TACTFUL: Tactile-Driven Exploration For Object Localization and Identification in Confined Environments
Pith reviewed 2026-06-25 23:34 UTC · model grok-4.3
The pith
Tactile sensing with a single learned policy lets robots locate and identify objects in confined spaces without vision.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
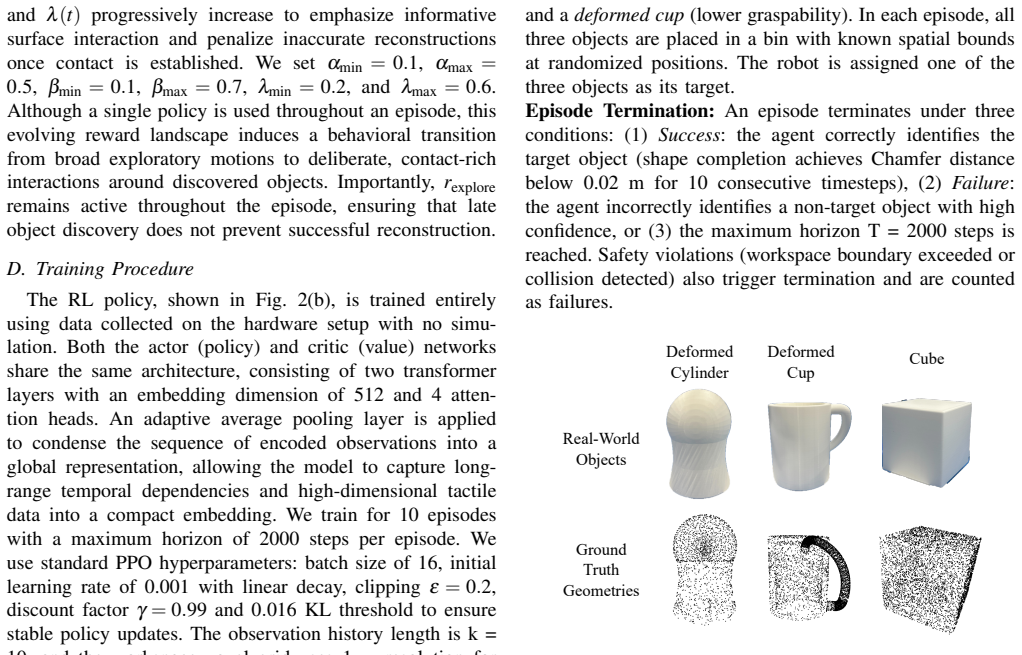
TACTFUL is a vision-free tactile exploration framework that enables a multi-fingered robot to autonomously explore confined workspaces, discover objects through contact, and identify them via tactile reconstruction. Trained entirely on real hardware without simulation, our system learns a single policy that balances global workspace exploration with local surface refinement through a dynamic reward schedule. Our results demonstrate that tactile sensing, when paired with structured learning, can serve as an effective primary modality for object-level reasoning, achieving 77% success with 0.015 m average reconstruction error and outperforming baseline approaches on real-world objects.
What carries the argument
The single policy with dynamic reward schedule that shifts from global workspace exploration to local surface refinement, trained directly on real hardware.
If this is right
- Object discovery and identification become feasible in spaces where vision sensors cannot be used.
- Tactile data alone produces object reconstructions with 0.015 m average error.
- The method exceeds baseline performance on physical objects without any simulation training.
- One policy handles both broad search across the workspace and detailed local refinement.
Where Pith is reading between the lines
- The same real-hardware training approach could apply to other contact-rich tasks such as sorting or assembly in low-visibility conditions.
- Extending the policy to sequences of multiple objects might increase overall task completion rates in cluttered scenes.
- Tactile-dominant systems could lower reliance on cameras in manipulation pipelines, reducing failure modes from lighting changes.
Load-bearing premise
A single policy trained entirely on real hardware without simulation, using a dynamic reward schedule, can reliably balance global workspace exploration with local surface refinement in confined environments.
What would settle it
Repeated trials in which the policy locates objects in fewer than half the attempts or yields average reconstruction error above 0.03 meters on new confined real-world setups would show the approach does not work as claimed.
