MemGraphRAG: Memory-based Multi-Agent System for Graph Retrieval-Augmented Generation
Pith reviewed 2026-06-28 18:18 UTC · model grok-4.3
The pith
MemGraphRAG uses a shared-memory multi-agent system to build consistent and connected knowledge graphs for improved retrieval-augmented generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
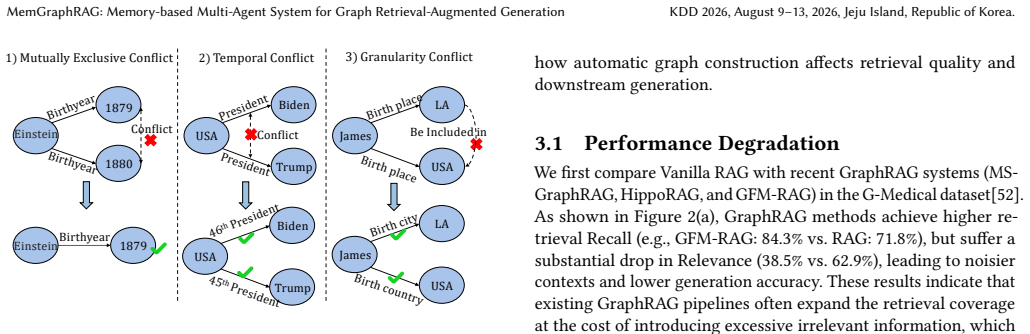
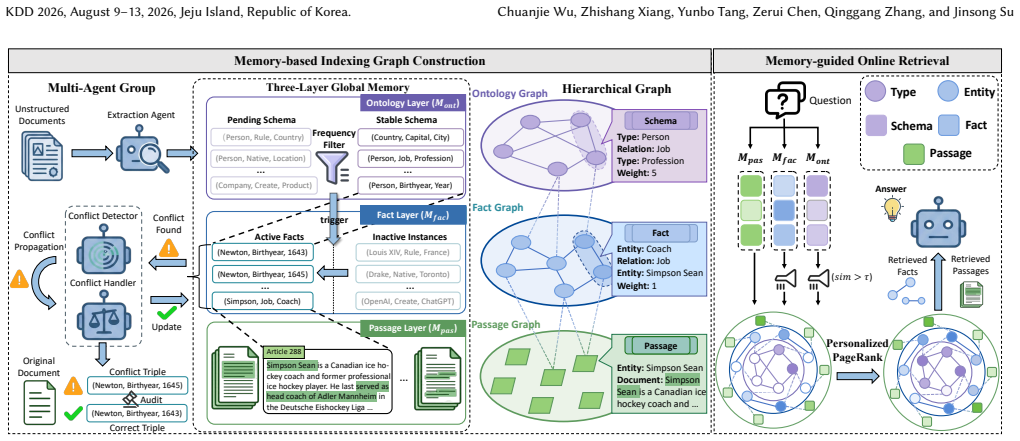
MemGraphRAG introduces a memory-based multi-agent system in which a collaborative society of agents, supported by shared memory that supplies unified global context, dynamically resolves logical conflicts and maintains structural connectivity during graph construction from large unstructured corpora.
What carries the argument
The shared memory that provides a unified global context to the society of agents throughout the extraction process, enabling conflict resolution and connectivity maintenance.
If this is right
- Graphs produced are thematically consistent without logical conflicts.
- Structural connectivity is preserved across the entire corpus.
- Memory-aware hierarchical retrieval can leverage the improved graph structure.
- Retrieval performance on complex queries exceeds that of state-of-the-art GraphRAG methods at comparable efficiency.
Where Pith is reading between the lines
- This suggests that global context during extraction is more important than local optimization for graph quality.
- The multi-agent setup could be tested on domains with highly interconnected information, such as scientific literature.
- Shared memory might allow fewer agents to achieve similar consistency if memory access is optimized.
Load-bearing premise
The shared-memory multi-agent society can reliably detect and resolve logical conflicts and maintain structural connectivity across an entire corpus during graph extraction.
What would settle it
A test on a large benchmark corpus where the graphs from MemGraphRAG still show unresolved logical conflicts or fragmentation, resulting in retrieval performance no better than baselines.
