Glia: A Human-Inspired AI for Automated Systems Design and Optimization
Pith reviewed 2026-05-18 03:24 UTC · model grok-4.3
The pith
Glia uses a multi-agent LLM setup to design interpretable algorithms for computer systems that match human expert performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By organizing large language models into a human-inspired multi-agent system with dedicated roles for reasoning, experimentation, and analysis that interact via an evaluation framework, it is possible to generate creative, high-performing, and interpretable designs for complex systems problems such as managing distributed GPU clusters for LLM inference, achieving performance on par with human experts while requiring significantly less time.
What carries the argument
The multi-agent LLM workflow in which specialized agents for reasoning, experimentation, and analysis collaborate through an evaluation framework to ground abstract reasoning in empirical feedback.
If this is right
- Glia can produce system designs that are understandable by humans rather than opaque policies.
- It can discover novel insights into workload behavior during the design process.
- Such AI assistance could speed up the development of algorithms for request routing, scheduling, and auto-scaling in similar systems.
- The approach suggests AI can handle creative aspects of systems design traditionally done by experts.
Where Pith is reading between the lines
- If this method generalizes, it could be used to design systems for other domains like network protocols or database optimization.
- The interpretability of the outputs might enable iterative improvement where humans refine the AI-generated ideas.
- Combining this with traditional optimization tools could lead to hybrid design processes that leverage both reasoning and numerical search.
- Success here raises the possibility of AI autonomously handling more of the systems research pipeline beyond just design.
Load-bearing premise
That the structured collaboration of LLM agents through empirical evaluation will reliably lead to creative and high-performing system designs without frequent errors in reasoning or experimentation.
What would settle it
Running Glia on the same GPU cluster task multiple times and checking if the generated algorithms consistently achieve performance metrics close to or better than published human-expert baselines, with clear failures if they fall short or cannot be interpreted.
Figures












read the original abstract
Can AI autonomously design mechanisms for computer systems on par with the creativity and reasoning of human experts? We present Glia, an AI architecture for networked systems design that uses large language models (LLMs) in a human-inspired multi-agent workflow. Each agent specializes in reasoning, experimentation, and analysis, collaborating through an evaluation framework that grounds abstract reasoning in empirical feedback. Unlike prior ML-for-systems methods that optimize black-box policies, Glia generates interpretable designs and exposes its reasoning. When applied to a distributed GPU cluster for LLM inference, it produces new algorithms for request routing, scheduling, and auto-scaling that perform at human-expert levels in significantly less time, while yielding novel insights into workload behavior. Our results suggest that combining reasoning LLMs with structured experimentation, an AI can produce creative and understandable designs for complex systems problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Glia, a multi-agent LLM architecture for automated design of networked systems. Specialized agents handle reasoning, experimentation, and analysis, collaborating via an evaluation framework that incorporates empirical feedback. Applied to request routing, scheduling, and auto-scaling on a distributed GPU cluster for LLM inference, the system is claimed to generate interpretable algorithms that match human-expert performance in less time while revealing novel workload insights.
Significance. If the performance claims are substantiated with rigorous quantitative evidence, the work would be significant as one of the first demonstrations that structured multi-agent LLM workflows can autonomously produce creative, interpretable system designs competitive with human experts, moving beyond black-box policy optimization.
major comments (2)
- Abstract: The claim that the generated algorithms 'perform at human-expert levels' is unsupported by any quantitative metrics, baselines, error bars, or description of the comparison protocol against documented human experts. This is load-bearing for the central result.
- Evaluation Framework section: No details are provided on test workload durations, variance reporting, number of replications, or statistical controls used by the experimentation and analysis agents to accept or revise designs. Without these, it is impossible to confirm that empirical feedback, rather than LLM narrative, drives the final outputs.
minor comments (1)
- Abstract: The phrase 'in significantly less time' would be clearer with a specific time comparison or factor relative to human design processes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas for strengthening the presentation of our quantitative results and methodological transparency. We address each major comment below and have revised the manuscript to incorporate the suggested improvements.
read point-by-point responses
-
Referee: Abstract: The claim that the generated algorithms 'perform at human-expert levels' is unsupported by any quantitative metrics, baselines, error bars, or description of the comparison protocol against documented human experts. This is load-bearing for the central result.
