AgenticDataBench: A Comprehensive Benchmark for Data Agents
Pith reviewed 2026-07-03 03:34 UTC · model grok-4.3
The pith
AgenticDataBench supplies realistic data science tasks from 15 domains plus skill-level labels to test LLM data agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
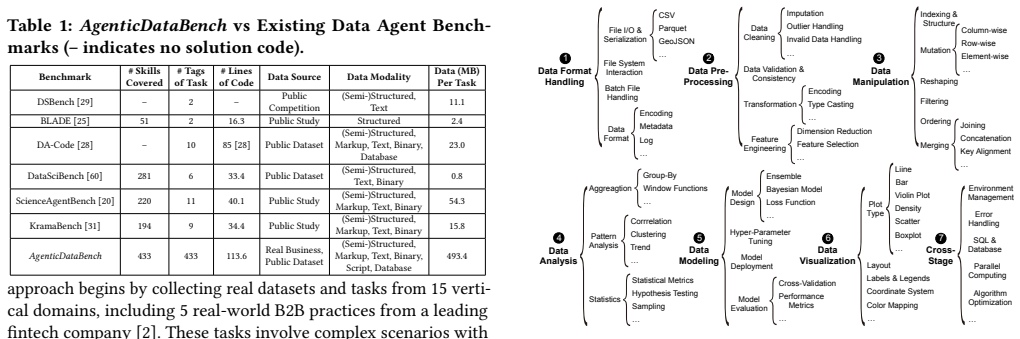
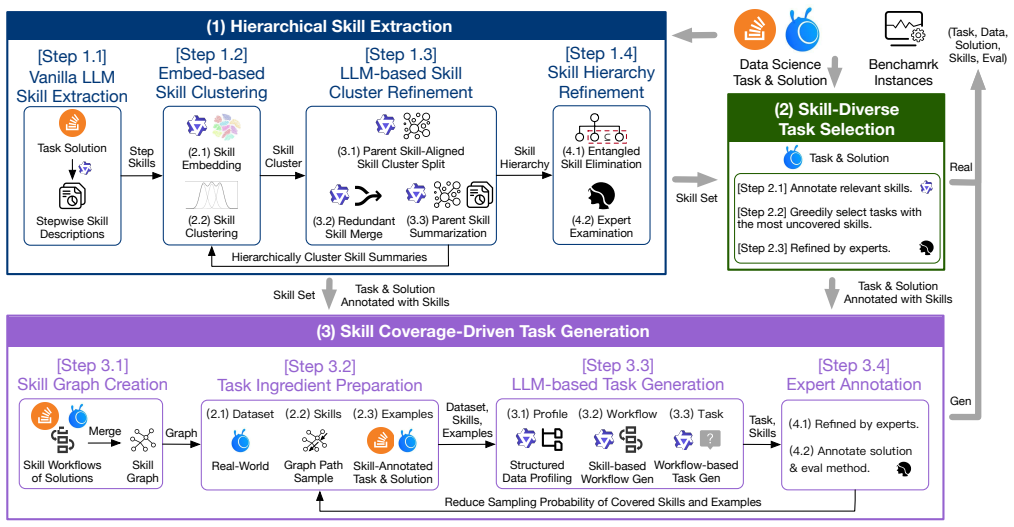
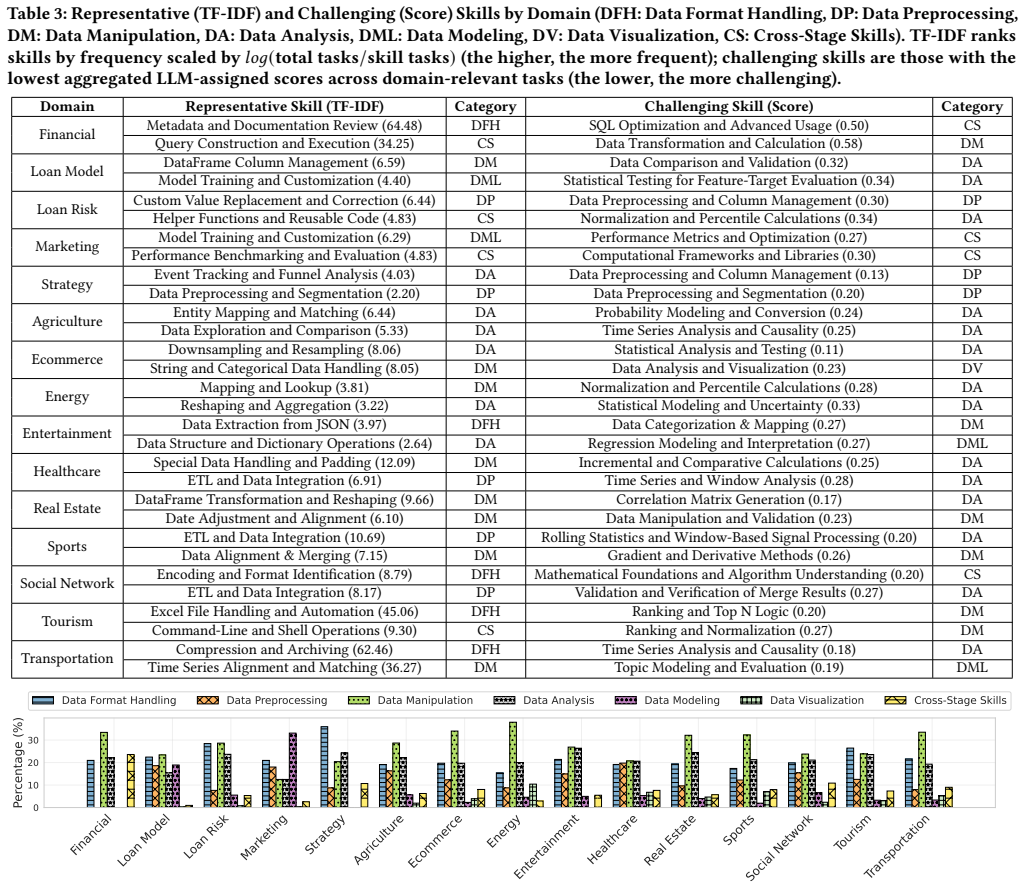
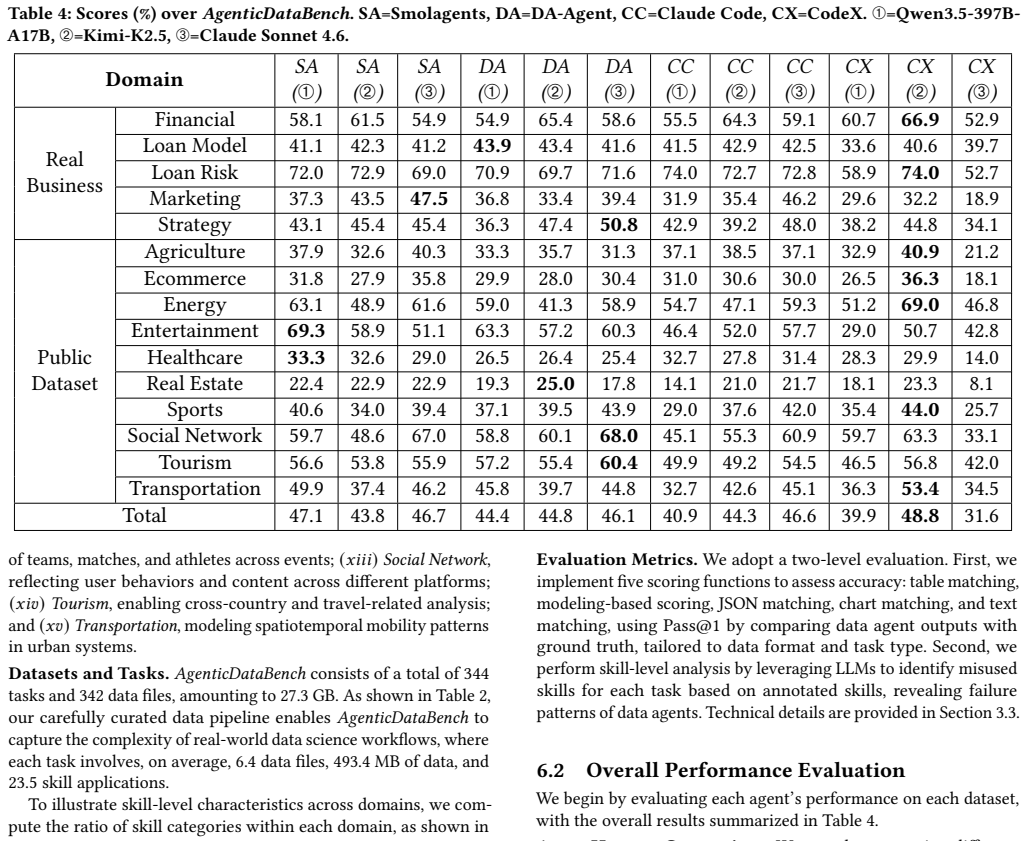
AgenticDataBench is a benchmark of realistic tasks spanning 15 vertical domains, including five real B2B use cases, whose coverage is quantified by the number of data science skills they contain. Representative skills are obtained by skill-aligned hierarchical clustering on large-scale Stack Overflow solutions; real tasks are chosen to maximize skill-composition diversity; and LLM-generated workflows fill gaps for domains without native data. The resulting annotated testbed enables skill-level evaluation of state-of-the-art data agents.