Figures




read the original abstract
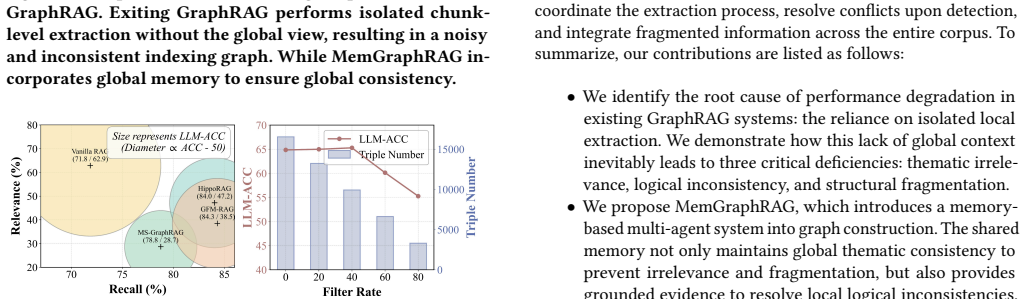
Retrieval-Augmented Generation (RAG) has become an essential method for mitigating hallucinations in Large Language Models (LLMs) by leveraging external knowledge. Although effective for simple queries, traditional RAG struggles with large-scale, unstructured corpora where information is highly fragmented. Graph-based RAG (GraphRAG) incorporates knowledge graphs to capture structural relationships, enabling more comprehensive retrieval for complex reasoning. However, existing GraphRAG methods rely on isolated, fragment-level extraction for graph construction, lacking a global perspective on the whole corpus. As a result, these methods frequently lead to thematically inconsistent, logically conflicting, and structurally fragmented graphs that degrade retrieval performance. In this paper, we propose MemGraphRAG, a novel framework that introduces a memory-based multi-agent system to ensure high-quality graph construction. Specifically, MemGraphRAG employs a collaborative society of agents supported by shared memory, which provides a unified global context throughout the extraction process. This mechanism allows agents to dynamically resolve logical conflicts and maintain structural connectivity throughout the corpus. Furthermore, we propose a memory-aware hierarchical retrieval algorithm tailored for the constructed graph. Extensive experiments on multiple benchmarks demonstrate that MemGraphRAG outperforms the state-of-the-art baseline models with comparable efficiency. Our code is available at https://github.com/XMUDeepLIT/MemGraphRAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MemGraphRAG, a memory-based multi-agent framework for GraphRAG. It employs a collaborative society of agents with shared memory to supply unified global context during knowledge-graph extraction from large unstructured corpora, enabling dynamic resolution of logical conflicts and maintenance of structural connectivity. This is contrasted with prior fragment-level extraction methods that produce inconsistent and fragmented graphs. The work also introduces a memory-aware hierarchical retrieval algorithm. Experiments on multiple benchmarks are reported to show outperformance over state-of-the-art baselines at comparable efficiency; code is released.
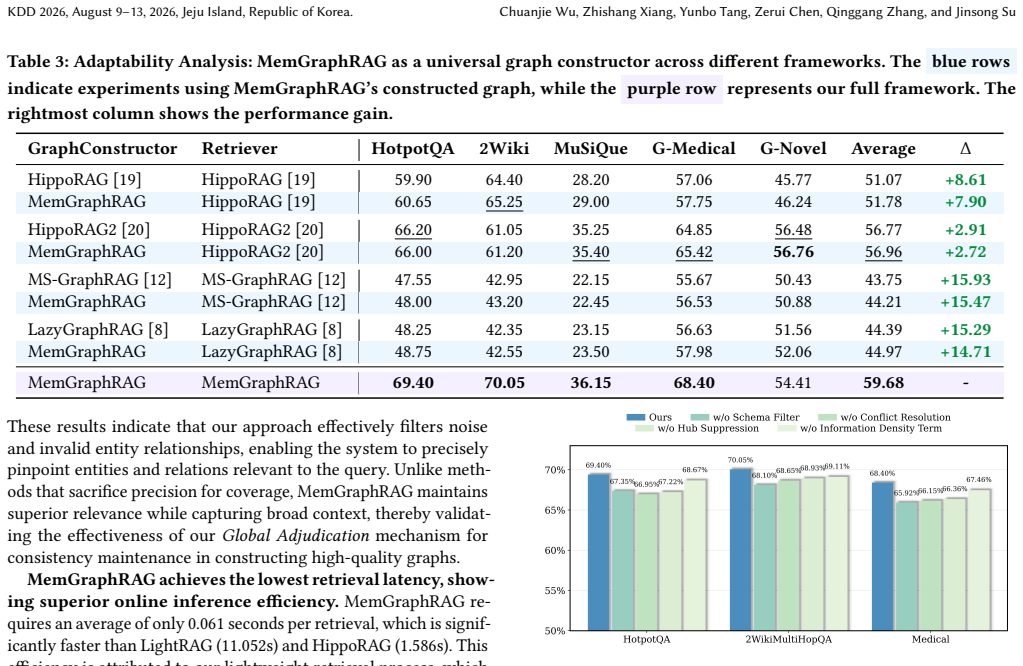
Significance. If the shared-memory multi-agent mechanism can be shown to be the source of improved graph quality and retrieval performance, the approach would address a recognized limitation in existing GraphRAG pipelines for complex reasoning over fragmented corpora. The public release of code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract and §3] Abstract and §3 (Method): The central claim that shared memory 'allows agents to dynamically resolve logical conflicts and maintain structural connectivity throughout the corpus' is load-bearing for attributing performance gains to the proposed mechanism rather than to hierarchical retrieval alone, yet no description of the conflict-detection algorithm, resolution protocol, or memory-update rules is supplied.
