PipeFusion: Patch-level Pipeline Parallelism for Diffusion Transformers Inference
Pith reviewed 2026-05-24 01:15 UTC · model grok-4.3
The pith
PipeFusion partitions diffusion transformer images into patches and reuses one-step-old feature maps to cut communication costs during multi-GPU inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PipeFusion achieves state-of-the-art inference speed for diffusion transformers by applying patch-level pipeline parallelism that reuses one-step stale feature maps, thereby reducing communication volume compared with prior parallelism schemes while distributing parameters for better memory use on large models.
What carries the argument
Patch-level pipeline parallelism that reuses one-step stale feature maps to supply context for the current pipeline step.
If this is right
- Larger DiT models such as Flux.1 become practical on PCIe GPU clusters because parameters are distributed rather than replicated.
- Communication volume drops below that of tensor, sequence, and DistriFusion baselines, directly lowering end-to-end latency.
- Memory footprint per device shrinks, allowing higher-resolution generation or batch sizes on the same hardware.
- The pipeline schedule can be applied to any DiT variant that exhibits gradual input change across denoising steps.
Where Pith is reading between the lines
- The same reuse idea could be tested on video or 3D diffusion models where temporal or spatial coherence is even stronger.
- If the similarity assumption weakens at very late denoising steps, a hybrid schedule that switches to fresh maps near the end might preserve quality while retaining most of the speedup.
- Extending the patch pipeline to heterogeneous GPU clusters would require only adjustments to the communication pattern, not to the core reuse logic.
Load-bearing premise
High similarity between inputs from successive diffusion steps lets one-step-old feature maps supply adequate context without materially harming final image quality.
What would settle it
Run the same models with and without the stale-map reuse on the eight-GPU setup and compare both wall-clock time and standard image-quality metrics such as FID; a large quality drop would falsify the central claim.
Figures




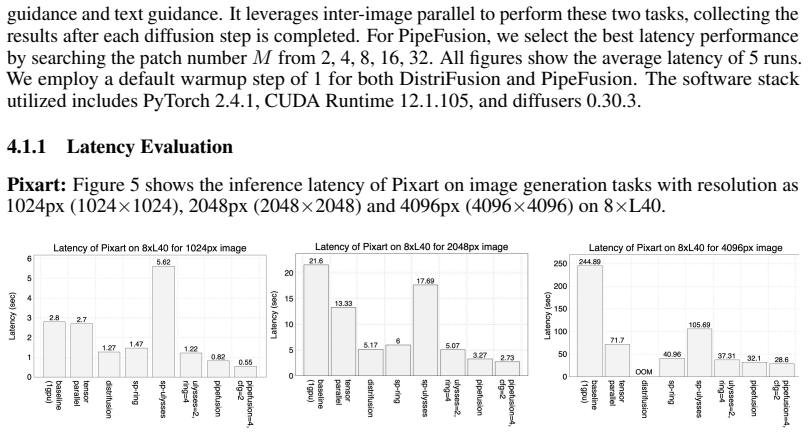
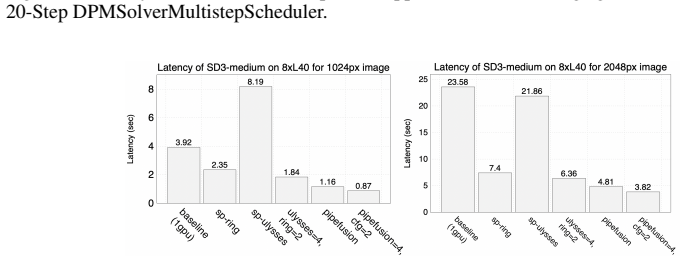





read the original abstract
This paper presents PipeFusion, an innovative parallel methodology to tackle the high latency issues associated with generating high-resolution images using diffusion transformers (DiTs) models. PipeFusion partitions images into patches and the model layers across multiple GPUs. It employs a patch-level pipeline parallel strategy to orchestrate communication and computation efficiently. By capitalizing on the high similarity between inputs from successive diffusion steps, PipeFusion reuses one-step stale feature maps to provide context for the current pipeline step. This approach notably reduces communication costs compared to existing DiTs inference parallelism, including tensor parallel, sequence parallel and DistriFusion. PipeFusion enhances memory efficiency through parameter distribution across devices, ideal for large DiTs like Flux.1. Experimental results demonstrate that PipeFusion achieves state-of-the-art performance on 8$\times$L40 PCIe GPUs for Pixart, Stable-Diffusion 3, and Flux.1 models. Our source code is available at https://github.com/xdit-project/xDiT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PipeFusion, a patch-level pipeline parallelism technique for Diffusion Transformer (DiT) inference. It partitions both image patches and model layers across GPUs and reuses one-step-stale feature maps (exploiting similarity between successive diffusion steps) to reduce inter-GPU communication relative to tensor parallelism, sequence parallelism, and DistriFusion. The method is evaluated on PixArt, Stable Diffusion 3, and Flux.1, claiming state-of-the-art latency on 8×L40 PCIe GPUs while preserving output quality; source code is released.
