TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Pith reviewed 2026-05-16 11:03 UTC · model grok-4.3
The pith
TouchGuide steers pre-trained visuomotor policies at inference time using a contact physical model to produce physically valid actions for contact-rich tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints.
What carries the argument
The Contact Physical Model (CPM), a task-specific module trained via contrastive learning on expert demonstrations that supplies tactile-informed feasibility scores to refine policy sampling toward physically valid contacts.
If this is right
- TouchGuide consistently outperforms state-of-the-art visuo-tactile policies on five contact-rich manipulation tasks.
- The method works with both diffusion-based and flow-matching visuomotor policies without modifying their training.
- Steering happens only at inference time, preserving the original policy while adding tactile constraints.
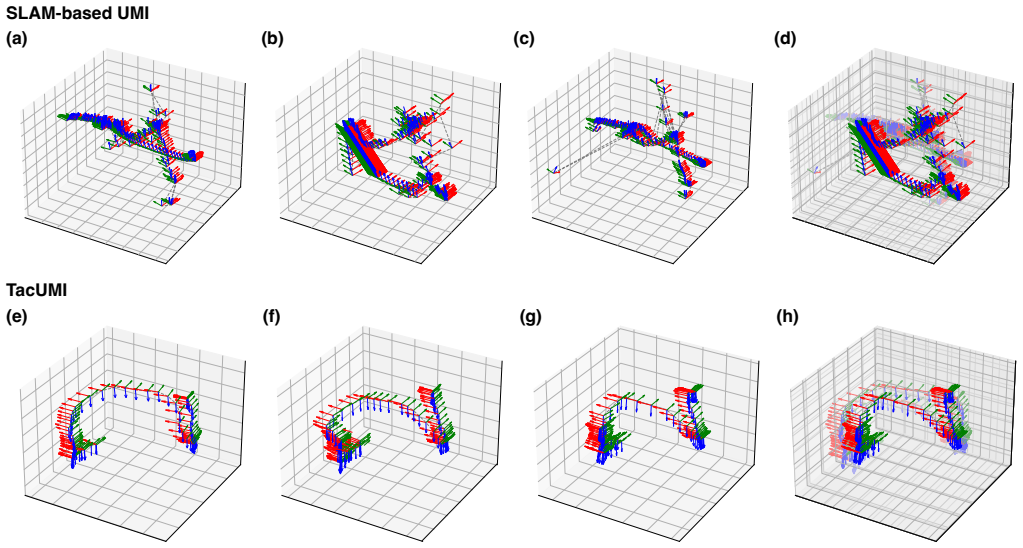
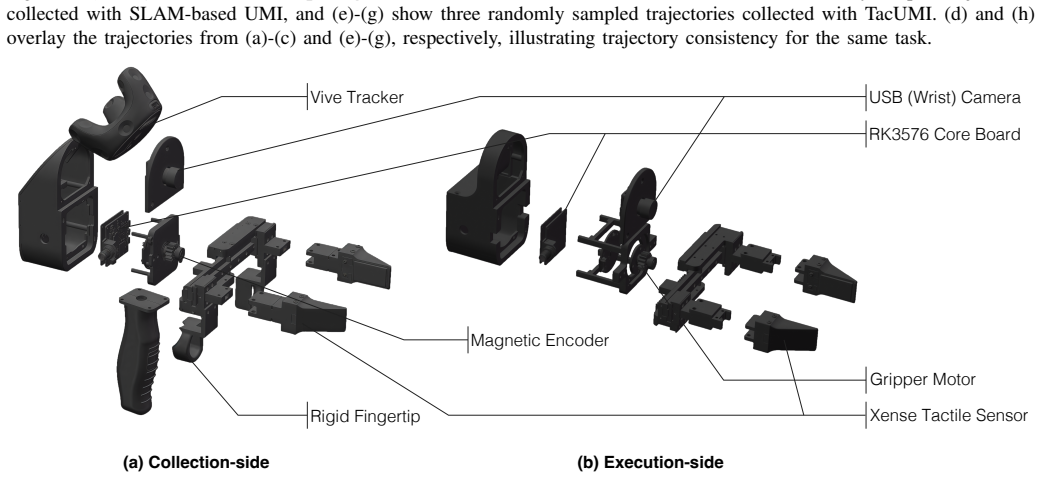
- TacUMI enables collection of high-quality tactile data at lower cost using rigid fingertips for direct feedback.
