A Comprehensive Survey of Agents for Computer Use: Foundations, Challenges, and Future Directions
Pith reviewed 2026-05-23 04:56 UTC · model grok-4.3
The pith
A survey of 87 agents for computer use identifies six gaps blocking practical deployment and proposes targeted fixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a taxonomy spanning domain contexts, observation-action modalities, and perception-reasoning-learning processes, the review of 87 ACUs and 33 datasets shows that agents for computer use exhibit insufficient generalization, inefficient learning, limited planning, low task complexity in benchmarks, non-standardized evaluation, and a disconnect between research and practical conditions; addressing these via vision-based low-level control, adaptive learning beyond prompting, effective planning methods, real-world-complexity benchmarks, task-success evaluation, and deployment-constrained design will advance the field toward robust general-purpose agents.
What carries the argument
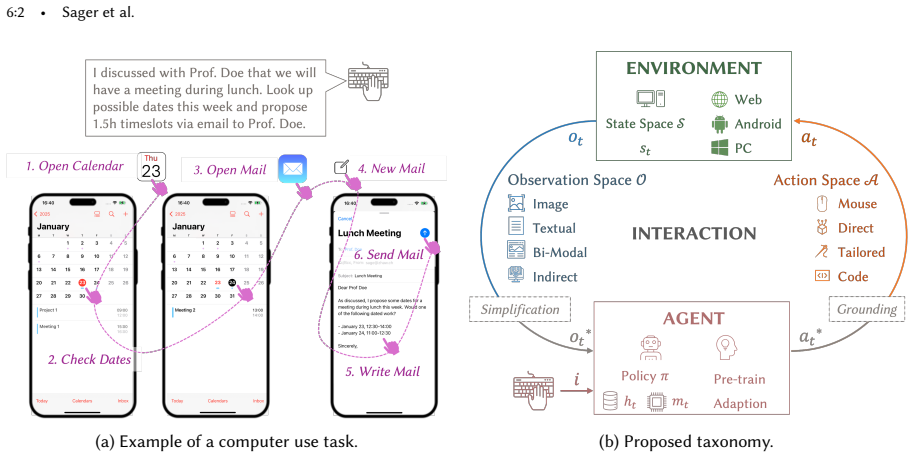
The unifying taxonomy that classifies ACUs by operating contexts, observation and action modalities, and how agents perceive, reason, and learn.
If this is right
- Vision-based observations paired with low-level control actions will improve generalization across devices and interfaces.
- Methods for adaptive learning beyond static prompting will reduce reliance on fixed instructions and improve efficiency.
- Stronger planning and reasoning components will enable agents to handle longer, multi-step tasks reliably.
- Benchmarks that incorporate real-world task complexity will produce more meaningful progress measurements than current simplified suites.
- Standardized evaluation centered on task success rates will enable direct comparisons across systems and close the research-practice gap.
Where Pith is reading between the lines
- Future papers could adopt the taxonomy as a checklist to ensure they address all three perspectives when describing new agents.
- Shifting emphasis toward low-level control may encourage development of agents that mimic human screen interaction more closely than API-based approaches.
- The identified disconnect suggests value in creating shared testbeds that simulate actual user environments and constraints.
- Extending the survey periodically could track whether the advocated changes reduce the six gaps over time.
Load-bearing premise
The 87 ACUs and 33 datasets selected for review capture the representative landscape of agents for computer use without significant omissions.
What would settle it
Identification of a widely deployed or high-performing agent for computer use that falls outside the three-dimensional taxonomy or was omitted from the reviewed set.
