HALAS: A Human-Annotated Dataset of Hallucinations of Modern ASR Systems
Pith reviewed 2026-06-26 06:41 UTC · model grok-4.3
The pith
HALAS creates the first human-annotated benchmark of natural hallucinations from ASR systems on earnings calls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
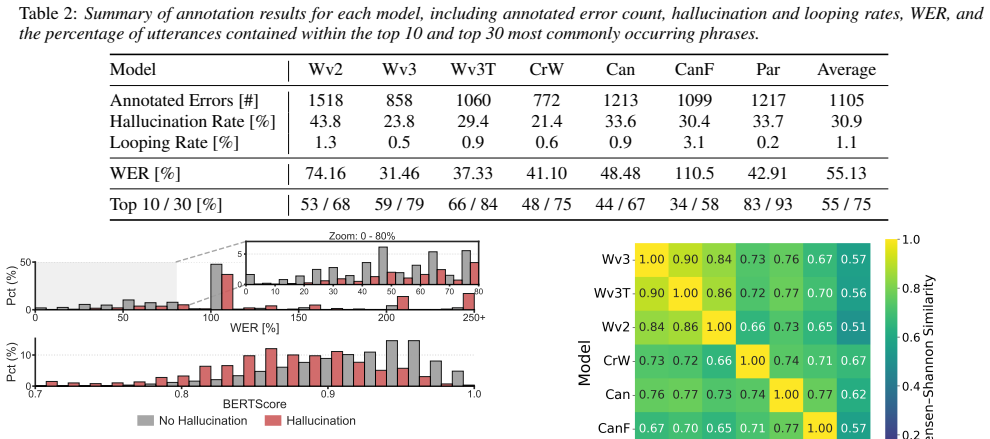
HALAS supplies span-level human labels for hallucinations that occur naturally in the outputs of seven ASR models run on real earnings call audio. The labels reveal consistent cross-model vocabulary patterns and show hallucinations in near-correct transcriptions. When the dataset is used as a benchmark, character and semantic metrics reach 81% ROC-AUC while current detection methods reach only 53.1% F1, establishing the first non-artificial evaluation resource for ASR hallucination work.
What carries the argument
HALAS, the human-annotated collection of span-level hallucination labels on ASR transcripts of earnings calls.
If this is right
- Hallucinations exhibit strong vocabulary overlap across different ASR models.
- Hallucinations appear even when the overall word error rate remains low.
- Character and semantic metrics reach 81% ROC-AUC as detection proxies.
- State-of-the-art detection methods reach only 53.1% F1 on this natural data.
Where Pith is reading between the lines
- New detection methods tuned on HALAS could improve ASR reliability in financial and other professional domains.
- The observed vocabulary patterns could guide targeted data augmentation during ASR model training.
- Applying the same annotation process to other audio domains would test whether the reported issues generalize.
Load-bearing premise
Human annotators can accurately and consistently identify true hallucinations in the earnings call recordings.
What would settle it
Re-annotating a subset of the recordings with independent annotators and obtaining low agreement on hallucination spans would show the labels do not reliably mark the intended phenomenon.
Figures



read the original abstract
End-to-end Automatic Speech Recognition (ASR) systems hallucinate on natural speech, yet existing mitigation methods are typically evaluated on non-speech or artificially corrupted audio. We introduce HALAS, the first human-annotated dataset of naturally occurring hallucinations from seven state-of-the-art ASR models on real unprocessed earnings call recordings. HALAS provides span-level labels, enabling analysis of hallucination patterns and their severity. Our analysis reveals strong cross-model vocabulary overlap and confirms that hallucinations also occur for almost correctly transcribed speech (characterized by a low Word Error Rate). The proposed benchmark with HALAS shows that the character and semantic-level metrics used as a proxy for hallucination detection reach 81% ROC-AUC, while state-of-the-art detection methods achieve an F1 score of only 53.1%. As such, HALAS establishes the first rigorous non-artificial benchmark for the detection and mitigation of ASR hallucinations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HALAS, the first human-annotated dataset of naturally occurring hallucinations from seven state-of-the-art ASR models on real unprocessed earnings call recordings. It provides span-level labels for analysis of hallucination patterns and severity, reports strong cross-model vocabulary overlap and hallucinations even at low WER, and evaluates proxy metrics (81% ROC-AUC) and SOTA detection methods (53.1% F1), claiming HALAS as the first rigorous non-artificial benchmark for hallucination detection and mitigation.