- The low-dimensional action-space fusion reduces the need for end-to-end multimodal retraining.
Where Pith is reading between the lines
- This separation of visual generation and tactile refinement could let teams reuse large-scale visual pre-training across many contact tasks by swapping only the lightweight CPM.
- If the feasibility scoring proves robust, similar inference-time modules might be added for other modalities such as force or audio to further constrain sampling.
- The approach opens a path to rapid adaptation on new hardware or objects by collecting a small expert set and training one new CPM rather than retraining the full policy.
- In deployment, the method could lower the rate of physically unsafe actions by rejecting low-feasibility samples before execution.
Load-bearing premise
The task-specific Contact Physical Model trained on limited expert demonstrations will generalize to give accurate feasibility scores that correctly identify and steer toward physically valid contact actions in new situations.
What would settle it
Measuring that guided actions on a held-out contact-rich task violate physical constraints at a similar rate to the unguided baseline or produce no improvement in task success rate would falsify the central claim.
Figures










read the original abstract
Fine-grained and contact-rich manipulation remain challenging for robots, largely due to the underutilization of tactile feedback. To address this, we introduce TouchGuide, a novel cross-policy visuo-tactile fusion paradigm that fuses modalities within a low-dimensional action space. Specifically, TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model (CPM) provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints. Furthermore, to facilitate TouchGuide training with high-quality and cost-effective data, we introduce TacUMI, a data collection system. TacUMI achieves a favorable trade-off between precision and affordability; by leveraging rigid fingertips, it obtains direct tactile feedback, thereby enabling the collection of reliable tactile data. Extensive experiments on five challenging contact-rich tasks, such as shoe lacing and chip handover, show that TouchGuide consistently and significantly outperforms state-of-the-art visuo-tactile policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TouchGuide, a two-stage inference-time method for steering pre-trained diffusion or flow-matching visuomotor policies using tactile feedback. A task-specific Contact Physical Model (CPM), trained via contrastive learning on limited expert demonstrations, provides feasibility scores to refine coarse visual actions toward physically valid contacts. The work also presents TacUMI, a rigid-fingertip data collection system for affordable tactile data. Experiments on five contact-rich tasks (e.g., shoe lacing, chip handover) claim consistent and significant outperformance over state-of-the-art visuo-tactile policies.
Significance. If the quantitative results and generalization claims hold under scrutiny, TouchGuide offers a practical advance for contact-rich manipulation by enabling tactile-informed refinement at inference time without retraining the base policy. This could reduce the data and compute burden for fine-grained tasks while improving physical feasibility, provided the CPM proves robust beyond the training distribution.
major comments (2)
- Abstract: The claim of 'consistent and significant outperformance' on five tasks is stated without any quantitative metrics, baselines, error bars, or ablation details, which prevents assessment of effect sizes or statistical reliability.
- CPM training and evaluation sections: No ablations are reported on the number of expert demonstrations required for CPM training, cross-task transfer performance, or robustness to contact variations (friction, compliance, sensor noise). This leaves open the possibility that reported gains arise from overfitting to demonstration-specific contact patterns rather than a general steering mechanism.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights opportunities to improve the clarity and robustness of our claims. We address each major comment below and will make targeted revisions to the manuscript.
read point-by-point responses
-
Referee: Abstract: The claim of 'consistent and significant outperformance' on five tasks is stated without any quantitative metrics, baselines, error bars, or ablation details, which prevents assessment of effect sizes or statistical reliability.
Authors: We agree that the abstract would benefit from including key quantitative results. The main paper (Section 5, Tables 1-3) already reports success rates with error bars, baselines, and statistical comparisons across all five tasks. In the revised version, we will update the abstract to preview representative metrics (e.g., average success rate improvements of 18-32% over state-of-the-art visuo-tactile baselines) while directing readers to the full experimental details. This change will allow better assessment of effect sizes without altering the underlying claims. revision: yes
-
Referee: CPM training and evaluation sections: No ablations are reported on the number of expert demonstrations required for CPM training, cross-task transfer performance, or robustness to contact variations (friction, compliance, sensor noise). This leaves open the possibility that reported gains arise from overfitting to demonstration-specific contact patterns rather than a general steering mechanism.