Figures















read the original abstract
Agents for computer use (ACUs) are an emerging class of systems capable of executing complex tasks on digital devices -- such as desktops, mobile phones, and web platforms -- given instructions in natural language. These agents can automate tasks by controlling software via low-level actions like mouse clicks and touchscreen gestures. However, despite rapid progress, ACUs are not yet mature for everyday use. In this survey, we investigate the state-of-the-art, trends, and research gaps in the development of practical ACUs. We provide a comprehensive review of the ACU landscape, introducing a unifying taxonomy spanning three dimensions: (I) the domain perspective, characterizing agent operating contexts; (II) the interaction perspective, describing observation modalities (e.g., screenshots, HTML) and action modalities (e.g., mouse, keyboard, code execution); and (III) the agent perspective, detailing how agents perceive, reason, and learn. We review 87 ACUs and 33 datasets across foundation model-based and classical approaches through this taxonomy. Our analysis identifies six major research gaps: insufficient generalization, inefficient learning, limited planning, low task complexity in benchmarks, non-standardized evaluation, and a disconnect between research and practical conditions. To address these gaps, we advocate for: (a) vision-based observations and low-level control to enhance generalization; (b) adaptive learning beyond static prompting; (c) effective planning and reasoning methods and models; (d) benchmarks that reflect real-world task complexity; (e) standardized evaluation based on task success; (f) aligning agent design with real-world deployment constraints. Together, our taxonomy and analysis establish a foundation for advancing ACU research toward general-purpose agents for robust and scalable computer use.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey of agents for computer use (ACUs) that introduces a three-dimensional taxonomy (domain perspective on operating contexts, interaction perspective on observation/action modalities, and agent perspective on perception/reasoning/learning). It reviews 87 ACUs and 33 datasets spanning foundation-model and classical approaches, derives six research gaps (insufficient generalization, inefficient learning, limited planning, low task complexity in benchmarks, non-standardized evaluation, and research-practice disconnect), and proposes targeted directions including vision-based low-level control, adaptive learning, improved planning methods, more complex benchmarks, success-based standardized evaluation, and real-world deployment alignment.
Significance. If the reviewed corpus is representative, the taxonomy supplies a unifying organizational framework for an emerging subfield and the gap analysis usefully highlights actionable priorities such as moving beyond static prompting and aligning benchmarks with deployment constraints. The explicit linkage of gaps to concrete recommendations (e.g., vision-based observations) adds practical value for guiding future ACU work.
major comments (2)
- [Introduction and review sections] The central claim that six specific gaps exist field-wide rests on the representativeness of the 87 ACUs and 33 datasets. No explicit search protocol, inclusion/exclusion criteria, date range, or systematic selection procedure is described (Introduction and the review sections), making it impossible to verify that important classes of systems (closed-source agents, non-English interfaces, or classical non-LLM baselines) were not systematically omitted; any such omission would render the observed gaps in generalization, planning, and benchmark complexity potentially non-representative.
- [Analysis and gap identification sections] The derivation of the six gaps from patterns in the reviewed corpus is presented as following logically from the taxonomy, yet the manuscript provides no quantitative breakdown (e.g., counts or percentages of systems exhibiting each limitation) or inter-rater reliability for the gap assignments, weakening the evidential basis for treating the gaps as load-bearing field-wide conclusions rather than observations within the sampled set.
minor comments (2)
- [Abstract] The abstract states the review covers 'foundation model-based and classical approaches' but does not indicate the temporal scope or search venues, which would aid readers in assessing currency.
- [Figures and tables] Figure and table captions could more explicitly link each entry back to the three taxonomy axes to improve navigability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to improve methodological transparency. We address each major comment below and will revise the manuscript to incorporate additional details on selection procedures and quantitative support for the gap analysis.
read point-by-point responses
-
Referee: [Introduction and review sections] The central claim that six specific gaps exist field-wide rests on the representativeness of the 87 ACUs and 33 datasets. No explicit search protocol, inclusion/exclusion criteria, date range, or systematic selection procedure is described (Introduction and the review sections), making it impossible to verify that important classes of systems (closed-source agents, non-English interfaces, or classical non-LLM baselines) were not systematically omitted; any such omission would render the observed gaps in generalization, planning, and benchmark complexity potentially non-representative.
Authors: We agree that an explicit description of the literature selection process would strengthen the manuscript. Although the reviewed corpus was assembled through targeted searches across arXiv, Google Scholar, and major conferences with the goal of covering both foundation-model and classical approaches, the current version does not detail the protocol. In the revision we will add a new subsection (likely in Section 2 or a dedicated Methodology appendix) specifying the search keywords, databases, date range (papers up to late 2024), inclusion criteria (e.g., systems that perform computer-use tasks via GUI or API actions), and exclusion criteria. We will also explicitly note coverage limitations regarding closed-source commercial agents and non-English interfaces. This addition will allow readers to evaluate representativeness without changing the taxonomy or the six identified gaps. revision: yes
-
Referee: [Analysis and gap identification sections] The derivation of the six gaps from patterns in the reviewed corpus is presented as following logically from the taxonomy, yet the manuscript provides no quantitative breakdown (e.g., counts or percentages of systems exhibiting each limitation) or inter-rater reliability for the gap assignments, weakening the evidential basis for treating the gaps as load-bearing field-wide conclusions rather than observations within the sampled set.
