Recognition: no theorem link
Automating Database-Native Function Code Synthesis with LLMs
Pith reviewed 2026-05-13 21:16 UTC · model grok-4.3
The pith
DBCooker automates synthesis of database-native functions with LLMs, raising average accuracy by 34.55 percent across SQLite, PostgreSQL, and DuckDB.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
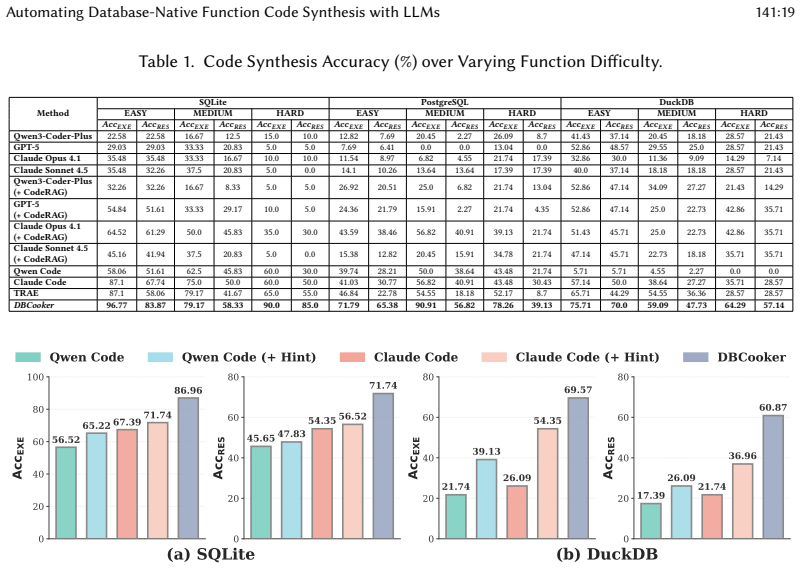
DBCooker is an LLM-based system whose function characterization module identifies specialized units and cross-unit links; its operations include a pseudo-code plan generator that builds skeletons around reusable references, a hybrid fill-in-the-blank model guided by probabilistic priors to insert core logic, and three-level progressive validation for syntax, compliance, and semantics; these are unified by adaptive orchestration. The system delivers 34.55 percent higher accuracy on average than prior methods on SQLite, PostgreSQL, and DuckDB while synthesizing functions absent from SQLite v3.50.
What carries the argument
The hybrid fill-in-the-blank model guided by probabilistic priors and component awareness, paired with three-level progressive validation that checks syntax, standards compliance, and semantic correctness.
If this is right
- Database developers can introduce new kernel functions with substantially less manual coding effort.
- The same pipeline produces usable code for SQLite, PostgreSQL, and DuckDB without per-system redesign.
- Functions missing from the latest release of a database can be generated automatically.
- Structured planning and validation reduce the hallucinations that occur with generic LLM code generators.
- Adaptive orchestration based on prior similar functions improves consistency across repeated synthesis tasks.
Where Pith is reading between the lines
- The same breakdown of characterization, planning, hybrid insertion, and staged checks could apply to generating code for other layered systems such as storage engines or network stacks.
- If the validation stages prove robust, they offer a reusable pattern for making LLMs reliable in domains where partial errors cause system-wide failures.
- Success on missing functions suggests the method could speed up database customization for specific business requirements without waiting for upstream releases.
- Testing the approach on larger functions with more interdependent units would reveal whether the current orchestration strategy scales.
Load-bearing premise
The hybrid fill-in-the-blank model and three-level progressive validation will reliably block LLM hallucinations and produce functionally correct code for many different function types.
What would settle it
Run DBCooker on a new function, integrate the output into one of the tested databases, and observe whether it produces wrong query results or crashes on real data despite passing all validation stages.
