Cascading Hallucination in Agentic RAG: The CHARM Framework for Detection and Mitigation
Pith reviewed 2026-06-28 06:30 UTC · model grok-4.3
The pith
The CHARM framework detects cascading hallucinations in multi-step agentic RAG systems by adding stage-level verification and consistency tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cascading hallucination is a distinct failure mode in agentic RAG where errors at early stages propagate and amplify across successive reasoning steps. CHARM provides four components—stage-level fact verification, cross-stage consistency tracking, confidence propagation monitoring, and cascade resolution triggering—that detect and interrupt this propagation without replacing the underlying pipeline, yielding an 89.4% cascade detection rate and 82.1% error propagation reduction.
What carries the argument
CHARM, an architectural framework consisting of stage-level fact verification, cross-stage consistency tracking, confidence propagation monitoring, and cascade resolution triggering that operates alongside standard agentic RAG pipelines.
If this is right
- Stage-level fact verification identifies errors before they reach later reasoning steps.
- Cross-stage consistency tracking reveals when intermediate outputs conflict with prior steps.
- Confidence propagation monitoring flags decreasing reliability across the pipeline.
- Cascade resolution triggering interrupts error spread before the final output is generated.
- The framework integrates with existing human-in-the-loop oversight for production use.
Where Pith is reading between the lines
- Similar stage-wise checks could be adapted to other multi-step agent architectures like planning or tool-use systems.
- Evaluating CHARM on real-world production pipelines rather than only benchmarks would test its practical robustness.
- The taxonomy of cascade patterns may help classify failures in related systems such as chain-of-thought reasoning.
- Reducing error propagation this way could improve reliability in safety-critical applications of agentic AI.
Load-bearing premise
Stage-level fact verification and cross-stage consistency tracking can be implemented accurately on retrieved content without introducing new errors or requiring changes to the underlying agentic pipeline architecture.
What would settle it
Running CHARM on a multi-hop QA dataset where a known early-stage hallucination propagates to the final answer but CHARM reports no cascade would falsify the detection effectiveness.
Figures

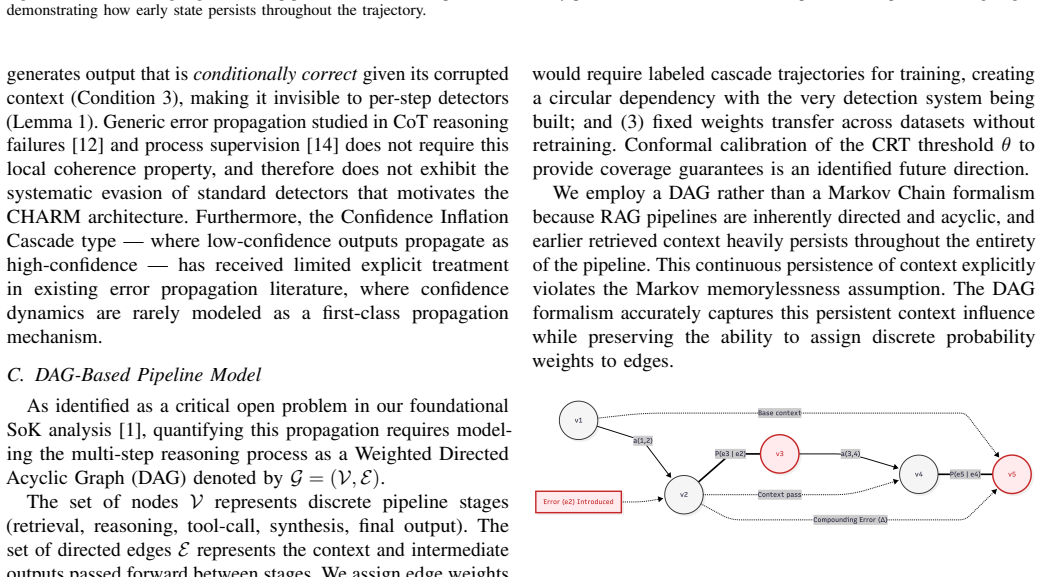

read the original abstract
Multi-step agentic retrieval-augmented generation (RAG) pipelines have demonstrated significant capability for complex reasoning tasks, yet remain vulnerable to a class of failure that existing hallucination detection mechanisms systematically miss: cascading hallucination, where errors introduced at early pipeline stages propagate and amplify across successive reasoning steps, producing confident but factually incorrect final outputs. To address this vulnerability, we formalize cascading hallucination as a distinct failure mode in agentic RAG systems, present a four-type taxonomy of cascade patterns, and introduce CHARM (Cascading Hallucination Aware Resolution and Mitigation), an architectural framework for detecting and interrupting error propagation in multi-step reasoning pipelines. CHARM comprises four components - stage-level fact verification, cross-stage consistency tracking, confidence propagation monitoring, and cascade resolution triggering - that operate alongside standard agentic RAG pipelines without requiring architectural replacement. We evaluate CHARM on HotpotQA, MuSiQue, 2WikiMultiHopQA, and a custom adversarial dataset across LangChain agentic pipeline configurations, achieving an 89.4% cascade detection rate with a 5.3% false positive rate and 215 ms +/- 18 ms average latency overhead per stage, achieving an error propagation reduction of 82.1%, compared to 18.5% for output-level detectors. Component ablations confirm that each detection module contributes meaningfully to overall cascade coverage. CHARM integrates with human-in-the-loop oversight frameworks to provide a complete reliability and governance stack for production agentic AI deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript formalizes 'cascading hallucination' as a distinct failure mode in multi-step agentic RAG pipelines where early-stage errors propagate and amplify across reasoning steps. It presents a four-type taxonomy of cascade patterns and introduces the CHARM framework with four components (stage-level fact verification, cross-stage consistency tracking, confidence propagation monitoring, and cascade resolution triggering) that can be added to existing pipelines without replacement. Evaluation on HotpotQA, MuSiQue, 2WikiMultiHopQA, and a custom adversarial dataset across LangChain configurations reports 89.4% cascade detection rate, 5.3% false positive rate, 215 ms +/- 18 ms latency overhead per stage, and 82.1% error propagation reduction (vs. 18.5% for output-level detectors), with component ablations confirming contributions; integration with human-in-the-loop oversight is also discussed.