Significance. If the quality-preservation claim holds, PipeFusion would offer a practical route to lower-latency, memory-efficient inference for large DiTs on commodity multi-GPU hardware. The open-source release is a concrete strength that supports reproducibility and follow-on work.
major comments (2)
- [Experimental results / Evaluation] The central performance claim rests on the unverified assumption that one-step stale feature maps supply adequate context without materially degrading image quality. No ablation isolating the quality impact of this reuse (FID, CLIP score, or human preference with vs. without stale maps) is referenced in the evaluation description, which is load-bearing for the communication-savings argument.
- [Abstract and Experimental results] The abstract asserts SOTA latency on 8×L40 GPUs for PixArt, SD3, and Flux.1 yet supplies no quantitative numbers, baselines, or quality metrics. Without these data the SOTA claim cannot be assessed.
minor comments (1)
- Notation for patch partitioning and pipeline stages should be defined once with a consistent symbol table or figure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experimental results / Evaluation] The central performance claim rests on the unverified assumption that one-step stale feature maps supply adequate context without materially degrading image quality. No ablation isolating the quality impact of this reuse (FID, CLIP score, or human preference with vs. without stale maps) is referenced in the evaluation description, which is load-bearing for the communication-savings argument.
Authors: We agree that an explicit ablation isolating the quality impact of one-step stale feature reuse would provide stronger evidence. The current manuscript reports overall quality metrics (FID, CLIP) for PipeFusion versus baselines but does not include a controlled with/without-stale comparison. We will add this ablation study in the revised version. revision: yes
-
Referee: [Abstract and Experimental results] The abstract asserts SOTA latency on 8×L40 GPUs for PixArt, SD3, and Flux.1 yet supplies no quantitative numbers, baselines, or quality metrics. Without these data the SOTA claim cannot be assessed.
Authors: We acknowledge that the abstract currently lacks specific numerical results. In the revision we will expand the abstract to include key latency figures, the compared baselines, and quality metrics that support the SOTA claim on 8×L40 GPUs. revision: yes
Circularity Check
No circularity: engineering method with external benchmarks and no self-referential derivations
full rationale
The paper describes a patch-level pipeline parallelism technique for DiT inference that reuses one-step stale feature maps based on observed input similarity across diffusion steps. This is presented as an empirical engineering choice, not a derived prediction or first-principles result. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. Performance is benchmarked against external baselines (tensor parallel, sequence parallel, DistriFusion) on Pixart, SD3, and Flux.1, with code released for reproduction. The similarity assumption is stated explicitly but does not reduce any result to its own inputs by construction. This is a standard non-circular systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Inputs from successive diffusion steps have high similarity allowing reuse of one-step stale feature maps
Forward citations
Cited by 3 Pith papers
-
ChunkFlow: Communication-Aware Chunked Prefetching for Layerwise Offloading in Distributed Diffusion Transformer Inference
ChunkFlow achieves up to 1.28x step-time speedup and up to 49% lower peak GPU memory for DiT inference by using a first-order model to guide communication-aware chunked prefetching.
-
CoCoDiff: Optimizing Collective Communications for Distributed Diffusion Transformer Inference Under Ulysses Sequence Parallelism
CoCoDiff achieves 3.6x average and 8.4x peak speedup for distributed DiT inference on up to 96 GPU tiles via tile-aware all-to-all, V-first scheduling, and selective V communication.
