TRIAGE: Role-Typed Credit Assignment for Agentic Reinforcement Learning
Pith reviewed 2026-07-01 06:05 UTC · model grok-4.3
The pith
Role-conditioned credit projects per-segment advantage residuals onto semantic role labels to reduce estimation error in agentic RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Role-conditioned credit is the optimal segment-level correction expressible from role labels alone -- a projection of the per-segment advantage residual onto the role variable -- so that the fixed role constants reduce advantage estimation error whenever the judge is reliable, and we connect this to lower-variance policy gradients.
What carries the argument
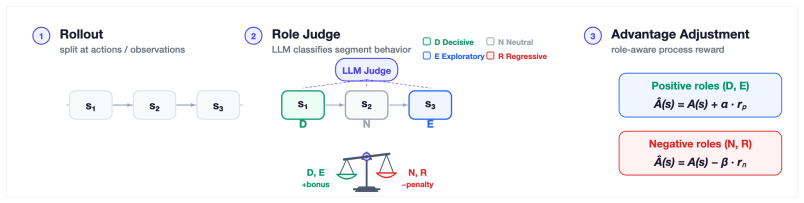
The role-typed credit assignment that maps a structured judge's four-class segment labels (decisive progress, useful exploration, no-progress infrastructure, regression) to fixed bounded process rewards added to the uniform outcome advantage from the verifier.
If this is right
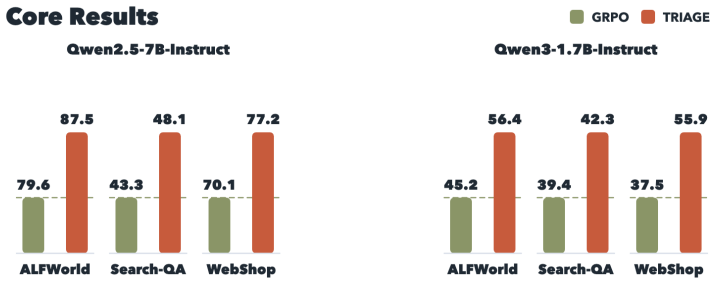
- Higher success rates than GRPO on ALFWorld, Search-QA, and WebShop for two policy models.
- Outperforms both a scalar judge-derived process reward and an outcome-supervised shared-backbone value baseline.
- Reduces environment-facing turns by an additional 10.4 percent on completed ALFWorld rollouts and 14.8 percent on WebShop rollouts relative to GRPO.
- Dominant gain comes from reliable detection of regression inside successful trajectories; exploration credit supplies a consistent secondary gain.
- The projection property links the method to lower-variance policy gradients.
Where Pith is reading between the lines
- The projection view implies that any reliable categorical label set could serve as a similar low-dimensional corrector for advantage residuals in other RL settings.
- If judge reliability can be maintained at scale, the approach could reduce the number of wasted steps in long-horizon agent training without changing the policy architecture.
- The method separates the source of optimization direction (verifier outcome) from the source of local correction (role labels), which may allow independent improvement of each component.
- Ablation results suggest that extending the role set or making the mapping rules learnable rather than fixed could yield further variance reduction.
Load-bearing premise
The structured judge produces reliable role labels for every segment; unreliable labels cause the fixed rules to distort rather than correct the advantage estimates.
What would settle it
A controlled test in which the judge is forced to misclassify regression segments as decisive progress and success rates are measured against the GRPO baseline on the same environments.
Figures
read the original abstract
Agentic reinforcement learning requires assigning credit to environment-facing actions such as searches, clicks, edits, navigation commands, and object interactions. Standard GRPO uses the final verifier outcome as a uniform advantage over all action tokens. This outcome signal is useful but structurally incomplete: it punishes useful exploration in failed rollouts and reinforces redundant or regressive actions in successful rollouts. We propose TRIAGE, a role-typed credit assignment framework that adds a semantic role axis to outcome credit. A structured judge classifies each segment as decisive progress, useful exploration, no-progress infrastructure, or regression, and a fixed role-conditioned rule maps these labels to bounded segment-level process rewards. This keeps verifier outcomes as the source of optimization direction while correcting the two main blind spots of outcome-only credit. We further show that role-conditioned credit is the optimal segment-level correction expressible from role labels alone -- a projection of the per-segment advantage residual onto the role variable -- so that the fixed role constants reduce advantage estimation error whenever the judge is reliable, and we connect this to lower-variance policy gradients. Across ALFWorld, Search-QA, and WebShop, TRIAGE improves success rates over GRPO for two policy models and outperforms both a scalar judge-derived process reward and an outcome-supervised shared-backbone value baseline. Ablations show that the gain comes from role typing rather than merely adding dense rewards: reliable detection of regression inside successful trajectories is the dominant contributor, while exploration credit provides a consistent secondary gain; on completed ALFWorld and WebShop rollouts, TRIAGE also reduces environment-facing turns by an additional $10.4\%$ and $14.8\%$ relative to GRPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRIAGE, a role-typed credit assignment method for agentic RL that augments GRPO by using a structured judge to classify trajectory segments into four roles (decisive progress, useful exploration, no-progress infrastructure, regression) and apply fixed role-conditioned process rewards. It claims this corrects outcome-only credit blind spots, that role-conditioned credit is the optimal segment-level correction as a projection of per-segment advantage residuals onto the role variable, and that it reduces estimation error when the judge is reliable while yielding lower-variance gradients. Empirical results show improved success rates over GRPO and baselines on ALFWorld, Search-QA, and WebShop for two policies, with ablations attributing gains primarily to regression detection and secondary gains from exploration credit, plus reduced environment-facing turns.