Significance. If the empirical results hold and the verification components prove reliable on multi-hop content, this would represent a practical contribution to robustness in agentic RAG by targeting error propagation specifically, with low overhead and compatibility with existing systems and governance frameworks.
major comments (1)
- [Evaluation (as described in abstract)] Evaluation (abstract): The central claims of 89.4% cascade detection and 82.1% error propagation reduction rest on the untested premise that stage-level fact verification and cross-stage consistency tracking achieve high accuracy on the same retrieved passages used by the agentic pipeline. On HotpotQA and MuSiQue, retrieved content often contains partial, conflicting, or ambiguous facts across hops; no independent validation, error analysis, or ablation isolating verifier accuracy is described to rule out missed cascades or spurious triggers.
minor comments (2)
- [Abstract] The custom adversarial dataset is referenced but its construction, size, adversarial strategy, and relation to the standard benchmarks are not described.
- [Abstract] Specific LangChain agentic pipeline configurations (e.g., number of stages, retrieval settings) used for the reported metrics are not detailed.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on our evaluation methodology. We address the concern point by point below.
read point-by-point responses
-
Referee: The central claims of 89.4% cascade detection and 82.1% error propagation reduction rest on the untested premise that stage-level fact verification and cross-stage consistency tracking achieve high accuracy on the same retrieved passages used by the agentic pipeline. On HotpotQA and MuSiQue, retrieved content often contains partial, conflicting, or ambiguous facts across hops; no independent validation, error analysis, or ablation isolating verifier accuracy is described to rule out missed cascades or spurious triggers.
Authors: We acknowledge that the manuscript does not include an independent validation or error analysis isolating the accuracy of the stage-level fact verifier on the retrieved passages themselves. The reported 89.4% detection rate and component ablations reflect end-to-end cascade coverage against ground-truth annotations rather than direct verifier precision/recall on ambiguous or conflicting passages. We agree this leaves open the possibility of missed cascades or spurious triggers and will add a dedicated verifier accuracy analysis (including precision/recall on HotpotQA and MuSiQue passages) plus an ablation isolating verifier performance in the revised version. revision: yes
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper introduces the CHARM framework with four components and reports empirical results (89.4% detection rate, 82.1% error reduction) on public benchmarks HotpotQA, MuSiQue, 2WikiMultiHopQA plus a custom dataset. No equations, derivations, or self-citations are shown that reduce any prediction or result to fitted inputs or self-definitions by construction. Component ablations and latency measurements are presented as direct experimental outcomes rather than tautological outputs. This is the normal case of an empirical systems paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard multi-hop QA benchmarks accurately represent cascading hallucination behavior in production agentic systems
invented entities (2)
-
Cascading hallucination
no independent evidence
-
CHARM framework (four components)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Mishra, S. Niroula, U. Yadav, D. Thakur, S. Gyawali, and S. Gaire, “Sok: Agentic retrieval-augmented generation (rag): Taxon- omy, architectures, evaluation, and research directions,”arXiv preprint arXiv:2603.07379, 2026
-
[2]
Artificial intelligence risk management framework: Generative ai profile (nist ai 600-1),
National Institute of Standards and Technology, “Artificial intelligence risk management framework: Generative ai profile (nist ai 600-1),” U.S. Department of Commerce, Tech. Rep., July 2024. [Online]. Available: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
2024
-
[3]