Figures





read the original abstract
Humans effortlessly locate and identify objects by touch alone, even without vision. In contrast, robotic systems rely heavily on vision and struggle with autonomous tactile exploration and object identification. We present TACTFUL, a vision-free tactile exploration framework that enables a multi-fingered robot to autonomously explore confined workspaces, discover objects through contact, and identify them via tactile reconstruction. Trained entirely on real hardware without simulation, our system learns a single policy that balances global workspace exploration with local surface refinement through a dynamic reward schedule. Our results demonstrate that tactile sensing, when paired with structured learning, can serve as an effective primary modality for object-level reasoning, achieving 77% success with 0.015 m average reconstruction error and outperforming baseline approaches on real-world objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TACTFUL, a vision-free tactile exploration framework for a multi-fingered robot operating in confined workspaces. A single policy is trained entirely on real hardware (no simulation) using a dynamic reward schedule to balance global exploration with local surface refinement; the system discovers objects via contact and performs tactile reconstruction for identification, reporting 77% success and 0.015 m average reconstruction error while outperforming baselines on real-world objects.
Significance. If the empirical claims hold under rigorous validation, the work would establish tactile sensing as a viable primary modality for object-level reasoning in vision-denied settings, with direct relevance to confined-environment robotics. The real-hardware-only training is a concrete strength that sidesteps sim-to-real transfer issues.
major comments (2)
- [Abstract] Abstract: the headline metrics (77% success, 0.015 m average reconstruction error, outperformance of baselines) are presented without any information on trial count, success definition, reconstruction-error measurement protocol, baseline implementations, or statistical tests. This omission renders the central empirical claim unverifiable from the supplied text.
- [Method (dynamic reward schedule)] The description of the dynamic reward schedule (the sole asserted mechanism for trading off global workspace coverage against local surface sampling): no coverage curves, reward-component ablations, or failure-mode statistics across object geometries or initial conditions are supplied to demonstrate that the schedule actually enforces the required exploration-refinement transition on hardware.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the clarity of our empirical claims and the validation of the dynamic reward schedule. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline metrics (77% success, 0.015 m average reconstruction error, outperformance of baselines) are presented without any information on trial count, success definition, reconstruction-error measurement protocol, baseline implementations, or statistical tests. This omission renders the central empirical claim unverifiable from the supplied text.
Authors: We agree that the abstract would benefit from additional context to allow verification of the headline metrics without requiring the reader to consult the full text. The experimental details (trial counts, success criteria, error measurement protocol, baseline implementations, and statistical tests) are provided in Sections 4 and 5 of the manuscript. We will revise the abstract to concisely incorporate the number of trials, a brief success definition, and references to the protocols and baselines described in the methods. revision: yes
-
Referee: [Method (dynamic reward schedule)] The description of the dynamic reward schedule (the sole asserted mechanism for trading off global workspace coverage against local surface sampling): no coverage curves, reward-component ablations, or failure-mode statistics across object geometries or initial conditions are supplied to demonstrate that the schedule actually enforces the required exploration-refinement transition on hardware.
Authors: The dynamic reward schedule is presented in Section 3.2, and its effectiveness is evidenced by the overall system performance on hardware. We acknowledge that explicit supporting analyses (coverage curves, reward ablations, and failure-mode statistics) are not currently included. We will add these elements to the revised manuscript to directly demonstrate the exploration-refinement transition across object geometries and initial conditions. revision: yes
Circularity Check
No circularity: empirical hardware results with no fitted derivations or self-referential reductions.
full rationale