Authors: We accept that quantitative summaries would make the gap claims more robust. In the revised manuscript we will add a table (or inline statistics) reporting, for each of the six gaps, the approximate fraction of the 87 ACUs that exhibit the limitation according to our taxonomy-based analysis. We will also clarify the gap-identification process, which was performed through iterative author discussion and cross-referencing with the taxonomy dimensions rather than independent multi-rater coding. Inter-rater reliability metrics are therefore not applicable to this single-team survey and cannot be supplied; however, we will document the decision criteria used for each gap to improve transparency. These changes constitute a partial revision because the core gap list remains unchanged while the supporting evidence is strengthened. revision: partial
Circularity Check
No circularity: literature survey with independent qualitative analysis
full rationale
This is a survey paper that proposes a three-axis taxonomy, applies it to a corpus of 87 ACUs and 33 datasets, and derives six research gaps from observed patterns in that corpus. No equations, fitted parameters, predictions, or self-referential derivations exist. The central claims rest on qualitative synthesis of external literature rather than any reduction of outputs to inputs by construction, self-citation chains, or ansatzes. The representativeness of the reviewed set is an explicit methodological assumption but does not create circularity, as the gaps are presented as observations from the sample rather than tautological restatements of the selection criteria. The paper is self-contained as a review and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 11 Pith papers
-
ReVision: Scaling Computer-Use Agents via Temporal Visual Redundancy Reduction
ReVision reduces visual token usage by 46% on average in agent trajectories via a learned patch selector and improves success rates by 3% on three benchmarks, showing that history saturation stems from inefficient rep...
-
From Task to Tutorial: An Automated GUI Framework for Excel Tutorial Document and Video Creation
An AI framework automates Excel tutorial and video creation from task descriptions via an Execution Agent, achieving 8.5% higher task success and 1/20th the authoring time of experts.
-
WebMall -- A Multi-Shop Benchmark for Evaluating Web Agents
WebMall is the first offline multi-shop benchmark for evaluating LLM web agents on complex comparison shopping tasks across heterogeneous product data from multiple simulated e-shops.
-
ReVision: Scaling Computer-Use Agents via Temporal Visual Redundancy Reduction
ReVision reduces visual tokens in computer-use agent histories by 46% on average and raises success rates by 3% by learning to drop redundant patches across screenshots, allowing longer histories to keep improving per...
-
Quantifying Trust: Financial Risk Management for Trustworthy AI Agents
The paper introduces the Agentic Risk Standard (ARS) as a payment settlement framework that delivers predefined compensation for AI agent execution failures, misalignment, or unintended outcomes.
-
VeriOS: Query-Driven Proactive Human-Agent-GUI Interaction for Trustworthy OS Agents
VeriOS-Agent is an OS agent that proactively queries humans in untrustworthy scenarios via a query-driven framework and three-stage training, achieving 19.72% higher step-wise success rate over baselines while preserv...
-
GUI Agents with Reinforcement Learning: Toward Digital Inhabitants
The paper delivers the first comprehensive overview of RL for GUI agents, organizing methods into offline, online, and hybrid strategies while analyzing trends in rewards, efficiency, and deliberation to outline a fut...
-
Neural Computers
Neural Computers are introduced as a new machine form where computation, memory, and I/O are unified in a learned runtime state, with initial video-model experiments showing acquisition of basic interface primitives f...
-
How Far Are We from Generating Missing Modalities with Foundation Models?
Evaluates 42 variants of foundation models across three formalized paradigms for missing modality reconstruction, identifies shortfalls in semantic extraction and validation, and introduces an agentic framework that r...
-
InfantAgent-Next: A Multimodal Generalist Agent for Automated Computer Interaction
InfantAgent-Next integrates tool-based and vision agents in a modular architecture and reports 7.27% accuracy on OSWorld, exceeding Claude-Computer-Use while also testing on GAIA and SWE-Bench.