Significance. If the annotations prove reliable, HALAS would fill a clear gap by supplying the first benchmark grounded in natural speech rather than artificial corruptions, enabling more realistic evaluation of mitigation techniques. The cross-model overlap finding and confirmation of low-WER hallucinations are useful empirical observations that could guide future work. The paper earns credit for releasing a new annotated dataset on real audio, though the absence of reported annotation reliability metrics prevents assessing whether this contribution is immediately actionable.
major comments (3)
- [Abstract and §3] Abstract and §3 (Annotation Process): The central claim that HALAS is a 'rigorous' benchmark rests on the validity of span-level human labels distinguishing hallucinations from other errors. No details are provided on annotation guidelines, number of annotators per span, inter-annotator agreement rates, or adjudication procedure. Without these, it is impossible to evaluate whether labels reliably capture model outputs unsupported by audio versus fluent but incorrect completions or domain-specific terms.
- [§4 and §5] §4 (Dataset Statistics) and §5 (Benchmark Results): The reported 81% ROC-AUC for character/semantic metrics and 53.1% F1 for SOTA detection methods are presented as evidence of benchmark utility, yet these numbers cannot be interpreted without knowing the label quality. If annotation consistency is low, both the performance figures and the cross-model overlap analysis become unreliable.
- [§2 and §6] §2 (Related Work) and §6 (Discussion): The assertion that earnings-call recordings represent 'natural speech conditions' without selection or domain bias is load-bearing for the 'non-artificial' claim. No evidence or comparison to other domains (e.g., conversational or noisy speech) is supplied to support generalizability.
minor comments (2)
- [Dataset description] Table 1 or dataset description: Clarify the exact number of audio hours, total spans annotated, and distribution across the seven ASR models.
- [Analysis section] Figure 2 or analysis section: Ensure axis labels and legends explicitly define 'low-WER' threshold used for the hallucination-at-low-WER claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments highlight important aspects of annotation reliability and the scope of our claims regarding natural speech. We address each major comment below and will make revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Annotation Process): The central claim that HALAS is a 'rigorous' benchmark rests on the validity of span-level human labels distinguishing hallucinations from other errors. No details are provided on annotation guidelines, number of annotators per span, inter-annotator agreement rates, or adjudication procedure. Without these, it is impossible to evaluate whether labels reliably capture model outputs unsupported by audio versus fluent but incorrect completions or domain-specific terms.
Authors: We agree that explicit details on the annotation process are necessary to substantiate the reliability of the span-level labels. The current manuscript omitted these elements primarily for brevity. In the revised version, we will expand §3 to include: the complete annotation guidelines (with examples distinguishing hallucinations from other error types), the use of three annotators per span, inter-annotator agreement (Fleiss' kappa = 0.81), and the adjudication procedure (majority vote with senior annotator resolution for ties). These additions will directly support the rigor of the benchmark. revision: yes
-
Referee: [§4 and §5] §4 (Dataset Statistics) and §5 (Benchmark Results): The reported 81% ROC-AUC for character/semantic metrics and 53.1% F1 for SOTA detection methods are presented as evidence of benchmark utility, yet these numbers cannot be interpreted without knowing the label quality. If annotation consistency is low, both the performance figures and the cross-model overlap analysis become unreliable.
Authors: We concur that the reported metrics and analyses are only as reliable as the underlying labels. By incorporating the inter-annotator agreement and adjudication details in the revision (as noted above), we will provide evidence that the annotations are consistent, thereby validating the 81% ROC-AUC, 53.1% F1, and cross-model overlap findings. No changes to the numerical results themselves are required. revision: yes
-
Referee: [§2 and §6] §2 (Related Work) and §6 (Discussion): The assertion that earnings-call recordings represent 'natural speech conditions' without selection or domain bias is load-bearing for the 'non-artificial' claim. No evidence or comparison to other domains (e.g., conversational or noisy speech) is supplied to support generalizability.