What carries the argument
AgenticDataBench, constructed by extracting recurring data science skills via hierarchical clustering from Stack Overflow, then assembling and annotating tasks that maximize coverage of those skills across real and generated workflows.
If this is right
- Evaluations can now report agent performance broken down by individual data science skills instead of aggregate success rates.
- The benchmark includes five real fintech B2B cases chosen to maximize practical skill diversity.
- Open-sourced testbed allows repeated, comparable runs of current and future data agents.
- Coverage is measured directly by the count of distinct skills exercised in the task set.
- State-of-the-art agents receive skill-level diagnostics showing where they succeed or fall short.
Where Pith is reading between the lines
- Adoption of this benchmark could shift research focus toward agents that reliably handle the most frequent skill patterns rather than narrow end-to-end tasks.
- The clustering-plus-LLM-generation recipe may transfer to building benchmarks for other agent domains that lack large public task corpora.
- Fine-grained labels open the possibility of training or fine-tuning agents on specific weak skills identified by the benchmark.
Load-bearing premise
The skills identified by clustering and the tasks produced by LLMs for missing domains faithfully reflect actual data science practice rather than introducing artificial simplicity or bias.
What would settle it
A panel of practicing data scientists rates a random sample of the generated tasks as substantially less realistic or complex than typical real-world workflows, or finds that skill coverage does not predict observed workflow difficulty.
Figures


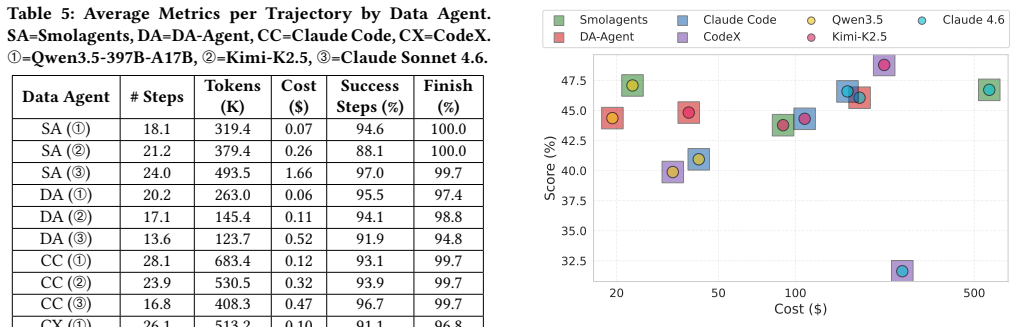
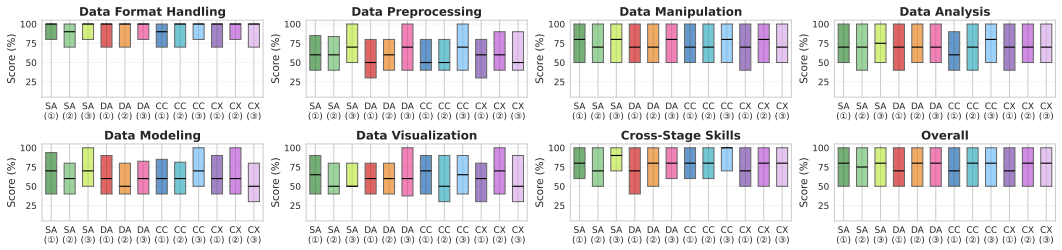

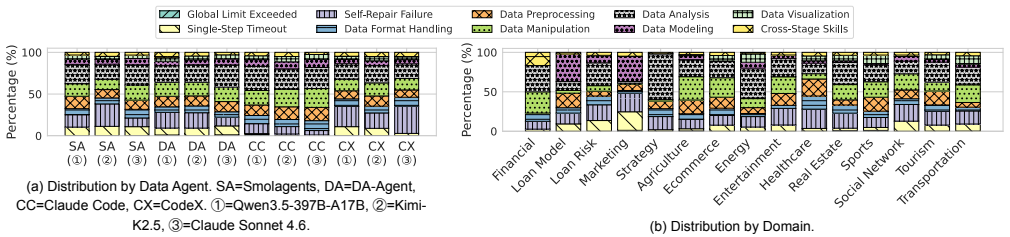
read the original abstract
Data science aims to derive actionable insights from heterogeneous raw data, unlocking the value of the massive amounts of data generated in modern society. Automating this process is essential to reducing labor-intensive efforts for data scientists and enabling scalable data-driven applications. Recently, large language model (LLM)-based data agents have emerged as a promising solution to automate data science workflows. However, the field lacks comprehensive benchmarks to rigorously evaluate these agents across diverse scenarios with fine-grained granularity. To address this gap, we propose AgenticDataBench, a comprehensive benchmark featuring realistic tasks spanning diverse domains with fine-grained ground-truth labels. This enables evaluations to capture the diversity and complexity of data science workflows and the detailed performance of agents. First, to cover diverse domains, we collect real datasets and tasks from 15 vertical domains, including 5 real-world B2B use cases from a leading fintech company. Second, to remove redundancy in real-world tasks and generate high-quality tasks for domains lacking real data, we introduce data science skills, recurring data-centric operational patterns, and quantify benchmark coverage by the number of skills included. Representative skills are extracted from large-scale task solutions on Stack Overflow using skill-aligned hierarchical clustering. Third, for real-world business tasks, we select task-solution pairs that maximize diversity in skill composition, ensuring broad coverage of practical scenarios. Fourth, to generate realistic tasks for devise domains without real tasks, we propose a systematic LLM-based task generation approach to create workflows and tasks based on these skills. Finally, we evaluate state-of-the-art data agents using our annotated benchmark and open-sourced testbed, providing detailed skill-level insights.