Significance. If the optimality derivation and judge-reliability condition hold, the work supplies a structured, low-parameter way to inject process-level signals into outcome-based RL for agentic settings, addressing specific failure modes like punishing exploration or reinforcing regression. The projection framing and connection to variance reduction are potentially valuable if derived rigorously; the multi-benchmark empirical results and role-typing ablations provide concrete evidence of practical impact when the judge performs as assumed.
major comments (3)
- [Abstract / optimality section] Abstract (optimality claim) and the section presenting the projection argument: the statement that role-conditioned credit 'is the optimal segment-level correction expressible from role labels alone' and 'reduce[s] advantage estimation error whenever the judge is reliable' is load-bearing for the central theoretical contribution, yet no derivation details, error bounds, or formal proof of the projection property are supplied; without these, the guarantee does not follow from the role labels alone.
- [Abstract / ablations] Abstract and results/ablations section: the claim that gains come from role typing (especially regression detection inside successful trajectories) rests on the structured judge producing reliable labels, but no judge accuracy, human agreement, or per-role error rates are reported on any benchmark; this directly affects whether the fixed constants reduce rather than inflate advantage error, as highlighted by the dominant ablation contributor.
- [Results / tables] Results section (empirical claims): success-rate improvements and turn reductions (10.4% and 14.8% relative) are reported without error bars, number of seeds, or statistical tests, making it impossible to assess whether the gains over GRPO, scalar process-reward baseline, and value baseline are robust.
minor comments (2)
- [Method] The four role definitions and the exact mapping from labels to bounded rewards are described at a high level; providing the precise prompt template or decision rules used by the judge would improve reproducibility.
- [Abstract / §3] The abstract states that the approach 'keeps verifier outcomes as the source of optimization direction' but does not clarify how the role rewards are combined with the final verifier signal in the advantage computation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical framing, judge validation, and statistical reporting. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / optimality section] Abstract (optimality claim) and the section presenting the projection argument: the statement that role-conditioned credit 'is the optimal segment-level correction expressible from role labels alone' and 'reduce[s] advantage estimation error whenever the judge is reliable' is load-bearing for the central theoretical contribution, yet no derivation details, error bounds, or formal proof of the projection property are supplied; without these, the guarantee does not follow from the role labels alone.
Authors: We agree that the projection argument requires a more explicit derivation. The manuscript presents the high-level claim that role-conditioned credit is the projection of the per-segment advantage residual onto the role variable, but we will revise the optimality section to include the full mathematical steps deriving this projection, the resulting error bound conditional on judge reliability, and the explicit link to lower-variance gradients. This will make the theoretical guarantee self-contained. revision: yes
-
Referee: [Abstract / ablations] Abstract and results/ablations section: the claim that gains come from role typing (especially regression detection inside successful trajectories) rests on the structured judge producing reliable labels, but no judge accuracy, human agreement, or per-role error rates are reported on any benchmark; this directly affects whether the fixed constants reduce rather than inflate advantage error, as highlighted by the dominant ablation contributor.
Authors: We acknowledge that the absence of quantitative judge validation is a limitation, as judge reliability underpins whether the fixed role rewards reduce advantage error. The current manuscript does not report accuracy, agreement, or per-role metrics. In revision we will add a dedicated evaluation subsection reporting judge accuracy, human agreement rates on sampled trajectories across benchmarks, and per-role precision/recall to substantiate the ablation claims. revision: yes
-
Referee: [Results / tables] Results section (empirical claims): success-rate improvements and turn reductions (10.4% and 14.8% relative) are reported without error bars, number of seeds, or statistical tests, making it impossible to assess whether the gains over GRPO, scalar process-reward baseline, and value baseline are robust.