The paper reports measured outcomes (77% success, 0.015 m error) from real-hardware policy training and experiments. No equations, parameter fits, or derivation chains are described that reduce claims to inputs by construction. The dynamic reward schedule is presented as an empirical training mechanism, not a self-defined prediction. This matches the default case of a self-contained empirical study against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The influence of visual and haptic material information on early grasping force,
W. M. Bergmann Tiest and A. M. Kappers, “The influence of visual and haptic material information on early grasping force,”Royal Society open science, vol. 6, no. 3, p. 181563, 2019
2019
-
[2]
An open-environment tactile sensing system: toward simple and efficient material identifica- tion,
X. Wei, B. Wang, Z. Wu, and Z. L. Wang, “An open-environment tactile sensing system: toward simple and efficient material identifica- tion,”Advanced Materials, vol. 34, no. 29, p. 2203073, 2022
2022
-
[3]
Vita-zero: Zero-shot visuotactile object 6d pose estimation,
H. Li, J. Akl, S. Sridhar, T. Brady, and T. Padir, “Vita-zero: Zero-shot visuotactile object 6d pose estimation,”
-
[4]
Available: https://www.amazon.science/publications/ vita-zero-zero-shot-visuotactile-object-6d-pose-estimation
[Online]. Available: https://www.amazon.science/publications/ vita-zero-zero-shot-visuotactile-object-6d-pose-estimation
-
[5]
Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,
J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,” in2022 International Conference on Robotics and Automation (ICRA). IEEE, 2022, pp. 8298–8304
2022
-
[6]
3d-vitac: Learning fine-grained manipulation with visuo-tactile sensing,
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li, “3d-vitac: Learning fine-grained manipulation with visuo-tactile sensing,”arXiv preprint arXiv:2410.24091, 2024
arXiv 2024
-
[7]
Simple, a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects,
M. Bauza, A. Bronars, Y . Hou, I. Taylor, N. Chavan-Dafle, and A. Rodriguez, “Simple, a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects,”Science Robotics, vol. 9, no. 91, p. eadi8808, 2024
2024
-
[8]
Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning,
K. Li, P. Li, T. Liu, Y . Li, and S. Huang, “Maniptrans: Efficient dexterous bimanual manipulation transfer via residual learning,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025
2025
-
[9]
Tactile mapping and local- ization from high-resolution tactile imprints,
M. Bauza, O. Canal, and A. Rodriguez, “Tactile mapping and local- ization from high-resolution tactile imprints,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 3811–3817
2019
-
[10]
A review of tactile information: Perception and action through touch,
Q. Li, O. Kroemer, Z. Su, F. F. Veiga, M. Kaboli, and H. J. Ritter, “A review of tactile information: Perception and action through touch,” IEEE Transactions on Robotics, vol. 36, no. 6, pp. 1619–1634, 2020
2020
-
[11]
Actexplore: Active tactile explo- ration on unknown objects,
A.-H. Shahidzadeh, S. J. Yoo, P. Mantripragada, C. D. Singh, C. Ferm ¨uller, and Y . Aloimonos, “Actexplore: Active tactile explo- ration on unknown objects,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 3411–3418
2024
-
[12]
Dexskills: Skill segmentation using haptic data for learning autonomous long-horizon robotic manipulation tasks,
X. Mao, G. Giudici, C. Coppola, K. Althoefer, I. Farkhatdinov, Z. Li, and L. Jamone, “Dexskills: Skill segmentation using haptic data for learning autonomous long-horizon robotic manipulation tasks,” in 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 5104–5111
2024
-
[13]
Tandem3d: Active tactile ex- ploration for 3d object recognition,
J. Xu, H. Lin, S. Song, and M. Ciocarlie, “Tandem3d: Active tactile ex- ploration for 3d object recognition,”arXiv preprint arXiv:2209.08772, 2022
arXiv 2022
-
[14]
Tactofind: A tactile only system for object retrieval,
S. Pai, T. Chen, M. Tippur, E. Adelson, A. Gupta, and P. Agrawal, “Tactofind: A tactile only system for object retrieval,” in2023 IEEE International Conference on Robotics and Automation (ICRA), 2023, pp. 8025–8032
2023
-
[15]
Tactile slam with a biomimetic whiskered robot,
C. Fox, M. Evans, M. Pearson, and T. Prescott, “Tactile slam with a biomimetic whiskered robot,” in2012 IEEE International Conference on Robotics and Automation. IEEE, 2012, pp. 4925–4930
2012
-
[16]
Uncertainty aware grasp- ing and tactile exploration,
S. Dragiev, M. Toussaint, and M. Gienger, “Uncertainty aware grasp- ing and tactile exploration,” in2013 IEEE International conference on robotics and automation. IEEE, 2013, pp. 113–119
2013
-
[17]
Apple: Toward general active perception via reinforcement learning,
T. Schneider, C. de Farias, R. Calandra, L. Chen, and J. Peters, “Apple: Toward general active perception via reinforcement learning,” inThe Fourteenth International Conference on Learning Representations
-
[18]