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AgenticDataBench as a benchmark for LLM-based data agents. It collects real datasets and tasks from 15 vertical domains (including 5 B2B fintech cases), extracts recurring data science skills via skill-aligned hierarchical clustering on large-scale Stack Overflow solutions, selects task-solution pairs maximizing skill diversity for the real B2B cases, applies an LLM-based generation pipeline to synthesize workflows and tasks for domains lacking real data, annotates all tasks with fine-grained ground-truth labels, and evaluates state-of-the-art agents on the resulting benchmark while releasing an open-sourced testbed to enable skill-level performance analysis.
Significance. If the constructed tasks prove realistic and representative, the benchmark would address a clear gap by supplying the first large-scale, multi-domain resource with fine-grained annotations for data-agent evaluation, moving beyond coarse end-to-end metrics. The inclusion of genuine B2B use cases and the commitment to open-sourcing the testbed are concrete strengths that would facilitate reproducible follow-on work.
major comments (2)
- [Abstract, Fourth] Abstract, Fourth: the LLM-based task generation approach is presented without any described validation step (expert review, comparison to real workflow traces, or distributional match to observed data-science practice); this directly undermines the central claim that the benchmark supplies 'realistic tasks' spanning diverse domains.
- [Abstract, Second] Abstract, Second: the skill-aligned hierarchical clustering on Stack Overflow is introduced without reported quantitative diagnostics (cluster quality, coverage statistics, or alignment with external data-science skill taxonomies), leaving the representativeness of both the real-task selection and the LLM-generated tasks unverified.
minor comments (1)
- [Abstract] Abstract: 'for devise domains' appears to be a typographical error and should read 'for diverse domains'.
Simulated Author's Rebuttal
We thank the referee for the insightful comments. We address each major point below and commit to revisions that strengthen the methodological transparency without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract, Fourth] Abstract, Fourth: the LLM-based task generation approach is presented without any described validation step (expert review, comparison to real workflow traces, or distributional match to observed data-science practice); this directly undermines the central claim that the benchmark supplies 'realistic tasks' spanning diverse domains.
Authors: We agree the abstract omits explicit validation details for the LLM pipeline. The full manuscript describes the generation process but does not include a validation subsection. In revision we will add expert review of a sampled subset of generated tasks, direct comparison against the five real B2B workflow traces, and distributional statistics matching observed skill frequencies. This addition will be placed in the methods section and referenced from the abstract. revision: yes
-
Referee: [Abstract, Second] Abstract, Second: the skill-aligned hierarchical clustering on Stack Overflow is introduced without reported quantitative diagnostics (cluster quality, coverage statistics, or alignment with external data-science skill taxonomies), leaving the representativeness of both the real-task selection and the LLM-generated tasks unverified.