- [§5] §5 (Experiments): No metrics are reported that directly test the claimed mechanism, such as conflict counts before/after resolution, resolution success rate, inter-fragment consistency score, or a graph-fragmentation index comparing MemGraphRAG graphs to baselines; without these, it is impossible to confirm that the shared-memory component functions as asserted or drives the reported gains.
minor comments (2)
- Table captions and axis labels in the experimental figures should explicitly state the evaluation metrics and dataset names for immediate readability.
- The related-work section would benefit from a short paragraph contrasting MemGraphRAG specifically with other multi-agent or memory-augmented GraphRAG variants that have appeared since 2024.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for improving the description of our proposed mechanism and the evidence supporting its contribution. We address each major comment below and commit to revisions that will strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Method): The central claim that shared memory 'allows agents to dynamically resolve logical conflicts and maintain structural connectivity throughout the corpus' is load-bearing for attributing performance gains to the proposed mechanism rather than to hierarchical retrieval alone, yet no description of the conflict-detection algorithm, resolution protocol, or memory-update rules is supplied.
Authors: We agree that the manuscript presents the shared-memory multi-agent system at a conceptual level in §3 without supplying the low-level algorithmic specifications. This limits the ability to fully attribute gains to the mechanism. In the revised manuscript we will add a new subsection to §3 that formally specifies the conflict-detection algorithm (semantic similarity plus LLM-based entailment verification), the resolution protocol (including agent querying of shared memory and arbitration rules), and the memory-update rules (with consistency checks and versioning). Pseudocode and a worked example from one of the corpora will be included. revision: yes
-
Referee: [§5] §5 (Experiments): No metrics are reported that directly test the claimed mechanism, such as conflict counts before/after resolution, resolution success rate, inter-fragment consistency score, or a graph-fragmentation index comparing MemGraphRAG graphs to baselines; without these, it is impossible to confirm that the shared-memory component functions as asserted or drives the reported gains.