-
Large Language Model-Brained GUI Agents: A Survey
A survey consolidating frameworks, data practices, large action models, benchmarks, applications, and research gaps in LLM-brained GUI agents.
Reference graph
Works this paper leans on
-
[1]
Halima Abukadah, Moghis Fereidouni, and A.B. Siddique. 2024. Mapping Natural Language Intents to User Interfaces through Vision- Language Models. InProc. of the 18th ICSC. IEEE, Laguna Hills, CA, USA, 237–244. https://doi.org/10.1109/ICSC59802.2024.00045
-
[2]
Anthropic. 2024. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://www.anthropic.com/news/3-5- models-and-computer-use
work page 2024
-
[3]
Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. 2017. Deep reinforcement learning: A brief survey.IEEE Signal Processing Magazine34, 6 (2017), 26–38. https://doi.org/10.1109/MSP.2017.2743240
-
[4]
Rim Assouel, Tom Marty, Massimo Caccia, Issam H. Laradji, Alexandre Drouin, Sai Rajeswar, Hector Palacios, Quentin Cappart, David Vazquez, Nicolas Chapados, Maxime Gasse, and Alexandre Lacoste. 2023. The unsolved challenges of LLMs as generalist web agents: A case study. InProc. of the 37th Int. Conf. on NeurIPS: Foundation Models for Decision Making Work...
work page 2023
-
[5]
Gilles Baechler, Srinivas Sunkara, Maria Wang, Fedir Zubach, Hassan Mansoor, Vincent Etter, Victor Carbune, Jason Lin, Jindong Chen, and Abhanshu Sharma. 2024. ScreenAI: A Vision-Language Model for UI and Infographics Understanding. InProc. of the 33rd IJCAI. IJCAI, Jeju, Korea, 3058–3068. https://doi.org/10.24963/ijcai.2024/339
-
[6]
Bowen Baker, Ilge Akkaya, Peter Zhokhov, Joost Huizinga, Jie Tang, Adrien Ecoffet, Brandon Houghton, Raul Sampedro, and Jeff Clune
-
[7]
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos. InProc. of the 36th Int. Conf. on NeurIPS, Vol. 35. Curran Associates, Inc., New Orleans, LA, USA, 24639–24654
-
[8]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. 2009. Curriculum learning. InProc. of the 26th ICML. PMLR, Montreal, QC, Canada, 41–48. https://doi.org/10.1145/1553374.1553380
-
[9]
William E Bishop, Alice Li, Christopher Rawles, and Oriana Riva. 2024. Latent State Estimation Helps UI Agents to Reason. https: //doi.org/10.48550/arXiv.2405.11120
-
[10]
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, Lawrence Jang, and Zack Hui. 2024. Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale. https: //doi.org/10.48550/arXiv.2409.08264
-
[11]
Branavan, Harr Chen, Luke Zettlemoyer, and Regina Barzilay
S.R.K. Branavan, Harr Chen, Luke Zettlemoyer, and Regina Barzilay. 2009. Reinforcement Learning for Mapping Instructions to Actions. InProc. of the Joint Conf. of the 47th Annual Meeting of the ACL and the 4th IJCNLP. ACL, Suntec, Singapore, 82–90
work page 2009
-
[12]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
-
[13]
Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, and Bryan A. Plummer. 2022. A dataset for interactive vision-language navigation with unknown command feasibility. InProceedings of the ECCV. Springer Nature Switzerland, Tel Aviv, Israel, 312–328. https://doi.org/10.1007/978-3-031-20074-8_18
-
[14]
Hyungjoo Chae, Namyoung Kim, Kai Tzu-iunn Ong, Minju Gwak, Gwanwoo Song, Jihoon Kim, Sunghwan Kim, Dongha Lee, and Jinyoung Yeo. 2024. Web Agents with World Models: Learning and Leveraging Environment Dynamics in Web Navigation. https://doi.org/10.48550/arXiv.2410.13232
-
[15]
Tathagata Chakraborti, Vatche Isahagian, Rania Khalaf, Yasaman Khazaeni, Vinod Muthusamy, Yara Rizk, and Merve Unuvar. 2020. From Robotic Process Automation to Intelligent Process Automation: Emerging Trends. InBusiness Process Management: Blockchain and Robotic Process Automation Forum. Springer International Publishing, Seville, Spain, 215–228. https://...
