RoboEval: Where Robotic Manipulation Meets Structured and Scalable Evaluation
Pith reviewed 2026-05-19 07:15 UTC · model grok-4.3
The pith
RoboEval augments binary success counts with behavioral and outcome metrics to distinguish execution quality in robotic manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
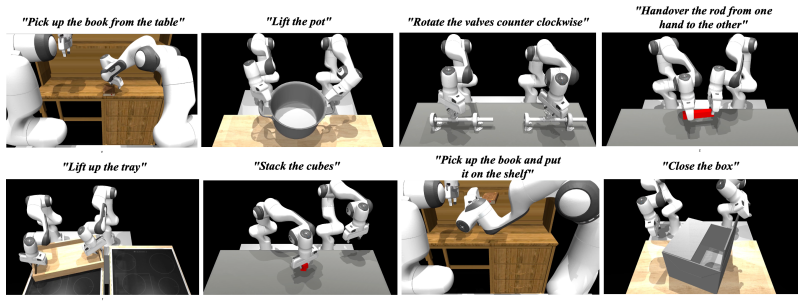
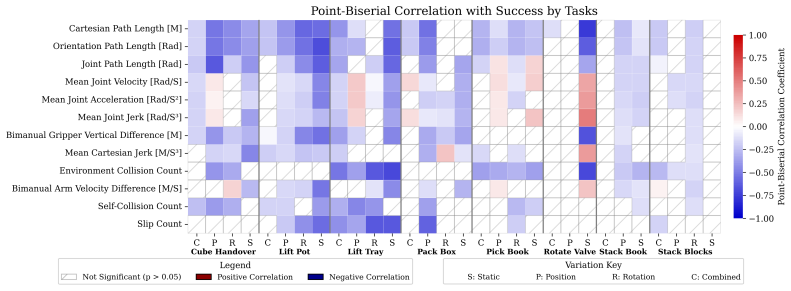
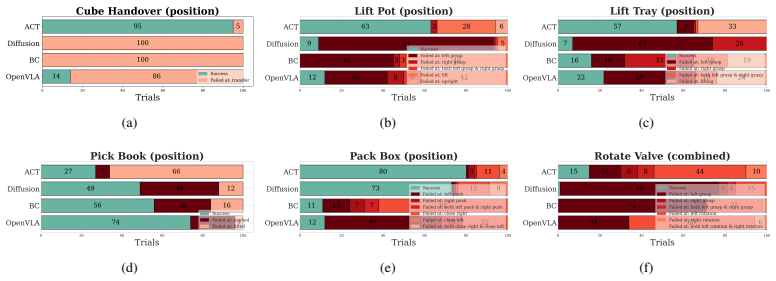
By instrumenting eight bimanual manipulation tasks with metrics that quantify efficiency, coordination, and safety or stability together with outcome measures that trace stagewise progress and localize failures, RoboEval supplies a finer-grained picture of policy performance than binary success alone. The framework includes systematic task variations and more than three thousand demonstrations inside a reproducible modular simulation platform. Validation experiments demonstrate that the metrics remain stable under variation, possess discriminative power among policies with comparable success rates, and correlate with task success.
What carries the argument
The RoboEval framework of standardized behavioral metrics for efficiency, coordination, and safety plus outcome measures that track stagewise progress and localize failures.
If this is right
- Policies with nearly identical success rates can now be ranked by differences in coordination or efficiency.
- Failure analysis becomes localized to specific task stages rather than remaining a single success or failure label.
- Task variations can be used to test how robust a policy remains under controlled changes in object placement or timing.
- Reproducible comparisons across research groups become possible through the shared simulation platform and metric definitions.
Where Pith is reading between the lines
- Detailed metrics could guide policy training by highlighting specific weaknesses such as poor hand coordination during particular stages.
- The same instrumentation approach might extend to single-arm or mobile manipulation tasks to build a broader family of benchmarks.
- If the metrics prove robust on hardware, they could inform safety standards for robots operating near humans by quantifying stability margins.
- A shared public leaderboard based on these metrics would shift research incentives toward balanced performance rather than success-rate optimization alone.
Load-bearing premise
The proposed behavioral and outcome metrics will continue to provide stable and meaningful distinctions when moved beyond the current simulation platform and the eight chosen bimanual tasks.
