KnowRL: Exploring Knowledgeable Reinforcement Learning for Factuality
Pith reviewed 2026-05-19 07:30 UTC · model grok-4.3
The pith
KnowRL integrates a factuality reward into reinforcement learning to reduce hallucinations in slow-thinking language models while preserving reasoning strength.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
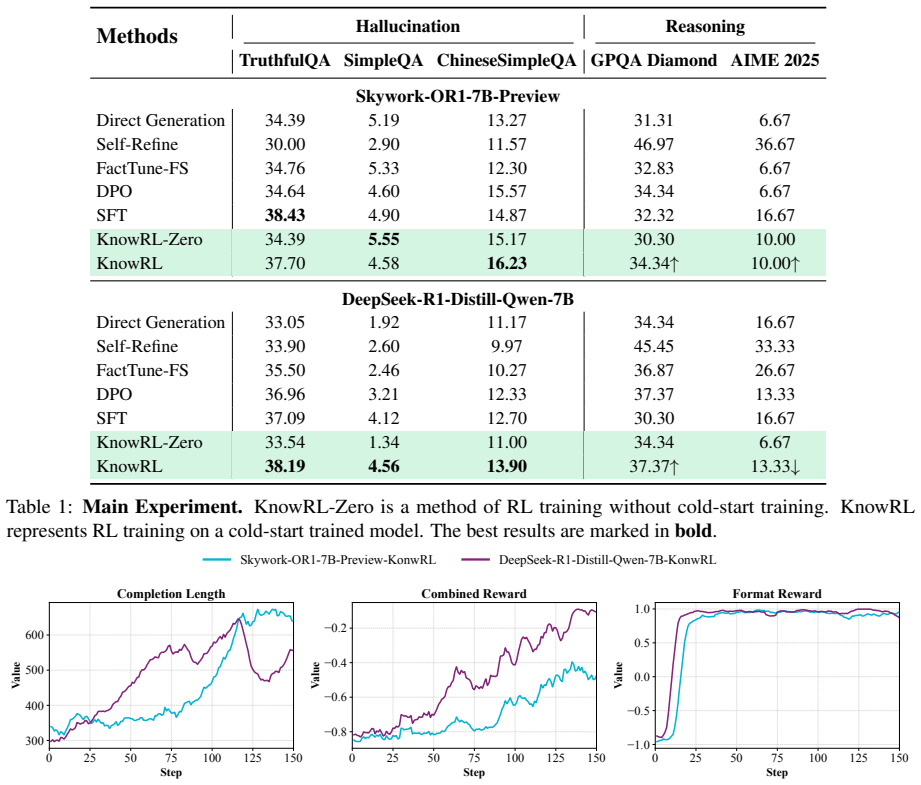
KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process.
What carries the argument
The factuality reward based on knowledge verification, which supplies a per-step signal during RL training that rewards reasoning steps staying inside the model's verified knowledge.
If this is right
- Reasoning traces contain fewer unsupported claims because each step receives direct factual feedback.
- The model maintains its original accuracy on tasks that require multi-step logic or calculation.
- Existing slow-thinking models can adopt the method by adding the reward term without altering their core architecture.
- Training produces internalized strategies that favor checking knowledge boundaries before continuing a chain of thought.
Where Pith is reading between the lines
- Similar per-step factual rewards could be tested on other long-horizon generation tasks such as multi-turn dialogue or code generation.
- Outcome-only rewards in RL may systematically conflict with factuality whenever reasoning length increases.
- If verification sources improve, the same training loop could scale to larger models and broader domains.
Load-bearing premise
The factuality reward based on knowledge verification supplies an accurate and unbiased signal that correctly flags when a reasoning step exceeds the model's knowledge boundaries without adding new errors or selection biases.
What would settle it
Run the trained model on a held-out set of questions whose answers require external knowledge outside the verification source, then measure whether the rate of factual errors drops while scores on separate reasoning benchmarks remain stable.
