Elastic MoE: Unlocking the Inference-Time Scalability of Mixture-of-Experts
Pith reviewed 2026-05-18 14:14 UTC · model grok-4.3
The pith
Elastic training lets one MoE model keep improving when it activates two to three times more experts at inference than it saw in training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the observed inference-time scaling wall stems from experts lacking learned collaboration across different activation patterns, and that a training procedure which simultaneously exposes experts to diverse combinations while guiding the router toward high-quality selections removes the wall, allowing performance to scale up to 2-3 times the training-time activation count across multiple model sizes and tasks.
What carries the argument
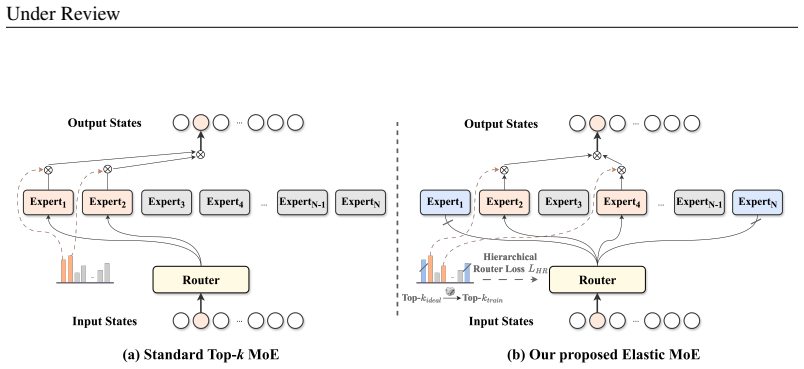
The Elastic Mixture-of-Experts training framework that forces the router and experts to practice collaboration under many different numbers of active experts during the training phase.
If this is right
- A single trained model can serve multiple quality-latency operating points without any retraining or model swapping.
- Peak performance on downstream tasks rises compared with models trained at a fixed expert count.
- The approach works across four different MoE architectures ranging from 7B to 21B parameters.
- The usable inference scaling range expands from roughly the training k to two or three times that value on nine standard benchmarks.
Where Pith is reading between the lines
- Deployment pipelines could adjust the number of active experts on the fly according to current load or hardware constraints instead of maintaining multiple model copies.
- The same training pattern might help other sparsely activated architectures that currently suffer when their activation count changes after training.
- Practitioners could test whether the method also stabilizes performance when the inference count drops below the training count, which the paper does not examine.
- Future experiments could check whether the gains hold when the test distribution differs markedly from the training data mixtures used to create the diverse expert teams.
Load-bearing premise
The performance drop when activating extra experts at inference is caused by a lack of learned collaboration among experts that can be fixed simply by exposing the model to many different expert combinations while training.
What would settle it
Train an EMoE model on a standard benchmark then measure accuracy while increasing the inference activation count from 1x to 3x the training value; if accuracy falls sharply past 1.5x, the training change does not fully remove the scaling wall.
Figures







read the original abstract
Mixture-of-Experts (MoE) models typically fix the number of activated experts $k$ at both training and inference. However, real-world deployments often face heterogeneous hardware, fluctuating workloads, and diverse quality-latency requirements, while training separate models for each scenario is costly. Considering that MoE models already operate with sparse activation, adjusting the number of activated experts offers a natural path to serving diverse budgets with a single model. Yet, we find that activating more experts $k'$ ($> k$) at inference does not yield the expected gains. Instead, performance degrades rapidly after only a slight increase, a phenomenon we term the \textit{inference-time scaling wall}. Further investigation reveals that this degradation stems from a lack of learned collaboration among experts. To address this, we introduce \textbf{Elastic Mixture-of-Experts (EMoE)}, a novel training framework that enables MoE models to elastically vary the number of activated experts at inference. By simultaneously training experts to collaborate in diverse combinations and encouraging the router to make high-quality selections, EMoE ensures robust performance across inference budgets. Extensive experiments across four MoE architectures (7B--21B) and nine benchmarks show that EMoE significantly expands the effective scaling range to 2-3$\times$ the training-time $k$, while also achieving higher peak performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies an 'inference-time scaling wall' in Mixture-of-Experts models, where activating k' > k experts at inference causes rapid performance degradation. It attributes this to insufficient learned collaboration among experts and introduces Elastic MoE (EMoE), a training framework that simultaneously optimizes experts for diverse combinations and improves router quality. Experiments across four MoE architectures (7B–21B) and nine benchmarks claim that EMoE expands the effective scaling range to 2–3× the training-time k while also raising peak performance.