Authors: The clustering procedure is detailed in the manuscript, yet quantitative diagnostics are indeed absent. We will incorporate cluster-quality metrics (silhouette score and Davies-Bouldin index), coverage statistics across the 15 domains, and alignment scores against established taxonomies (e.g., Kaggle skill tags and ACM data-science curriculum). These will appear in a new diagnostics subsection and will be cited in the abstract. revision: yes
Circularity Check
No circularity: benchmark construction uses external sources without self-referential reduction
full rationale
The paper describes a benchmark construction pipeline that collects real datasets from 15 domains, extracts skills via hierarchical clustering on external Stack Overflow data, selects diverse task-solution pairs, and applies LLM generation for missing domains. No equations, fitted parameters, predictions, or first-principles results are present that reduce to the inputs by construction. No self-citations are load-bearing for the central claim, no uniqueness theorems are invoked, and no ansatz or renaming occurs. The process is self-contained against external benchmarks (real datasets and SO traces) and does not create a definitional loop; its value depends on external adoption rather than internal equivalence.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Real datasets and tasks collected from 15 vertical domains including 5 B2B fintech cases sufficiently represent the diversity of data science workflows.
- domain assumption Skill-aligned hierarchical clustering on large-scale Stack Overflow solutions extracts representative recurring data-centric operational patterns without significant omission or duplication.
- domain assumption LLM-based task generation produces realistic workflows and tasks for domains lacking real data.
Reference graph
Works this paper leans on
-
[1]
Retrieved Febrary 11, 2026 from https: //platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
2026.Agent Skills - Claude API Docs. Retrieved Febrary 11, 2026 from https: //platform.claude.com/docs/en/agents-and-tools/agent-skills/overview
2026
-
[2]
Retrieved Febrary 11, 2026 from https://antdigital.com/en
2026.AI-Driven eKYC & Mobile Solutions | Ant Digital Technologies. Retrieved Febrary 11, 2026 from https://antdigital.com/en
2026
-
[3]
Retrieved Febrary 11, 2026 from https://bailian.console.alibabacloud.com/
2026.Bailian Console of the Large Model Service Platform. Retrieved Febrary 11, 2026 from https://bailian.console.alibabacloud.com/
2026
-
[4]
Retrieved February 11, 2026 from https://geodata.bts.gov/datasets/usdot::means- of-transportation-to-work/about
2026.Bureau of Transportation Statistics - National Transportation Atlas Database. Retrieved February 11, 2026 from https://geodata.bts.gov/datasets/usdot::means- of-transportation-to-work/about
2026
-
[5]
Retrieved February 11, 2026 from https://openai.com/codex
2026.Codex | AI Coding Partner from OpenAI | OpenAI. Retrieved February 11, 2026 from https://openai.com/codex
2026
-
[6]
Re- trieved February 11, 2026 from https://gdc.cancer.gov/about-data/publications/ PanCan-Clinical-2018
2026.Genomic Data Commons - TCGA Pan-Cancer Clinical Data Resource. Re- trieved February 11, 2026 from https://gdc.cancer.gov/about-data/publications/ PanCan-Clinical-2018
2026
-
[7]
Retrieved Febrary 11, 2026 from https://archive.ics.uci.edu
2026.Home - UCI Machine Learning Repository. Retrieved Febrary 11, 2026 from https://archive.ics.uci.edu
2026
-
[8]
Retrieved Febrary 11, 2026 from https://www.kaggle.com/
2026.Kaggle: Your Machine Learning and Data Science Community. Retrieved Febrary 11, 2026 from https://www.kaggle.com/
2026
-
[9]
Retrieved Febrary 11, 2026 from https://data.mendeley.com/
2026.Mendeley Data. Retrieved Febrary 11, 2026 from https://data.mendeley.com/