Figures






read the original abstract
Large Language Models (LLMs), particularly slow-thinking models, often exhibit severe hallucination, outputting incorrect content due to an inability to accurately recognize knowledge boundaries during reasoning. While Reinforcement Learning (RL) can enhance complex reasoning abilities, its outcome-oriented reward mechanism often lacks factual supervision over the thinking process, further exacerbating the hallucination problem. To address the high hallucination in slow-thinking models, we propose Knowledge-enhanced RL, KnowRL. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward, based on knowledge verification, into the RL training process, helping them recognize their knowledge boundaries. This targeted factual input during RL training enables the model to learn and internalize fact-based reasoning strategies. By directly rewarding adherence to facts within the reasoning steps, KnowRL fosters a more reliable thinking process. Experimental results on three hallucination evaluation datasets and two reasoning evaluation datasets demonstrate that KnowRL effectively mitigates hallucinations in slow-thinking models while maintaining their original strong reasoning capabilities. Our code is available at https://github.com/zjunlp/KnowRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes KnowRL, a reinforcement learning framework for slow-thinking LLMs that augments standard outcome-based RL with an additional factuality reward derived from knowledge verification. The method aims to help models recognize their knowledge boundaries during step-by-step reasoning, thereby reducing hallucinations on factual content while preserving performance on reasoning tasks. Experiments are reported on three hallucination benchmarks and two reasoning benchmarks, with the claim that KnowRL achieves lower hallucination rates without degrading reasoning accuracy.
Significance. If the knowledge-verification component supplies a reliable, low-bias training signal, the approach would constitute a concrete, training-time intervention that directly targets the factuality gap in current RL post-training pipelines for LLMs. The combination of maintained reasoning strength with reduced hallucination would be of practical interest to the community working on reliable chain-of-thought systems.
major comments (3)
- [Method] Method section (description of the factuality reward): the manuscript provides no implementation details on how knowledge verification is performed (external LLM judge, retrieval system, or self-verification), how verification errors or uncertainty are quantified, or how the resulting reward is normalized and scaled relative to the outcome reward. Because the central empirical claim rests on this reward supplying an accurate signal for knowledge-boundary violations, the absence of these specifics prevents evaluation of whether the observed hallucination reduction is caused by the proposed mechanism or by correlated artifacts.
- [Experiments] Experimental results (hallucination datasets): no verifier-accuracy statistics, inter-annotator agreement, or ablation that isolates the factuality reward (e.g., RL with only outcome reward vs. full KnowRL) are reported. Without such controls it is impossible to rule out that the measured improvement arises from selection bias in the verifier or from other unstated training differences rather than from the claimed knowledge-boundary supervision.
- [Method] Reward formulation: the paper states that the factuality reward is 'integrated into the RL training process' but supplies neither the mathematical expression for the combined reward nor any analysis of how the two reward components interact during policy optimization. This omission is load-bearing for reproducibility and for understanding whether the method remains stable across different base models.
minor comments (2)
- [Abstract] Abstract contains a verbatim repeated sentence describing the core idea; this should be removed for clarity.
- [Introduction] The GitHub link is provided but the repository contents (training scripts, verifier implementation, exact hyper-parameters) are not referenced in the text; adding a pointer to the relevant files would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and have revised the manuscript to incorporate additional details and controls as suggested.
read point-by-point responses
-
Referee: [Method] Method section (description of the factuality reward): the manuscript provides no implementation details on how knowledge verification is performed (external LLM judge, retrieval system, or self-verification), how verification errors or uncertainty are quantified, or how the resulting reward is normalized and scaled relative to the outcome reward. Because the central empirical claim rests on this reward supplying an accurate signal for knowledge-boundary violations, the absence of these specifics prevents evaluation of whether the observed hallucination reduction is caused by the proposed mechanism or by correlated artifacts.
Authors: We agree that the original submission lacked sufficient implementation specifics in the main text. In the revised manuscript we have added a dedicated subsection under Methods that describes the knowledge verification procedure, which combines retrieval-augmented checking with an external LLM judge, quantifies uncertainty via a confidence threshold, and normalizes the resulting factuality reward before scaling it relative to the outcome reward. These additions allow direct evaluation of the proposed mechanism. revision: yes
-
Referee: [Experiments] Experimental results (hallucination datasets): no verifier-accuracy statistics, inter-annotator agreement, or ablation that isolates the factuality reward (e.g., RL with only outcome reward vs. full KnowRL) are reported. Without such controls it is impossible to rule out that the measured improvement arises from selection bias in the verifier or from other unstated training differences rather than from the claimed knowledge-boundary supervision.
