Toward Training Superintelligent Software Agents through Self-Play SWE-RL
Pith reviewed 2026-05-21 16:02 UTC · model grok-4.3
The pith
An LLM agent trains itself to repair software bugs by generating and fixing its own increasingly complex test-specified tasks inside real codebases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
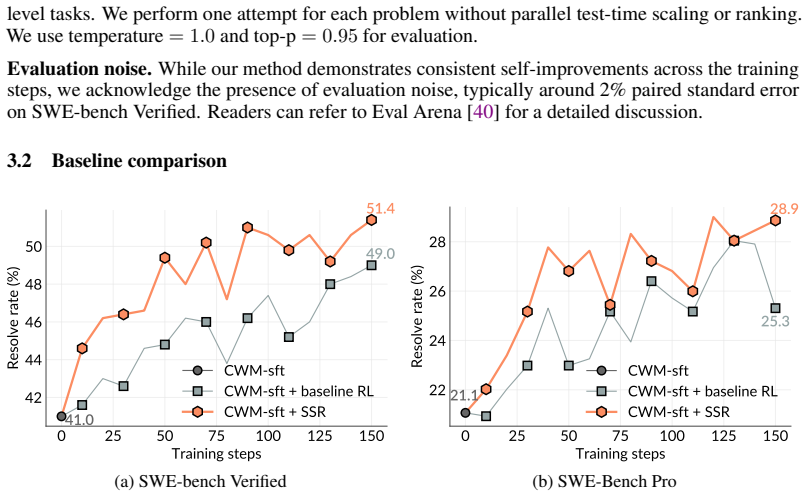
SSR trains one LLM agent via reinforcement learning in a self-play setting inside sandboxed repositories that contain only source code and installed dependencies. The agent generates bug-injection patches and corresponding repair patches, with each task defined by a test patch rather than natural language, and receives rewards based on test outcomes. Over the training trajectory the agent records consistent self-improvement and outperforms a human-data baseline on SWE-bench Verified and SWE-Bench Pro, even though those benchmark issues use natural language descriptions absent from the self-play data.
What carries the argument
Self-play SWE-RL (SSR), the loop in which a single LLM agent generates its own bug-repair tasks by injecting bugs and specifying them with test patches, then learns to solve those tasks through reinforcement learning.
If this is right
- Agents can collect large volumes of training experience directly from existing real-world software repositories without new human labeling.
- Training on patch-specified tasks produces measurable transfer to natural language issue resolution.
- Accuracy keeps rising across the entire training run rather than saturating early.
- The same minimal-assumption setup supplies a concrete route toward agents that exceed human performance in understanding and modifying complex systems.
Where Pith is reading between the lines
- The approach could be extended to self-generated tasks that involve adding new features or refactoring modules rather than only repairing bugs.
- Similar self-play loops might be applied in other sandboxable domains to reduce dependence on human-curated datasets.
Load-bearing premise
Performance gains measured on self-generated bug-repair tasks inside sandboxed repositories will transfer to solving natural language issues drawn from real developer workflows.
What would settle it
Evaluating the trained agent on a fresh collection of natural language bug reports taken from repositories that were never part of the self-play training set and checking whether the reported accuracy advantage disappears.
Figures








read the original abstract
While current software agents powered by large language models (LLMs) and agentic reinforcement learning (RL) can boost programmer productivity, their training data (e.g., GitHub issues and pull requests) and environments (e.g., pass-to-pass and fail-to-pass tests) heavily depend on human knowledge or curation, posing a fundamental barrier to superintelligence. In this paper, we present Self-play SWE-RL (SSR), a first step toward training paradigms for superintelligent software agents. Our approach takes minimal data assumptions, only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests. Grounded in these real-world codebases, a single LLM agent is trained via reinforcement learning in a self-play setting to iteratively inject and repair software bugs of increasing complexity, with each bug formally specified by a test patch rather than a natural language issue description. On the SWE-bench Verified and SWE-Bench Pro benchmarks, SSR achieves notable self-improvement (+10.4 and +7.8 points, respectively) and consistently outperforms the human-data baseline over the entire training trajectory, despite being evaluated on natural language issues absent from self-play. Our results, albeit early, suggest a path where agents autonomously gather extensive learning experiences from real-world software repositories, ultimately enabling superintelligent systems that exceed human capabilities in understanding how systems are constructed, solving novel challenges, and autonomously creating new software from scratch.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Self-play SWE-RL (SSR), a reinforcement learning method in which a single LLM agent is trained via self-play to iteratively inject and repair bugs of increasing complexity inside sandboxed repositories. Bugs are formally specified by test patches rather than natural-language issue descriptions, requiring only access to source code and installed dependencies with no human-labeled issues or tests. The paper reports that SSR produces self-improvement of +10.4 points on SWE-bench Verified and +7.8 points on SWE-Bench Pro, consistently outperforming a human-data baseline across the entire training trajectory, even though evaluation uses natural-language issues absent from self-play. The work is positioned as an early step toward training paradigms for superintelligent software agents that can autonomously gather learning experiences from real-world codebases.