Authors: We agree that the abstract would benefit from more explicit quantitative support for this central claim. The manuscript body reports performance comparisons using metrics such as latency, throughput, and resource efficiency against both standard baselines and human-expert-designed policies, including results from multiple evaluation runs. To address the concern directly, we have revised the abstract to reference these key metrics, note the use of error bars from replications, and briefly describe the comparison protocol (including how human-expert algorithms were sourced and evaluated under identical conditions). This change ensures the claim is better grounded without altering the underlying results. revision: yes
-
Referee: Evaluation Framework section: No details are provided on test workload durations, variance reporting, number of replications, or statistical controls used by the experimentation and analysis agents to accept or revise designs. Without these, it is impossible to confirm that empirical feedback, rather than LLM narrative, drives the final outputs.
Authors: We acknowledge that the Evaluation Framework section requires greater specificity on these operational details to demonstrate the role of empirical feedback. We have expanded this section to specify test workload durations, how variance is reported across runs, the number of replications performed for each candidate design, and the statistical controls (such as significance thresholds) applied by the analysis agent when deciding whether to accept, reject, or iterate on a design. These additions clarify the data-driven nature of the workflow. revision: yes
Circularity Check
No circularity: empirical workflow is self-contained
full rationale
The paper describes a multi-agent LLM workflow that generates system designs and validates them through an evaluation framework grounded in empirical measurements on a GPU cluster. No equations, fitted parameters, or uniqueness theorems are invoked that reduce the performance claims to self-definition or prior self-citations. The central result—that generated routing/scheduling/auto-scaling algorithms reach human-expert levels—is presented as an outcome of the experimentation loop rather than a definitional or post-hoc fit. Absent any load-bearing self-citation chain or ansatz smuggled via prior work, the derivation remains independent of its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can be effectively specialized into roles for reasoning, experimentation, and analysis that collaborate productively through an evaluation framework.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Glia employs an agentic workflow that mirrors how expert humans design systems—through conceptual understanding, hypothesis formation, experimental testing, ideation, and iterative refinement.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanalpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
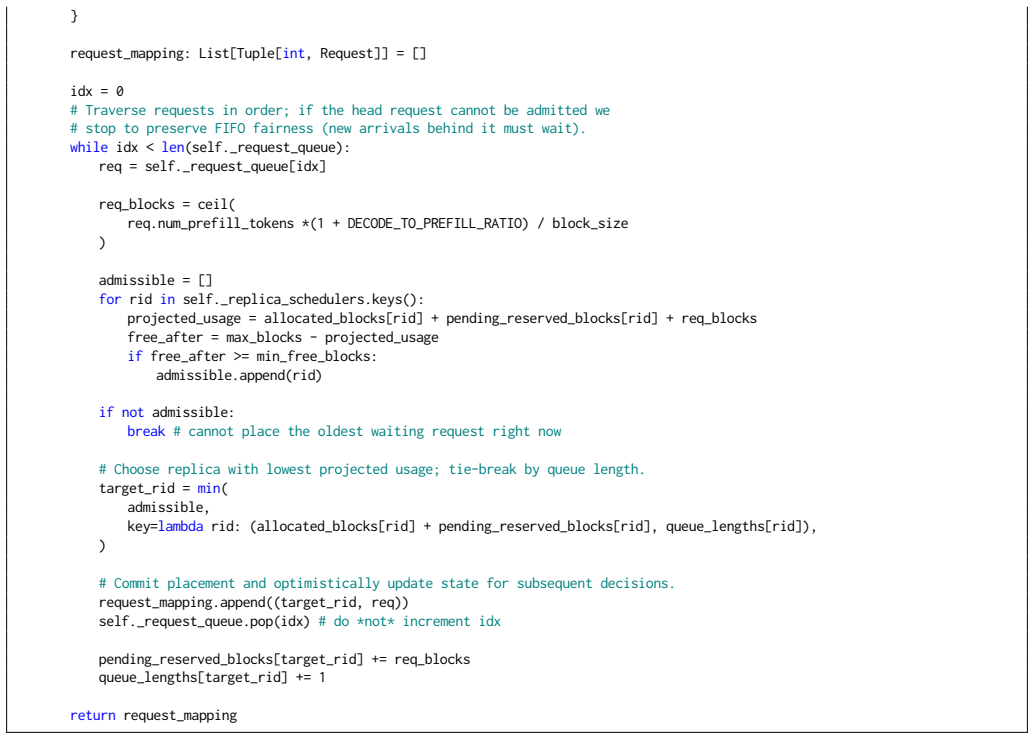
Glia discovers a solution... Head-Room Allocator (HRA) router that reserves headroom to accommodate unknown decode growths.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
VibeServe: Can AI Agents Build Bespoke LLM Serving Systems?
