MIST: A Co-Design Framework for Heterogeneous, Multi-Stage LLM Inference
Pith reviewed 2026-05-22 21:12 UTC · model grok-4.3
The pith
MIST simulates multi-stage LLM inference across heterogeneous hardware to evaluate configurations without exhaustive real-world testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MIST is a Heterogeneous Multi-stage LLM inference Execution Simulator that models diverse request stages including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. It supports heterogeneous clients executing multiple models concurrently, incorporates advanced batching strategies and multi-level memory hierarchies, and integrates real hardware traces with analytical modeling to capture trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments.
What carries the argument
MIST, the simulator that integrates real hardware traces with analytical modeling to predict performance across multi-stage pipelines on diverse hardware.
If this is right
- Designers can quantify how reasoning stages affect overall latency.
- Batching strategies for pipelines that mix CPU and accelerator resources become identifiable through simulation.
- The effects of remote KV cache retrieval on system architecture can be assessed without building full systems.
- Navigation of large configuration spaces becomes feasible at lower cost than cloud-based exhaustive testing.
Where Pith is reading between the lines
- The same trace-plus-model approach could apply to evaluating power draw or thermal limits in staged inference systems.
- Standardized test suites for multi-stage serving might emerge if simulators like this see wider use.
- Similar modeling could support early-stage design of inference systems for non-LLM workloads that also feature sequential stages.
Load-bearing premise
Combining real hardware traces with analytical modeling captures the main performance trade-offs without needing complete physical benchmarking.
What would settle it
Running a set of actual deployments on selected configurations and measuring whether the simulator's latency and cost predictions match the observed values within acceptable error.
Figures


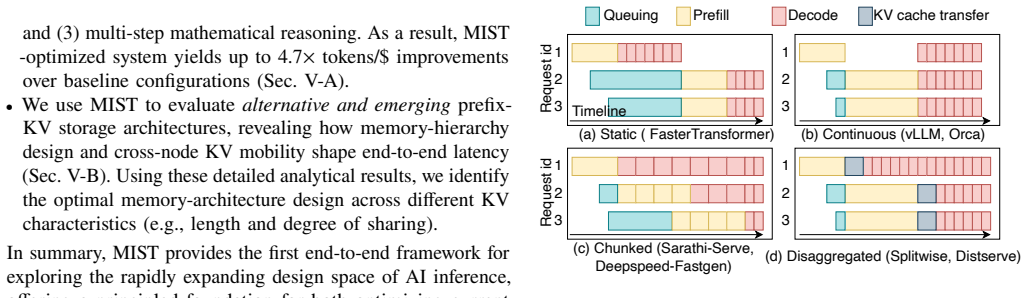








read the original abstract
Modern LLM serving now spans multi-stage pipelines including RAG retrieval and KV cache reuse, each with distinct compute, memory, and latency demands. Inference engines expose a large configuration space with no systematic navigation methodology, and exhaustively benchmarking configurations can exceed 40K in cloud costs. Simultaneously, the hardware landscape is rapidly diversifying across AMD GPUs, TPUs, and custom ASICs, while cross-vendor prefill-decode (PD) disaggregated configurations lack unified software stacks for end-to-end evaluation today. To address this gap, we present MIST, a Heterogeneous Multi-stage LLM inference Execution Simulator. MIST models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. MIST supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, MIST captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. MIST empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MIST, a Heterogeneous Multi-stage LLM inference Execution Simulator for modeling request stages including RAG, KV retrieval, reasoning, prefill, and decode across heterogeneous hardware hierarchies. It supports concurrent multi-model execution, advanced batching, and multi-level memory hierarchies by integrating real hardware traces with analytical modeling to capture trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator and PD-disaggregated setups. Case studies examine the impact of reasoning stages on end-to-end latency, optimal batching for hybrid pipelines, and architectural implications of remote KV cache retrieval, with the central claim that MIST provides actionable co-design insights while avoiding exhaustive benchmarking costs exceeding 40K.