Significance. If the reported gains prove robust and attributable to generalizable agentic reasoning rather than repository-specific familiarity, the self-play paradigm would constitute a meaningful advance by substantially reducing dependence on human-curated training data. The consistent outperformance over the human-data baseline throughout training is a positive signal for scalability. The approach's minimal data assumptions and grounding in real repositories are strengths that could support broader exploration of autonomous software-agent training.
major comments (3)
- [Abstract] Abstract: the claim that natural-language issues are absent from self-play is stated, yet the manuscript is silent on whether the underlying source repositories used for SSR training overlap with those in SWE-bench Verified and SWE-Bench Pro. This distinction is load-bearing for the transfer claim; substantial overlap would allow the observed gains (+10.4 / +7.8 points) to arise from increased exposure to specific codebases, APIs, and test structures rather than improved general reasoning.
- [Experimental results] Experimental results section: no details are provided on training stability, variance across independent runs, or statistical significance of the benchmark improvements. Without these, it is difficult to determine whether the self-improvement trajectory is reliable or sensitive to random seeds and hyperparameter choices.
- [Method and evaluation] Method and evaluation sections: the paper does not describe how bug complexity is controlled or increased during self-play, nor how the self-generated test-patch tasks are ensured to be disjoint in difficulty and structure from the natural-language issues in the evaluation benchmarks. This control is necessary to support the claim that improvements transfer beyond the self-play distribution.
minor comments (2)
- [Abstract] Abstract and title: the phrasing 'superintelligent software agents' and 'superintelligence' should be qualified as aspirational given the preliminary scale of the experiments.
- [Throughout] Throughout the manuscript: ensure consistent definition of acronyms (SSR, SWE-RL) on first use and clarify the precise composition of the human-data baseline for direct comparison.
Simulated Author's Rebuttal
We thank the referee for their insightful comments and the opportunity to improve our manuscript. Below, we provide a point-by-point response to the major comments and indicate the revisions made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that natural-language issues are absent from self-play is stated, yet the manuscript is silent on whether the underlying source repositories used for SSR training overlap with those in SWE-bench Verified and SWE-Bench Pro. This distinction is load-bearing for the transfer claim; substantial overlap would allow the observed gains (+10.4 / +7.8 points) to arise from increased exposure to specific codebases, APIs, and test structures rather than improved general reasoning.
Authors: We agree that clarifying the repository overlap is essential to substantiate the transfer of improvements. The training repositories for SSR are selected from a diverse set of open-source projects that do not intersect with the SWE-bench Verified or SWE-Bench Pro repositories. This separation ensures that the agent learns general bug injection and repair strategies rather than memorizing specific codebases. In the revised manuscript, we have added this information to the Abstract and the Experimental Setup section, along with a table listing the training repositories to make the distinction explicit. revision: yes
-
Referee: [Experimental results] Experimental results section: no details are provided on training stability, variance across independent runs, or statistical significance of the benchmark improvements. Without these, it is difficult to determine whether the self-improvement trajectory is reliable or sensitive to random seeds and hyperparameter choices.
Authors: We acknowledge the importance of reporting training stability and statistical measures for reproducibility. We have conducted additional analysis on three independent training runs with varied random seeds. The revised Experimental Results section now includes plots showing the mean performance trajectory with standard deviation bands, and we report p-values from statistical tests confirming the significance of the +10.4 and +7.8 point gains over the baseline. These additions demonstrate that the self-improvement is robust and not overly sensitive to initialization. revision: yes
-
Referee: [Method and evaluation] Method and evaluation sections: the paper does not describe how bug complexity is controlled or increased during self-play, nor how the self-generated test-patch tasks are ensured to be disjoint in difficulty and structure from the natural-language issues in the evaluation benchmarks. This control is necessary to support the claim that improvements transfer beyond the self-play distribution.