Authors: We appreciate this important point regarding potential overfitting. The current manuscript demonstrates TouchGuide's effectiveness using the collected demonstrations but does not include the requested ablations. In the revision, we will add: (i) an ablation study varying the number of expert demonstrations (5, 10, 20) for CPM training, (ii) cross-task transfer experiments where a CPM trained on one task is applied to another, and (iii) robustness tests introducing sensor noise and friction/compliance variations in simulation. These results will be included in the main text or supplementary material to support that the steering mechanism generalizes beyond demonstration-specific patterns. revision: yes
Circularity Check
No circularity: empirical method with separate training and inference stages
full rationale
The paper describes TouchGuide as a two-stage inference-time steering procedure: a pre-trained visuomotor policy generates coarse actions from vision, then a separately trained task-specific Contact Physical Model (CPM) supplies feasibility scores to refine sampling. The CPM is trained contrastively on expert demonstrations and applied at test time; the headline results are experimental outperformance on five tasks. No equations, derivations, or self-citations are presented that reduce the claimed gains to the training inputs by construction. The generalization of the CPM is an empirical assumption, not a definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- CPM contrastive learning hyperparameters
axioms (1)
- domain assumption Pre-trained diffusion or flow-matching visuomotor policies produce coarse visually-plausible actions in early sampling steps
invented entities (2)
-
Contact Physical Model (CPM)
no independent evidence
-
TacUMI
no independent evidence
Forward citations
Cited by 4 Pith papers
-
Referring-Aware Visuomotor Policy Learning for Closed-Loop Manipulation
ReV is a referring-aware visuomotor policy using coupled diffusion heads for real-time trajectory replanning in robotic manipulation, trained solely via targeted perturbations to expert demonstrations and achieving hi...
-
Learning Tactile-Aware Quadrupedal Loco-Manipulation Policies
A tactile-aware hierarchical policy for quadrupedal loco-manipulation improves real-world contact-rich task performance by 28.54% over vision-only and visuotactile baselines.
-
TAMEn: Tactile-Aware Manipulation Engine for Closed-Loop Data Collection in Contact-Rich Tasks
TAMEn supplies a cross-morphology wearable interface and pyramid-structured visuo-tactile data regime that raises bimanual manipulation success rates from 34% to 75% via closed-loop collection.
-
Learning Tactile-Aware Quadrupedal Loco-Manipulation Policies
A hierarchical tactile-aware policy combines human-demonstration training for contact cue prediction with sim-to-real reinforcement learning to improve quadrupedal loco-manipulation performance by 28.54% over vision b...
Reference graph
Works this paper leans on
-
[1]
Aloha 2: An enhanced low-cost hardware for bimanual teleoperation,
Jorge Aldaco, Travis Armstrong, Robert Baruch, Jeff Bingham, Sanky Chan, Kenneth Draper, De- bidatta Dwibedi, Chelsea Finn, Pete Florence, Spencer Goodrich, et al. Aloha 2: An enhanced low-cost hardware for bimanual teleoperation.arXiv preprint arXiv:2405.02292, 2024. 2
- [2]
-
[3]
Bifold: Bimanual cloth folding with language guidance.arXiv preprint arXiv:2501.16458, 2025
Oriol Barbany, Adri `a Colom´e, and Carme Torras. Bifold: Bimanual cloth folding with language guidance.arXiv preprint arXiv:2501.16458, 2025. 1
-
[4]
Jianxin Bi, Kevin Yuchen Ma, Ce Hao, Mike Zheng Shou, and Harold Soh. Vla-touch: Enhancing vision- language-action models with dual-level tactile feedback. arXiv preprint arXiv:2507.17294, 2025. 1, 2, 6
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A vi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Bi-act: Bilateral control-based imitation learning via action chunking with transformer
Thanpimon Buamanee, Masato Kobayashi, Yuki Uran- ishi, and Haruo Takemura. Bi-act: Bilateral control-based imitation learning via action chunking with transformer. In2024 IEEE International Conference on Advanced Intelligent Mechatronics (AIM), pages 410–415. IEEE,
-
[7]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch
Remi Cadene, Simon Alibert, Alexander Soare, Quentin Gallouedec, Adil Zouitine, Steven Palma, Pepijn Kooijmans, Michel Aractingi, Mustafa Shukor, Dana Aubakirova, Martino Russi, Francesco Capuano, Caro- line Pascal, Jade Choghari, Jess Moss, and Thomas Wolf. Lerobot: State-of-the-art machine learning for real-world robotics in pytorch. https://github.com/...