Significance. If the hybrid trace-plus-analytical modeling proves accurate, MIST would address a genuine gap in systematic navigation of large configuration spaces for multi-stage LLM serving on diversifying hardware (AMD GPUs, TPUs, custom ASICs) and could reduce reliance on costly real-system sweeps while enabling exploration of cross-vendor PD disaggregation; the explicit support for heterogeneous concurrent clients and multi-level memory is a concrete strength relative to prior frameworks.
major comments (1)
- [Case studies] Case studies section: the manuscript asserts that real hardware traces plus analytical modeling capture critical trade-offs such as memory bandwidth contention, inter-cluster latency, and batching efficiency, yet supplies no quantitative validation (prediction error, sensitivity analysis, or direct comparisons against measured end-to-end latency on real systems), which is load-bearing for the claim that the resulting insights are actionable.
minor comments (1)
- Notation for stage-specific parameters (e.g., batching strategies, memory hierarchy levels) could be introduced with a single summary table to improve readability across the modeling sections.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable feedback. The major comment highlights an important aspect of the validation of MIST's modeling approach. We address it directly below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: Case studies section: the manuscript asserts that real hardware traces plus analytical modeling capture critical trade-offs such as memory bandwidth contention, inter-cluster latency, and batching efficiency, yet supplies no quantitative validation (prediction error, sensitivity analysis, or direct comparisons against measured end-to-end latency on real systems), which is load-bearing for the claim that the resulting insights are actionable.
Authors: We agree that explicit quantitative validation strengthens the actionability claim. The current manuscript relies on real hardware traces as the basis for the analytical models and demonstrates their use in case studies, but does not report aggregate prediction errors or direct end-to-end latency comparisons for the full simulated pipelines. In the revised version we will add a dedicated validation subsection that includes (1) sensitivity analysis across key parameters such as batch size and memory bandwidth, and (2) direct comparisons of MIST-predicted latencies against measured values on the same hardware configurations used to collect the traces. These additions will be placed in the case studies section to directly support the trade-off insights. revision: yes
Circularity Check
No circularity: new simulator framework with no self-referential derivations
full rationale
The paper introduces MIST as a novel heterogeneous multi-stage LLM inference simulator that combines real hardware traces with analytical modeling. No equations, fitted parameters presented as predictions, self-citations, or ansatzes appear in the abstract or description that would reduce any claimed result to its inputs by construction. The central claims rest on the framework's ability to model stages like RAG, prefill, and decode across hardware hierarchies, positioned as an independent contribution rather than a tautology. This is a standard non-finding for a systems paper describing a new tool.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hardware traces from real systems can be integrated with analytical models to predict performance accurately.
invented entities (1)
-
MIST simulator
no independent evidence
Forward citations
Cited by 2 Pith papers
-
MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
Chakra introduces a portable, interoperable graph-based execution trace format for distributed ML workloads along with supporting tools to standardize performance benchmarking and software-hardware co-design.
-
MLCommons Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces
Chakra introduces a standardized graph-based execution trace representation for distributed ML workloads along with supporting tools to enable benchmarking, analysis, generation, and co-design across simulators and hardware.