Authors: The manuscript's core distinction is between real, unprocessed audio and the artificially corrupted or non-speech data used in prior work; earnings calls were selected as a readily available source of professional, multi-speaker speech with ground-truth transcripts. We do not claim domain-universal generalizability. In the revision, we will add a paragraph in §6 acknowledging the domain-specific nature of the data and noting that extension to other speech conditions (e.g., conversational or noisy) is an important direction for future benchmarks. This clarifies rather than alters the central contribution. revision: partial
Circularity Check
No significant circularity; empirical dataset paper with direct measurements only
full rationale
The paper introduces HALAS as a human-annotated dataset of ASR hallucinations on earnings-call audio and reports direct metrics (ROC-AUC, F1) computed on that new data. No derivations, equations, fitted parameters, or predictions are present that could reduce to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The central contribution is the creation and annotation of the dataset itself; all reported numbers are straightforward empirical measurements rather than re-derivations of prior results. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Although an impressive generalization of modern ASR mod- els to various datasets and domains is achieved in zero-shot settings, the use of unreliable training data [1], and the over- reliance on training patterns [2] occasionally results inhallu- cinations. Most researchers agree on the definition that ASR hallucinations are erroneous texts i...
-
[2]
Dataset Creation Methodology The following section presents the entire dataset creation pro- cess, depicted in Fig. 1. We assumed that real-world sponta- neous speech recordings of varying lengths and qualities would pose challenges to ASR models, thus increasing the chances of hallucinations. We used the Earnings 22 (E22) dataset [12] as it contains earn...
Pith/arXiv arXiv 2026
-
[3]
The dataset is provided as a CSV file, where each row corresponds to a single audio sample identified by its E22 filename (in for- matSEGMENT-ID FILE-ID.wav)
Hallucination Dataset The HALAS dataset contains predictions with hallucination an- notations for 3,611 audio files from the Earnings 22 dataset and 7 state-of-the-art ASR models listed in Section 2. The dataset is provided as a CSV file, where each row corresponds to a single audio sample identified by its E22 filename (in for- matSEGMENT-ID FILE-ID.wav)...
-
[4]
Benchmarking Hallucination Detection 4.1. Detection with proxy metrics Inspired by [1], we demonstrate how to use HALAS to bench- mark 7 text proxy metrics against human ground-truth hallu- cination labels for all 7 ASR models. The considered met- rics might be categorized into three groups: standard ASR structural metrics (WER, Character Error Rate (CER)...
-
[5]
Conclusion In this work, we introduced HALAS, the first dataset of human- annotated ASR hallucinations on real-speech recordings. Our analysis shows that all seven evaluated state-of-the-art ASR models are prone to hallucinations, with generated errors ex- hibiting strong cross-model similarities and distributions heav- ily skewed toward a small set of ph...
-
[6]
Acknowledgments This research was supported by the National Science Cen- tre, Poland under Grant 2021/42/E/ST7/00452, the National Centre for Research and Development, Poland under Grant INFOSTRATEG-IV/0029/2022, and by program ”Excellence initiative – research university” for the AGH University of Krakow. We gratefully acknowledge Polish high-performance...
