AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Pith reviewed 2026-05-16 14:07 UTC · model grok-4.3
The pith
AgencyBench shows closed-source models outperforming open-source ones 48.4% to 32.1% on long-horizon tasks averaging one million tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AgencyBench establishes that closed-source models significantly outperform open-source models on realistic long-horizon agent tasks and that performance depends on alignment between model and agentic scaffold, with proprietary models strongest in native ecosystems and open-source models showing distinct framework-specific peaks.
What carries the argument
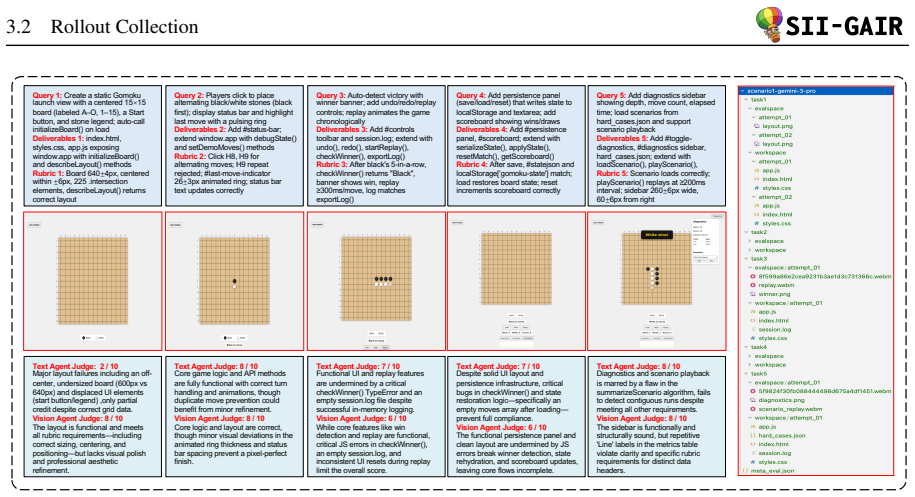
User simulation agent supplying iterative feedback together with a Docker sandbox for rubric-based visual and functional assessment, applied to 138 tasks that average 90 tool calls and one million tokens each.
If this is right
- Closed-source models achieve substantially higher success rates than open-source models across the benchmark.
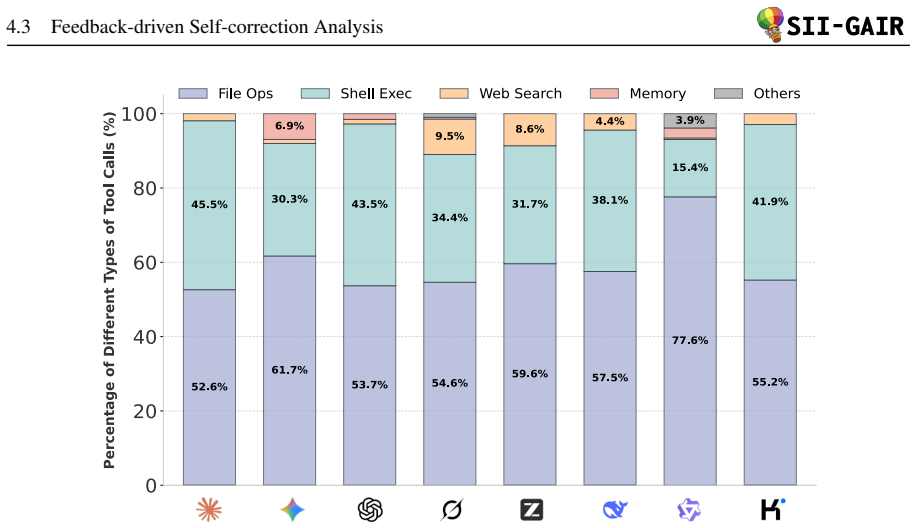
- Models differ markedly in resource efficiency, ability to self-correct from feedback, and preferences for particular tools.
- Proprietary models reach their highest performance when run inside their native agent frameworks.
- Open-source models display clear performance peaks when paired with specific execution frameworks.
- Future gains require co-optimizing model architecture together with the surrounding agentic framework.
Where Pith is reading between the lines
- Open-source model developers could target feedback-driven self-correction as a concrete route to close the observed gap.
- The 32 scenarios could serve as a fixed test set for measuring whether larger open models narrow the closed-source lead over time.
- Embedding AgencyBench tasks directly into agent training loops might accelerate improvement on long-horizon consistency.
Load-bearing premise
The user simulation agent supplies realistic, unbiased iterative feedback that matches human judgment for long-horizon tasks.
What would settle it
A side-by-side run of a random subset of tasks using both the simulation agent and real human users, then comparing the agent success scores and the quality of feedback provided.