Reference graph
Works this paper leans on
-
[1]
Automatic prefix caching — vllm,
“Automatic prefix caching — vllm,” [Online; accessed 2025-04- 11]. [Online]. Available: https://docs.vllm.ai/en/latest/design/v1/prefix caching.html
work page 2025
-
[2]
Dynamo inference framework — nvidia developer,
“Dynamo inference framework — nvidia developer,” [Online; accessed 2025-04-10]. [Online]. Available: https://developer.nvidia.com/dynamo
work page 2025
-
[3]
What is prefix caching? a beginner’s guide - ai resources,
“What is prefix caching? a beginner’s guide - ai resources,” [Online; accessed 2025-04-11]. [Online]. Available: https://www.modular.com/ ai-resources/what-is-prefix-caching-a-beginner-s-guide
work page 2025
-
[4]
Choose the k-nn algorithm for your billion-scale use case with opensearch — aws big data blog,
“Choose the k-nn algorithm for your billion-scale use case with opensearch — aws big data blog,” 9 2022, [Online; accessed 2025-04-11]. [Online]. Available: https://aws.amazon.com/blogs/big-data/ choose-the-k-nn-algorithm-for-your-billion-scale-use-case-with-opensearch/
work page 2022
-
[5]
Vidur: A large-scale simulation framework for llm inference,
A. Agrawal, N. Kedia, J. Mohan, A. Panwar, N. Kwatra, B. Gulavani, R. Ramjee, and A. Tumanov, “Vidur: A large-scale simulation framework for llm inference,” 2024. [Online]. Available: https: //arxiv.org/abs/2405.05465
-
[6]
Taming throughput-latency tradeoff in llm inference with sarathi-serve,
A. Agrawal, N. Kedia, A. Panwar, J. Mohan, N. Kwatra, B. S. Gulavani, A. Tumanov, and R. Ramjee, “Taming throughput-latency tradeoff in llm inference with sarathi-serve,”Proceedings of 18th USENIX Symposium on Operating Systems Design and Implementation, 2024, Santa Clara, 2024
work page 2024
-
[7]
Large language models for mathematical reasoning: Progresses and challenges,
J. Ahn, R. Verma, R. Lou, D. Liu, R. Zhang, and W. Yin, “Large language models for mathematical reasoning: Progresses and challenges,”
-
[8]
Large language models for mathematical reasoning: Progresses and challenges
[Online]. Available: https://arxiv.org/abs/2402.00157
-
[9]
Sharegpt vicuna datasets at hugging face,
anon823116, “Sharegpt vicuna datasets at hugging face,” 2024. [Online]. Available: https://huggingface.co/datasets/anon8231489123/ShareGPT Vicuna unfiltered
work page 2024
-
[10]
ns-3 network backend — astra-sim 2.2 documentation,
Astra-Sim, “ns-3 network backend — astra-sim 2.2 documentation,” [Online; accessed 2025-06-19]. [Online]. Available: https://astra-sim. github.io/astra-sim-docs/network-backend/ns3-network-backend.html
work page 2025
-
[11]
Azure Public Dataset: Azure LLM Inference Trace 2023,
M. Azure, “Azure Public Dataset: Azure LLM Inference Trace 2023,” https://github.com/Azure/AzurePublicDataset/blob/master/ AzureLLMInferenceDataset2023.md, 2023, accessed: 2025-04-10
work page 2023
-
[12]
Demystifying platform requirements for diverse llm inference use cases,
A. Bambhaniya, R. Raj, G. Jeong, S. Kundu, S. Srinivasan, M. Elavazha- gan, M. Kumar, and T. Krishna, “Demystifying platform requirements for diverse llm inference use cases,”arXiv preprint arXiv:2406.01698, 2024
-
[13]
Do large language models need a content delivery network?