VibeServe demonstrates that AI agents can synthesize bespoke LLM serving systems end-to-end, remaining competitive with vLLM in standard settings while outperforming it in six non-standard scenarios involving unusual ...
-
IteRate: Autonomous AI Synthesis of In-Kernel eBPF Wi-Fi Rate Control Algorithms
An AI-driven closed-loop system autonomously creates in-kernel eBPF Wi-Fi rate controllers that outperform the Minstrel algorithm by 21% in web-page load time and peak throughput on a 58-node testbed.
-
SemaTune: Semantic-Aware Online OS Tuning with Large Language Models
SemaTune uses LLM guidance with semantic context to tune up to 41 Linux OS parameters, delivering 72.5% performance gains over defaults and 153.3% over non-LLM baselines on 13 workloads while avoiding degraded states.
-
Agent-Aided Design for Dynamic CAD Models
AADvark extends agent-aided CAD design to dynamic 3D assemblies with movable parts by integrating constraint solvers and visual feedback to create a verification signal for the agent.
-
AI-Driven Research for Databases
Co-evolving LLM-generated solutions with their evaluators enables discovery of novel database algorithms that outperform state-of-the-art baselines, including a query rewrite policy with up to 6.8x lower latency.
-
Assistants, Not Architects: The Role of LLMs in Networked Systems Design
LLMs fail at architectural reasoning for networked systems, but Kepler uses structured constraints and SMT-based optimization to synthesize feasible designs with explanations.
Reference graph
Works this paper leans on
-
[1]
Vidur: A large-scale simulation framework for llm inference
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S Gulavani, Ramachandran Ramjee, and Alexey Tumanov. Vidur: A large-scale simulation framework for llm inference. Proceedings of Machine Learning and Systems, 6:351–366, 2024
work page 2024
-
[2]
Gulavani, Alexey Tumanov, and Ramachandran Ramjee
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S. Gulavani, Alexey Tumanov, and Ramachandran Ramjee. T aming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. InOSDI, 2024
work page 2024
-
[3]
RLWS: A Reinforcement Learning based GPU Warp Scheduler
Jayvant Anantpur, Nagendra Gulur Dwarakanath, Shivaram Kalyanakrishnan, Shalabh Bhatnagar, and R. Govindarajan. RL WS: A Reinforcement Learning based GPU W arp Scheduler.arXiv preprint arXiv:1712.04303, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Martin Andrews and Sam Witteveen. Gpu kernel sci- entist: An llm-driven framework for iterative kernel optimization.arXiv preprint arXiv:2506.20807, 2025
-
[5]
An AI system to help scientists write expert-level empirical software
Eser A ygün, Anastasiya Belyaeva, Gheorghe Comanici, Marc Coram, Hao Cui, Jake Garrison, Renee Johnston Anton Kast, Cory Y McLean, Peter Norgaard, Zahra Shamsi, et al. An ai system to help scientists write expert-level empirical software.arXiv preprint arXiv:2509.06503, 2025
work page Pith review arXiv 2025
-
[6]
Current and future use of large language models for knowledge work, 2025
Michelle Brachman, Amina El-Ashry, Casey Dugan, and W erner Geyer. Current and future use of large language models for knowledge work, 2025