work page 2024
-
[8]
Jiahang Cao, Yize Huang, Hanzhong Guo, Rui Zhang, Mu Nan, Weijian Mai, Jiaxu Wang, Hao Cheng, Jingkai Sun, Gang Han, et al. Compose your policies! im- proving diffusion-based or flow-based robot policies via test-time distribution-level composition.arXiv preprint arXiv:2510.01068, 2025. 1, 6
-
[9]
Multi-Modal Manipulation via Multi-Modal Policy Consensus
Haonan Chen, Jiaming Xu, Hongyu Chen, Kaiwen Hong, Binghao Huang, Chaoqi Liu, Jiayuan Mao, Yunzhu Li, Yilun Du, and Katherine Driggs-Campbell. Multi-modal manipulation via multi-modal policy consensus.arXiv preprint arXiv:2509.23468, 2025. 1, 2, 6, 7, 17, 25, 28
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yi- heng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain random- ization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational con- ference on machine learning, pages 1597–1607. PmLR,
-
[12]
Visuo-tactile transformers for manipulation,
Yizhou Chen, Andrea Sipos, Mark Van der Merwe, and Nima Fazeli. Visuo-tactile transformers for manipulation. arXiv preprint arXiv:2210.00121, 2022. 2
-
[13]
Zhengxue Cheng, Yiqian Zhang, Wenkang Zhang, Haoyu Li, Keyu Wang, Li Song, and Hengdi Zhang. Omnivtla: Vision-tactile-language-action model with semantic- aligned tactile sensing.arXiv preprint arXiv:2508.08706,
-
[14]
Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots
Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. Universal manipulation interface: In-the- wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024. 2, 3, 4, 8, 18, 20, 28
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025. 1, 2, 3, 4, 6, 18, 25, 28
work page 2025
-
[16]
In-the-wild compliant manipulation with umi-ft.arXiv preprint arXiv:2601.09988, 2026
Hojung Choi, Yifan Hou, Chuer Pan, Seongheon Hong, Austin Patel, Xiaomeng Xu, Mark R Cutkosky, and Shuran Song. In-the-wild compliant manipulation with umi-ft.arXiv preprint arXiv:2601.09988, 2026. 2, 18, 20
-
[17]
Multimodal visual-tactile representation learning through self-supervised contrastive pre-training
Vedant Dave, Fotios Lygerakis, and Elmar Rueckert. Multimodal visual-tactile representation learning through self-supervised contrastive pre-training. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 8013–8020. IEEE, 2024. 2
work page 2024
-
[18]
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021. 2, 4, 5, 14
work page 2021
-
[19]
Using 3d mice to control robot manipulators
Varad Dhat, Nick Walker, and Maya Cakmak. Using 3d mice to control robot manipulators. InProceedings of the 2024 ACM/IEEE International Conference on Human- Robot Interaction, pages 896–900, 2024. 2
work page 2024
-
[20]
Bunny-visionpro: Real-time bimanual dexterous teleop- eration for imitation learning
Runyu Ding, Yuzhe Qin, Jiyue Zhu, Chengzhe Jia, Shiqi Yang, Ruihan Yang, Xiaojuan Qi, and Xiaolong Wang. Bunny-visionpro: Real-time bimanual dexterous teleop- eration for imitation learning. In2025 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), pages 12248–12255. IEEE, 2025. 2, 18, 19
work page 2025
-
[21]
Zihao Ding, Guodong Chen, Zhenhua Wang, and Lin- ing Sun. Adaptive visual–tactile fusion recognition for robotic operation of multi-material system.Frontiers in Neurorobotics, 17:1181383, 2023. 2
work page 2023
-
[22]
Maximilian Du and Shuran Song. Dynaguide: Steering diffusion polices with active dynamic guidance.arXiv preprint arXiv:2506.13922, 2025. 2, 3, 4, 5, 22, 25, 28
-
[23]
On the guidance of flow matching.arXiv preprint arXiv:2502.02150, 2025