Y. Cheng, K. Du, J. Yao, and J. Jiang, “Do large language models need a content delivery network?”arXiv preprint arXiv:2409.13761, 2024
-
[14]
Lmcache: An efficient kv cache layer for enterprise-scale llm inference,
Y. Cheng, Y. Liu, J. Yao, Y. An, X. Chen, S. Feng, Y. Huang, S. Shen, K. Du, and J. Jiang, “Lmcache: An efficient kv cache layer for enterprise-scale llm inference,” 2025. [Online]. Available: https://arxiv.org/abs/2510.09665
-
[15]
Accelerating vector search: Nvidia cuvs ivf-pq part 1, deep dive — nvidia technical blog,
A. Chirkin, “Accelerating vector search: Nvidia cuvs ivf-pq part 1, deep dive — nvidia technical blog,” 7 2024, [Online; accessed 2025-03-08]. [Online]. Available: https://developer.nvidia.com/blog/ accelerating-vector-search-nvidia-cuvs-ivf-pq-deep-dive-part-1/
work page 2024
-
[16]
Llmservingsim: A hw/sw co-simulation infrastructure for llm inference serving at scale,
J. Cho, M. Kim, H. Choi, G. Heo, and J. Park, “Llmservingsim: A hw/sw co-simulation infrastructure for llm inference serving at scale,”
-
[17]
Available: https://arxiv.org/abs/2408.05499
[Online]. Available: https://arxiv.org/abs/2408.05499
-
[18]
A complete survey on llm-based ai chatbots,
S. K. Dam, C. S. Hong, Y. Qiao, and C. Zhang, “A complete survey on llm-based ai chatbots,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.16937
-
[19]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” 2024. [Online]. Available: https://arxiv.org/abs/2312.10997
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models
S. Gehman, S. Gururangan, M. Sap, Y. Choi, and N. A. Smith, “Realtoxicityprompts: Evaluating neural toxic degeneration in language models,” 2020. [Online]. Available: https://arxiv.org/abs/2009.11462
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[21]
Introducing gemini: Google’s most capable ai model yet,
Google, “Introducing gemini: Google’s most capable ai model yet,” 2023. [Online]. Available: https://blog.google/technology/ai/google-gemini-ai/
work page 2023
-
[22]
Benchmark Persistent Disk performance on a Linux VM,
Google Cloud, “Benchmark Persistent Disk performance on a Linux VM,” https://cloud.google.com/compute/docs/disks/ benchmarking-pd-performance-linux, 2025, last updated: 2025-08-07; Accessed: 2025-08-20
work page 2025
-
[23]
OpenThoughts: Data Recipes for Reasoning Models
E. Guha, R. Marten, S. Keh, N. Raoof, G. Smyrnis, H. Bansal, M. Nezhurina, J. Mercat, T. Vu, Z. Sprague, A. Suvarna, B. Feuer, L. Chen, Z. Khan, E. Frankel, S. Grover, C. Choi, N. Muennighoff, S. Su, W. Zhao, J. Yang, S. Pimpalgaonkar, K. Sharma, C. C.-J. Ji, Y. Deng, S. Pratt, V. Ramanujan, J. Saad-Falcon, J. Li, A. Dave, A. Albalak, K. Arora, B. Wulfe, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Reasoning with Language Model is Planning with World Model
S. Hao, Y. Gu, H. Ma, J. J. Hong, Z. Wang, D. Z. Wang, and Z. Hu, “Reasoning with language model is planning with world model.” [Online]. Available: http://arxiv.org/abs/2305.14992
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Deepspeed-fastgen: High-throughput text generation for llms via MII and deepspeed-inference
C. Holmes, M. Tanaka, M. Wyatt, A. A. Awan, J. Rasley, S. Rajbhandari, R. Y. Aminabadi, H. Qin, A. Bakhtiari, L. Kurilenkoet al., “Deepspeed- fastgen: High-throughput text generation for llms via mii and deepspeed- inference,”arXiv preprint arXiv:2401.08671, 2024
-
[26]
Atlas: Few-shot learning with retrieval augmented language models,