Authors: We acknowledge the value of these controls. The revised Experiments section now includes an ablation comparing outcome-only RL against full KnowRL, reports verifier accuracy on a held-out validation set, and provides inter-annotator agreement for the hallucination labels. These results help isolate the contribution of the factuality reward. revision: yes
-
Referee: [Method] Reward formulation: the paper states that the factuality reward is 'integrated into the RL training process' but supplies neither the mathematical expression for the combined reward nor any analysis of how the two reward components interact during policy optimization. This omission is load-bearing for reproducibility and for understanding whether the method remains stable across different base models.
Authors: We concur that a formal expression and interaction analysis are necessary. The revised Method section now presents the combined reward as a weighted sum R = R_outcome + λ · R_factuality, together with a brief analysis of how the weighting parameter λ affects policy gradient stability across base models. This formulation is also reflected in the released code. revision: yes
Circularity Check
No significant circularity: empirical method with external reward signal
full rationale
The paper proposes KnowRL by integrating an external factuality reward derived from knowledge verification into RL training for slow-thinking LLMs. No equations, derivations, or mathematical chains are present in the abstract or description. The reward mechanism is positioned as an input from verification rather than internally fitted or self-defined, and results are reported on separate hallucination and reasoning evaluation datasets. No load-bearing self-citations, uniqueness theorems, or renamings of known results appear. The central claim therefore does not reduce to its own inputs by construction and remains an empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An external knowledge verification procedure can be run at training time and produces accurate labels for whether each reasoning step stays within the model's knowledge boundaries.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
integrating a factuality reward, based on knowledge verification, into the RL training process... Rfact(o) = min(Nsupported(othink, K)/15, 1.0)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KnowRL guides models to perform fact-based slow thinking by integrating a factuality reward
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Beyond Reasoning: Reinforcement Learning Unlocks Parametric Knowledge in LLMs
RL on binary rewards boosts LLM factual recall by ~27% relative across models by redistributing probability mass to latent correct answers rather than acquiring new knowledge.
-
Only Say What You Know: Calibration-Aware Generation for Long-Form Factuality
Exploration-Commitment Decoupling instantiated as Calibration-Aware Generation improves long-form factuality by up to 13% and reduces decoding time by up to 37% on five benchmarks.
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought reasoning in the wild is not always faithful.arXiv preprint:2503.08679, 2025
Model2vec: Turn any sentence transformer into a small fast model. Iván Arcuschin, Jett Janiak, Robert Krzyzanowski, Senthooran Rajamanoharan, Neel Nanda, and Arthur Conmy. 2025. Chain-of-thought reasoning in the wild is not always faithful. arXiv preprint arXiv:2503.08679. Junwei Bao, Nan Duan, Zhao Yan, Ming Zhou, and Tiejun Zhao. 2016. Constraint-based ...
-
[2]
Alphazero-like tree-search can guide large language model decoding and training,
Alphazero-like tree-search can guide large lan- guage model decoding and training. arXiv preprint arXiv:2309.17179. Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. 2025. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective stars. arXiv preprint arXiv:2503.01307. Etash Guha, Ryan ...
-
[3]
Skywork open reasoner series. Notion Blog. Yancheng He, Shilong Li, Jiaheng Liu, Yingshui Tan, Weixun Wang, Hui Huang, Xingyuan Bu, Hangyu Guo, Chengwei Hu, Boren Zheng, et al. 2024b. Chinese simpleqa: A chinese factuality evalua- tion for large language models. arXiv preprint arXiv:2411.07140. Alex Heyman and Joel Zylberberg. 2025. Reason- ing large lang...