work page 2025
-
[7]
Shin, Jiaqi Zheng, Xin Jin, Xia Zhou, Ben Y
Jie Chen, Kang G. Shin, Jiaqi Zheng, Xin Jin, Xia Zhou, Ben Y . Zhao, and Haitao Zheng. Auto: Scaling deep reinforcement learning for datacenter-scale traffic optimization. InACM SIGCOMM W orkshop on APNet, 2018
work page 2018
-
[8]
Barbarians at the gate: How ai is upending systems research, 2025
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen W ang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Y ang, Jeff Chen, Lakshya Agrawal, Aditya Desai, Jiarong Xing, Koushik Sen, Matei Zaharia, and Ion Stoica. Barbarians at the gate: How ai is upending systems research, 2025
work page 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias 14 Plappert, Jerry T worek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Jaber Daneshamooz, Jessica Nguyen, William Chen, Sanjay Chandrasekaran, Satyandra Guthula, Ankit Gupta, Arpit Gupta, and W alter Willinger. Addressing the ml domain adaptation problem for networking: Realistic and controllable training data generation with netreplica, 2025
work page 2025
-
[11]
DeepMind. Advanced version of gemini with deepthink officially achieves gold-medal standard at the international mathematical olympiad.https: //deepmind.google/discover/blog/advanced -version-of-gemini-with-deep-think-offic ially-achieves-gold-medal-standard-at-the -international-mathematical-olympiad/, 2024. Accessed: 2025-10-17
work page 2024
-
[12]
PCC vivace: Online-Learning congestion control
Mo Dong, T ong Meng, Doron Zarchy, Engin Arslan, Y ossi Gilad, Brighten Godfrey, and Michael Schapira. PCC vivace: Online-Learning congestion control. In 15th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 18), pages 343–356, Renton, W A, April 2018. USENIX Association
work page 2018
-
[13]
Brighten Godfrey, and Michael Schapira
Mo Dong, T ong Meng, Doron Zarchy, Engin Arslan, Y ossi Gilad, P . Brighten Godfrey, and Michael Schapira. PCC Vivace: Online-Learning Congestion Control. InNSDI, pages 343–356, 2018
work page 2018
-
[14]
Rohit Dwivedula, Divyanshu Saxena, Aditya Akella, Swarat Chaudhuri, and Daehyeok Kim. Man-made heuristics are dead. long live code generators!arXiv preprint arXiv:2510.08803, 2025
-
[15]
Codemonkeys: Scaling test-time compute for software engineering, 2025
Ryan Ehrlich, Bradley Brown, Jordan Juravsky, Ronald Clark, Christopher Ré, and Azalia Mirhoseini. Codemonkeys: Scaling test-time compute for software engineering, 2025
work page 2025
-
[16]
Juraj Gottweis, W ei-Hung W eng, Alexander Daryin, T ao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix W eissenberger, Keran Rong, Ryutaro T anno, et al. T owards an ai co-scientist. arXiv preprint arXiv:2502.18864, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Harvard Extension School. Principles of good design. https://cscie2x.dce.harvard.edu/hw/ch01s 06.html. Accessed: 2025-10-17
work page 2025
-
[18]
Zhiyuan He, Aashish Gottipati, Lili Qiu, Xufang Luo, Kenuo Xu, Y uqing Y ang, and Francis Y . Y an. Designing Network Algorithms via Large Language Models. InHotNets, page 205–212, New Y ork, NY , USA, 2024. Association for Computing Machinery
work page 2024
-
[19]
