer learning dilemma and demonstrate how our conditional distillati...
-
[6]
We demonstrate that standard SV models suffer severe acoustic mismatch and catastrophic forgetting when adapted to NVVs
Conclusion and Future Work This paper addresses a critical blind spot in current speech re- search by presenting the first systematic study of speaker iden- tity verification across 10 distinct NVV types. We demonstrate that standard SV models suffer severe acoustic mismatch and catastrophic forgetting when adapted to NVVs. To overcome this, we proposed a...
-
[7]
Acknowledgments We acknowledge the National Center for High-Performance Computing (NCHC) of the National Institutes of Applied Re- search (NIAR) in Taiwan for providing computing resources. Additionally, this work was supported by the Ministry of Education (MOE) of Taiwan under the project Taiwan Cen- ters of Excellence in Artificial Intelligence, through...
-
[8]
The authors remain solely responsible for the research design, experiments, analysis, and reported results
Generative AI Use Disclosure Generative AI tools assisted in polishing the manuscript’s lan- guage. The authors remain solely responsible for the research design, experiments, analysis, and reported results. AI tools did not contribute to the substantive scientific content
-
[9]
NaturalSpeech 3: zero-shot speech synthesis with factorized codec and diffusion models,
Z. Ju, Y . Wang, K. Shen, X. Tan, D. Xin, D. Yang, Y . Liu, Y . Leng, K. Song, S. Tang, Z. Wu, T. Qin, X.-Y . Li, W. Ye, S. Zhang, J. Bian, L. He, J. Li, and S. Zhao, “NaturalSpeech 3: zero-shot speech synthesis with factorized codec and diffusion models,” inProceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[10]
CosyVoice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training
Z. Du, C. Gao, Y . Wang, F. Yu, T. Zhao, H. Wang, X. Lv, H. Wang, C. Ni, X. Shi, K. An, G. Yang, Y . Li, Y . Chen, Z. Gao, Q. Chen, Y . Gu, M. Chen, Y . Chen, S. Zhang, W. Wang, and J. Ye, “CosyV oice 3: Towards In-the-wild Speech Generation via Scaling-up and Post-training,” 2025. [Online]. Available: https://arxiv.org/abs/2505.17589
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
C.-J. Hsu, Y .-C. Lin, C.-C. Lin, W.-C. Chen, H. L. Chung, C.-A. Li, Y .-C. Chen, C.-Y . Yu, M.-J. Lee, C.-C. Chen, R.-H. Huang, H. yi Lee, and D.-S. Shiu, “Breezyvoice: Adapting tts for taiwanese mandarin with enhanced polyphone disambiguation – challenges and insights,” 2025. [Online]. Available: https://arxiv.org/abs/2501.17790
-
[12]
Emotion-aligned generation in diffusion text to speech models via preference- guided optimization,
J. Shi, H. Du, Y . He, Y . A. Hong, and Y . Gao, “Emotion-aligned generation in diffusion text to speech models via preference- guided optimization,” inICASSP 2026-2026 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2026, pp. 16 492–16 496
2026
-
[13]
Zero-shot voice conversion with diffusion transformers,
S. Liu, “Zero-shot V oice Conversion with Diffusion Transform- ers,” 2024. [Online]. Available: https://arxiv.org/abs/2411.09943
-
[14]
WavLM: Large- Scale Self-Supervised Pre-Training for Full Stack Speech Pro- cessing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large- Scale Self-Supervised Pre-Training for Full Stack Speech Pro- cessing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[15]
Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdi- nov, and A. Mohamed, “Hubert: Self-supervised speech represen- tation learning by masked prediction of hidden units,”IEEE/ACM transactions on audio, speech, and language processing, vol. 29, pp. 3451–3460, 2021
2021
-
[16]
ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,” inInterspeech 2020, 2020, pp. 3830–3834
2020
-
[17]
V oxCeleb: A Large- Scale Speaker Identification Dataset,
A. Nagrani, J. S. Chung, and A. Zisserman, “V oxCeleb: A Large- Scale Speaker Identification Dataset,” inInterspeech 2017, 2017, pp. 2616–2620
2017
-
[18]
Speaker recognition with cough, laugh and
M. Zhang, Y . Chen, L. Li, and D. Wang, “Speaker recognition with cough, laugh and ”Wei”,” in2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC), 2017, pp. 497–501
2017
-
[19]
Y . Lin, X. Qin, H. Cui, Z. Zhu, and M. Li, “Laugh Betrays You? Learning Robust Speaker Representation From Speech Containing Non-Verbal Fragments,” 2023. [Online]. Available: https://arxiv.org/abs/2210.16028
-
[20]
Perceptual cues in nonverbal vocal expressions of emotion,
D. A. Sauter, F. Eisner, A. J. Calder, and S. K. Scott, “Perceptual cues in nonverbal vocal expressions of emotion,”Quarterly jour- nal of experimental psychology, vol. 63, no. 11, pp. 2251–2272, 2010
2010
-
[21]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean, “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer,”arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Learning without forgetting,
Z. Li and D. Hoiem, “Learning without forgetting,”IEEE transac- tions on pattern analysis and machine intelligence, vol. 40, no. 12, pp. 2935–2947, 2017
2017
-
[23]
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language,
A. Baevski, W.-N. Hsu, Q. Xu, A. Babu, J. Gu, and M. Auli, “data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language,” inProceedings of the 39th International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, and S. Sabato, Eds., vol. 16...
2022
-
[24]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, 2019, pp. 4690–4699
2019
-
[25]
Switch transformers: Scal- ing to trillion parameter models with simple and efficient spar- sity,
W. Fedus, B. Zoph, and N. Shazeer, “Switch transformers: Scal- ing to trillion parameter models with simple and efficient spar- sity,”Journal of Machine Learning Research, vol. 23, no. 120, pp. 1–39, 2022
2022
-
[26]
Bootstrap your own latent-a new approach to self-supervised learning,
J.-B. Grill, F. Strub, F. Altch ´e, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Ghesh- laghi Azaret al., “Bootstrap your own latent-a new approach to self-supervised learning,”Advances in neural information pro- cessing systems, vol. 33, pp. 21 271–21 284, 2020
2020
-
[27]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,”Advances in neural information processing systems, vol. 33, pp. 18 661–18 673, 2020
2020
-
[28]
Improving speaker representations using contrastive losses on multi-scale features,
S. Dixit, M. Baali, R. Singh, and B. Raj, “Improving speaker representations using contrastive losses on multi-scale features,” arXiv preprint arXiv:2410.05037, 2024
-
[29]
M. Borisov, E. Spirin, and D. Diatlova, “Nonverbaltts: A public english corpus of text-aligned nonverbal vocalizations with emotion annotations for text-to-speech,”arXiv preprint arXiv:2507.13155, 2025
-
[30]
Montreal forced aligner: Trainable text-speech align- ment using kaldi
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal forced aligner: Trainable text-speech align- ment using kaldi.” inInterspeech, vol. 2017, 2017, pp. 498–502
2017
-
[31]
voc2vec: A Foundation Model for Non-Verbal V ocalization,
A. Koudounas, M. La Quatra, S. M. Siniscalchi, and E. Baralis, “voc2vec: A Foundation Model for Non-Verbal V ocalization,” in ICASSP 2025 - 2025 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2025, pp. 1–5
2025
-
[32]
Confidence intervals for evaluation in machine learning
L. Ferrer and P. Riera, “Confidence intervals for evaluation in machine learning.” [Online]. Available: https://github.com/ luferrer/ConfidenceIntervals
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.