G. Izacard, P. Lewis, M. Lomeli, L. Hosseini, F. Petroni, T. Schick, J. Dwivedi-Yu, A. Joulin, S. Riedel, and E. Grave, “Atlas: Few-shot learning with retrieval augmented language models,”Journal of Machine Learning Research, vol. 24, no. 251, pp. 1–43, 2023
work page 2023
-
[27]
Intelligent router for llm workloads: Improving performance through workload-aware load balancing,
K. Jain, A. Parayil, A. Mallick, E. Choukse, X. Qin, J. Zhang, ´I˜nigo Goiri, R. Wang, C. Bansal, V. R¨ uhle, A. Kulkarni, S. Kofsky, and S. Rajmohan, “Intelligent router for llm workloads: Improving performance through workload-aware load balancing,” 2025. [Online]. Available: https://arxiv.org/abs/2408.13510
-
[28]
A Survey on Large Language Models for Code Generation
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim, “A survey on large language models for code generation,” 2024. [Online]. Available: https://arxiv.org/abs/2406.00515
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Rago: Systematic performance optimization for retrieval-augmented generation serving,
W. Jiang, S. Subramanian, C. Graves, G. Alonso, A. Yazdanbakhsh, and V. Dadu, “Rago: Systematic performance optimization for retrieval-augmented generation serving,” 2025. [Online]. Available: https://arxiv.org/abs/2503.14649
-
[30]
Billion-scale similarity search with GPUs
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with gpus,” 2017. [Online]. Available: https://arxiv.org/abs/1702.08734
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
Dense Passage Retrieval for Open-Domain Question Answering
V. Karpukhin, B. O ˘guz, S. Min, P. Lewis, L. Wu, S. Edunov, D. Chen, and W. tau Yih, “Dense passage retrieval for open-domain question answering,” 2020. [Online]. Available: https://arxiv.org/abs/2004.04906
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[32]
The NarrativeQA reading comprehension challenge,
T. Koˇcisk´ y, J. Schwarz, P. Blunsom, C. Dyer, K. M. Hermann, G. Melis, and E. Grefenstette, “The NarrativeQA reading comprehension challenge,” Transactions of the Association for Computational Linguistics, vol. 6, pp. 317–328, 2018. [Online]. Available: https://aclanthology.org/Q18-1023
work page 2018
-
[33]
H. Kwon, P. Chatarasi, V. Sarkar, T. Krishna, M. Pellauer, and A. Parashar, “Maestro: A data-centric approach to understand reuse, performance, and hardware cost of dnn mappings,”IEEE Micro, vol. 40, no. 3, pp. 20–29, 2020
work page 2020
-
[34]
Efficient Memory Management for Large Language Model Serving with PagedAttention , booktitle =
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th Symposium on Operating Systems Principles, ser. SOSP ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 611–626. [Online]. Available:...
-
[35]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
work page 2023
-
[36]
Fast Inference from Transformers via Speculative Decoding
Y. Leviathan, M. Kalman, and Y. Matias, “Fast inference from transformers via speculative decoding,” 2023. [Online]. Available: https://arxiv.org/abs/2211.17192
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. K¨ uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[38]
H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,” 2023. [Online]. Available: https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Parrot: efficient serving of llm-based applications with semantic variable,
C. Lin, Z. Han, C. Zhang, Y. Yang, F. Yang, C. Chen, and L. Qiu, “Parrot: efficient serving of llm-based applications with semantic variable,” in Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation, ser. OSDI’24. USA: USENIX Association, 2024