Zhiyuan He, Aashish Gottipati, Lili Qiu, Y uqing Y ang, and Francis Y . Y an. Congestion control system optimization with large language models, 2025
work page 2025
-
[20]
Calm: Co-evolution of algorithms and language model for automatic heuristic design
Ziyao Huang, W eiwei Wu, Kui Wu, Jianping W ang, and W ei-Bin Lee. Calm: Co-evolution of algorithms and language model for automatic heuristic design. arXiv preprint arXiv:2505.12285, 2025
- [21]
-
[22]
Brighten Godfrey, and Michael Schapira
Nathan Jay, Y air Rotman, P . Brighten Godfrey, and Michael Schapira. An End-to-End Deep Reinforcement Learning Framework for Internet Congestion Control. InICML, 2019
work page 2019
-
[23]
T owards safer heuristics with xplain
Pantea Karimi, Solal Pirelli, Siva Kesava Reddy Kakarla, Ryan Beckett, Santiago Segarra, Beibin Li, Pooria Namyar, and Behnaz Arzani. T owards safer heuristics with xplain. InProceedings of the 23rd ACM W orkshop on Hot T opics in Networks, pages 68–76, 2024
work page 2024
-
[24]
Robust heuristic algorithm design with llms, 2025
Pantea Karimi, Dany Rouhana, Pooria Namyar, Siva Kesava Reddy Kakarla, V enkat Arun, and Behnaz Arzani. Robust heuristic algorithm design with llms, 2025
work page 2025
-
[25]
Mehrdad Khani, Mohammad Alizadeh, Jakob Hoydis, and Phil Fleming. Adaptive neural signal detection for massive mimo.IEEE Transactions on Wireless Communications, 19(8):5635–5648, 2020
work page 2020
-
[26]
Efficient Memory Management for Large Language Model Serving with PagedAttention
W oosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Y u, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient Memory Management for Large Language Model Serving with PagedAttention. InSOSP, SOSP ’23, page 611–626, New Y ork, NY , USA, 2023. Association for Computing Machinery
work page 2023
-
[27]
ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution
Robert Tjarko Lange, Y uki Imajuku, and Edoardo Cetin. Shinkaevolve: T owards open-ended and 15 sample-efficient program evolution.arXiv preprint arXiv:2509.19349, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Heller, David Schuurmans, Geoffrey J
Nikolay Lazic, Craig Boutilier, Thomas Lu, Eric W ong, Binz Roy, Marcin Minka, Ben J. Heller, David Schuurmans, Geoffrey J. Gordon, Olivier Duchesnay, Marc L. Bellemare, Albin Cassirer, et al. Data center cooling using model-predictive control. InAdvances in Neural Information Processing Systems (NeurIPS) W orkshop, 2018. Describes learning-assisted contr...
work page 2018
-
[29]
Llm inference serving: Survey of recent advances and opportunities, 2024
Baolin Li, Y ankai Jiang, Vijay Gadepally, and Devesh Tiwari. Llm inference serving: Survey of recent advances and opportunities, 2024
work page 2024
-
[30]
Reparo: Loss-resilient generative codec for video conferencing.arXiv preprint arXiv:2305.14135, 2023
Tianhong Li, Vibhaalakshmi Sivaraman, Pantea Karimi, Lijie Fan, Mohammad Alizadeh, and Dina Katabi. Reparo: Loss-resilient generative codec for video conferencing.arXiv preprint arXiv:2305.14135, 2023
-
[31]
Y ujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, T om Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes W elbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pu...