Significance. If the central mechanism holds, EMoE would allow a single trained MoE model to serve heterogeneous hardware, workloads, and quality-latency trade-offs without retraining separate models for each k, reducing deployment overhead. The evaluation spans multiple architectures and benchmarks, which is a positive indicator of generality for an empirical method.
major comments (2)
- [Abstract] Abstract: The diagnosis that degradation 'stems from a lack of learned collaboration among experts' is load-bearing for the EMoE objective. An alternative—that the router trained only on the original top-k produces mis-calibrated scores for larger sets—is not isolated. No ablation is described that holds the router fixed while varying only expert co-training, nor are router calibration metrics (e.g., rank correlation of router scores with held-out expert utility) reported at k' = 2k.
- [Abstract] Abstract and experimental description: The claim of 'consistent gains' and '2-3× the training-time k' is presented without specifying exact baselines, ablation controls, statistical significance tests, or the precise metric used to quantify the inference-time scaling wall. These omissions directly affect assessment of whether the reported expansion is robust.
minor comments (1)
- The abstract introduces the term 'inference-time scaling wall' without situating it against prior observations of MoE scaling behavior; a short related-work sentence would improve context.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, clarifying our existing analyses where possible and outlining targeted revisions to improve precision and isolation of effects.
read point-by-point responses
-
Referee: [Abstract] Abstract: The diagnosis that degradation 'stems from a lack of learned collaboration among experts' is load-bearing for the EMoE objective. An alternative—that the router trained only on the original top-k produces mis-calibrated scores for larger sets—is not isolated. No ablation is described that holds the router fixed while varying only expert co-training, nor are router calibration metrics (e.g., rank correlation of router scores with held-out expert utility) reported at k' = 2k.
Authors: We appreciate the referee highlighting the importance of isolating the root cause. Section 4.2 of the manuscript already includes experiments that fix the router (using both the trained router and an oracle router) while varying expert training objectives, showing that performance degradation persists even with improved routing, which supports the collaboration hypothesis. However, to more rigorously rule out the mis-calibration alternative, we will add a new ablation that holds the router weights completely fixed from the baseline training run and retrains only the experts under the EMoE co-training objective. We will also report router calibration metrics, including rank correlation between router scores and held-out expert utilities, evaluated at k' = 2k. revision: partial
-
Referee: [Abstract] Abstract and experimental description: The claim of 'consistent gains' and '2-3× the training-time k' is presented without specifying exact baselines, ablation controls, statistical significance tests, or the precise metric used to quantify the inference-time scaling wall. These omissions directly affect assessment of whether the reported expansion is robust.
Authors: We agree that explicit specification of these elements is essential. In the revised manuscript we will: (1) state the exact baselines (standard MoE trained and evaluated at the original k, plus dense models of comparable size); (2) detail all ablation controls including the fixed-router and oracle-router variants; (3) report statistical significance via paired t-tests over three random seeds for key results; and (4) define the scaling-wall metric as the largest k' at which average performance across benchmarks remains within 1% of the model's peak accuracy (or does not fall below the single-expert baseline). These clarifications will be added to both the abstract and the experimental section. revision: yes
Circularity Check
No circularity: empirical training framework with independent experimental validation
full rationale
The paper presents an entirely empirical contribution: it observes an inference-time scaling wall in MoE models, attributes it to insufficient expert collaboration via investigation, and proposes EMoE as a training procedure to expose experts to diverse combinations. No equations, derivations, or fitted parameters are shown to reduce the claimed gains (2-3× scaling range, higher peak performance) to quantities defined by construction from the inputs. The central claims rest on experiments across four architectures and nine benchmarks rather than self-referential definitions or load-bearing self-citations. The diagnosis and remedy are falsifiable outside the paper's own fitted values and do not collapse into tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Training experts on diverse activation combinations during training produces collaboration that generalizes to inference-time changes in k.
invented entities (1)
-
Elastic Mixture-of-Experts (EMoE) training framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
performance degradation stems from a lack of learned collaboration among experts... stochastic co-activation sampling... hierarchical router loss LHR = −DKL(h(x)∥U)
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
when a model is trained with k experts, the effective scaling range at inference is so narrow
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
MoE-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
MoE-Prefill achieves 1.35-1.59x higher throughput for prefill-only MoE serving by using asynchronous expert parallelism to overlap weight AllGather with computation and prefix-aware routing with true-FLOPs tracking.
-
Elastic Attention Cores for Scalable Vision Transformers
VECA learns effective visual representations using core-periphery attention where patches interact exclusively via a resolution-invariant set of learned core embeddings, achieving linear O(N) complexity while maintain...
