SnapStream: Efficient Long Sequence Decoding on Dataflow Accelerators
Pith reviewed 2026-05-18 01:56 UTC · model grok-4.3
The pith
SnapStream adapts KV cache compression to static-graph frameworks so large LLMs can run 128k context lengths on dataflow accelerators with 4x lower on-chip memory use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SnapStream is a KV cache compression technique that modifies standard multi-head attention to reduce memory footprint while remaining compatible with static graphs and continuous batching. In a 16-way tensor-parallel deployment of DeepSeek-671B on SambaNova SN40L accelerators, it supports 128k context length decoding at up to 1832 tokens per second. The approach yields 4x better on-chip memory usage and only minimal accuracy degradation on LongBench-v2, AIME24, and LiveCodeBench.
What carries the argument
SnapStream, a KV cache compression method that alters multi-head attention to fit inside static computation graphs and continuous batching while preserving model accuracy.
If this is right
- Production inference systems can support 128k context lengths on accelerators with limited on-chip memory.
- High throughput above 1800 tokens per second becomes feasible for 671B-scale models in tensor-parallel setups.
- Sparse KV attention techniques can be added to existing frameworks without rewriting their core scheduling logic.
- Memory savings of 4x allow either larger batch sizes or longer contexts under the same hardware limits.
Where Pith is reading between the lines
- The same compression pattern may transfer to other accelerators that enforce static execution plans.
- Accuracy behavior on reasoning benchmarks could guide whether similar methods apply to multi-turn agent workflows.
- If the approach scales to even larger models, it could reduce the hardware cost of serving long-context applications.
Load-bearing premise
Modifications to the standard multi-head attention algorithm for KV cache compression can be admitted within the static graphs and continuous batching methodology of industrial frameworks without breaking compatibility or causing substantial accuracy loss on modern instruction-following and reasoning models.
What would settle it
Accuracy on LongBench-v2, AIME24, or LiveCodeBench drops substantially below baseline when SnapStream is used in the 16-way DeepSeek-671B deployment, or the claimed 4x on-chip memory reduction fails to appear at 128k context length.
Figures






read the original abstract
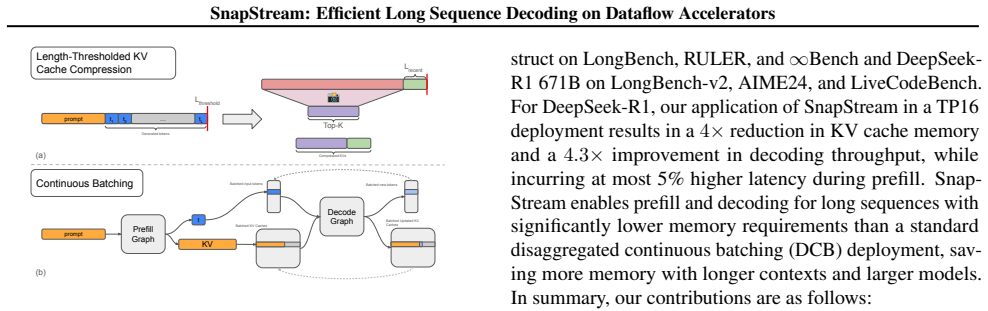
The proliferation of 100B+ parameter Large Language Models (LLMs) with 100k+ context length support have resulted in increasing demands for on-chip memory to support large KV caches. Techniques such as StreamingLLM and SnapKV demonstrate how to control KV cache size while maintaining model accuracy. Yet, these techniques are not commonly used within industrial deployments using frameworks like vLLM or SGLang. The reason is twofold: on one hand, the static graphs and continuous batching methodology employed by these frameworks make it difficult to admit modifications to the standard multi-head attention algorithm, while on the other hand, the accuracy implications of such techniques on modern instruction-following and reasoning models are not well understood, obfuscating the need for implementing these techniques. In this paper, we explore these accuracy implications on Llama-3.1-8B-Instruct and DeepSeek-R1, and develop SnapStream, a KV cache compression method that can be deployed at scale. We demonstrate the efficacy of SnapStream in a 16-way tensor-parallel deployment of DeepSeek-671B on SambaNova SN40L accelerators running at 128k context length and up to 1832 tokens per second in a real production setting. SnapStream enables $4\times$ improved on-chip memory usage and introduces minimal accuracy degradation on LongBench-v2, AIME24 and LiveCodeBench. To the best of our knowledge, this is the first implementation of sparse KV attention techniques deployed in a production inference system with static graphs and continuous batching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SnapStream, a KV cache compression method compatible with static graphs and continuous batching in industrial LLM inference frameworks. It evaluates the accuracy implications of such techniques on Llama-3.1-8B-Instruct and DeepSeek-R1 using LongBench-v2, AIME24, and LiveCodeBench, reporting minimal degradation. The central demonstration is a 16-way tensor-parallel production deployment of DeepSeek-671B on SambaNova SN40L accelerators at 128k context length, achieving up to 1832 tokens per second, 4× improved on-chip memory usage, and claiming this as the first such sparse KV attention deployment in a production system with static graphs and continuous batching.