-
[16]
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, and Lichao Sun. 2024. GUI-WORLD: A dataset for GUI-oriented multimodal LLM-based agents. https://doi.org/10.48550/arXiv.2406.10819
-
[17]
Qi Chen, Dileepa Pitawela, Chongyang Zhao, Gengze Zhou, Hsiang-Ting Chen, and Qi Wu. 2024. WebVLN: Vision-and-Language Navigation on Websites.Proc. of the AAAI Conf. on AI38, 2 (2024), 1165–1173. https://doi.org/10.1609/aaai.v38i2.27878
-
[18]
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2024. GUICourse: From general vision language models to versatile GUI agents. https://doi.org/10.48550/arXiv.2406.11317
-
[19]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.TMLR2023 (2023). https://openreview.net/forum?id=YfZ4ZPt8zd
work page 2023
-
[20]
Xingyu Chen, Zihan Zhao, Lu Chen, JiaBao Ji, Danyang Zhang, Ao Luo, Yuxuan Xiong, and Kai Yu. 2021. WebSRC: A Dataset for Web-Based Structural Reading Comprehension. InProc. of the Conf. on EMNLP. ACL, Punta Cana, Dominican Republic, 4173–4185. https://doi.org/10.18653/v1/2021.emnlp-main.343 Agents for Computer Use•6:31
-
[21]
Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Li YanTao, Jianbing Zhang, and Zhiyong Wu. 2024. SeeClick: Harnessing GUI grounding for advanced visual GUI agents. InProc. of the 62nd Annual Meeting of the ACL. ACL, Bangkok, Thailand, 9313–9332. https://doi.org/10.18653/v1/2024.acl-long.505
-
[22]
Junhee Cho, Jihoon Kim, Daseul Bae, Jinho Choo, Youngjune Gwon, and Yeong-Dae Kwon. 2024. CAAP: Context-aware action planning prompting to solve computer tasks with front-end UI only. https://doi.org/10.48550/arXiv.2406.06947
-
[23]
Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Alex Castro-Ros, Marie Pellat, Kevin Robinson, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping H...
-
[24]
Scaling Instruction-Finetuned Language Models.JMLR25, 70 (2024), 1–53
work page 2024
-
[25]
Tassnim Dardouri, Laura Minkova, Jessica López Espejel, Walid Dahhane, and El Hassane Ettifouri. 2024. Visual Grounding for Desktop Graphical User Interfaces. https://doi.org/10.48550/arXiv.2407.01558
-
[26]
Emilia David. 2025. Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku. https://venturebeat.com/ai/openais- agentic-era-begins-chatgpt-tasks-offers-job-scheduling-reminders-and-more/
work page 2025
-
[27]
Borges Jr., and Andreas Zeller
Christian Degott, Nataniel P. Borges Jr., and Andreas Zeller. 2019. Learning user interface element interactions. InProc. of the 28th ACM SIGSOFT Int. Symposium on Software Testing and Analysis. ACM, Beijing China, 296–306. https://doi.org/10.1145/3293882.3330569
-
[28]
Shihan Deng, Weikai Xu, Hongda Sun, Wei Liu, Tao Tan, Liujianfeng Liujianfeng, Ang Li, Jian Luan, Bin Wang, Rui Yan, and Shuo Shang. 2024. Mobile-Bench: An evaluation benchmark for LLM-based mobile agents. InProc. of the 62nd Annual Meeting of the ACL. ACL, Bangkok, Thailand, 8813–8831. https://doi.org/10.18653/v1/2024.acl-long.478
-
[29]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a generalist agent for the web. InProc. of the 37th Int. Conf. on NeurIPS. Curran Associates, Inc., New Orleans, LA, USA, 28091–28114
work page 2023
-
[30]
Yang Deng, Xuan Zhang, Wenxuan Zhang, Yifei Yuan, See-Kiong Ng, and Tat-Seng Chua. 2024. On the multi-turn instruction following for conversational web agents. InProc. of the 62nd Annual Meeting of the ACL. ACL, Bangkok, Thailand, 8795–8812. https://doi.org/10.18653/v1/2024.acl-long.477
- [31]
-
[32]
Nicolai Dorka, Janusz Marecki, and Ammar Anwar. 2024. Training a Vision Language Model as Smartphone Assistant. https: //doi.org/10.48550/arXiv.2404.08755