work page 2024
-
[40]
Cachegen: Kv cache compression and streaming for fast large language model serving,
Y. Liu, H. Li, Y. Cheng, S. Ray, Y. Huang, Q. Zhang, K. Du, J. Yao, S. Lu, G. Ananthanarayananet al., “Cachegen: Kv cache compression and streaming for fast large language model serving,” inProceedings of the ACM SIGCOMM 2024 Conference, 2024, pp. 38–56
work page 2024
-
[41]
Choose the k-nn algorithm for your billion-scale use case with opensearch — aws big data blog,
J. Mazanec and O. Hamzaoui, “Choose the k-nn algorithm for your billion-scale use case with opensearch — aws big data blog,” 9 2022, [Online; accessed 2025-03- 08]. [Online]. Available: https://aws.amazon.com/blogs/big-data/ choose-the-k-nn-algorithm-for-your-billion-scale-use-case-with-opensearch/ 13
work page 2022
-
[42]
Github copilot·your ai pair programmer
MIcrosoft, “Github copilot·your ai pair programmer.” [Online]. Available: https://github.com/features/copilot
-
[43]
Cacti 6.0: A tool to model large caches,
N. Muralimanohar, R. Balasubramonian, and N. P. Jouppi, “Cacti 6.0: A tool to model large caches,”HP laboratories, vol. 27, p. 28, 2009
work page 2009
-
[44]
SplitwiseSim: LLM Serving Cluster Simulator,
Mutinifni, “SplitwiseSim: LLM Serving Cluster Simulator,” https://github. com/Mutinifni/splitwise-sim, 2024, accessed: 2025-04-10
work page 2024
-
[45]
Github - nvidia/fastertransformer: Transformer related optimization, including bert, gpt,
NVIDIA, “Github - nvidia/fastertransformer: Transformer related optimization, including bert, gpt,” [Online; accessed 2025-04-10]. [Online]. Available: https://github.com/NVIDIA/FasterTransformer
work page 2025
- [46]
-
[47]
Timeloop: A systematic approach to dnn accelerator evaluation,
A. Parashar, P. Raina, Y. S. Shao, Y.-H. Chen, V. A. Ying, A. Mukkara, R. Venkatesan, B. Khailany, S. W. Keckler, and J. Emer, “Timeloop: A systematic approach to dnn accelerator evaluation,” in2019 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2019, pp. 304–315
work page 2019
-
[48]
Splitwise: Efficient generative llm inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, ´I˜nigo Goiri, A. Shah, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” 2023
work page 2023
-
[49]
R. Raj, S. Banerjee, N. Chandra, Z. Wan, J. Tong, A. Samajdar, and T. Krishna, “Scale-sim v3: A modular cycle-accurate systolic accelerator simulator for end-to-end system analysis,” 2025. [Online]. Available: https://arxiv.org/abs/2504.15377
-
[50]
ASTRA- SIM: Enabling sw/hw co-design exploration for distributed dl training platforms,
S. Rashidi, S. Sridharan, S. Srinivasan, and T. Krishna, “ASTRA- SIM: Enabling sw/hw co-design exploration for distributed dl training platforms,” inIEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2020
work page 2020
-
[51]
nick007x/github-code-2025·datasets at hugging face,
N. Saga, “nick007x/github-code-2025·datasets at hugging face,” 10 2025, [Online; accessed 2025-11-17]. [Online]. Available: https: //huggingface.co/datasets/nick007x/github-code-2025
work page 2025
-
[52]
Astra: Exploiting predictability to optimize deep learning,
M. Sivathanu, T. Chugh, S. S. Singapuram, and L. Zhou, “Astra: Exploiting predictability to optimize deep learning,” inProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, ser. ASPLOS ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 909–923. [Online]. Avail...