Ruiqi Feng, Chenglei Yu, Wenhao Deng, Peiyan Hu, and Tailin Wu. On the guidance of flow matching.arXiv preprint arXiv:2502.02150, 2025. 4, 5, 14
-
[24]
https://www.flexiv.com/products/rizon,
Flexiv Rizon4. https://www.flexiv.com/products/rizon,
-
[25]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation
Zipeng Fu, Tony Z Zhao, and Chelsea Finn. Mo- bile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Vital pretraining: Visuo-tactile pretraining for tactile and non-tactile manipulation poli- cies
Abraham George, Selam Gano, Pranav Katragadda, and Amir Barati Farimani. Vital pretraining: Visuo-tactile pretraining for tactile and non-tactile manipulation poli- cies. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 258–264. IEEE, 2025. 2
work page 2025
-
[27]
Peng Hao, Chaofan Zhang, Dingzhe Li, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, and Shuo Wang. Tla: Tactile-language-action model for contact-rich manipu- lation.arXiv preprint arXiv:2503.08548, 2025. 2
-
[28]
Erik Helmut, Niklas Funk, Tim Schneider, Cristiana de Farias, and Jan Peters. Tactile-conditioned diffu- sion policy for force-aware robotic manipulation.arXiv preprint arXiv:2510.13324, 2025. 2, 18, 20
- [29]
-
[30]
Jialei Huang, Shuo Wang, Fanqi Lin, Yihang Hu, Chuan Wen, and Yang Gao. Tactile-vla: unlocking vision- language-action model’s physical knowledge for tactile generalization.arXiv preprint arXiv:2507.09160, 2025. 2
-
[31]
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ash- win Balakrishna, Kevin Black, Ken Conley, Grace Con- nors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.π ∗ 0.6: a vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Es- mail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025. 2, 3, 4, 6, 15, 18, 25, 28
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Aadhithya Iyer, Zhuoran Peng, Yinlong Dai, Irmak Guzey, Siddhant Haldar, Soumith Chintala, and Lerrel Pinto. Open teach: A versatile teleoperation system for robotic manipulation.arXiv preprint arXiv:2403.07870,
-
[34]
Sunshine Jiang, Xiaolin Fang, Nicholas Roy, Tom ´as Lozano-P´erez, Leslie Pack Kaelbling, and Siddharth An- cha. Streaming flow policy: Simplifying diffusion/flow- matching policies by treating action trajectories as flow trajectories.arXiv preprint arXiv:2505.21851, 2025. 2
-
[35]
Tatsuya Kamijo, Cristian C Beltran-Hernandez, and Masashi Hamaya. Learning variable compliance control from a few demonstrations for bimanual robot with haptic feedback teleoperation system. In2024 IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS), pages 12663–12670. IEEE, 2024. 2
work page 2024
-
[36]
Soft-bubble grippers for robust and perceptive manipu- lation
Naveen Kuppuswamy, Alex Alspach, Avinash Uttam- chandani, Sam Creasey, Takuya Ikeda, and Russ Tedrake. Soft-bubble grippers for robust and perceptive manipu- lation. In2020 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 9917–9924. IEEE, 2020. 2
work page 2020
-
[37]
Mike Lambeta, Po-Wei Chou, Stephen Tian, Brian Yang, Benjamin Maloon, Victoria Rose Most, Dave Stroud, Raymond Santos, Ahmad Byagowi, Gregg Kammerer, et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5 (3):3838–3845, 2020. 2
work page 2020
-
[38]
Michelle A Lee, Yuke Zhu, Krishnan Srinivasan, Parth Shah, Silvio Savarese, Li Fei-Fei, Animesh Garg, and Jeannette Bohg. Making sense of vision and touch: Self-supervised learning of multimodal representations for contact-rich tasks. In2019 International conference on robotics and automation (ICRA), pages 8943–8950. IEEE, 2019. 2