Figures








read the original abstract
Database systems incorporate an ever-growing number of functions in their kernels (a.k.a., database native functions) for scenarios like new application support and business migration. This growth causes an urgent demand for automatic database native function synthesis. While recent advances in LLM-based code generation (e.g., Claude Code) show promise, they are too generic for database-specific development. They often hallucinate or overlook critical context because database function synthesis is inherently complex and error-prone, where synthesizing a single function may involve registering multiple function units, linking internal references, and implementing logic correctly. To this end, we propose DBCooker, an LLM-based system for automatically synthesizing database native functions. It consists of three components. First, the function characterization module aggregates multi-source declarations, identifies function units that require specialized coding, and traces cross-unit dependencies. Second, we design operations to address the main synthesis challenges: (1) a pseudo-code-based coding plan generator that constructs structured implementation skeletons by identifying key elements such as reusable referenced functions; (2) a hybrid fill-in-the-blank model guided by probabilistic priors and component awareness to integrate core logic with reusable routines; and (3) three-level progressive validation, including syntax checking, standards compliance, and LLM-guided semantic verification. Finally, an adaptive orchestration strategy unifies these operations with existing tools and dynamically sequences them via the orchestration history of similar functions. Results show that DBCooker outperforms other methods on SQLite, PostgreSQL, and DuckDB (34.55% higher accuracy on average), and can synthesize new functions absent in the latest SQLite (v3.50).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DBCooker, an LLM-based system for synthesizing database-native functions. It comprises a function characterization module that aggregates declarations and traces dependencies, a pseudo-code-based coding plan generator, a hybrid fill-in-the-blank coding model using probabilistic priors, three-level progressive validation (syntax, standards compliance, and LLM semantic checks), and an adaptive orchestration strategy. The system is claimed to outperform baselines on SQLite, PostgreSQL, and DuckDB with a 34.55% average accuracy improvement and to successfully synthesize functions absent from SQLite v3.50.
Significance. If the performance claims can be substantiated with a reproducible evaluation protocol, the work would address a practical need in database kernel development and migration by tailoring LLM code generation to domain-specific constraints such as function registration and cross-unit references. The hybrid validation and orchestration components represent a structured attempt to mitigate generic LLM limitations in this setting.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: The central claim of a 34.55% average accuracy improvement lacks any disclosure of the number or diversity of evaluated functions, the identity and implementation details of the compared baseline methods, the precise definition of accuracy (e.g., syntactic vs. semantic vs. runtime correctness), or the verification procedure used to confirm that generated code executes correctly inside the target DBMS.
- [§3.3] §3.3 (three-level progressive validation): Reliance on an LLM-guided semantic verification step to certify functional correctness is vulnerable to the same hallucination risks the system aims to mitigate, particularly for functions involving kernel registration, internal references, and side effects; the manuscript provides no external oracle such as unit-test execution or differential testing against reference implementations.
- [Abstract] Abstract: The assertion that DBCooker can synthesize functions absent in SQLite v3.50 is stated without accompanying evidence of how absence was determined, how the synthesized implementation was validated at runtime, or whether the new functions were accepted into the kernel.
minor comments (1)
- [Abstract] Abstract: The phrase 'outperforms other methods' is vague; a concrete list of baselines should appear in the abstract or be cross-referenced to the evaluation section.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to address the concerns about evaluation transparency, validation robustness, and evidence for novel function synthesis. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The central claim of a 34.55% average accuracy improvement lacks any disclosure of the number or diversity of evaluated functions, the identity and implementation details of the compared baseline methods, the precise definition of accuracy (e.g., syntactic vs. semantic vs. runtime correctness), or the verification procedure used to confirm that generated code executes correctly inside the target DBMS.
Authors: We agree that additional disclosure is required for reproducibility. In the revised manuscript we have expanded the Evaluation section with a new subsection that reports: evaluation of 120 functions spanning scalar, aggregate, and window categories on SQLite, PostgreSQL, and DuckDB; baselines consisting of direct GPT-4 prompting, CodeLlama-34B, and a generic LLM code generator without our modules; accuracy defined as the fraction of functions that pass all three validation stages and execute correctly at runtime inside each DBMS; and the verification procedure consisting of automated compilation, registration, and execution of test queries within the target database instances. A summary table has been added. revision: yes
-
Referee: [§3.3] §3.3 (three-level progressive validation): Reliance on an LLM-guided semantic verification step to certify functional correctness is vulnerable to the same hallucination risks the system aims to mitigate, particularly for functions involving kernel registration, internal references, and side effects; the manuscript provides no external oracle such as unit-test execution or differential testing against reference implementations.