Authors: We agree that variability measures are needed to establish robustness. We will revise the results section and tables to report error bars over multiple random seeds, state the number of seeds explicitly, and include statistical significance tests comparing TRIAGE against the baselines. revision: yes
Circularity Check
No significant circularity; central optimality claim is a mathematical projection property independent of fitted values
full rationale
The paper's key derivation states that role-conditioned credit equals the projection of the per-segment advantage residual onto the role variable, presented as the optimal correction expressible from role labels alone. This is a definitional property of orthogonal projection in the space of role-typed functions and does not reduce to any fitted parameter or self-citation chain. The fixed role constants are applied after the judge labels segments, but the optimality statement itself is not constructed by fitting those constants to the target advantage; it holds whenever the judge supplies the labels. No equations or sections in the provided text equate a prediction to its own input by construction, smuggle an ansatz via self-citation, or rename an empirical pattern as a new result. The derivation remains self-contained against external benchmarks such as the GRPO baseline and ablations on regression detection.
Axiom & Free-Parameter Ledger
free parameters (1)
- role-conditioned reward constants
axioms (1)
- domain assumption A structured judge can classify every trajectory segment into one of four semantic roles with sufficient reliability to reduce advantage error.
invented entities (1)
-
decisive progress / useful exploration / no-progress infrastructure / regression roles
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
doi: 10.1038/s41586-025-09422-z. Luong Trung, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. ReFT: Reasoning with reinforced fine-tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7601–7614, Bangkok, Thailand,
-
[3]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.410. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.410 2024
-
[4]
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Beyond GRPO and on-policy distillation: An empirical sparse-to-dense reward principle for language- model post-training.arXiv preprint arXiv:2605.12483, 2026a. Hanlin Wang, Chak Tou Leong, Jiashuo Wang, Jian Wang, and Wenjie Li. SPA-RL: Reinforcing LLM agents via stepwise p...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Self-Distilled Agentic Reinforcement Learning
Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Self-distilled agentic reinforcement learning. arXiv preprint arXiv:2605.15155,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. TIP: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026b. Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
Matthew Dunn, Levent Sagun, Mike Higgins, V . Ugur Guney, V olkan Cirik, and Kyunghyun Cho. SearchQA: A new Q&A dataset augmented with context from a search engine.arXiv preprint arXiv:1704.05179,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback.arXiv preprint arXiv:2303.17651,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Rubric-based On-policy Distillation
Junfeng Fang, Zhepei Hong, Mao Zheng, Mingyang Song, Gengsheng Li, Houcheng Jiang, Dan Zhang, Haiyun Guo, Xiang Wang, and Tat-Seng Chua. Rubric-based on-policy distillation.arXiv preprint arXiv:2605.07396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Toolformer: Language Models Can Teach Themselves to Use Tools
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023a. Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolforme...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Advances in Neural Information Processing Systems, 2023b. Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. STaR: Bootstrapping reasoning with reasoning.arXiv preprint a...
-
[14]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Expand (AGRPO i +λc ˆρ−A ∗)2 = (λc ˆρ−δ) 2 =δ 2 +λ 2c2 ˆρ−2λc ˆρδ and average over the batch; the correctionλ2σ2 c −2λCov is a convex quadratic inλ, minimized at λ⋆. B Extended Theoretical Discussion This appendix expands the short discussion following Proposition 2: why the fixed constants should align with the residual, how the correction connects to po...
2004
-
[16]
no regression penalty
and of the degradation at large λ and |cR| (Table 10). We therefore present these results as a justification conditional on judge reliability, which our audit (Section 5, Appendix H) measures directly rather than assumes. 13 Table 8: Training hyperparameters. Here η is the learning rate, G is the number of rollouts per prompt, Steps is the number of optim...
2017
-
[17]
AM”)s0 [E] short wave broadcast service |s 1 [E] short wave broadcast service am |s 2 [E] short wave broadcast service mode|a[R] AM. SQ-F4 (answer “February and June
SQ-F3 (answer “AM”)s0 [E] short wave broadcast service |s 1 [E] short wave broadcast service am |s 2 [E] short wave broadcast service mode|a[R] AM. SQ-F4 (answer “February and June”) s0 [E] south west wind blows across Nigeria |s 1 [E] south west wind blows across Nigeria between |s 2 [E] south west wind blows across Nigeria between Februar. . .|a[R] Febr...
2018
-
[18]
SQ-F7 (answer “2018”) s0 [E] Philadelphia last Super Bowl win |s 1 [E] Philadelphia Eagles last Super Bowl win|a[R]
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.