Figures



read the original abstract
Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgencyBench, a benchmark for LLM-based autonomous agents on long-horizon real-world tasks. It comprises 32 scenarios and 138 tasks (averaging 90 tool calls and 1M tokens each) derived from daily AI usage, evaluating 6 core agentic capabilities. Automated evaluation is enabled via a user simulation agent for iterative feedback and a Docker sandbox for visual/functional rubric assessment. Key results show closed-source models outperforming open-source models (48.4% vs 32.1% success), with further analysis of resource efficiency, self-correction, tool-use preferences, and the effects of agentic scaffolds. The benchmark and toolkit are released publicly.
Significance. If the user simulation agent's feedback is shown to align with human judgment, AgencyBench would provide a scalable, automated testbed for complex agent capabilities that existing single-step benchmarks cannot capture. The reported performance gaps, efficiency disparities, and scaffold interactions could inform co-optimization of models and frameworks, while the public release supports reproducibility and further research in autonomous agents.
major comments (3)
- [Abstract and §4] Abstract and §4 (Evaluation Setup): The headline result (closed-source 48.4% vs open-source 32.1%) is generated by an automated loop relying on the user simulation agent to supply iterative feedback over ~90 tool calls. No correlation coefficients, inter-rater agreement scores, or ablation comparing simulator feedback to human judgments on the same long-horizon trajectories are reported, leaving the performance ordering vulnerable to simulation-specific artifacts.
- [§3] §3 (Benchmark Construction): The 138 tasks and associated rubrics are described at a high level, but the manuscript provides no details on rubric derivation process, pilot validation against real-user outcomes, or measures of simulation fidelity for the 1M-token contexts. This weakens claims about the benchmark capturing genuine real-world agent performance.
- [§5] §5 (Analysis of Self-Correction and Tool Use): The reported disparities in feedback-driven self-correction and tool-use preferences across model families are presented without quantitative ablations isolating the contribution of the simulator versus intrinsic model differences; this makes it difficult to attribute the gaps solely to agent capability.
minor comments (3)
- [Abstract] The abstract refers to '6 core agentic capabilities' without enumerating them explicitly in the provided text.
- [Related Work] Consider adding citations to prior long-horizon agent benchmarks (e.g., WebArena, AgentBench) for clearer positioning in the related work section.
- [Figures and Tables] Figure captions and table headers could more explicitly state the number of runs or statistical significance for the reported percentages.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our work. We have carefully considered each point and provide point-by-point responses below, along with indications of revisions to be made in the updated manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation Setup): The headline result (closed-source 48.4% vs open-source 32.1%) is generated by an automated loop relying on the user simulation agent to supply iterative feedback over ~90 tool calls. No correlation coefficients, inter-rater agreement scores, or ablation comparing simulator feedback to human judgments on the same long-horizon trajectories are reported, leaving the performance ordering vulnerable to simulation-specific artifacts.
Authors: We agree that demonstrating alignment between the user simulation agent and human judgment is essential for validating the benchmark's reliability. In the revised version, we will add a dedicated subsection in §4 that presents a human evaluation study on a representative subset of tasks. This study will include correlation coefficients (e.g., Pearson and Spearman) between simulator-provided feedback and human assessments, as well as inter-rater agreement metrics. We will also include an ablation comparing performance under simulator vs. human feedback loops where feasible. These additions will directly address concerns about simulation-specific artifacts. revision: yes
-
Referee: [§3] §3 (Benchmark Construction): The 138 tasks and associated rubrics are described at a high level, but the manuscript provides no details on rubric derivation process, pilot validation against real-user outcomes, or measures of simulation fidelity for the 1M-token contexts. This weakens claims about the benchmark capturing genuine real-world agent performance.
Authors: We appreciate this observation and will substantially expand §3 in the revision. The updated section will detail the rubric derivation process, which involved iterative refinement based on real-world AI usage logs and expert review. We will describe the pilot validation conducted with actual users to ensure rubrics reflect realistic outcomes. Additionally, we will report quantitative measures of simulation fidelity, such as the agreement rate between simulated user responses and human responses in sampled interactions, particularly for long-context scenarios. This will provide stronger evidence for the benchmark's real-world relevance. revision: yes
-
Referee: [§5] §5 (Analysis of Self-Correction and Tool Use): The reported disparities in feedback-driven self-correction and tool-use preferences across model families are presented without quantitative ablations isolating the contribution of the simulator versus intrinsic model differences; this makes it difficult to attribute the gaps solely to agent capability.