What would settle it
Running the same metrics on a new set of policies or on physical hardware and finding that they show no greater stability, no added ability to separate policies with similar success rates, or no correlation with task outcomes.
Figures




read the original abstract
We introduce RoboEval, a structured evaluation framework and benchmark for robotic manipulation that augments binary success with principled behavioral and outcome metrics. Existing evaluations often collapse performance into outcome counts, masking differences in execution quality and obscuring failure structure. RoboEval provides eight bimanual tasks with systematically controlled variations, more than three thousand expert demonstrations, and a modular simulation platform for reproducible experimentation. All tasks are instrumented with standardized metrics that quantify efficiency, coordination, and safety/stability, as well as outcome measures that trace stagewise progress and localize failure modes. Through extensive experiments with state-of-the-art visuomotor policies, we validate these metrics by analyzing their stability under variation, discriminative power across policies with similar success rates, and correlation with task success. Project Page: https://robo-eval.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RoboEval, a structured evaluation framework and benchmark for robotic manipulation that augments binary success with behavioral metrics (efficiency, coordination, safety/stability) and stagewise outcome measures to localize failures. It supplies eight bimanual tasks with controlled variations, over 3000 expert demonstrations, and a modular simulation platform. The central contribution is the validation of these metrics via stability under variation, discriminative power across policies with similar success rates, and correlation with task success, demonstrated through experiments with state-of-the-art visuomotor policies.
Significance. If the metrics are shown to be stable and discriminative, the framework could meaningfully advance evaluation practices in robotics by revealing execution-quality differences that success rates alone obscure. The large demonstration set and reproducible modular platform are clear strengths supporting community use. The work's broader significance for real robotic manipulation, however, depends on addressing the sim-to-real gap highlighted in the validation claims.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: All reported stability, discrimination, and correlation analyses rely on perfect simulator state access for the eight bimanual tasks. The manuscript does not include real-robot transfer experiments or ablation under sensor noise/partial observability, yet the abstract positions the metrics as supplying 'meaningful distinctions in robotic manipulation performance.' This sim-to-real assumption is load-bearing for the central validation claim.
- [Experiments] Experiments section: The discriminative-power and correlation results are presented without error bars, confidence intervals, or statistical significance tests. It is therefore unclear whether the reported distinctions across policies with similar success rates are robust or sensitive to post-hoc analysis choices.
minor comments (1)
- [Platform] The modular platform description would benefit from an explicit list of which simulator components (physics engine, sensor models) are exposed for custom instrumentation.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: All reported stability, discrimination, and correlation analyses rely on perfect simulator state access for the eight bimanual tasks. The manuscript does not include real-robot transfer experiments or ablation under sensor noise/partial observability, yet the abstract positions the metrics as supplying 'meaningful distinctions in robotic manipulation performance.' This sim-to-real assumption is load-bearing for the central validation claim.
Authors: We agree that all validation experiments use perfect simulator state. This controlled setting is required to isolate and quantify the stability, discriminative power, and correlation properties of the metrics with the precision needed for the claims. We will revise the abstract to state explicitly that the reported distinctions are demonstrated in simulation. In addition, we will add new ablation studies that inject sensor noise and partial observability into the simulation to test metric behavior under more realistic sensing conditions. Real-robot transfer lies outside the scope of the present work, which centers on establishing a reproducible simulation benchmark; we will add a dedicated paragraph in the discussion section acknowledging the sim-to-real gap and outlining planned future transfer studies. revision: partial
-
Referee: [Experiments] Experiments section: The discriminative-power and correlation results are presented without error bars, confidence intervals, or statistical significance tests. It is therefore unclear whether the reported distinctions across policies with similar success rates are robust or sensitive to post-hoc analysis choices.