-
MoE-Prefill: Zero Redundancy Overheads in MoE Prefill Serving
ZeRO-Prefill achieves 1.35-1.59x higher throughput for MoE prefill serving by replacing per-layer activation AllToAll with overlapped asynchronous weight AllGather and prefix-aware routing.
-
Foundry: Template-Based CUDA Graph Context Materialization for Fast LLM Serving Cold Start
Foundry uses template-based CUDA graph context materialization to reduce LLM serving cold-start latency by up to 99% while preserving CUDA graph throughput gains.
Reference graph
Works this paper leans on
-
[1]
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se - Young Yun. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation. CoRR, abs/2507.10524, 2025. doi:10.48550/ARXIV.2507.10524. URL https://doi.org/10.48550/arXiv.2507.10524
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pond \' e de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bava...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking
Yilong Chen, Junyuan Shang, Zhenyu Zhang, Yanxi Xie, Jiawei Sheng, Tingwen Liu, Shuohuan Wang, Yu Sun, Hua Wu, and Haifeng Wang. Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Proceedings of the 63rd Annual Meeting of ...
work page 2025
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457, 2018. URL http://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Opencompass: A universal evaluation platform for foundation models
OpenCompass Contributors. Opencompass: A universal evaluation platform for foundation models. https://github.com/open-compass/opencompass, 2023
work page 2023
-
[7]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, Zhenda Xie, Y. K. Li, Panpan Huang, Fuli Luo, Chong Ruan, Zhifang Sui, and Wenfeng Liang. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. In Lun - Wei Ku, Andre Martins, and Vivek Srikumar (eds.)...
-
[8]
DeepSeek - AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, Hao Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J. L. Cai, Jian...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.04434 2024
-
[9]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Dhillon, Yulia Tsvetkov, Hanna Hajishirzi, Sham M
Devvrit, Sneha Kudugunta, Aditya Kusupati, Tim Dettmers, Kaifeng Chen, Inderjit S. Dhillon, Yulia Tsvetkov, Hanna Hajishirzi, Sham M. Kakade, Ali Farhadi, and Prateek Jain. Matformer: Nested transformer for elastic inference. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang (eds.), Advances...
work page 2024
-
[11]
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Jun Zhao, Wei Shen, Yuhao Zhou, Zhiheng Xi, Xiao Wang, Xiaoran Fan, Shiliang Pu, Jiang Zhu, Rui Zheng, Tao Gui, Qi Zhang, and Xuanjing Huang. Loramoe: Revolutionizing mixture of experts for maintaining world knowledge in language model alignment, 2023
work page 2023
-
[12]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res., 23: 0 120:1--120:39, 2022. URL https://jmlr.org/papers/v23/21-0998.html
work page 2022
-
[13]
Hydravit: Stacking heads for a scalable vit
Janek Haberer, Ali Hojjat, and Olaf Landsiedel. Hydravit: Stacking heads for a scalable vit. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang (eds.), Advances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouve...
work page 2024
-
[14]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
work page 2021
-
[15]
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen - Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[16]
Harder task needs more experts: Dynamic routing in M o E models
Quzhe Huang, Zhenwei An, Nan Zhuang, Mingxu Tao, Chen Zhang, Yang Jin, Kun Xu, Kun Xu, Liwei Chen, Songfang Huang, and Yansong Feng. Harder task needs more experts: Dynamic routing in M o E models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Lon...
-
[17]
Upcycling instruction tuning from dense to mixture-of-experts via parameter merging
Tingfeng Hui, Zhenyu Zhang, Shuohuan Wang, Yu Sun, Hua Wu, and Sen Su. Upcycling instruction tuning from dense to mixture-of-experts via parameter merging. CoRR, abs/2410.01610, 2024. doi:10.48550/ARXIV.2410.01610. URL https://doi.org/10.48550/arXiv.2410.01610
-
[18]
Adaptive Mixtures of Local Experts
Robert A. Jacobs, Michael I. Jordan, Steven J. Nowlan, and Geoffrey E. Hinton. Adaptive mixtures of local experts. Neural Comput., 3 0 (1): 0 79--87, 1991. doi:10.1162/NECO.1991.3.1.79. URL https://doi.org/10.1162/neco.1991.3.1.79
-
[19]
Moe++: Accelerating mixture-of-experts methods with zero-computation experts
Peng Jin, Bo Zhu, Li Yuan, and Shuicheng Yan. Moe++: Accelerating mixture-of-experts methods with zero-computation experts. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=t7P5BUKcYv
work page 2025
-
[20]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Regina Barzilay and Min - Yen Kan (eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, ACL 2017, Vancouver, Canada, July 30 - August 4, Volume 1: Long Pape...