Authors: We acknowledge the need for clearer isolation of factors in our analysis. In the revised manuscript, we will enhance §5 with additional ablations. Specifically, we will include experiments where the same models are evaluated under both the simulator and a human-in-the-loop setup on a subset of tasks to quantify the simulator's influence. We will also present results controlling for the simulator by using fixed feedback templates derived from human data. These ablations will help attribute observed disparities more confidently to differences in model capabilities. revision: yes
Circularity Check
No significant circularity; purely empirical benchmark with direct rubric measurements
full rationale
The paper presents AgencyBench as an empirical evaluation framework consisting of 138 tasks with fixed queries, deliverables, and rubrics. Performance is computed directly via rubric-based assessment inside a Docker sandbox after iterative feedback from the simulation agent. No equations, fitted parameters, or derivations are present that reduce the reported scores (48.4% closed-source vs 32.1% open-source) to inputs by construction. The simulation agent is a methodological tool for automation rather than a self-referential component whose outputs are defined in terms of the measured results. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The derivation chain is therefore self-contained against external task definitions and rubrics.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents can execute multi-step tasks using external tools over long horizons
- domain assumption Simulated user feedback approximates human feedback for evaluation purposes
Forward citations
Cited by 5 Pith papers
-
SWE-Chain: Benchmarking Coding Agents on Chained Release-Level Package Upgrades
SWE-Chain provides 155 chained version transitions and 1,660 requirements across 9 Python packages, where frontier agents resolve 44.8% of tasks on average and struggle to preserve functionality across releases.
-
How to Interpret Agent Behavior
ACT*ONOMY is a Grounded-Theory-derived hierarchical taxonomy and open repository that enables systematic comparison and characterization of autonomous agent behavior across trajectories.
-
HMACE: Heterogeneous Multi-Agent Collaborative Evolution for Combinatorial Optimization
HMACE deploys Proposer, Generator, Evaluator, and Reflector agents in an evolutionary loop to generate and refine heuristics for NP-hard problems, reporting lower optimality gaps and token costs than baselines on TSP ...
-
Aligned Agents, Biased Swarm: Measuring Bias Amplification in Multi-Agent Systems
Multi-agent systems amplify minor stochastic biases into systemic polarization via echo-chamber effects in structured workflows, even with neutral agents.
-
FileGram: Grounding Agent Personalization in File-System Behavioral Traces
FileGram grounds AI agent personalization in file-system behavioral traces via a data simulation engine, a diagnostic benchmark, and a bottom-up memory architecture.
Reference graph
Works this paper leans on
-
[1]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, et al. 2024. Openhands: An open platform for ai software developers as generalist agents.arXiv preprint arXiv:2407.16741
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [3]
- [4]
-
[5]
xAI. 2025. grok-4.1.https://x.ai/news/grok-4-1
work page 2025
- [6]
- [7]
- [8]
- [9]
- [10]
-
[11]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652
work page 2024
-
[13]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations. 12 A. Appendix SII-GAIR A Appendix Scenarios Tasks Game 10 50 Front-end 3 15 Back-end 3 15 Code 9 29 Research 5 19 MCP 2 10 Tota...
work page 2022
-
[14]
The ”Executors”:There is a striking divergence in how models orient themselves
The ”Navigators” vs. The ”Executors”:There is a striking divergence in how models orient themselves. GLM-4.6 exhibits a unique ”navigator” strategy, invokinglist directory 158 times—nearly triple the av- erage of other models. This indicates a strong preference for gathering environmental context before taking ac- tion. Conversely, GPT-5.2 and Claude-4.5-...
-
[15]
”Rewriters”:The data reveals a fundamental difference in code modification philosophies
Editing Styles: ”Surgeons” vs. ”Rewriters”:The data reveals a fundamental difference in code modification philosophies. GPT-5.2 acts as a ”surgeon,” heavily utilizing the replace tool (146 invocations) to make precise, localized edits to existing files. In sharp contrast, GLM-4.6 overwhelmingly prefers thewrite file tool (381 invocations), suggesting a te...
-
[16]
Memory Utilization:Gemini-3-Pro stands out as the sole model to effectively leverage long-term memory capabilities. It is the only model to record significant usage of update memory bank (22 times) and initialize memory bank (7 times). While other models rely entirely on their context window, Gemini attempts to persist state and key information externally...
-
[17]
Information Retrieval:For external knowledge acquisition, GLM-4.6 again shows a distinct profile, us- ing web fetch 96 times, whereas models like Claude-4.5-Opus and GPT-5.2 rely more on their internal knowledge or specific search queries (search file content). 13 A.2 Evaluation Prompts SII-GAIR Claude-4.5-O Claude-4.5-S Gemini-3 GPT-5.2 Grok-4.1 GLM-4.6 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.