-
GENSERVE: Efficient Co-Serving of Heterogeneous Diffusion Model Workloads
GENSERVE improves SLO attainment by up to 44% for co-serving heterogeneous T2I and T2V diffusion workloads via step-level preemption, elastic parallelism, and joint scheduling.
Reference graph
Works this paper leans on
-
[1]
BlackForestLabs. Announcing black forest labs. https://blackforestlabs.ai/ announcing-black-forest-labs/, 2024. Accessed: [2024.10]
work page 2024
-
[2]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[3]
Junsong Chen, Chongjian Ge, Enze Xie, Yue Wu, Lewei Yao, Xiaozhe Ren, Zhongdao Wang, Ping Luo, Huchuan Lu, and Zhenguo Li. Pixart- \sigma: Weak-to-strong training of diffusion transformer for 4k text-to-image generation.arXiv preprint arXiv:2403.04692, 2024
-
[4]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[5]
Video generation models as world simulators
OpenAI. Video generation models as world simulators. https://openai.com/index/ video-generation-models-as-world-simulators/, 2024. Accessed: May 2024
work page 2024
-
[6]
Movie gen: A cast of media foundation models
MetaAI. Movie gen: A cast of media foundation models. https: // ai. meta. com/ static-resource/ movie-gen-research-paper, 2024. Accessed: 2024-10-14
work page 2024
-
[7]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pages 234–241. Springer, 2015
work page 2015
-
[8]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[9]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Leon Song, Samyam Rajbhandari, and Yuxiong He. Deepspeed ulysses: System optimizations for enabling training of extreme long sequence transformer models.arXiv preprint arXiv:2309.14509, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Junhyuk So, Jungwon Lee, and Eunhyeok Park. Frdiff: Feature reuse for exquisite zero-shot acceleration of diffusion models.CoRR, abs/2312.03517, 2023
-
[12]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15762–15772, 2024
work page 2024
-
[13]
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion transformer via layer caching.arXiv preprint arXiv:2406.01733, 2024
-
[14]
Zhihang Yuan, Pu Lu, Hanling Zhang, Xuefei Ning, Linfeng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, and Yu Wang. Ditfastattn: Attention compression for diffusion transformer models.arXiv preprint arXiv:2406.08552, 2024
-
[15]
Real-time video generation with pyramid attention broad- cast.arXiv preprint arXiv:2408.12588, 2024
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broadcast.arXiv preprint arXiv:2408.12588, 2024
-
[16]
Distrifusion: Distributed parallel inference for high-resolution diffusion models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming- Yu Liu, Kai Li, and Song Han. Distrifusion: Distributed parallel inference for high-resolution diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[17]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 11
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[18]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps.Advances in Neural Information Processing Systems, 35:5775–5787, 2022
work page 2022
-
[19]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[20]
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al. Megascale: Scaling large language model training to more than 10,000 gpus.arXiv preprint arXiv:2402.15627, 2024
-
[21]
PixArt-$\alpha$: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhongdao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. Pixart- α: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
- [24]
-
[25]
Jiarui Fang and Shangchun Zhao. A unified sequence parallelism approach for long context generative ai.arXiv preprint arXiv:2405.07719, 2024
-
[26]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, Hy- oukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems, 32, 2019
work page 2019
-
[28]
Terapipe: Token-level pipeline parallelism for training large-scale language models
Zhuohan Li, Siyuan Zhuang, Shiyuan Guo, Danyang Zhuo, Hao Zhang, Dawn Song, and Ion Stoica. Terapipe: Token-level pipeline parallelism for training large-scale language models. In International Conference on Machine Learning, pages 6543–6552. PMLR, 2021
work page 2021
-
[29]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
work page 2017
-
[31]
black-forest-labs/flux.1-schnell · hugging face
-
[32]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
work page 2024
-
[33]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Microsoft COCO Captions: Data Collection and Evaluation Server
Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server.arXiv preprint arXiv:1504.00325, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[38]
Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu. On aliased resizing and surprising subtleties in gan evaluation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11410–11420, 2022. NeurIPS Paper Checklist 1.Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s cont...
work page 2022
-
[39]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
work page 2025
-
[40]
In other related work, it is common to use 50 steps [16] or even 100 steps [12], which helps to alleviate the overhead of warmup. To mitigate the performance degradation caused by warmup, we can separate the warmup steps from the remaining working steps and allocate different computational resources to them. The output feature maps after the warmup steps ...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.