Authors: We acknowledge that the current experimental section reports only end-to-end task performance and does not include direct diagnostics of the shared-memory mechanism. This is a fair observation. In the revision we will add a dedicated analysis subsection to §5 that reports conflict counts before and after resolution, resolution success rate, an inter-fragment consistency score, and a graph-fragmentation index, computed on the graphs produced by MemGraphRAG versus the baselines. These will be obtained via post-hoc analysis of the constructed knowledge graphs on the existing benchmark corpora. revision: yes
Circularity Check
No circularity: empirical framework with experimental validation
full rationale
The paper proposes MemGraphRAG as a practical multi-agent system with shared memory for graph construction, claiming empirical outperformance on benchmarks. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing steps exist in the provided text. The central mechanism is a design choice tested via experiments rather than reduced to its own inputs by construction. The result is self-contained as an engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International Conference on Learning Representations (ICLR)
2023
-
[2]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Ruther- ford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bog- dan Damoc, Aidan Clark, et al. 2022. Improving language models by retrieving from trillions of tokens. InInternational Conference on Machine Learning (ICML)
2022
-
[3]
ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Yijie Zhou, Chenzheng Zhu, Haofen Wang, Jeff Z. Pan, Wen Zhang, Huajun Chen, Fan Yang, Zenan Zhou, and Weipeng Chen. 2025. ReSearch: Learning to Reason with Search for LLMs via Reinforcement Learning. arXiv:2503.19470 [cs.AI] https://arxiv.org/ abs/2503.19470
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Shengyuan Chen, Zheng Yuan, Qinggang Zhang, Wen Hua, Jiannong Cao, and Xiao Huang. 2025. Neuro-Symbolic Entity Alignment via Variational Inference. The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[5]
Shengyuan Chen, Qinggang Zhang, Junnan Dong, Wen Hua, Qing Li, and Xiao Huang. 2024. Entity alignment with noisy annotations from large language models.The Thirty-Eighth Annual Conference on Neural Information Processing Systems(2024)
2024
- [6]
-
[7]
CircleMind-AI. 2024. FastGraphRAG: High-speed graph-based retrieval- augmented generation.CircleMind-AI Blog(2024)
2024
-
[8]
Jonathan Larson Darren Edge, Ha Trinh. 2024. LazyGraphRAG: Setting a new standard for quality and cost.Microsoft Blog(2024)
2024
- [9]
- [10]
-
[11]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[12]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [13]
- [14]
-
[15]
Linfeng Gao, Baolong Bi, Zheng Yuan, Le Wang, Zerui Chen, Zhimin Wei, Shenghua Liu, Qinggang Zhang, and Jinsong Su. 2025. Probing Latent Knowl- edge Conflict for Faithful Retrieval-Augmented Generation.arXiv preprint arXiv:2510.12460(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Zirui Guo, Lianghao Xia, Yanhua Yu, Tu Ao, and Chao Huang. 2024. LightRAG: Simple and Fast Retrieval-Augmented Generation.arXiv preprint arXiv:2410.05779 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
-
[19]
Bernal Jiménez Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su
-
[20]
InAdvances in Neural Information Processing Systems (NeurIPS)
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Lan- guage Models. InAdvances in Neural Information Processing Systems (NeurIPS)
-
[21]
Bernal Jiménez Gutiérrez, Yiheng Shu, Weijian Qi, Sizhe Zhou, and Yu Su. 2025. From rag to memory: Non-parametric continual learning for large language models.arXiv preprint arXiv:2502.14802(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-Augmented Language Model Pre-Training. arXiv:2002.08909 [cs.CL] https://arxiv.org/abs/2002.08909
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [23]
-
[24]
Haoyu Han, Yu Wang, Harry Shomer, Kai Guo, Jiayuan Ding, Yongjia Lei, Ma- hantesh Halappanavar, Ryan A Rossi, Subhabrata Mukherjee, Xianfeng Tang, et al
-
[25]
Retrieval-augmented generation with graphs (graphrag).arXiv preprint arXiv:2501.00309(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh V Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. 2024. G-retriever: Retrieval-augmented KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea. Chuanjie Wu, Zhishang Xiang, Yunbo Tang, Zerui Chen, Qinggang Zhang, and Jinsong Su generation for textual graph understanding and question answe...