-
[33]
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Léo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. 2024. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?. InProc. of the 41st ICML. PMLR, Vienna, Austria, 11642–11662
work page 2024
-
[34]
Moghis Fereidouni and A. B. Siddique. 2024. Search beyond queries: Training smaller language models for web interactions via reinforcement learning. https://doi.org/10.48550/arXiv.2404.10887
-
[35]
Yogesh Fulpagare, Kuei-Ru Huang, Ying-Hao Liao, and Chi-Chuan Wang. 2022. Optimal energy management for air cooled server fans using deep reinforcement learning control method.Energy and Buildings277 (2022), 112542. https://doi.org/10.1016/j.enbuild.2022. 112542
-
[36]
H. Furuta, K.-H. Lee, O. Nachum, Y. Matsuo, A. Faust, S. S. Gu, and I. Gur. 2024. Multimodal web navigation with instruction-finetuned foundation models. InProc. of the 12th ICLR. OpenReview.net, Singapore. https://openreview.net/forum?id=upKyBTClJm
work page 2024
-
[37]
Hiroki Furuta, Yutaka Matsuo, Aleksandra Faust, and Izzeddin Gur. 2023. Exposing limitations of language model agents in sequential- task compositions on the web. https://doi.org/10.48550/arXiv.2311.18751
-
[38]
Difei Gao, Lei Ji, Zechen Bai, Mingyu Ouyang, Peiran Li, Dongxing Mao, Qinchen Wu, Weichen Zhang, Peiyi Wang, Xiangwu Guo, Hengxu Wang, Luowei Zhou, and Mike Zheng Shou. 2024. ASSISTGUI: Task-oriented desktop graphical user interface automation. https://doi.org/10.48550/arXiv.2312.13108
-
[39]
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program- aided language models. InProc. of the 40th ICML. PMLR, Honolulu, Hawaii, USA, 10764–10799
work page 2023
-
[40]
Minghe Gao, Wendong Bu, Bingchen Miao, Yang Wu, Yunfei Li, Juncheng Li, Siliang Tang, Qi Wu, Yueting Zhuang, and Meng Wang
-
[41]
https://doi.org/10.48550/arXiv.2411.10943
Generalist Virtual Agents: A Survey on Autonomous Agents Across Digital Platforms. https://doi.org/10.48550/arXiv.2411.10943
-
[42]
Robert Geirhos, Jörn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Felix A Wichmann
-
[43]
Shortcut learning in deep neural networks.Nature Machine Intelligence2, 11 (2020), 665–673
work page 2020
-
[44]
Google Deepmind. 2024. Project Mariner: A research prototype exploring the future of human-agent interaction, starting with your browser. https://deepmind.google/technologies/project-mariner/. Accessed 24 January 2025
work page 2024
- [45]
-
[46]
Sorin Grigorescu, Bogdan Trasnea, Tiberiu Cocias, and Gigel Macesanu. 2020. A Survey of Deep Learning Techniques for Autonomous Driving.Journal of Field Robotics37, 3 (2020), 362–386. https://doi.org/10.1002/rob.21918 6:32•Sager et al
-
[47]
Yanchu Guan, Dong Wang, Zhixuan Chu, Shiyu Wang, Feiyue Ni, Ruihua Song, Longfei Li, Jinjie Gu, and Chenyi Zhuang. 2023. Intelligent Virtual Assistants with LLM-based Process Automation. InProc. of the 30th ACM SIGKDD Conf. on Knowledge Discovery and Data Mining. ACM, Barcelona, Spain, 5018–5027. https://doi.org/10.1145/3637528.3671646
-
[48]
Yiduo Guo, Zekai Zhang, Yaobo Liang, Dongyan Zhao, and Nan Duan. 2024. PPTC benchmark: Evaluating large language models for PowerPoint task completion. InFindings of the ACL. ACL, Bangkok, Thailand, 8682–8701. https://doi.org/10.18653/v1/2024.findings- acl.514
-
[49]
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. 2024. StableToolBench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the ACL. ACL, Bangkok, Thailand, 11143–11156. https://doi.org/10.18653/v1/2024.findings-acl.664
-
[50]