Significance. If the accuracy preservation transfers to the 671B-scale model under the reported conditions, the result is significant. It supplies the first concrete production evidence that KV-cache compression techniques can be admitted into static-graph, continuous-batching inference stacks without framework breakage, while delivering measurable memory and throughput gains on dataflow hardware for 100k+ context lengths. This directly addresses a practical deployment barrier that has kept academic methods such as StreamingLLM and SnapKV out of industrial use.
major comments (1)
- [Abstract] Abstract and results summary: accuracy evaluation is performed only on Llama-3.1-8B-Instruct and DeepSeek-R1; the production claim for DeepSeek-671B at 128k context under SnapStream supplies no quantitative accuracy numbers, baseline comparisons, or degradation values for that model. Because attention sparsity and reasoning behavior can scale differently at 671B, the transfer of the 'minimal degradation' result remains an unverified assumption that is load-bearing for the central claim.
minor comments (1)
- [Abstract] Abstract: specific numerical accuracy deltas, baseline scores, and error bars are absent, which would allow readers to assess the magnitude of 'minimal accuracy degradation' directly.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The concern about accuracy evaluation at the 671B scale is well-taken, and we address it directly below while proposing targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and results summary: accuracy evaluation is performed only on Llama-3.1-8B-Instruct and DeepSeek-R1; the production claim for DeepSeek-671B at 128k context under SnapStream supplies no quantitative accuracy numbers, baseline comparisons, or degradation values for that model. Because attention sparsity and reasoning behavior can scale differently at 671B, the transfer of the 'minimal degradation' result remains an unverified assumption that is load-bearing for the central claim.
Authors: We agree that the current presentation could be clearer on this distinction. Accuracy evaluations using LongBench-v2, AIME24, and LiveCodeBench were performed exclusively on Llama-3.1-8B-Instruct and DeepSeek-R1, as these models enable thorough, reproducible benchmarking at manageable scale. The 671B production deployment on SambaNova SN40L focuses on system-level outcomes (throughput up to 1832 tokens/sec and 4× on-chip memory reduction) under static graphs and continuous batching. Direct quantitative accuracy measurement at 671B was not feasible within the production setting due to compute cost and the priority on demonstrating deployability. We will revise the abstract and add a dedicated limitations paragraph clarifying the models used for accuracy results, the rationale for proxy evaluation, and the assumption that sparsity behavior transfers across scales. This will make the claims more precise without altering the core system contribution. revision: yes
Circularity Check
No circularity: empirical deployment and benchmark results
full rationale
The paper's central claims rest on direct measurements from a 16-way tensor-parallel deployment of DeepSeek-671B on SambaNova SN40L hardware at 128k context, plus accuracy evaluations on LongBench-v2, AIME24 and LiveCodeBench using Llama-3.1-8B-Instruct and DeepSeek-R1. No derivation chain, equations, or fitted parameters are presented as predictions; the work is an engineering implementation of KV-cache compression within static graphs and continuous batching. No self-definitional steps, load-bearing self-citations, or ansatz smuggling appear in the abstract or described content. The result is self-contained against external hardware and benchmark evidence.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SnapStream applies SnapKV during prefill and StreamingLLM during decoding... ring buffer... Lrb = (L+1−Lsr) mod Lrecent + Lsr
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
KV Cache Offloading for Context-Intensive Tasks
KV offloading degrades accuracy on context-intensive tasks due to low-rank key projections and unreliable landmarks; a simpler alternative improves results across models and benchmarks.
-
KV Cache Offloading for Context-Intensive Tasks
KV offloading hurts accuracy on context-heavy tasks due to low-rank key projections and bad landmarks, but a simpler strategy recovers performance across models.