A face recognition method using deep learning to identify mask and unmask objects,
S. Mishra and H. Reza, “A face recognition method using deep learning to identify mask and unmask objects,” in2022 IEEE World AI IoT Congress (AIIoT). IEEE, 2022, pp. 091–099
2022
-
[4]
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
P. Manakul, A. Liusie, and M. J. Gales, “Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models,” arXiv preprint arXiv:2303.08896, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation,
S. Min, K. Krishna, X. Lyu, M. Lewis, W.-t. Yih, P. W. Koh, M. Iyyer, L. Zettlemoyer, and H. Hajishirzi, “Factscore: Fine-grained atomic evaluation of factual precision in long form text generation,”arXiv preprint arXiv:2305.14251, 2023
-
[6]
Ragas: Automated Evaluation of Retrieval Augmented Generation
S. Es, J. James, L. Espinosa-Anke, and S. Schockaert, “Ragas: Au- tomated evaluation of retrieval augmented generation,”arXiv preprint arXiv:2309.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
N. Shinn, F. Labash, A. Gopinath, and K. Narasimhan, “Reflexion: Language agents with verbal reinforcement learning,”arXiv preprint arXiv:2303.11366, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,” inAdvances in Neural Information Processing Systems, vol. 33, 2020, pp. 9459–9474
2020
-
[9]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, 2023
2023
-
[10]
Automatically correcting large language models: Survey and taxonomy,
L. Pan, M. Saxon, R. Connor, A. Sharma, and W. Y . Wang, “Automatically correcting large language models: Survey and taxonomy,”arXiv preprint arXiv:2308.03188, 2023
-
[11]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in Neural Information Processing Systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[12]
Faith and fate: Limits of transformers on compositionality,
N. Dziri, X. Lu, M. Sclar, X. L. Li, L. Jian, B. Y . Lin, P. West, C. Bhagavatula, R. L. Bras, J. D. Hwanget al., “Faith and fate: Limits of transformers on compositionality,”Advances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[13]
Retrieval-Augmented Generation for Large Language Models: A Survey
Y . Gao, Y . Xiong, X. Gao, K. Jia, J. Pan, Y . Bi, Y . Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,”arXiv preprint arXiv:2312.10997, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
H. Lightmanet al., “Let’s verify step by step,”arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Sentence-bert: Sentence embeddings using siamese bert-networks,
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,” inProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, 2019, pp. 3982– 3992
2019
-
[16]
Deberta: Decoding-enhanced bert with disentangled attention,
P. He, X. Liu, J. Gao, and W. Chen, “Deberta: Decoding-enhanced bert with disentangled attention,” inInternational Conference on Learning Representations, 2021
2021
-
[17]
Language Models (Mostly) Know What They Know
S. Kadavathet al., “Language models (mostly) know what they know,” arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inProceedings of the 34th International Conference on Machine Learning (ICML), 2017
2017
-
[19]
Langchain: Building applications with llms through compos- ability,
H. Chase, “Langchain: Building applications with llms through compos- ability,” https://github.com/hwchase17/langchain, 2023
2023
-
[20]
Llamaindex: A data framework for large language models,
J. Liu, “Llamaindex: A data framework for large language models,” https://github.com/jerryjliu/llama index, 2023
2023
-
[21]
Trustworthy agentic ai pipelines: Human-in-the-loop oversight architectures for secure enterprise deployment,
S. Mishra, “Trustworthy agentic ai pipelines: Human-in-the-loop oversight architectures for secure enterprise deployment,”ResearchGate preprint, 2026
2026
-
[22]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[23]
Billion-scale similarity search with GPUs,
J. Johnson, M. Douze, and H. J ´egou, “Billion-scale similarity search with GPUs,”IEEE Transactions on Big Data, 2019
2019
-
[24]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering,
Z. Yang, P. Qi, S. Zhang, Y . Bengio, W. W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2369–2380
2018
-
[25]
Musique: Multihop questions via single-hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Musique: Multihop questions via single-hop question composition,” inTransactions of the Association for Computational Linguistics, vol. 10, 2022, pp. 539– 554
2022
-
[26]
Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,
X. Ho, A.-K. D. Nguyen, S. Sugawara, and A. Aizawa, “Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps,” inProceedings of the 28th International Conference on Computational Linguistics, 2020, pp. 6609–6625