-
[27]
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. 2020. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.arXiv preprint arXiv:2011.01060(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [28]
-
[29]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave
-
[30]
Atlas: Few-shot learning with retrieval augmented language models.The Journal of Machine Learning Research (JMLR)(2023)
2023
-
[31]
Houcheng Jiang, Junfeng Fang, Ningyu Zhang, Guojun Ma, Mingyang Wan, Xiang Wang, Xiangnan He, and Tat-seng Chua. 2025. AnyEdit: Edit Any Knowledge Encoded in Language Models.ICML(2025)
2025
-
[32]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. InEmpirical Methods in Natural Language Processing (EMNLP)
2023
-
[33]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv:2503.09516 [cs.CL] https://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al
-
[35]
In Advances in Neural Information Processing Systems (NeurIPS)
Retrieval-augmented generation for knowledge-intensive nlp tasks. In Advances in Neural Information Processing Systems (NeurIPS)
-
[36]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025. Search-o1: Agentic Search-Enhanced Large Reasoning Models. arXiv:2501.05366 [cs.AI] https://arxiv.org/abs/2501.05366
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Yujie Lin, Kunquan Li, YiXuan Liao, Xiaoxin Chen, and Jinsong Su. 2026. Bi- directional Bias Attribution: Debiasing Large Language Models without Modify- ing Prompts. InThe Fourteenth International Conference on Learning Representa- tions. https://openreview.net/forum?id=mUTN9VIaSy
2026
-
[39]
Yujie Lin, Chengyi Yang, Zhishang Xiang, Yiping Song, and Jinsong Su. 2026. ZeroUnlearn: Few-Shot Knowledge Unlearning in Large Language Models. arXiv:2605.18879 [cs.LG] https://arxiv.org/abs/2605.18879
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
LINHAO LUO, Yuan-Fang Li, Reza Haf, and Shirui Pan. 2024. Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning. InThe Twelfth International Conference on Learning Representations
2024
- [41]
-
[42]
Das, and Chengqi Zhang
Renqiang Luo, Huafei Huang, Shuo Yu, Fengqi Yu, Feng Xia, Sajal K. Das, and Chengqi Zhang. 2026. Utility-Preserving Federated Graph Learning with Dual- Perspective Fairness.IEEE Transactions on Pattern Analysis and Machine Intelli- gence(2026)
2026
- [43]
-
[44]
OpenAI. 2023. GPT-4 Technical Report.OpenAI Blog(2023)
2023
-
[45]
Tyler Thomas Procko and Omar Ochoa. 2024. Graph retrieval-augmented genera- tion for large language models: A survey. InConference on AI, Science, Engineering, and Technology (AIxSET)
2024
- [46]
-
[47]
Meng Qu and Jian Tang. 2019. Probabilistic Logic Neural Networks for Reason- ing. InAdvances in Neural Information Processing Systems (NeurIPS). Vancouver, Canada, 7710–7720
2019
-
[48]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InInternational Conference on Learning Representations (ICLR)
2024
- [49]
-
[50]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. In International Conference on Learning Representations (ICLR)
2024
-
[52]
Transactions of the Association for Computational Linguistics10 (2022), 539–554
MuSiQue: Multi-hop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics10 (2022), 539–554
2022
-
[53]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[54]
InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers)
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers). 10014–10037
-
[55]
Hong Ting Tsang, Jiaxin Bai, Haoyu Huang, Qiao Xiao, Tianshi Zheng, Baixuan Xu, Shujie Liu, and Yangqiu Song. 2025. AutoGraph-R1: End-to-End Reinforce- ment Learning for Knowledge Graph Construction. arXiv:2510.15339 [cs.CL] https://arxiv.org/abs/2510.15339
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Shu Wang, Yixiang Fang, Yingli Zhou, Xilin Liu, and Yuchi Ma. 2025. ArchRAG: Attributed Community-based Hierarchical Retrieval-Augmented Generation. arXiv preprint arXiv:2502.09891(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Yu Wang, Nedim Lipka, Ryan A Rossi, Alexa Siu, Ruiyi Zhang, and Tyler Derr