Authors: We thank the referee for highlighting the need for statistical rigor. In the revised manuscript we will recompute the discriminative-power and correlation analyses across multiple random seeds, report error bars (standard deviation) and 95% confidence intervals, and include appropriate statistical tests (paired t-tests or Wilcoxon signed-rank tests with p-values) to establish that the observed differences between policies are statistically significant and not sensitive to analysis choices. revision: yes
Circularity Check
No circularity: metrics and validation are independently defined and tested
full rationale
The paper defines new behavioral metrics (efficiency, coordination, safety/stability) and stagewise outcome measures directly from task instrumentation in a modular simulation platform, then validates them empirically by measuring stability under variation, discriminative power, and correlation with success rates across policies. No equations or derivations reduce any claimed result to its own inputs by construction, no parameters are fitted to a subset and then relabeled as predictions, and no load-bearing claims rest on self-citations whose supporting results are themselves unverified. The framework is self-contained as an empirical benchmark introduction, with all validation steps performed on external policy outputs rather than internal tautologies.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce four classes of metrics... Trajectory-Based Metrics... Spatial Metrics... Coordination and Bimanual Metrics... Task Progression and Outcome Metrics.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tasks... decomposed into skill-specific stages... stage-wise success indicators
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
MolmoAct2: Action Reasoning Models for Real-world Deployment
MolmoAct2 delivers an open VLA model with new specialized components, datasets, and techniques that outperforms baselines on benchmarks while releasing all weights, code, and data for real-world robot use.
-
MolmoAct2: Action Reasoning Models for Real-world Deployment
MolmoAct2 is an open VLA model that outperforms baselines like Pi-05 on 7 benchmarks and whose backbone surpasses GPT-5 on 13 embodied-reasoning tasks through new datasets, specialized training, and architecture chang...
-
RoboPlayground: Democratizing Robotic Evaluation through Structured Physical Domains
RoboPlayground reframes robotic manipulation evaluation as a language-driven process over structured physical domains, letting users author varied yet reproducible tasks that reveal policy generalization failures.
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierar- chical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
work page 2009
-
[2]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang. Squad: 100,000+ questions for machine comprehension of text, 2016. URL https://arxiv.org/abs/1606.05250
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba. Openai gym, 2016. URL https://arxiv.org/abs/1606.01540
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Y . Tassa, Y . Doron, A. Muldal, T. Erez, Y . Li, D. de Las Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, T. Lillicrap, and M. Riedmiller. Deepmind control suite, 2018. URL https://arxiv.org/abs/1801.00690
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [5]
-
[6]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning, pages 1094–1100. PMLR, 2020
work page 2020
-
[7]
N. Chernyadev, N. Backshall, X. Ma, Y . Lu, Y . Seo, and S. James. Bigym: A demo-driven mobile bi-manual manipulation benchmark, 2024. URL https://arxiv.org/abs/2407. 07788
work page 2024
-
[8]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, S. Nasiriany, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learning. In arXiv preprint arXiv:2009.12293, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. Maniskill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023
work page 2023
-
[10]
The colosseum: A benchmark for evaluating generalization for robotic manipulation
W. Pumacay, I. Singh, J. Duan, R. Krishna, J. Thomason, and D. Fox. The colosseum: A benchmark for evaluating generalization for robotic manipulation, 2024. URL https: //arxiv.org/abs/2402.08191
-
[11]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, et al. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel. Humanoidbench: Simulated hu- manoid benchmark for whole-body locomotion and manipulation, 2024
work page 2024
-
[13]
Y . Chen, Y . Geng, F. Zhong, J. Ji, J. Jiang, Z. Lu, H. Dong, and Y . Yang. Bi-dexhands: Towards human-level bimanual dexterous manipulation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):2804–2818, 2023. 11
work page 2023
- [14]
- [15]
- [16]
-
[17]
R. Newbury, M. Gu, L. Chumbley, A. Mousavian, C. Eppner, J. Leitner, J. Bohg, A. Morales, T. Asfour, D. Kragic, et al. Deep learning approaches to grasp synthesis: A review. IEEE Transactions on Robotics, 39(5):3994–4015, 2023
work page 2023
-
[18]
On Evaluation of Embodied Navigation Agents
P. Anderson, A. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V . Koltun, J. Kosecka, J. Ma- lik, R. Mottaghi, M. Savva, et al. On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Rb2: Robotic manipulation benchmarking with a twist,
S. Dasari, J. Wang, J. Hong, S. Bahl, Y . Lin, A. Wang, A. Thankaraj, K. Chahal, B. Calli, S. Gupta, D. Held, L. Pinto, D. Pathak, V . Kumar, and A. Gupta. Rb2: Robotic manipulation benchmarking with a twist, 2022. URL https://arxiv.org/abs/2203.08098
-
[20]
F. Krebs and T. Asfour. A bimanual manipulation taxonomy. IEEE Robotics and Automation Letters, 7(4):11031–11038, 2022. doi:10.1109/LRA.2022.3196158
-
[21]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. In Proceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[23]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024. 12
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.