-
[53]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
C. Snell, J. Lee, K. Xu, and A. Kumar, “Scaling llm test-time compute optimally can be more effective than scaling model parameters,” 2024. [Online]. Available: https://arxiv.org/abs/2408.03314
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Q. Team, “Qwen3 technical report,” 2025. [Online]. Available: https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Rubin (microarchitecture) - wikipedia,
C. to Wikimedia projects, “Rubin (microarchitecture) - wikipedia,” 6 2024, [Online; accessed 2025-04-11]. [Online]. Available: https: //en.wikipedia.org/wiki/Rubin (microarchitecture)
work page 2024
-
[56]
Ironwood: The first google tpu for the age of inference,
A. Vahdat, “Ironwood: The first google tpu for the age of inference,” 4 2025, [Online; accessed 2025-04-11]. [Online]. Available: https: //blog.google/products/google-cloud/ironwood-tpu-age-of-inference/
work page 2025
-
[57]
vllm, “Vllm auto tune,” August 2025, [Online; accessed 2025-11- 18]. [Online]. Available: https://github.com/vllm-project/vllm/blob/main/ benchmarks/auto tune/README.md
work page 2025
-
[58]
Add Splitwise Implementation to vLLM,
vLLM contributors, “Add Splitwise Implementation to vLLM,” https: //github.com/vllm-project/vllm/pull/2809, 2024, accessed: 2025-04-10
work page 2024
-
[59]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[60]
W. Won, T. Heo, S. Rashidi, S. Sridharan, S. Srinivasan, and T. Krishna, “Astra-sim2. 0: Modeling hierarchical networks and disaggregated systems for large-model training at scale,” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2023, pp. 283–294
work page 2023
-
[61]
Gandiva: Introspective cluster scheduling for deep learning,
W. Xiao, R. Bhardwaj, R. Ramjee, M. Sivathanu, N. Kwatra, Z. Han, P. Patel, X. Peng, H. Zhao, Q. Zhang, F. Yang, and L. Zhou, “Gandiva: Introspective cluster scheduling for deep learning,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18). Carlsbad, CA: USENIX Association, Oct. 2018, pp. 595–610. [Online]. Available: https:/...
work page 2018
-
[62]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,” 2024. [Online]. Available: https://arxiv.org/abs/ 2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[63]
Cacheblend: Fast large language model serving with cached knowledge fusion
J. Yao, H. Li, Y. Liu, S. Ray, Y. Cheng, Q. Zhang, K. Du, S. Lu, and J. Jiang, “Cacheblend: Fast large language model serving with cached knowledge fusion,”arXiv preprint arXiv:2405.16444, 2024
-
[64]
A runtime-based computational performance predictor for deep neural network training,
G. X. Yu, Y. Gao, P. Golikov, and G. Pekhimenko, “A runtime-based computational performance predictor for deep neural network training,”
-
[65]
Available: https://arxiv.org/abs/2102.00527
[Online]. Available: https://arxiv.org/abs/2102.00527
-
[66]
Orca: A distributed serving system for {Transformer-Based} generative mod- els,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for {Transformer-Based} generative mod- els,” in16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22), 2022, pp. 521–538
work page 2022
-
[67]
A hardware evaluation framework for large language model inference,
H. Zhang, A. Ning, R. Prabhakar, and D. Wentzlaff, “A hardware evaluation framework for large language model inference,”arXiv preprint arXiv:2312.03134, 2023
-
[68]
The Lessons of Developing Process Reward Models in Mathematical Reasoning
Z. Zhang, C. Zheng, Y. Wu, B. Zhang, R. Lin, B. Yu, D. Liu, J. Zhou, and J. Lin, “The lessons of developing process reward models in mathematical reasoning,”arXiv preprint arXiv:2501.07301, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Sglang: Efficient execution of structured language model programs,
L. Zheng, L. Yin, Z. Xie, C. Sun, J. Huang, C. H. Yu, S. Cao, C. Kozyrakis, I. Stoica, J. E. Gonzalez, C. Barrett, and Y. Sheng, “Sglang: Efficient execution of structured language model programs,”
-
[70]
SGLang: Efficient Execution of Structured Language Model Programs
[Online]. Available: https://arxiv.org/abs/2312.07104
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving,
Y. Zhong, S. Liu, J. Chen, J. Hu, Y. Zhu, X. Liu, X. Jin, and H. Zhang, “Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving,” 2024
work page 2024
-
[72]
Daydream: Accurately estimating the efficacy of optimizations for DNN training,
H. Zhu, A. Phanishayee, and G. Pekhimenko, “Daydream: Accurately estimating the efficacy of optimizations for DNN training,” in 2020 USENIX Annual Technical Conference (USENIX ATC 20). USENIX Association, Jul. 2020, pp. 337–352. [Online]. Available: https://www.usenix.org/conference/atc20/presentation/zhu-hongyu 14
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.