-
[4]
Latent Retrieval for Weakly Supervised Open Domain Question Answering
Latent retrieval for weakly supervised open domain question answering. arXiv preprint arXiv:1906.00300. Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Hein- rich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neu...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[5]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Selfcheckgpt: Zero-resource black-box hal- lucination detection for generative large language models. arXiv preprint arXiv:2303.08896. Jianbiao Mei, Tao Hu, Daocheng Fu, Licheng Wen, Xuemeng Yang, Rong Wu, Pinlong Cai, Xing Gao, Yu Yang, Chengjun Xie, et al. 2025. o2-searcher: A searching-based agent model for open-domain open-ended question answering. ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Advances in neural in- formation processing systems, 35:27730–27744
Training language models to follow instruc- tions with human feedback. Advances in neural in- formation processing systems, 35:27730–27744. Nisarg Patel, Mohith Kulkarni, Mihir Parmar, Aashna Budhiraja, Mutsumi Nakamura, Neeraj Varshney, and Chitta Baral. 2024. Multi-logieval: Towards eval- uating multi-step logical reasoning ability of large language mod...
-
[7]
Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neu- big, and Xiang Yue
Are reasoning models more prone to halluci- nation? arXiv preprint arXiv:2505.23646. Edward Yeo, Yuxuan Tong, Morry Niu, Graham Neu- big, and Xiang Yue. 2025. Demystifying long chain-of-thought reasoning in llms. arXiv preprint arXiv:2502.03373. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. Does re- inforcement ...
-
[8]
First normalize the query by properly capitalizing names, titles, and other named entities
-
[9]
Determine if the query has sufficient context to be answered meaningfully
-
[10]
Extract only the most important entities from the query that are essential for answering it RULES:
-
[11]
Extract a MAXIMUM of 2 specific entities (people, places, objects, works, etc.)
-
[12]
Output the MOST important entity first, then the secondary entity (if any)
-
[13]
Extract precise named entities, not general concepts or phrases
-
[14]
Keep related entities together as a single entity (e.g., character names with their roles)
-
[15]
Return individual entities rather than relationships or possessive forms
-
[16]
Only extract truly representative entities - ignore generic terms that don’t specifically define the query
-
[17]
Only REJECT queries that meet the rejection criteria below ONLY reject queries in these specific cases:
-
[18]
When the entity in the query is completely ambiguous (e.g., "Who is that person?")
-
[19]
When the query lacks necessary qualifying information (e.g., "Who will win?" with no mention of what contest)
-
[20]
When the query is too vague to determine its intent (e.g., "What happened to him?")
-
[21]
When the query is time-sensitive and contains temporal references like "now", "current", "latest", "recent", etc
-
[22]
When the query lacks sufficient information to determine a single definitive answer, potentially leading to multiple correct interpretations or answers
-
[23]
who played barbara gordon batgirl?
Be careful not to extract purely numerical information such as a year as an entity Note: Queries with historical context, pop culture references, geographical locations, or other well-defined entities should be ACCEPTED. EXAMPLES: Example 1: Original Query: "who played barbara gordon batgirl?" Normalized Query: "Who played Barbara Gordon Batgirl?" Output:...
-
[24]
This aligns with his role as a colonial military commander. \n\ nOn the other hand, William Bolivar was also in the military but joined the Spanish Regulars, which was a different force. The question specifically mentions a military commander, so Philip Bolivar is the likely answer. I don't recall any other notable military commands from Simon Bolivar's d...
work page 2025
-
[25]
Performance on TheoremQA Model Direct Generation KnowRL Trained Improvement DeepSeek-R1-Distill-Qwen-7B 12.75% 17.88% +5.13% Skywork-OR1-7B-Preview 12.00% 15.12% +3.12% Table 4: Performance on TheoremQA
-
[26]
DS-Base: DeepSeek-R1-Distill- Qwen-7B, DS-KnowRL: the KnowRL-trained version
Performance on OlympiadBench Sub-task DS-Base DS-KnowRL SW-Base SW-KnowRL maths_en_COMP 8.61% 9.94% 4.75% 7.42% maths_zh_COMP 7.35% 11.27% 5.39% 6.62% maths_zh_CEE 10.65% 9.35% 8.79% 8.15% physics_en_COMP 1.69% 1.27% 0.85% 0.00% physics_zh_CEE 7.83% 13.91% 3.48% 9.57% Table 5: Performance on OlympiadBench, with layout transposed for clarity. DS-Base: Deep...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.