2026
-
[10]
Retrieved February 11, 2026 from https://www.naturalearthdata.com/downloads/50m-cultural-vectors/
2026.Natural Earth - Free Vector and Raster Map Data. Retrieved February 11, 2026 from https://www.naturalearthdata.com/downloads/50m-cultural-vectors/
2026
-
[11]
Retrieved February 11, 2026 from https://github.com/owid/co2-data
2026.Our World in Data - CO2 and Greenhouse Gas Emissions. Retrieved February 11, 2026 from https://github.com/owid/co2-data
2026
-
[12]
Retrieved February 11, 2026 from https: //code.claude.com/docs/en/overview
2026.Overview - Claude Code Docs. Retrieved February 11, 2026 from https: //code.claude.com/docs/en/overview
2026
-
[13]
Retrieved Febrary 11, 2026 from https://huggingface.co/collections/Qwen/qwen3-embedding
2026.Qwen3-Embedding - a Qwen Collection. Retrieved Febrary 11, 2026 from https://huggingface.co/collections/Qwen/qwen3-embedding
2026
-
[14]
2026.smolagents: a barebones library for agents that think in code.Retrieved Febrary 11, 2026 from https://github.com/huggingface/smolagents
2026
-
[15]
Retrieved Febrary 11, 2026 from https://stackoverflow.com
2026.Stack Overflow - Where Developers Learn, Share, & Build Careers. Retrieved Febrary 11, 2026 from https://stackoverflow.com
2026
-
[16]
Retrieved February 11, 2026 from https://www.nyc.gov/site/tlc/about/tlc-trip- record-data.page
2026.TLC Trip Record Data - New York City Taxi and Limousine Commission. Retrieved February 11, 2026 from https://www.nyc.gov/site/tlc/about/tlc-trip- record-data.page
2026
- [17]
-
[18]
Kwan Ho Ryan Chan, Yaodong Yu, Chong You, Haozhi Qi, John Wright, and Yi Ma. 2022. ReduNet: A White-box Deep Network from the Principle of Maximizing Rate Reduction.J. Mach. Learn. Res.23 (2022), 114:1–114:103
2022
-
[19]
Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christopher Ré
Mayee F. Chen, Nicholas Roberts, Kush Bhatia, Jue Wang, Ce Zhang, Frederic Sala, and Christopher Ré. 2023. Skill-it! A data-driven skills framework for understanding and training language models. InNIPS
2023
-
[20]
Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun
Ziru Chen, Shijie Chen, Yuting Ning, Qianheng Zhang, Boshi Wang, Botao Yu, Yifei Li, Zeyi Liao, Chen Wei, Zitong Lu, Vishal Dey, Mingyi Xue, Frazier N. Baker, Benjamin Burns, Daniel Adu-Ampratwum, Xuhui Huang, Xia Ning, Song Gao, Yu Su, and Huan Sun. 2025. ScienceAgentBench: Toward Rigorous Assessment of Language Agents for Data-Driven Scientific Discover...
2025
-
[21]
Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael C
Aniket Didolkar, Anirudh Goyal, Nan Rosemary Ke, Siyuan Guo, Michal Valko, Timothy P. Lillicrap, Danilo Jimenez Rezende, Yoshua Bengio, Michael C. Mozer, and Sanjeev Arora. 2024. Metacognitive Capabilities of LLMs: An Exploration in Mathematical Problem Solving. InNIPS
2024
-
[22]
Martin Ester, Hans-Peter Kriegel, Jörg Sander, Xiaowei Xu, et al. 1996. A density- based algorithm for discovering clusters in large spatial databases with noise. In SIGKDD, Vol. 96. 226–231
1996
-
[23]
2025.Magic Quadrant for Data Science and Machine Learning Plat- forms
Gartner, Inc. 2025.Magic Quadrant for Data Science and Machine Learning Plat- forms. Technical Report. Gartner, Inc. https://www.gartner.com/en/documents/ 6533902 Published May 28, 2025
2025
-
[24]
1992.Benchmark Handbook: For Database and Transaction Processing Systems
Jim Gray. 1992.Benchmark Handbook: For Database and Transaction Processing Systems. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA
1992
-
[25]
Ken Gu, Ruoxi Shang, Ruien Jiang, Keying Kuang, Richard-John Lin, Donghe Lyu, Yue Mao, Youran Pan, Teng Wu, Jiaqian Yu, et al. 2024. BLADE: Benchmarking Language Model Agents for Data-Driven Science. InEMNLP. 13936–13971
2024
-