-
KV Cache Offloading for Context-Intensive Tasks
KV offloading degrades performance on context-intensive tasks due to low-rank key projections and unreliable landmarks, but a simpler alternative strategy restores accuracy across LLM families.
-
KV Cache Offloading for Context-Intensive Tasks
KV offloading hurts accuracy on context-heavy tasks because of low-rank key projections and bad landmarks, but a simpler strategy improves results across models and benchmarks.
Reference graph
Works this paper leans on
-
[1]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
URL https://arxiv.org/abs/2308.16369. Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y ., Lebr´on, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head check- points,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
URL https://arxiv.org/abs/ 2305.13245. Bai, Y ., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y ., Tang, J., and Li, J. Longbench: A bilingual, multitask benchmark for long context understanding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
URL https: //arxiv.org/abs/2308.14508. Behrouz, A., Zhong, P., and Mirrokni, V . Titans: Learning to memorize at test time,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Titans: Learning to Memorize at Test Time
URL https://arxiv. org/abs/2501.00663. Beltagy, I., Peters, M. E., and Cohan, A. Longformer: The long-document transformer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Longformer: The Long-Document Transformer
URL https: //arxiv.org/abs/2004.05150. Chen, K., Xiao, G., Wang, M. Z., and Billa, S. Streamingllm support?,
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[6]
Generating Long Sequences with Sparse Transformers
URL https://arxiv.org/abs/1904.10509. Dao, T., Fu, D. Y ., Ermon, S., Rudra, A., and R´e, C. Flashat- tention: Fast and memory-efficient exact attention with io- awareness,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[7]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
URL https://arxiv.org/abs/ 2205.14135. DeepSeek-AI, Liu, A., Feng, B., Wang, B., Wang, B., Liu, B., Zhao, C., Dengr, C., Ruan, C., Dai, D., Guo, D., et al. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
URL https: //arxiv.org/abs/2405.04434. DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., Zhang, X., Yu, X., Wu, Y ., Wu, Z. F., Gou, Z., Shao, Z., et al. Deepseek-r1: Incentivizing reasoning capa- bility in llms via reinforcement learning, 2025a. URL https://arxiv.org/abs/2501.12948. DeepSeek-AI, Li...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Cartridges: Lightweight and general-purpose long context representations via self-study,
URL https://arxiv.org/abs/2506.06266. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., et al. The llama 3 herd of models,
-
[10]
URL https://arxiv. org/abs/2407.21783. Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., Zhang, Y ., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
RULER: What's the Real Context Size of Your Long-Context Language Models?
URLhttps://arxiv.org/abs/2404.06654. Kamradt, G. Needle in a haystack - pressure testing llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Kimi K2: Open Agentic Intelligence
URL https://arxiv.org/abs/ 2507.20534. Kitaev, N., Łukasz Kaiser, and Levskaya, A. Reformer: The efficient transformer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Reformer: The Efficient Transformer
URL https://arxiv. org/abs/2001.04451. Kwon, W., Li, Z., Zhuang, S., Sheng, Y ., Zheng, L., Yu, C. H., Gonzalez, J. E., Zhang, H., and Stoica, I. Ef- ficient memory management for large language model serving with pagedattention,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[14]
Efficient Memory Management for Large Language Model Serving with PagedAttention
URL https:// arxiv.org/abs/2309.06180. Li, Y ., Huang, Y ., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. Snapkv: Llm knows what you are looking for before generation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
SnapKV: LLM Knows What You are Looking for Before Generation
URL https://arxiv.org/abs/2404.14469. Nandkar, P., Gandhi, D., Farahini, N., Zeffer, H., Long, J., Rydh, S., Musaddiq, M., Zhao, T., Brot, J., Good- bar, R., Du, Y ., Wang, M., and Prabhakar, R. Spec- ulative decoding on the sn40l reconfigurable dataflow unit,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
URL https://doi.org/10.1109/MM. 2025.3592570. NVIDIA, I. Tensorrt. URL https://github.com/ NVIDIA/TensorRT. OpenAI, Agarwal, S., Ahmad, L., Ai, J., Altman, S., Apple- baum, A., Arbus, E., Arora, R. K., Bai, Y ., Baker, B., Bao, H., Barak, B., Bennett, A., Bertao, T., Brett, N., Brevdo, E., Brockman, G., Bubeck, S., Chang, C., Chen, K., Chen, M., et al. gp...