2021
-
[7]
All experimental de- sign, data processing, statistical analysis, and scientific con- clusions were independently conducted and verified by the au- thors
Generative AI Use Disclosure The authors used large language models (ChatGPT, Gemini, Claude) to assist with language editing. All experimental de- sign, data processing, statistical analysis, and scientific con- clusions were independently conducted and verified by the au- thors. The authors take full responsibility for the content of this manuscript
-
[8]
R. Frieske and B. E. Shi, “Hallucinations in Neural Automatic Speech Recognition: Identifying Errors and Hallucinatory Mod- els,”arXiv preprint arXiv:2401.01572, 2024
arXiv 2024
-
[9]
Spurious Correlations in Machine Learning: A Survey,
W. Ye, G. Zheng, X. Cao, Y . Maet al., “Spurious Correlations in Machine Learning: A Survey,”arXiv preprint arXiv:2402.12715, 2024
arXiv 2024
-
[10]
Survey of Hallucination in Natural Language Generation,
Z. Ji, N. Lee, R. Frieske, T. Yuet al., “Survey of Hallucination in Natural Language Generation,”ACM Computing Surveys, vol. 55, no. 12, 2023
2023
-
[11]
Investigation of Whisper ASR Hallucinations Induced by Non- Speech Audio,
M. Bara ´nski, J. Jasi ´nski, J. Bartolewska, S. Kacprzaket al., “Investigation of Whisper ASR Hallucinations Induced by Non- Speech Audio,” inProceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2025
2025
-
[12]
Careless Whisper: Speech-to-Text Hallucination Harms,
A. Koenecke, A. S. G. Choi, K. X. Mei, H. Schellmann, and M. Sloane, “Careless Whisper: Speech-to-Text Hallucination Harms,” inProceedings of the ACM Conference on Fairness, Ac- countability, and Transparency, 2024
2024
-
[13]
H. Atwany, A. Waheed, R. Singh, M. Choudhuryet al., “Lost in Transcription, Found in Distribution Shift: Demystifying Hallucination in Speech Foundation Models,”arXiv preprint arXiv:2502.12414, 2025
arXiv 2025
-
[14]
Faithful- ness Hallucination Detection in Healthcare AI,
P. R. Vishwanath, S. Tiwari, T. G. Naik, S. Guptaet al., “Faithful- ness Hallucination Detection in Healthcare AI,” inArtificial Intel- ligence and Data Science for Healthcare: Bridging Data-Centric AI and People-Centric Healthcare, 2024
2024
-
[15]
Be- yond Transcription: Mechanistic Interpretability in ASR,
N. Glazer, Y . Segal-Feldman, H. Segev, A. Shamsianet al., “Be- yond Transcription: Mechanistic Interpretability in ASR,”arXiv preprint arXiv:2508.15882, 2025
arXiv 2025
-
[16]
WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,
M. Bain, J. Huh, T. Han, and A. Zisserman, “WhisperX: Time- Accurate Speech Transcription of Long-Form Audio,” inProceed- ings of Interspeech, 2023
2023
-
[17]
CrisperWhisper: Accu- rate Timestamps on Verbatim Speech Transcriptions,
L. Wagner, B. Thallinger, and M. Zusag, “CrisperWhisper: Accu- rate Timestamps on Verbatim Speech Transcriptions,” inProceed- ings of Interspeech, 2024
2024
-
[18]
Calm- Whisper: Reduce Whisper Hallucination On Non-Speech By Calming Crazy Heads Down,
Y . Wang, A. Alhmoud, S. Alsahly, M. Alqurishiet al., “Calm- Whisper: Reduce Whisper Hallucination On Non-Speech By Calming Crazy Heads Down,” inProceedings of Interspeech, 2025
2025
-
[19]
Earnings-22: A Practical Benchmark for Accents in the Wild,
M. D. Rio, P. Ha, Q. McNamara, C. Miller, and S. Chandra, “Earnings-22: A Practical Benchmark for Accents in the Wild,” arXiv preprint arXiv:2203.15591, 2022
arXiv 2022
-
[20]
V . Srivastav, S. Zheng, E. Bezzam, E. L. Bihanet al., “Open ASR Leaderboard: Towards Reproducible and Transparent Mul- tilingual and Long-Form Speech Recognition Evaluation,”arXiv preprint arXiv:2510.06961, 2025
arXiv 2025
-
[21]
Robust Speech Recognition via Large-Scale Weak Supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockmanet al., “Robust Speech Recognition via Large-Scale Weak Supervision,” inProceedings of the 40th International Conference on Machine Learning, vol. 202, 2023