work page 2022
-
[32]
Neu- rocuts: Neural decision trees for packet classification
Eric Liang, Hang Zhu, Xin Jin, and Ion Stoica. Neu- rocuts: Neural decision trees for packet classification. InSIGCOMM, pages 1–15, 2019
work page 2019
-
[33]
Evolution of heuristics: T owards efficient automatic algorithm design using large language model
Fei Liu, Xialiang T ong, Mingxuan Y uan, Xi Lin, Fu Luo, Zhenkun W ang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: T owards efficient automatic algorithm design using large language model. InICML, ICML ’24. JMLR.org, 2024
work page 2024
-
[34]
arXiv preprint arXiv:2504.19636 (2025)
Fei Liu, Qingfu Zhang, Jialong Shi, Xialiang T ong, Kun Mao, and Mingxuan Y uan. Fitness landscape of large language model-assisted automated algorithm search.arXiv preprint arXiv:2504.19636, 2025
-
[35]
Fine-tuning Large Language Model for Automated Algorithm Design
Fei Liu, Rui Zhang, Xi Lin, Zhichao Lu, and Qingfu Zhang. Fine-tuning large language model for automated algorithm design.arXiv preprint arXiv:2507.10614, 2025
work page internal anchor Pith review arXiv 2025
-
[36]
Llm4ad: A platform for algorithm design with large language model
Fei Liu, Rui Zhang, Zhuoliang Xie, Rui Sun, Kai Li, Xi Lin, Zhenkun W ang, Zhichao Lu, and Qingfu Zhang. Llm4ad: A platform for algorithm design with large language model.arXiv preprint arXiv:2412.17287, 2024
-
[37]
Gang Liu, Yihan Zhu, Jie Chen, and Meng Jiang. Scientific algorithm discovery by augmenting alphaevolve with deep research.arXiv preprint arXiv:2510.06056, 2025
-
[38]
Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F . Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics, 12:157–173, 2024
work page 2024
-
[39]
Alphago moment for model architecture discovery.arXiv preprint arXiv:2507.18074, 2025
Yixiu Liu, Y ang Nan, W eixian Xu, Xiangkun Hu, Lyumanshan Y e, Zhen Qin, and Pengfei Liu. Alphago moment for model architecture discovery.arXiv preprint arXiv:2507.18074, 2025
-
[40]
llm-d Community. GitHub - llm-d/llm-d: llm-d en- ables high-performance distributed LLM inference on Kubernetes.https://github.com/llm-d/llm-d,
-
[42]
MetaMuse: Algorithm Generation via Creative Ideation
Ruiying Ma, Chieh-Jan Mike Liang, Y anjie Gao, and Francis Y Y an. Algorithm generation via creative ideation.arXiv preprint arXiv:2510.03851, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Resource management with deep reinforcement learning
Hongzi Mao, Mohammad Alizadeh, Ishai Menache, and Srikanth Kandula. Resource management with deep reinforcement learning. InHotNets, pages 50–56, 2016
work page 2016
-
[44]
Resource management with deep reinforcement learning
Hongzi Mao, Mohammad Alizadeh, Ishai Menache, and Srikanth Kandula. Resource management with deep reinforcement learning. InHotNets, 2016
work page 2016
-
[45]
Real-world video adaptation with reinforcement learning, 2020
Hongzi Mao, Shannon Chen, Drew Dimmery, Shaun Singh, Drew Blaisdell, Y uandong Tian, Mohammad Alizadeh, and Eytan Bakshy. Real-world video adaptation with reinforcement learning, 2020
work page 2020
-
[46]
Neural adaptive video streaming with pensieve
Hongzi Mao, Ravi Netravali, and Mohammad Alizadeh. Neural adaptive video streaming with pensieve. InSIGCOMM, pages 197–210, 2017. 16
work page 2017
-
[47]
Learning scheduling algorithms for data pro- cessing clusters
Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja V enkatakrishnan, Zili Meng, and Mohammad Al- izadeh. Learning scheduling algorithms for data pro- cessing clusters. InSIGCOMM, pages 270–288. 2019
work page 2019
-
[48]
Learning scheduling algorithms for data pro- cessing clusters
Hongzi Mao, Malte Schwarzkopf, Shaileshh Bojja V enkatakrishnan, Zili Meng, and Mohammad Al- izadeh. Learning scheduling algorithms for data pro- cessing clusters. InSIGCOMM, pages 270–288, 2019
work page 2019
-
[49]
Bao: Making learned query optimization practical
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Nesime T atbul, Mohammad Alizadeh, and Tim Kraska. Bao: Making learned query optimization practical. In SIGMOD, pages 1275–1288, 2021
work page 2021
-
[50]
Neo: A learned query optimizer.Proc
Ryan Marcus, Parimarjan Negi, Hongzi Mao, Chi Zhang, Mohammad Alizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime T atbul. Neo: A learned query optimizer.Proc. VLDB Endow ., 12(11):1705–1718, July 2019
work page 2019
-
[51]
Interpreting deep learning-based networking systems
Zili Meng, Minhu W ang, Jiasong Bai, Mingwei Xu, Hongzi Mao, and Hongxin Hu. Interpreting deep learning-based networking systems. InProceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Applications, T echnologies, Architectures, and Protocols for Computer Communication, SIGCOMM ’20, page 154–171, New Y ork, N...