Active tactile object exploration with gaussian processes,
Z. Yi, R. Calandra, F. Veiga, H. van Hoof, T. Hermans, Y . Zhang, and J. Peters, “Active tactile object exploration with gaussian processes,” in2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 4925–4930
2016
-
[19]
Simultaneous tactile localiza- tion and reconstruction of an object during robotic manipulation,
G. KISSOUM and V . PERDEREAU, “Simultaneous tactile localiza- tion and reconstruction of an object during robotic manipulation,” in 2021 20th International Conference on Advanced Robotics (ICAR), 2021, pp. 948–954
2021
-
[20]
Learning efficient haptic shape exploration with a rigid tactile sensor array,
S. Fleer, A. Moringen, R. L. Klatzky, and H. Ritter, “Learning efficient haptic shape exploration with a rigid tactile sensor array,”PloS one, vol. 15, no. 1, p. e0226880, 2020
2020
-
[21]
Touch if it’s transparent! actor: Active tactile-based category-level transparent object reconstruction,
P. K. Murali, B. Porr, and M. Kaboli, “Touch if it’s transparent! actor: Active tactile-based category-level transparent object reconstruction,” in2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 10 792–10 799
2023
-
[22]
Learning to navigate in complex environments,
P. Mirowski, R. Pascanu, F. Viola, H. Soyer, A. J. Ballard, A. Banino, M. Denil, R. Goroshin, L. Sifre, K. Kavukcuogluet al., “Learning to navigate in complex environments,”arXiv preprint arXiv:1611.03673, 2016
Pith/arXiv arXiv 2016
-
[23]
A short survey on memory based reinforcement learning (2019),
D. Ramani, “A short survey on memory based reinforcement learning (2019),”arXiv preprint arXiv:1904.06736, 1904
Pith/arXiv arXiv 2019
-
[24]
Dextouch: Learning to seek and manipulate objects with tactile dexterity,
K.-W. Lee, Y . Qin, X. Wang, and S.-C. Lim, “Dextouch: Learning to seek and manipulate objects with tactile dexterity,”IEEE Robotics and Automation Letters, vol. 9, no. 12, pp. 10 772–10 779, 2024
2024
-
[25]
A deep reinforcement learning approach for active slam,
J. A. Placed and J. A. Castellanos, “A deep reinforcement learning approach for active slam,”Applied Sciences, vol. 10, no. 23, p. 8386, 2020
2020
-
[26]
Dexter- ous manipulation with deep reinforcement learning: Efficient, general, and low-cost,
H. Zhu, A. Gupta, A. Rajeswaran, S. Levine, and V . Kumar, “Dexter- ous manipulation with deep reinforcement learning: Efficient, general, and low-cost,” in2019 International Conference on Robotics and Automation (ICRA), 2019, pp. 3651–3657
2019
-
[27]
Integrating behavior cloning and reinforcement learning for improved performance in dense and sparse reward environments,
V . G. Goecks, G. M. Gremillion, V . J. Lawhern, J. Valasek, and N. R. Waytowich, “Integrating behavior cloning and reinforcement learning for improved performance in dense and sparse reward environments,” inProceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, ser. AAMAS ’20. Richland, SC: International Foundation ...
2020
-
[28]
Efficient tactile simulation with differentiability for robotic manipulation,
J. Xu, S. Kim, T. Chen, A. R. Garcia, P. Agrawal, W. Matusik, and S. Sueda, “Efficient tactile simulation with differentiability for robotic manipulation,” inConference on Robot Learning. PMLR, 2023, pp. 1488–1498
2023
-
[29]
Survey of imitation learning for robotic manipulation,
B. Fang, S. Jia, D. Guo, M. Xu, S. Wen, and F. Sun, “Survey of imitation learning for robotic manipulation,”International Journal of Intelligent Robotics and Applications, vol. 3, no. 4, pp. 362–369, 2019
2019
-
[30]
Robotic behav- ioral cloning through task building,
J. Choi, H. Kim, Y . Son, C.-W. Park, and J. H. Park, “Robotic behav- ioral cloning through task building,” in2020 International Conference on Information and Communication Technology Convergence (ICTC), 2020, pp. 1279–1281
2020
-
[31]
Proximal policy optimization algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[32]
Sonata: Self-supervised learn- ing of reliable point representations,
X. Wu, D. DeTone, D. Frost, T. Shen, C. Xie, N. Yang, J. Engel, R. Newcombe, H. Zhao, and J. Straub, “Sonata: Self-supervised learn- ing of reliable point representations,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 193–22 204
2025
-
[33]
Efficient and scalable point cloud gen- eration with sparse point-voxel diffusion models,
I. Romanelis, V . Fotis, A. Kalogeras, C. Alexakos, K. Mous- takas, and A. Munteanu, “Efficient and scalable point cloud gen- eration with sparse point-voxel diffusion models,”arXiv preprint arXiv:2408.06145, 2024
arXiv 2024
-
[34]
Adversarial grasp objects,
D. Wang, D. Tseng, P. Li, Y . Jiang, M. Guo, M. Danielczuk, J. Mahler, J. Ichnowski, and K. Goldberg, “Adversarial grasp objects,” in2019 IEEE 15th International Conference on Automation Science and Engineering (CASE). IEEE, 2019, pp. 241–248
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.