work page 2019
-
[39]
Chuanyu Li, Chaoyi Liu, Daotan Wang, Shuyu Zhang, Lusong Li, Zecui Zeng, Fangchen Liu, Jing Xu, and Rui Chen. Vitamin-b: A reliable and efficient visuo- tactile bimanual manipulation interface.arXiv preprint arXiv:2511.05858, 2025. 2, 18, 20
-
[40]
Changyi Lin, Ziqi Lin, Shaoxiong Wang, and Huazhe Xu. Dtact: A vision-based tactile sensor that measures high- resolution 3d geometry directly from darkness.arXiv preprint arXiv:2209.13916, 2022. 2
-
[41]
Changyi Lin, Han Zhang, Jikai Xu, Lei Wu, and Huazhe Xu. 9dtact: A compact vision-based tactile sensor for accurate 3d shape reconstruction and generalizable 6d force estimation.IEEE Robotics and Automation Letters, 9(2):923–930, 2023. 2
work page 2023
-
[42]
Fangchen Liu, Chuanyu Li, Yihua Qin, Jing Xu, Pieter Abbeel, and Rui Chen. Vitamin: Learning contact- rich tasks through robot-free visuo-tactile manipulation interface.arXiv preprint arXiv:2504.06156, 2025. 2, 18, 20
-
[43]
Kehui Liu, Zhongjie Jia, Yang Li, Pengan Chen, Song Liu, Xin Liu, Pingrui Zhang, Haoming Song, Xinyi Ye, Nieqing Cao, et al. Fastumi-100k: Advancing data-driven robotic manipulation with a large-scale umi-style dataset. arXiv preprint arXiv:2510.08022, 2025. 2
-
[44]
CDP: Towards Robust Autoregressive Visuomotor Policy Learning via Causal Diffusion, August 2025
Jiahua Ma, Yiran Qin, Yixiong Li, Xuanqi Liao, Yulan Guo, and Ruimao Zhang. Cdp: Towards robust autore- gressive visuomotor policy learning via causal diffusion. arXiv preprint arXiv:2506.14769, 2025. 1, 2
-
[45]
HKU MMLab. A live-stream robotic teamwork for clothing manipulation from zero to hero.HKU MMLab Research Blog, 2025. https://mmlab.hk/research/kai0. 1
work page 2025
-
[46]
Robotwin: Dual-arm robot benchmark with generative digital twins (early version)
Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. Robotwin: Dual-arm robot benchmark with generative digital twins (early version). InEuropean Conference on Computer Vision, pages 264–273. Springer, 2024. 2
work page 2024
-
[47]
Yiran Qin, Li Kang, Xiufeng Song, Zhenfei Yin, Xiaohong Liu, Xihui Liu, Ruimao Zhang, and Lei Bai. Robofactory: Exploring embodied agent collab- oration with compositional constraints.arXiv preprint arXiv:2503.16408, 2025. 1, 25, 28
-
[48]
Yuzhe Qin, Wei Yang, Binghao Huang, Karl Van Wyk, Hao Su, Xiaolong Wang, Yu-Wei Chao, and Dieter Fox. Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system.arXiv preprint arXiv:2307.04577, 2023. 2
-
[49]
Mc-tac: Mod- ular camera-based tactile sensor for robot gripper
Jieji Ren, Jiang Zou, and Guoying Gu. Mc-tac: Mod- ular camera-based tactile sensor for robot gripper. In International Conference on Intelligent Robotics and Applications, pages 169–179. Springer, 2023. 2
work page 2023
-
[50]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Ca- puano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, An- dres Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Zhanyi Sun and Shuran Song. Latent policy bar- rier: Learning robust visuomotor policies by staying in- distribution.arXiv preprint arXiv:2508.05941, 2025. 2, 3, 4, 5, 6, 25, 28
-
[52]
Sudharshan Suresh, Haozhi Qi, Tingfan Wu, Taosha Fan, Luis Pineda, Mike Lambeta, Jitendra Malik, Mrinal Kalakrishnan, Roberto Calandra, Michael Kaess, et al. Neuralfeels with neural fields: Visuotactile perception for in-hand manipulation.Science Robotics, 9(96):eadl0628,
-
[53]