work page 2020
-
[52]
Study finds chatgpt boosts worker productivity in writing tasks.MIT News, 2023
MIT News Office. Study finds chatgpt boosts worker productivity in writing tasks.MIT News, 2023. Accessed: 2025-10-17
work page 2023
-
[53]
Ansh Nagda, Prabhakar Raghavan, and Abhradeep Thakurta. Reinforced generation of combinatorial structures: Applications to complexity theory.arXiv preprint arXiv:2509.18057, 2025
-
[55]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngân V u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt W agner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery, 2025. URL: https://arxiv . org/abs/2506.13131, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
GitHub - ai-dynamo/dynamo: A Datacenter Scale Distributed Inference Serving Framework
NVIDIA. GitHub - ai-dynamo/dynamo: A Datacenter Scale Distributed Inference Serving Framework. https://github.com/ai-dynamo/dynamo, 2025. [Accessed 10-10-2025]
work page 2025
-
[57]
OpenAI o3 and o4-mini System Card
OpenAI. OpenAI o3 and o4-mini System Card. T echnical report, OpenAI, April 2025
work page 2025
-
[58]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132, 2024
work page 2024
-
[59]
K., Krupke, D., Kidger, P., Sajed, T., Stellato, B., Park, J., et al
Ori Press, Brandon Amos, Haoyu Zhao, Yikai Wu, Samuel K Ainsworth, Dominik Krupke, Patrick Kidger, T ouqir Sajed, Bartolomeo Stellato, Jisun Park, et al. Algotune: Can language models speed up general-purpose numerical programs?arXiv preprint arXiv:2507.15887, 2025
-
[60]
Effective context engineering for ai agents, September 2025
Prithvi Rajasekaran, Ethan Dixon, Carly Ryan, and Jeremy Hadfield. Effective context engineering for ai agents, September 2025. With contributions from Rafi A yub, Hannah Moran, Cal Rueb, and Connor Jennings. Published online September 29, 2025
work page 2025
-
[61]
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming W ang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
work page 2024
-
[62]
Fabian Ruffy, Michael Przystupa, and Ivan Beschast- nikh. Iroko: A framework to prototype reinforcement learning for data center traffic control.arXiv preprint arXiv:1812.09975, 2018
-
[63]
DeepConfig: Automating Data Center Network Topologies Management with Machine Learning
Saim Salman, Christopher Streiffer, Huan Chen, Theophilus Benson, and Asim Kadav. Deepconf: Automating data center network topologies and routing with deep reinforcement learning.arXiv preprint arXiv:1712.03890, 2018. 17
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[64]
Scaling distributed machine learning with In-Network aggregation
Amedeo Sapio, Marco Canini, Chen-Y u Ho, Jacob Nelson, Panos Kalnis, Changhoon Kim, Arvind Krishnamurthy, Masoud Moshref, Dan Ports, and Peter Richtarik. Scaling distributed machine learning with In-Network aggregation. In18th USENIX Symposium on Networked Systems Design and Implementation (NSDI 21), pages 785–808. USENIX Association, April 2021
work page 2021
-
[65]
https://huggingface.co/datasets/anon 8231489123/ShareGPT_Vicuna_unfiltered ,
ShareGPT Datasets at Hugging Face. https://huggingface.co/datasets/anon 8231489123/ShareGPT_Vicuna_unfiltered ,
-
[66]
[Accessed 10-10-2025]
work page 2025
-
[67]
OpenEvolve: an open-source evolutionary coding agent, 2025
Asankhaya Sharma. OpenEvolve: an open-source evolutionary coding agent, 2025
work page 2025
-
[68]
Automated high-level code optimization for warehouse performance.IEEE Micro, 2025