[26]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. 2025. Deepseek-r1: Incen- tivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Ruilin Hu, Yuyu Luo, Guoliang Li, Shuangqiao Wu, and Yun Luo. 2026. OpenSQL: Data-Efficient Text-to-SQL for Open-Source LLMs via Synthesized Intermediate Supervision.Proc. VLDB Endow(2026)
2026
-
[28]
Yiming Huang, Jianwen Luo, Yan Yu, Yitong Zhang, Fangyu Lei, Yifan Wei, Shizhu He, Lifu Huang, Xiao Liu, Jun Zhao, et al. 2024. DA-Code: Agent Data Science Code Generation Benchmark for Large Language Models. InEMNLP. 13487–13521
2024
-
[29]
Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wenlin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, and Dong Yu. 2025. DSBench: How Far Are Data Science Agents from Becoming Data Science Experts?. InICLR
2025
-
[30]
Simran Kaur, Simon Park, Anirudh Goyal, and Sanjeev Arora. 2025. Instruct- SkillMix: A Powerful Pipeline for LLM Instruction Tuning. InICLR
2025
-
[31]
Eugenie Lai, Gerardo Vitagliano, Ziyu Zhang, Om Chabra, Sivaprasad Sudhir, Anna Zeng, Anton A Zabreyko, Chenning Li, Ferdi Kossmann, Jialin Ding, et al
- [32]
-
[33]
Hai Lan, Tingting Wang, Zhifeng Bao, Guoliang Li, Daomin Ji, Ge Lee, Feng Luo, Zi Huang, Hailang Qiu, and Gang Hua. 2026. AgenticScholar: Agentic Data Management with Pipeline Orchestration for Scholarly Corpora.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–28
2026
-
[34]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al . 2024. Can llm already serve as a database interface? a big bench for large-scale database grounded text-to- sqls.Advances in Neural Information Processing Systems36 (2024). https://bird- bench.github.io/
2024
-
[35]
Parameswaran
Shu Liu, Soujanya Ponnapalli, Shreya Shankar, Sepanta Zeighami, Alan Zhu, Shubham Agarwal, Ruiqi Chen, Samion Suwito, Shuo Yuan, Ion Sto- ica, Matei Zaharia, Alvin Cheung, Natacha Crooks, Joseph Gonzalez, and Aditya G. Parameswaran. 2026. Supporting Our AI Overlords: Redesign- ing Data Systems to be Agent-First. In16th Conference on Innovative Data System...
2026
-
[36]
Michaud, Jeff Gore, and Max Tegmark
Ziming Liu, Yizhou Liu, Eric J. Michaud, Jeff Gore, and Max Tegmark. 2025. Physics of Skill Learning.CoRRabs/2501.12391 (2025). arXiv:2501.12391
-
[37]
Yuyu Luo, Guoliang Li, Ju Fan, and Nan Tang. 2026. Data Agents: Levels, State of the Art, and Open Problems. InCompanion of the International Conference on Management of Data. 571–579
2026
-
[38]
Xian Lyu, Chen Lin, Yihang Zheng, Zhifeng Bao, Yiming Zhang, and Guoliang Li. 2026. GenIA: Generative Index Advisor for Dynamic Workloads and Data. IEEE Transactions on Knowledge and Data Engineering(2026)
2026
-
[39]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform man- ifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Michaud, Ziming Liu, Uzay Girit, and Max Tegmark
Eric J. Michaud, Ziming Liu, Uzay Girit, and Max Tegmark. 2023. The Quantiza- tion Model of Neural Scaling. InNIPS
2023
-
[41]
Mazda Moayeri, Vidhisha Balachandran, Varun Chandrasekaran, Safoora Yousefi, Thomas Fel, Soheil Feizi, Besmira Nushi, Neel Joshi, and Vibhav Vineet. 2025. Un- earthing Skill-level Insights for Understanding Trade-offs of Foundation Models. InICLR
2025
-
[42]
Fionn Murtagh and Pedro Contreras. 2012. Algorithms for hierarchical clustering: an overview.Wiley interdisciplinary reviews: data mining and knowledge discovery 2, 1 (2012), 86–97
2012
-
[43]
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. 1978. An analy- sis of approximations for maximizing submodular set functions—I.Mathematical programming14, 1 (1978), 265–294
1978
-
[44]
Jianmo Ni, Jiacheng Li, and Julian McAuley. 2019. Justifying recommendations using distantly-labeled reviews and fine-grained aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 188–197. https://cseweb.ucsd.edu/~jmcauley/...