I. Gur, H. Furuta, A. V. Huang, M. Safdari, Y. Matsuo, D. Eck, and A. Faust. 2024. A real-world webagent with planning, long context understanding, and program synthesis. InProc. of the 12th ICLR. OpenReview.net, Singapore. https://openreview.net/forum?id= 3XBcMehKcH
work page 2024
-
[51]
Izzeddin Gur, Natasha Jaques, Yingjie Miao, Jongwook Choi, Manoj Tiwari, Honglak Lee, and Aleksandra Faust. 2021. Environment Generation for Zero-Shot Compositional Reinforcement Learning. InProc. of the 34th Int. Conf. on NeurIPS, Vol. 34. Curran Associates, Inc., virtual, 4157–4169
work page 2021
-
[52]
Izzeddin Gur, Ofir Nachum, Yingjie Miao, Mustafa Safdari, Austin Huang, Aakanksha Chowdhery, Sharan Narang, Noah Fiedel, and Aleksandra Faust. 2023. Understanding HTML with large language models. InEmpirical Methods in Natural Language Processing. ACL, Singapore, 2803–2821. https://doi.org/10.18653/v1/2023.findings-emnlp.185
-
[53]
Izzeddin Gur, Ulrich Rückert, Aleksandra Faust, and Dilek Hakkani-Tür. 2019. Learning to navigate the web. InProc. of the 7th ICLR. OpenReview.net, New Orleans, LA, USA. https://openreview.net/pdf?id=BJemQ209FQ
work page 2019
-
[54]
David Ha and Jürgen Schmidhuber. 2018. Recurrent World Models Facilitate Policy Evolution. InProc. of the 32st Int. Conf. on NeurIPS, Vol. 31. Curran Associates, Inc., Montréal, Quebec, Canada
work page 2018
-
[55]
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. 2025. Mastering diverse control tasks through world models. Nature640, 8059 (April 2025), 647–653. https://doi.org/10.1038/s41586-025-08744-2
-
[56]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. 2024. WebVoyager: Building an end-to-end web agent with large multimodal models. InProc. of the 62nd Annual Meeting of the ACL. ACL, Bangkok, Thailand, 6864–6890. https://doi.org/10.18653/v1/2024.acl-long.371
-
[57]
Zecheng He, Srinivas Sunkara, Xiaoxue Zang, Ying Xu, Lijuan Liu, Nevan Wichers, Gabriel Schubiner, Ruby Lee, and Jindong Chen
-
[58]
ActionBert: Leveraging User Actions for Semantic Understanding of User Interfaces.Proc. of the AAAI Conf. on AI35, 7 (2021), 5931–5938. https://doi.org/10.1609/aaai.v35i7.16741
-
[59]
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. 2024. CogAgent: A visual language model for GUI agents. InProc. of the IEEE/CVF Conf. on CVPR. IEEE, Seattle, WA, USA, 14281–14290. https://doi.org/10.1109/CVPR52733.2024.01354
-
[60]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. LoRA: Low-Rank Adaptation of Large Language Models. https://doi.org/10.48550/arXiv.2106.09685
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2106.09685 2021
-
[61]
Siyuan Hu, Mingyu Ouyang, Difei Gao, and Mike Zheng Shou. 2024. The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use. https://doi.org/10.48550/arXiv.2411.10323
-
[62]
Drew A Hudson and Christopher D Manning. 2019. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProc. of the IEEE/CVF Conf. on CVPR. IEEE, Long Beach, CA, USA, 6700–6709. https://doi.org/10.1109/CVPR.2019.00686
-
[63]
Jez Humble and David Farley. 2011.Continuous delivery: reliable software releases through build, test, and deployment automation(7th edition ed.). Addison-Wesley, Boston, MA, USA
work page 2011
-
[64]
Peter C Humphreys, David Raposo, Tobias Pohlen, Gregory Thornton, Rachita Chhaparia, Alistair Muldal, Josh Abramson, Petko Georgiev, Adam Santoro, and Timothy Lillicrap. 2022. A data-driven approach for learning to control computers. InProc. of the 39th ICML. PMLR, Baltimore, Maryland, USA, 9466–9482
work page 2022
-
[65]
Taichi Iki and Akiko Aizawa. 2022. Do BERTs learn to use browser user interface? Exploring multi-step tasks with unified vision-and- language BERTs. https://doi.org/10.48550/arXiv.2203.07828