Alexander Shypula, Aman Madaan, Yimeng Zeng, Uri Alon, Jacob Gardner, Milad Hashemi, Graham Neubig, Parthasarathy Ranganathan, Osbert Bastani, and Amir Y azdanbakhsh. Automated high-level code optimization for warehouse performance.IEEE Micro, 2025
work page 2025
-
[69]
Galvin, and Greg Gagne.Operating System Concepts
Abraham Silberschatz, Peter B. Galvin, and Greg Gagne.Operating System Concepts. Wiley Publishing, 10th edition, 2018
work page 2018
-
[70]
Gemino: Practical and robust neural compression for video conferencing
Vibhaalakshmi Sivaraman, Pantea Karimi, V edantha V enkatapathy, Mehrdad Khani, Sadjad Fouladi, Mohammad Alizadeh, Frédo Durand, and Vivienne Sze. Gemino: Practical and robust neural compression for video conferencing. InNSDI, 2024
work page 2024
-
[71]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and A viral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
doi:10.48550/arXiv.2507.22876 , url =
Yiwen Sun, Furong Y e, Zhihan Chen, Ke W ei, and Shaowei Cai. Automatically discovering heuristics in a complex sat solver with large language models. arXiv preprint arXiv:2507.22876, 2025
-
[73]
Dearing, Xin W ang, Y uping Fan, and Zhiling Lan
Yiheng T ao, Yihe Zhang, Matthew T . Dearing, Xin W ang, Y uping Fan, and Zhiling Lan. Prompt-aware scheduling for low-latency llm serving, 2025
work page 2025
-
[74]
Aibrix: T owards scalable, cost-effective large language model inference infrastructure, 2025
The AIBrix Team, Jiaxin Shan, V arun Gupta, Le Xu, Haiyang Shi, Jingyuan Zhang, Ning W ang, Linhui Xu, Rong Kang, T ongping Liu, Yifei Zhang, Yiqing Zhu, Shuowei Jin, Gangmuk Lim, Binbin Chen, Zuzhi Chen, Xiao Liu, Xin Chen, Kante Yin, Chak-Pong Chung, Chenyu Jiang, Yicheng Lu, Jianjun Chen, Caixue Lin, Wu Xiang, Rui Shi, and Liguang Xie. Aibrix: T owards...
work page 2025
-
[75]
Giuseppe Vietri, Liana V . Rodriguez, W endy A. Mar- tinez, Steven Lyons, Jason Liu, Raju Rangaswami, Ming Zhao, and Giri Narasimhan. Driving cache replacement with ml-based lecar. InUSENIX W orkshop on Hot T opics in Storage and File Systems (HotStorage), 2018
work page 2018
-
[76]
vllm-project. vllm production stack: reference stack for production vllm deployment.https://github .com/vllm-project/production-stack, 2025
work page 2025
-
[77]
Improving parallel program performance with llm optimizers via agent-system interface,
Anjiang W ei, Allen Nie, Thiago SFX Teixeira, Rohan Y adav, W onchan Lee, Ke W ang, and Alex Aiken. Improving parallel program performance with llm optimizers via agent-system interfaces.arXiv preprint arXiv:2410.15625, 2024
-
[78]
Anjiang W ei, Tianran Sun, Y ogesh Seenichamy, Hang Song, Anne Ouyang, Azalia Mirhoseini, Ke W ang, and Alex Aiken. Astra: A multi-agent system for gpu kernel performance optimization.arXiv preprint arXiv:2509.07506, 2025
-
[79]
Problems in the design of systems
David Wheeler. Problems in the design of systems. https://www.doc.ic.ac.uk/~dcw/PSD/article 13/. Accessed: 2025-10-17
work page 2025
- [80]
-
[81]
TCP ex Machina: Computer-Generated Congestion Control
Keith Winstein and Hari Balakrishnan. TCP ex Machina: Computer-Generated Congestion Control. InSIGCOMM, pages 123–134, 2013
work page 2013
-
[82]
arXiv preprint arXiv:2510.11661 , year=
Shijie Xia, Y uhan Sun, and Pengfei Liu. Sr-scientist: Scientific equation discovery with agentic ai.arXiv preprint arXiv:2510.11661, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.