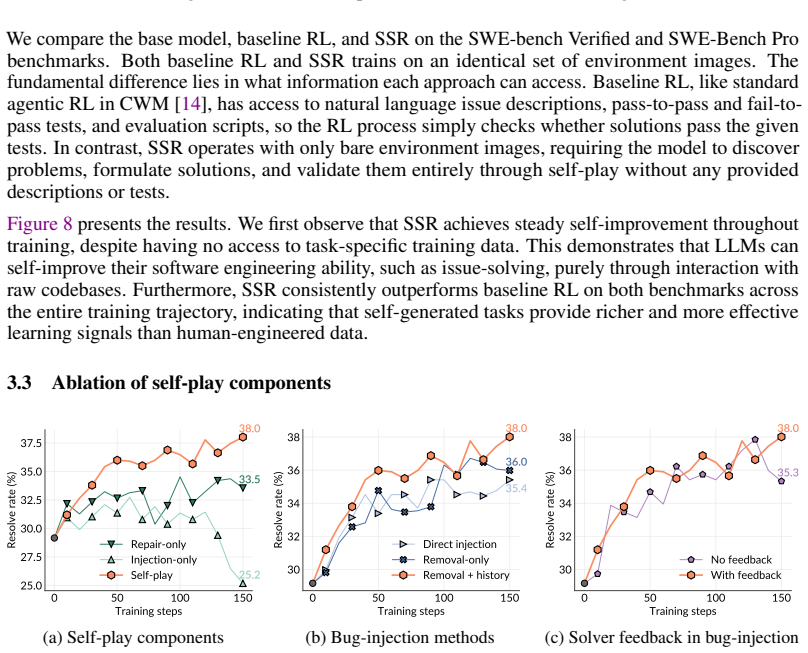
Authors: Thank you for this valuable suggestion. Bug complexity in self-play is controlled through a progressive curriculum: we begin with bugs affecting a single function and gradually increase to bugs spanning multiple files and functions, with complexity measured by the size of the test patch (number of lines modified) and the number of test cases involved. The agent's reward is tied to successful repair, allowing it to advance to harder bugs only after mastering simpler ones. For disjointness, the self-play tasks are generated within the training repositories using synthetic test patches, while the evaluation benchmarks consist of real natural-language issues from entirely separate repositories, creating a clear distribution shift in both task specification (test patch vs. NL description) and repository content. We have substantially expanded the Method section with a new subsection detailing the complexity scheduling algorithm and the distribution shift analysis to address this concern. revision: yes
Circularity Check
No significant circularity; empirical self-play gains are measured outcomes, not definitional reductions
full rationale
The paper defines a self-play RL loop that generates training signals via test-patch-specified bug injection and repair inside sandboxed repositories, then reports measured accuracy gains on separate SWE-bench natural-language benchmarks. No equations, fitted parameters, or self-citations are shown that make the reported +10.4 / +7.8 point improvements equivalent to the training inputs by construction. The self-play procedure is specified independently of the final benchmark scores, and the transfer claim rests on an empirical evaluation rather than a tautological identity. Potential repository overlap is a methodological concern about external validity, not a circularity in the derivation chain itself.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sandboxed repositories with source code and installed dependencies contain enough structure for an agent to learn transferable bug-injection and repair skills
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a single LLM policy is instantiated in two roles ... bug-injection agent and a bug-solving agent ... higher-order bugs constructed from the solver’s own failed repair attempts ... r_inject = 1-(1+α)s for 0<s<1
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
only requiring access to sandboxed repositories with source code and installed dependencies, with no need for human-labeled issues or tests
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
This survey introduces the Generate-Filter-Control-Replay (GFCR) taxonomy to structure rollout pipelines for RL-based post-training of reasoning LLMs.
-
Spreadsheet-RL: Advancing Large Language Model Agents on Realistic Spreadsheet Tasks via Reinforcement Learning
Spreadsheet-RL applies RL fine-tuning and a custom Gym environment to raise LLM agent Pass@1 scores on spreadsheet benchmarks from roughly 8-12% to 17-23%.
-
PREPING: Building Agent Memory without Tasks
Preping builds agent memory via proposer-guided synthetic practice and selective validation, matching offline/online methods at 2-3x lower deployment cost.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.