2019
- [45]
-
[46]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D Manning. 2024. RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. InICLR
2024
-
[47]
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.VLDB18, 9 (2025), 3035–3048
2025
-
[48]
Shreya Shankar, Sepanta Zeighami, and Aditya Parameswaran. 2026. Task Cascades for Efficient Unstructured Data Processing.Proceedings of the ACM on Management of Data4, 1 (SIGMOD (2026), 1–26
2026
- [49]
- [50]
-
[51]
Zhaoyan Sun, Xuanhe Zhou, Guoliang Li, Xiang Yu, Jianhua Feng, and Yong Zhang. 2025. R-Bot: An LLM-Based Query Rewrite System.VLDB18, 12 (2025), 5031–5044
2025
-
[52]
Zhaoyan Sun, Xuanhe Zhou, Jianming Wu, Wei Zhou, and Guoliang Li. 2025. D-Bot: An LLM-Powered DBA Copilot. InSIGMOD Companion. 235–238
2025
-
[53]
Zirui Tang, Xuanhe Zhou, Yumou Liu, Linchun Li, Yukai Wu, Weizheng Wang, Hongzhang Huang, Wei Zhou, Jun Zhou, Jiachen Song, Shaoli Yu, Jinqi Wang, Zihang Zhou, Hongyi Zhou, Yuting Lv, Jinyang Li, Jiashuo Liu, Ruoyu Chen, Chunwei Liu, GuoLiang Li, Jihua Kang, and Fan Wu. 2026. Workspace-Bench13 1.0: Benchmarking AI Agents on Workspace Tasks with Large-Scal...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Jiayi Wang and Jianhua Feng. 2025. Unify: An unstructured data analytics system. InICDE. IEEE, 4662–4674
2025
-
[55]
Kuncan Wang, Ziting Wang, Peizhuo Lv, Haoyang Li, Guoliang Li, Gao Cong, and Wei Dong. 2026. Data Agents Under Attack: Vulnerabilities in LLM-Driven Analytical Systems.arXiv preprint arXiv:2606.08661(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
Jingzhe Xu, Rui Wang, Jiannan Wang, and Guoliang Li. 2026. PrepBench: How Far Are We from Natural-Language-Driven Data Preparation?arXiv preprint arXiv:2605.08687(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Shihui Xu, Jiayi Wang, and Guoliang Li. 2026. Bridging the Gap: Cardinality Estimation for Semantic Queries on Unstructured Data.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–26
2026
-
[58]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Dingli Yu, Simran Kaur, Arushi Gupta, Jonah Brown-Cohen, Anirudh Goyal, and Sanjeev Arora. 2024. SKILL-MIX: a Flexible and Expandable Family of Evaluations for AI Models. InICLR
2024
-
[60]
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chengxing Xie, Cunxiang Wang, et al. 2026. GLM-5: from Vibe Coding to Agentic Engineering.arXiv preprint arXiv:2602.15763(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [61]
-
[62]
Yuxin Zhang, Meihao Fan, Ju Fan, Mingyang Yi, Yuyu Luo, Guoliang Li, Bin Wu, and Wenchao Zhou. 2026. Reward-SQL: Boosting Text-to-SQL via Stepwise Execution-Aware Reasoning and Process-Supervised Rewards.Proceedings of the ACM on Management of Data4, 3 (SIGMOD (2026), 1–27
2026
-
[63]
Wei Zhou, Yuyang Gao, Xuanhe Zhou, and Guoliang Li. 2025. Cracking SQL barriers: An llm-based dialect translation system.Proceedings of the ACM on Management of Data3, 3 (2025), 1–26
2025
-
[64]
Wei Zhou, Yuyang Gao, Xuanhe Zhou, and Guoliang Li. 2026. CrackSQL: A Hybrid Dialect Translation System Powered by LLM. InCompanion of the Inter- national Conference on Management of Data. 154–157
2026
- [65]
- [66]
-
[67]
Wei Zhou, Xuanhe Zhou, Shaokun Han, Hongming Xu, Guoliang Li, Zhiyu Li, Feiyu Xiong, and Fan Wu. 2026. Are We Ready For An Agent-Native Memory System? arXiv:2606.24775 [cs.CL] https://arxiv.org/abs/2606.24775
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[68]
Wei Zhou, Xuanhe Zhou, Qikang He, Guoliang Li, Bingsheng He, Quanqing Xu, and Fan Wu. 2026. Automating Database-Native Function Code Synthesis with LLMs.CoRRabs/2604.06231 (2026). https://doi.org/10.48550/ARXIV.2604.06231 arXiv:2604.06231
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.06231 2026
-
[69]
Xuanhe Zhou, Guoliang Li, Zhaoyan Sun, Zhiyuan Liu, Weize Chen, Jianming Wu, Jiesi Liu, Ruohang Feng, and Guoyang Zeng. 2024. D-Bot: Database Diagnosis System using Large Language Models.VLDB17, 10 (2024), 2514–2527
2024
-
[70]
Xuanhe Zhou, Zhaoyan Sun, and Guoliang Li. 2024. Db-gpt: Large language model meets database.Data Science and Engineering9, 1 (2024), 102–111. 14
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.