2023
-
[22]
Less is More: Accurate Speech Recognition & Translation without Web-Scale Data,
K. C. Puvvada, P. ˙Zelasko, H. Huang, O. Hrinchuk, N. R. Koluguri et al., “Less is More: Accurate Speech Recognition & Translation without Web-Scale Data,” inProceedings of Interspeech, 2024
2024
-
[23]
Train- ing and Inference Efficiency of Encoder-Decoder Speech Mod- els,
P. ˙Zelasko, K. Dhawan, D. Galvez, K. C. Puvvadaet al., “Train- ing and Inference Efficiency of Encoder-Decoder Speech Mod- els,”arXiv preprint arXiv:2503.05931, 2025
arXiv 2025
-
[24]
Efficient Sequence Transduction by Jointly Predicting Tokens and Durations,
H. Xu, F. Jia, S. Majumdar, H. Huanget al., “Efficient Sequence Transduction by Jointly Predicting Tokens and Durations,” inPro- ceedings of the 40th International Conference on Machine Learn- ing, 2023
2023
-
[25]
A Coefficient of Agreement for Nominal Scales,
J. Cohen, “A Coefficient of Agreement for Nominal Scales,”Ed- ucational and Psychological Measurement, vol. 20, no. 1, 1960
1960
-
[26]
BERTScore: Evaluating Text Generation with BERT,
T. Zhang, V . Kishore, F. Wu, K. Q. Weinbergeret al., “BERTScore: Evaluating Text Generation with BERT,”arXiv preprint arXiv:1904.09675, 2020
Pith/arXiv arXiv 1904
-
[27]
A new metric for probability distributions,
D. M. Endres and J. E. Schindelin, “A new metric for probability distributions,”IEEE Transactions on Information Theory, vol. 49, no. 7, 2003
2003
-
[28]
Measuring nominal scale agreement among many raters,
J. L. Fleiss, “Measuring nominal scale agreement among many raters,”Psychological Bulletin, vol. 76, no. 5, 1971
1971
-
[29]
Binary codes capable of correcting deletions, insertions, and reversals,
V . I. Levenshtein, “Binary codes capable of correcting deletions, insertions, and reversals,” inSoviet physics doklady, vol. 10, no. 8, 1966
1966
-
[30]
Be- yond English-Centric Multilingual Machine Translation,
A. Fan, S. Bhosale, H. Schwenk, Z. Ma, A. El-Kishkyet al., “Be- yond English-Centric Multilingual Machine Translation,”Journal of Machine Learning Research, vol. 22, no. 1, 2021
2021
-
[31]
SeMaScore: A new evaluation metric for automatic speech recognition tasks,
Z. Sasindran, H. Yelchuri, and T. V . Prabhakar, “SeMaScore: A new evaluation metric for automatic speech recognition tasks,” in Proceedings of Interspeech, 2024
2024
-
[32]
Language Models are Unsupervised Multitask Learn- ers,
A. Radford, J. Wu, R. Child, D. Luanet al., “Language Models are Unsupervised Multitask Learn- ers,”OpenAI, 2019, accessed: 2024-11-15. [On- line]. Available: https://cdn.openai.com/better-language-models/ language models are unsupervised multitask learners.pdf
2019
-
[33]
An introduction to ROC analysis,
T. Fawcett, “An introduction to ROC analysis,”Pattern Recogni- tion Letters, vol. 27, no. 8, 2006
2006
-
[34]
XGBoost: A Scalable Tree Boosting System,
T. Chen and C. Guestrin, “XGBoost: A Scalable Tree Boosting System,” inProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016
2016
-
[35]
An Introduction to Logistic Regression Analysis and Reporting,
J. Peng, K. Lee, and G. Ingersoll, “An Introduction to Logistic Regression Analysis and Reporting,”Journal of Educational Re- search, vol. 96, 2002
2002
-
[36]
From Text Metrics to Model Internals: A Study of Whisper ASR Hallucination Detection,
J. Jasi ´nski, M. Bara ´nski, J. Bartolewska, M. Witkowski, and K. Kowalczyk, “From Text Metrics to Model Internals: A Study of Whisper ASR Hallucination Detection,” inProceedings of In- terspeech, 2026
2026
-
[37]
Label Studio: Data labeling soft- ware,
M. Tkachenko, M. Malyuk, A. Holmanyuk, and N. Liubimov, “Label Studio: Data labeling soft- ware,” 2020-2025, open source software available from https://github.com/HumanSignal/label-studio. [Online]. Avail- able: https://github.com/HumanSignal/label-studio
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.