-
[66]
S. Jia, J. Kiros, and J. Ba. 2019. DOM-Q-NET: Grounded RL on structured language. InProc. of the 7th ICLR. OpenReview.net, New Orleans, LA, USA. https://openreview.net/forum?id=HJgd1nAqFX
work page 2019
-
[67]
Subbarao Kambhampati. 2024. Can Large Language Models Reason and Plan?Annals of the New York Academy of Sciences(2024), nyas.15125. https://doi.org/10.1111/nyas.15125
-
[68]
Raghav Kapoor, Yash Parag Butala, Melisa Russak, Jing Yu Koh, Kiran Kamble, Waseem Alshikh, and Ruslan Salakhutdinov. 2024. OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web. InProceedings of the ECCV. Springer-Verlag, Milan, Italy, 161–178. https://doi.org/10.1007/978-3-031-73113-6_10
-
[69]
Jihyung Kil, Chan Hee Song, Boyuan Zheng, Xiang Deng, Yu Su, and Wei-Lun Chao. 2024. Dual-view visual contextualization for web navigation. InProc. of the IEEE/CVF Conf. on CVPR. IEEE, Seattle WA, USA, 14445–14454. Agents for Computer Use•6:33
work page 2024
-
[70]
Geunwoo Kim, Pierre Baldi, and Stephen McAleer. 2023. Language models can solve computer tasks. InProc. of the 37th Int. Conf. on NeurIPS. Curran Associates, Inc., New Orleans, LA, USA, 39648–39677
work page 2023
-
[71]
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. 2024. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InProc. of the 62nd Annual Meeting of the ACL. ACL, Bangkok, Thailand, 881–905. https://doi.org/10.18653/v1/2024.acl-long.50
-
[72]
Jing Yu Koh, Stephen McAleer, Daniel Fried, and Ruslan Salakhutdinov. 2024. Tree Search for Language Model Agents. https: //doi.org/10.48550/arXiv.2407.01476
-
[73]
Yilun Kong, Jingqing Ruan, Yihong Chen, Bin Zhang, Tianpeng Bao, Shiwei Shi, Guoqing Du, Xiaoru Hu, Hangyu Mao, Ziyue Li, Xingyu Zeng, and Rui Zhao. 2023. TPTU-v2: Boosting Task Planning and Tool Usage of Large Language Model-based Agents in Real-world Systems. InProc. of the Conf. on EMNLP: Industry Track. ACL, Singapore, 371–385. https://doi.org/10.1865...
-
[74]
Yavuz Koroglu, Alper Sen, Ozlem Muslu, Yunus Mete, Ceyda Ulker, Tolga Tanriverdi, and Yunus Donmez. 2018. QBE: QLearning-based exploration of Android applications. InProc. of the 11th ICST. IEEE, New York, NY, USA, 105–115. https://doi.org/10.1109/ICST.2018.00020
-
[75]
Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, and Jie Tang. 2024. AutoWebGLM: Bootstrap and reinforce a large language model-based web navigating agent. https: //doi.org/10.48550/arXiv.2404.03648
-
[76]
Yann LeCun. 2022. A Path Towards Autonomous Machine Intelligence.Open Review(2022). https://openreview.net/pdf?id=BZ5a1r-kVsf
work page 2022
-
[77]
Juyong Lee, Taywon Min, Minyong An, Dongyoon Hahm, Haeone Lee, Changyeon Kim, and Kimin Lee. 2024. Benchmarking Mobile Device Control Agents across Diverse Configurations. https://doi.org/10.48550/arXiv.2404.16660
-
[78]
Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. 2023. Pix2Struct: Screenshot parsing as pretraining for visual language understanding. InProc. of the 40th ICML. PMLR, Honolulu, Hawaii, USA
work page 2023
-
[79]
Ko, Sangeun Oh, and Insik Shin
Sunjae Lee, Junyoung Choi, Jungjae Lee, Hojun Choi, Steven Y. Ko, Sangeun Oh, and Insik Shin. 2023. Explore, Select, Derive, and Recall: Augmenting LLM with Human-like Memory for Mobile Task Automation. https://doi.org/10.48550/arXiv.2312.03003
-
[80]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. InProc. of the 34th Int. Conf. on NeurIPS, Vol. 33. Curran Associates, Inc., virtual, 9459–9474
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.