work page doi:10.1109/mm 2025
-
[17]
gpt-oss-120b & gpt-oss-20b Model Card
URLhttps://arxiv.org/abs/2508.10925. Prabhakar, R. Sambanova sn40l rdu: Breaking the barrier of trillion+ parameter scale gen ai computing. In 2024 IEEE Hot Chips 36 Symposium (HCS), pp. 1–24, Los Alamitos, CA, USA, aug
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
doi: 10.1109/HCS61935.2024.10664717
IEEE Computer Society. doi: 10.1109/HCS61935.2024.10664717. URL https://doi.ieeecomputersociety.org/ 10.1109/HCS61935.2024.10664717. Prabhakar, R., Sivaramakrishnan, R., Gandhi, D., Du, Y ., Wang, M., Song, X., Zhang, K., Gao, T., Wang, A., Li, X., Sheng, Y ., Brot, J., Sokolov, D., Vivek, A., Leung, C., Sabnis, A., Bai, J., Zhao, T., Gottscho, M., Jackso...
-
[19]
Tacos: Topology-aware collective algorithm synthesizer for distributed machine learning
1109/micro61859.2024.00100. URL http://dx.doi. org/10.1109/MICRO61859.2024.00100. Riviere, M., Pathak, S., Sessa, P. G., Hardin, C., Bhupatiraju, S., Hussenot, L., Mesnard, T., Shahriari, B., Ram ´e, A., et al. Gemma 2: Improving open language models at a practical size,
-
[20]
Gemma 2: Improving Open Language Models at a Practical Size
URL https://arxiv.org/ abs/2408.00118. Tang, J., Zhao, Y ., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: Query-aware sparsity for efficient long- context llm inference,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Quest: Query-Aware Sparsity for Efficient Long-Context LLM Inference
URL https://arxiv. org/abs/2406.10774. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
URL https://arxiv.org/ abs/1706.03762. Wang, G., Upasani, S., Wu, C., Gandhi, D., Li, J., Hu, C., Li, B., and Thakker, U. Llms know what to drop: Self-attention guided kv cache eviction for efficient long- context inference,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D
URL https://arxiv.org/ abs/2503.08879. Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., and Zhou, D. Chain-of- thought prompting elicits reasoning in large language models,
-
[24]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
URL https://arxiv.org/abs/ 2201.11903. Xiao, C., Zhang, P., Han, X., Xiao, G., Lin, Y ., Zhang, Z., Liu, Z., and Sun, M. Infllm: Training-free long- context extrapolation for llms with an efficient context memory, 2024a. URL https://arxiv.org/abs/ 2402.04617. SnapStream: Efficient Long Sequence Decoding on Dataflow Accelerators Xiao, G., Tian, Y ., Chen, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URL https://arxiv.org/abs/2505.09388. Yu, G.-I. and Jeong, J. S. Orca: A distributed serving system for transformer-based generative models. InUSENIX Symposium on Operating Systems De- sign and Implementation,
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
URL https://arxiv.org/abs/ 2502.11089. Zhang, J., Xiang, C., Huang, H., Wei, J., Xi, H., Zhu, J., and Chen, J. Spargeattention: Accurate and training-free sparse attention accelerating any model inference,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
URLhttps://arxiv.org/abs/2502.18137. Zhang, X., Chen, Y ., Hu, S., Xu, Z., Chen, J., Hao, M. K., Han, X., Thai, Z. L., Wang, S., Liu, Z., and Sun, M. ∞bench: Extending long context evaluation beyond 100k tokens,
-
[28]
∞-bench: Extending long context evaluation beyond 100k tokens
URL https://arxiv.org/abs/ 2402.13718. Zhang, Z., Sheng, Y ., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y ., R´e, C., Barrett, C., Wang, Z., and Chen, B. H2o: Heavy-hitter oracle for efficient generative inference of large language models,
-
[29]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
URL https: //arxiv.org/abs/2306.14048. Zheng, L., Yin, L., Xie, Z., Sun, C., Huang, J., Yu, C. H., Cao, S., Kozyrakis, C., Stoica, I., Gonzalez, J. E., Bar- rett, C., and Sheng, Y . Sglang: Efficient execution of structured language model programs,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
SGLang: Efficient Execution of Structured Language Model Programs
URL https://arxiv.org/abs/2312.07104. Zhong, Y ., Liu, S., Chen, J., Hu, J., Zhu, Y ., Liu, X., Jin, X., and Zhang, H. Distserve: Disaggregating prefill and de- coding for goodput-optimized large language model serv- ing,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.