-
[58]
In Conference on Artificial Intelligence (AAAI)
Knowledge graph prompting for multi-document question answering. In Conference on Artificial Intelligence (AAAI)
- [59]
-
[60]
Zhishang Xiang, Chengyi Yang, Zerui Chen, Zhimin Wei, Yunbo Tang, Zongpei Teng, Zexi Peng, Zongxia Li, Chengsong Huang, Yicheng He, et al . 2026. A Systematic Survey of Self-Evolving Agents: From Model-Centric to Environment- Driven Co-Evolution. (2026)
2026
- [61]
- [62]
- [63]
- [64]
-
[65]
Diji Yang, Jinmeng Rao, Kezhen Chen, Xiaoyuan Guo, Yawen Zhang, Jie Yang, and Yi Zhang. 2024. Im-rag: Multi-round retrieval-augmented generation through learning inner monologues. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. 730–740
2024
-
[66]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A dataset for di- verse, explainable multi-hop question answering. InEmpirical Methods in Natural Language Processing (EMNLP)
2018
-
[67]
Zheng Yuan, Hao Chen, Zijin Hong, Qinggang Zhang, Feiran Huang, Qing Li, and Xiao Huang. 2025. Knapsack optimization-based schema linking for llm-based Text-to-SQL generation.arXiv preprint arXiv:2502.12911(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [68]
- [69]
- [70]
- [71]
-
[72]
Baolin Zheng, Guanlin Chen, Hongqiong Zhong, Qingyang Teng, Yingshui Tan, Zhendong Liu, Weixun Wang, Jiaheng Liu, Jian Yang, Huiyun Jing, et al. 2025. USB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models.arXiv preprint arXiv:2505.23793(2025)
- [73]
-
[74]
Chulun Zhou, Qiujing Wang, Mo Yu, Xiaoqian Yue, Rui Lu, Jiangnan Li, Yifan Zhou, Shunchi Zhang, Jie Zhou, and Wai Lam. 2025. The essence of contex- tual understanding in theory of mind: A study on question answering with story characters. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 22612–22631
2025
-
[75]
Chulun Zhou, Chunkang Zhang, Guoxin Yu, Fandong Meng, Jie Zhou, Wai Lam, and Mo Yu. 2025. Improving Multi-step RAG with Hypergraph-based Memory for Long-Context Complex Relational Modeling.arXiv preprint arXiv:2512.23959 (2025). MemGraphRAG: Memory-based Multi-Agent System for Graph Retrieval-Augmented Generation KDD 2026, August 9–13, 2026, Jeju Island, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
Yingli Zhou, Yaodong Su, Youran Sun, Shu Wang, Taotao Wang, Runyuan He, Yongwei Zhang, Sicong Liang, Xilin Liu, Yuchi Ma, et al. 2025. In-depth Analysis of Graph-based RAG in a Unified Framework.arXiv preprint arXiv:2503.04338 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Luyao Zhuang, Shengyuan Chen, Yilin Xiao, Huachi Zhou, Yujing Zhang, Hao Chen, Qinggang Zhang, and Xiao Huang. 2025. LinearRAG: Linear Graph Retrieval Augmented Generation on Large-scale Corpora.arXiv preprint arXiv:2510.10114(2025). A Additional Experiments A.1 Ablation on Backbone LLMs To further evaluate the universality and robustness of MemGraphRAG, ...
-
[78]
Newton was born in 1645
Input Corpus Doc A:“Newton was born in 1645. ” Doc B:“Isaac Newton, born 1643... ” Same Corpus: Contains mutually exclusive facts due to source errors or extraction noise
-
[79]
Global Adjudication: 𝐴𝑑𝑒𝑡 detects Conflict:𝑇 1 ⊥𝑇 2 →𝐴 𝑟𝑒𝑠 checks Evidence (𝑀𝑝𝑎𝑠 ) →Update: Keep𝑇 2, Discard𝑇 1
Graph Construction Isolated Extraction: 𝑇1 :(𝑁 𝑒𝑤𝑡𝑜𝑛, 𝑏𝑜𝑟𝑛_𝑖𝑛,1645) 𝑇2 :(𝑁 𝑒𝑤𝑡𝑜𝑛, 𝑏𝑜𝑟𝑛_𝑖𝑛,1643) →Both edges added to Graph𝐺. Global Adjudication: 𝐴𝑑𝑒𝑡 detects Conflict:𝑇 1 ⊥𝑇 2 →𝐴 𝑟𝑒𝑠 checks Evidence (𝑀𝑝𝑎𝑠 ) →Update: Keep𝑇 2, Discard𝑇 1
-
[80]
When was Isaac Newton born?
Retrieval Query Q: “When was Isaac Newton born?”
-
[81]
Consistent Path: Query triggers verified node:{1643} →Trace back to𝑀 𝑝𝑎𝑠 evidence
Retrieval Process Noisy Activation: Query triggers both nodes:{1645,1643} →Retriever fetches conflicting context. Consistent Path: Query triggers verified node:{1643} →Trace back to𝑀 𝑝𝑎𝑠 evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.