Ian H Taylor, Siyuan Dong, and Alberto Rodriguez. Gel- slim 3.0: High-resolution measurement of shape, force and slip in a compact tactile-sensing finger. In2022 International Conference on Robotics and Automation (ICRA), pages 10781–10787. IEEE, 2022. 2
work page 2022
-
[54]
https://www.vive.com/hk/accessory/ tracker3, 2025
Vive Tracker. https://www.vive.com/hk/accessory/ tracker3, 2025. 2
work page 2025
-
[55]
Inference-time policy steering through human interactions
Yanwei Wang, Lirui Wang, Yilun Du, Balakumar Sun- daralingam, Xuning Yang, Yu-Wei Chao, Claudia P ´erez- D’Arpino, Dieter Fox, and Julie Shah. Inference-time policy steering through human interactions. In2025 IEEE International Conference on Robotics and Automa- tion (ICRA), pages 15626–15633. IEEE, 2025. 2, 4
work page 2025
-
[56]
Ziye Wang, Li Kang, Yiran Qin, Jiahua Ma, Zhanglin Peng, Lei Bai, and Ruimao Zhang. Gaudp: Rein- venting multi-agent collaboration through gaussian- image synergy in diffusion policies.arXiv preprint arXiv:2511.00998, 2025. 1, 2
-
[57]
Lai Wei, Jiahua Ma, Yibo Hu, and Ruimao Zhang. Ensuring force safety in vision-guided robotic manip- ulation via implicit tactile calibration.arXiv preprint arXiv:2412.10349, 2024. 1, 6, 17
-
[58]
Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, Yaxin Peng, Chaomin Shen, et al. Diffusion-vla: General- izable and interpretable robot foundation model via self- generated reasoning.arXiv preprint arXiv:2412.03293,
-
[59]
Freetacman: Robot-free visuo-tactile data col- lection system for contact-rich manipulation,
Longyan Wu, Checheng Yu, Jieji Ren, Li Chen, Yufei Jiang, Ran Huang, Guoying Gu, and Hongyang Li. Freetacman: Robot-free visuo-tactile data collection sys- tem for contact-rich manipulation.arXiv preprint arXiv:2506.01941, 2025. 2, 18, 20
-
[60]
Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators
Philipp Wu, Yide Shentu, Zhongke Yi, Xingyu Lin, and Pieter Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators. In2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 12156–12163. IEEE, 2024. 2, 18, 19
work page 2024
-
[61]
https://www.xenserobotics.com/product/367/ detail/9, 2025
Xense. https://www.xenserobotics.com/product/367/ detail/9, 2025. 2
work page 2025
-
[62]
https://xensedoc.readthedocs.io/en/latest/ XenseSDK/XenseSDK.html, 2025
Xense SDK. https://xensedoc.readthedocs.io/en/latest/ XenseSDK/XenseSDK.html, 2025. 2, 3, 25
work page 2025
-
[63]
Mengda Xu, Han Zhang, Yifan Hou, Zhenjia Xu, Linxi Fan, Manuela Veloso, and Shuran Song. Dexumi: Using human hand as the universal manipulation in- terface for dexterous manipulation.arXiv preprint arXiv:2505.21864, 2025. 2
-
[64]
exumi: Extensible robot teaching system with action-aware task-agnostic tactile representation
Yue Xu, Litao Wei, Pengyu An, Qingyu Zhang, and Yong-Lu Li. exumi: Extensible robot teaching system with action-aware task-agnostic tactile representation. arXiv preprint arXiv:2509.14688, 2025. 2, 18, 20
-
[65]
Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation,
Han Xue, Jieji Ren, Wendi Chen, Gu Zhang, Yuan Fang, Guoying Gu, Huazhe Xu, and Cewu Lu. Re- active diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation.arXiv preprint arXiv:2503.02881, 2025. 1, 2, 3, 6, 7, 17, 18, 19, 25, 28
-
[66]
Touch and go: Learning from human-collected vision and touch,
Fengyu Yang, Chenyang Ma, Jiacheng Zhang, Jing Zhu, Wenzhen Yuan, and Andrew Owens. Touch and go: Learning from human-collected vision and touch.arXiv preprint arXiv:2211.12498, 2022. 2
-
[67]
Demonstrating the octopi- 1.5 visual-tactile-language model,