-
[21]
Lost in the Middle: How Language Models Use Long Contexts
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming - Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research. Tr...
work page internal anchor Pith review doi:10.1162/tacl 2019
-
[22]
Gshard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with conditional computation and automatic sharding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 . OpenReview.net, 2021. URL http...
work page 2021
-
[23]
Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification, 2023
Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong, and "Teknium". Slimorca: An open dataset of gpt-4 augmented flan reasoning traces, with verification, 2023. URL https://https://huggingface.co/Open-Orca/SlimOrca
work page 2023
-
[24]
OLMoE: Open Mixture-of-Experts Language Models
Niklas Muennighoff, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Jacob Morrison, Sewon Min, Weijia Shi, Pete Walsh, Oyvind Tafjord, Nathan Lambert, Yuling Gu, Shane Arora, Akshita Bhagia, Dustin Schwenk, David Wadden, Alexander Wettig, Binyuan Hui, Tim Dettmers, Douwe Kiela, Ali Farhadi, Noah A. Smith, Pang Wei Koh, Amanpreet Singh, and Hannaneh Hajishirzi. O...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
OpenAI. Gpt-4 technical report. ArXiv, abs/2303.08774, 2023. URL https://api.semanticscholar.org/CorpusID:266362871
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
From sparse to soft mixtures of experts
Joan Puigcerver, Carlos Riquelme Ruiz, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=jxpsAj7ltE
work page 2024
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. In The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Art...
-
[28]
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL h...
work page 2017
-
[29]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. CoRR, abs/2408.03314, 2024. doi:10.48550/ARXIV.2408.03314. URL https://doi.org/10.48550/arXiv.2408.03314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.03314 2024
-
[30]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Qwen1.5-moe: Matching 7b model performance with 1/3 activated parameters", February 2024
Qwen Team. Qwen1.5-moe: Matching 7b model performance with 1/3 activated parameters", February 2024. URL https://qwenlm.github.io/blog/qwen-moe/
work page 2024
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023 a . URL https://api.semanticscholar...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton - Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Har...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288 2023
-
[34]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V. N. Vishwanathan, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 30: Annual Conference o...
work page 2017
-
[35]
An Wang, Xingwu Sun, Ruobing Xie, Shuaipeng Li, Jiaqi Zhu, Zhen Yang, Pinxue Zhao, J. N. Han, Zhanhui Kang, Di Wang, Naoaki Okazaki, and Cheng - Zhong Xu. Hmoe: Heterogeneous mixture of experts for language modeling. CoRR, abs/2408.10681, 2024 a . doi:10.48550/ARXIV.2408.10681. URL https://doi.org/10.48550/arXiv.2408.10681
-
[36]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Lean Wang, Huazuo Gao, Chenggang Zhao, Xu Sun, and Damai Dai. Auxiliary-loss-free load balancing strategy for mixture-of-experts. CoRR, abs/2408.15664, 2024 b . doi:10.48550/ARXIV.2408.15664. URL https://doi.org/10.48550/arXiv.2408.15664
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.15664 2024
-
[37]
Remoe: Fully differentiable mixture-of-experts with relu routing
Ziteng Wang, Jun Zhu, and Jianfei Chen. Remoe: Fully differentiable mixture-of-experts with relu routing. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=4D0f16Vwc3
work page 2025
-
[38]
Magicoder: Empowering code generation with oss-instruct.arXiv preprint arXiv:2312.02120, 2023
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Source code is all you need. CoRR, abs/2312.02120, 2023. doi:10.48550/ARXIV.2312.02120. URL https://doi.org/10.48550/arXiv.2312.02120
-
[39]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https:...
work page 2024
-
[40]
URL https:// doi.org/10.18653/v1/p19-1472
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Anna Korhonen, David R. Traum, and Llu \' s M \` a rquez (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers , pp...
-
[41]
Adamoe: Token-adaptive routing with null experts for mixture-of-experts language models
Zihao Zeng, Yibo Miao, Hongcheng Gao, Hao Zhang, and Zhijie Deng. Adamoe: Token-adaptive routing with null experts for mixture-of-experts language models. In Yaser Al - Onaizan, Mohit Bansal, and Yun - Nung Chen (eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, Florida, USA, November 12-16, 2024 , pp.\ 6223--6235. Assoc...
-
[42]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[43]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[44]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[45]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.