2020
-
[27]
Ignore previous prompt: Attack techniques for language models,
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models,” inNeurIPS ML Safety Workshop, 2022
2022
-
[28]
H. Kang, J. Ni, and H. Yao, “EVER: Mitigating hallucination in large language models through real-time verification and rectification,”arXiv preprint arXiv:2311.09114, 2023
-
[29]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi- step questions,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi- step questions,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023, pp. 10 014– 10 037
2023
-
[30]
Agenthallu: Benchmarking automated hallucination attribution of llm-based agents,
X. Liu, X. Yang, Z. Li, P. Li, and R. He, “Agenthallu: Benchmarking automated hallucination attribution of llm-based agents,”arXiv preprint arXiv:2601.06818, 2026
-
[31]
Efron and R
B. Efron and R. J. Tibshirani,An Introduction to the Bootstrap. Chapman & Hall/CRC, 1994
1994
-
[32]
Self-RAG: Learning to retrieve, generate, and critique through self-reflection,
A. Asai, Z. Wu, Y . Wang, A. Salmani, and H. Hajishirzi, “Self-RAG: Learning to retrieve, generate, and critique through self-reflection,” in International Conference on Learning Representations (ICLR), 2024
2024
-
[33]
Artificial intelligence risk management framework (ai rmf 1.0) (nist trustworthy and responsible ai),
National Institute of Standards and Technology, “Artificial intelligence risk management framework (ai rmf 1.0) (nist trustworthy and responsible ai),” U.S. Department of Commerce, Tech. Rep. NIST IR 8259, January
-
[34]
[Online]. Available: https://doi.org/10.6028/NIST.AI.100-1
-
[35]
The state of AI: How organizations are rewiring to capture value,
A. Singla, A. Sukharevsky, L. Yee, M. Chui, and B. Hall, “The state of AI: How organizations are rewiring to capture value,” McKinsey & Company, Tech. Rep., March 2025, accessed: May 2026. [Online]. Avail- able: https://www.mckinsey.com/capabilities/quantumblack/our-insights/ the-state-of-ai-how-organizations-are-rewiring-to-capture-value
2025
-
[36]
Systematization of knowledge: Security and safety in the model context protocol ecosystem,
S. Gaire, S. Gyawali, S. Mishra, S. Niroula, D. Thakur, and U. Yadav, “Systematization of knowledge: Security and safety in the model context protocol ecosystem,”arXiv preprint arXiv:2512.08290, 2025
-
[37]
Traq: Trustworthy retrieval augmented question answering via conformal prediction,
S. Li, S. Park, I. Lee, and O. Bastani, “Traq: Trustworthy retrieval augmented question answering via conformal prediction,” inProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 3799–3821
2024
-
[38]
HaluEval: A large-scale hallucination evaluation benchmark for large language models,
J. Li, X. Cheng, W. X. Zhao, J.-Y . Nie, and J.-R. Wen, “HaluEval: A large-scale hallucination evaluation benchmark for large language models,”arXiv preprint arXiv:2305.11747, 2023
-
[39]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
S. T. I. Tonmoy, S. Zaman, V . Jain, A. Krause, T. Goswamiet al., “A comprehensive survey of hallucination mitigation techniques in large language models,”arXiv preprint arXiv:2401.01313, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Ares: An automated evaluation framework for retrieval-augmented generation systems,
J. Saad-Falcon, O. Khattab, C. Potts, and M. Zaharia, “Ares: An automated evaluation framework for retrieval-augmented generation systems,”arXiv preprint arXiv:2311.09476, 2023
-
[41]
March: Multi-agent reinforced self-check for llm hallucination,
Z. Li, Y . Zhang, P. Cheng, J. Song, M. Zhou, H. Li, S. Hu, Y . Qin, E. Zhao, X. Jianget al., “March: Multi-agent reinforced self-check for llm hallucination,”arXiv preprint arXiv:2603.24579, 2026
-
[42]
Zero-knowledge llm hallucination detection and mitigation through fine-grained cross-model consistency,
A. Goel, D. Schwartz, and Y . Qi, “Zero-knowledge llm hallucination detection and mitigation through fine-grained cross-model consistency,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2025, pp. 1982–1999
2025
-
[43]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[44]
Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval-augmented generation,
J. Zhang, Q. Zhang, B. Wang, L. Ouyang, Z. Wen, Y . Li, K.-H. Chow, C. He, and W. Zhang, “Ocr hinders rag: Evaluating the cascading impact of ocr on retrieval-augmented generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 17 443–17 453
2025
-
[45]
Zt-mcp: A zero-trust security architecture for mcp-connected ai agents,
S. Mishra, “Zt-mcp: A zero-trust security architecture for mcp-connected ai agents,”ResearchGate preprint, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.