Samson Yu, Kelvin Lin, and Harold Soh. Demonstrat- ing the octopi-1.5 visual-tactile-language model.arXiv preprint arXiv:2507.09985, 2025. 2
-
[68]
Wenzhen Yuan, Siyuan Dong, and Edward H Adelson. Gelsight: High-resolution robot tactile sensors for esti- mating geometry and force.Sensors, 17(12):2762, 2017. 2
work page 2017
-
[69]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations
Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Vtla: Vision- tactile-language-action model with preference learning for insertion manipulation,
Chaofan Zhang, Peng Hao, Xiaoge Cao, Xiaoshuai Hao, Shaowei Cui, and Shuo Wang. Vtla: Vision-tactile- language-action model with preference learning for in- sertion manipulation.arXiv preprint arXiv:2505.09577,
-
[71]
Qinglun Zhang, Zhen Liu, Haoqiang Fan, Guanghui Liu, Bing Zeng, and Shuaicheng Liu. Flowpolicy: Enabling fast and robust 3d flow-based policy via consistency flow matching for robot manipulation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025. 2
work page 2025
-
[72]
arXiv preprint arXiv:2505.23614 , year =
Xiangcheng Zhang, Haowei Lin, Haotian Ye, James Zou, Jianzhu Ma, Yitao Liang, and Yilun Du. Inference- time scaling of diffusion models through classical search. arXiv preprint arXiv:2505.23614, 2025. 2
-
[73]
Yazhan Zhang, Zicheng Kan, Yang Yang, Yu Alexander Tse, and Michael Yu Wang. Effective estimation of contact force and torque for vision-based tactile sensors with helmholtz–hodge decomposition.IEEE Robotics and Automation Letters, 4(4):4094–4101, 2019. 2
work page 2019
-
[74]
Can Zhao, Jin Liu, and Daolin Ma. ifem2.0: Dense 3d contact force field reconstruction and assessment for vision-based tactile sensors.IEEE Transactions on Robotics, 2024. 2
work page 2024
-
[75]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705,
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Fastumi: A scalable and hardware-independent universal manip- ulation interface with dataset
Zhaxizhuom Zhaxizhuoma, Kehui Liu, Chuyue Guan, Zhongjie Jia, Ziniu Wu, Xin Liu, Tianyu Wang, Shuai Liang, Pengan CHEN, Pingrui Zhang, et al. Fastumi: A scalable and hardware-independent universal manip- ulation interface with dataset. InConference on Robot Learning, pages 3069–3093. PMLR, 2025. 2, 3, 18, 20, 28
work page 2025
-
[77]
Guided flows for generative modeling and decision making.arXiv preprint arXiv:2311.13443, 2023
Qinqing Zheng, Matt Le, Neta Shaul, Yaron Lipman, Aditya Grover, and Ricky TQ Chen. Guided flows for generative modeling and decision making.arXiv preprint arXiv:2311.13443, 2023. 4, 5, 14
-
[78]
DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. Dino-wm: World models on pre-trained vi- sual features enable zero-shot planning.arXiv preprint arXiv:2411.04983, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[79]
Xinyue Zhu, Binghao Huang, and Yunzhu Li. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper.arXiv preprint arXiv:2507.15062, 2025. 2, 18, 20 APPENDIX A Classifier Guidance for Flow Matching (Proof of Proposition 1) . . . . . . . . . . . . . . . . . . . . . . 14 B Steering Hyperparameter Investigation . . . . . . ....
-
[80]
Ablation Study on Steering Hyperparameter:To select TouchGuide steering hyperparameters, we conducted extensive experiments on the Chip Handover task usingπ 0.5 [32] as the base policy. We primarily varied two hyperparameters (i.e., guidance scaleηand guidance stepsK TouchGuide, for the detailed hyperparameter implementation, see Alg. 1) by sweeping one w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.