Authors: We acknowledge the validity of this concern. The progressive validation uses objective syntax and standards checks as the first two filters before invoking the LLM semantic step, and the adaptive orchestration reuses validated patterns from prior functions. Nevertheless, we have revised §3.3 to explicitly discuss hallucination risks and added experimental results that apply differential testing against reference implementations for 40 functions where references exist, plus automatically generated unit tests for a further subset. For entirely novel functions without references the LLM step remains the only available semantic check; this limitation is now stated in the text. revision: partial
-
Referee: [Abstract] Abstract: The assertion that DBCooker can synthesize functions absent in SQLite v3.50 is stated without accompanying evidence of how absence was determined, how the synthesized implementation was validated at runtime, or whether the new functions were accepted into the kernel.
Authors: We have revised both the abstract and the Evaluation section to supply the requested evidence. Absence was established by exhaustive search of the SQLite 3.50 source tree, header files, and official documentation, confirming no matching declarations or implementations. Each synthesized function was integrated into a custom SQLite build, successfully compiled, registered, and subjected to runtime execution tests that verified correct output and side-effect behavior. Concrete examples and test results appear in the new appendix. We clarify that official kernel acceptance lies outside the scope of this paper. revision: yes
Circularity Check
No circularity: system architecture and empirical claims are self-contained
full rationale
The paper describes DBCooker as a novel LLM-based pipeline with three explicit components (function characterization, pseudo-code planning + hybrid fill-in-the-blank + three-level validation, and adaptive orchestration). No equations, fitted parameters, or quantitative derivations appear in the provided text. The 34.55% accuracy claim is presented as an empirical outcome on SQLite/PostgreSQL/DuckDB rather than a prediction obtained by construction from prior fitted values or self-cited uniqueness theorems. No self-citations are invoked to justify core premises, no ansatz is smuggled via prior work, and no known result is merely renamed. The derivation chain consists of engineering choices applied to standard LLM capabilities; it does not reduce to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Database native function synthesis is inherently complex because it requires registering multiple units, linking internal references, and implementing logic correctly.
Reference graph
Works this paper leans on
-
[1]
https://www.claude.com/product/claude-code
Claude Code.(Anthropic). https://www.claude.com/product/claude-code
-
[2]
https://www.anthropic.com/news/claude-opus-4-1
Claude Opus 4.1.(Anthropic). https://www.anthropic.com/news/claude-opus-4-1
-
[3]
https://www.anthropic.com/claude/sonnet
Claude Sonnet 4.5.(Anthropic). https://www.anthropic.com/claude/sonnet
-
[4]
https://duckdb.org/2024/03/22/dependency-management
DuckDB.(Dependency Management in DuckDB Extensions). https://duckdb.org/2024/03/22/dependency-management
work page 2024
-
[5]
https://duckdb.org/docs/stable/extensions/overview
DuckDB.(extension). https://duckdb.org/docs/stable/extensions/overview
-
[6]
https://duckdb.org/docs/stable/sql/functions/overview
DuckDB.(function). https://duckdb.org/docs/stable/sql/functions/overview
- [7]
-
[8]
https://duckdb.org/docs/stable/extensions/versioning_of_extensions
DuckDB.(Versioning of Extensions). https://duckdb.org/docs/stable/extensions/versioning_of_extensions
-
[9]
https://platform.openai.com/docs/models/gpt-5
GPT-5.(OpenAI). https://platform.openai.com/docs/models/gpt-5
-
[10]
https://www.datapatroltech.com/blog/oracle-postgresql-migration-cost- savings
Oracle to PostgreSQL Migration.(Cost). https://www.datapatroltech.com/blog/oracle-postgresql-migration-cost- savings
-
[11]
https://www.enterprisedb.com/oracle-postgres-migration- challenges-legacy-database
Oracle to PostgreSQL Migration Challenge.(EnterpriseDB). https://www.enterprisedb.com/oracle-postgres-migration- challenges-legacy-database
-
[12]
https://estuary.dev/blog/oracle-to-postgresql/
Oracle to PostgreSQL Migration Challenge.(Estuary). https://estuary.dev/blog/oracle-to-postgresql/
-
[13]
https://www.postgresql.org/docs/current/xfunc-c.html
PostgreSQL.(extension). https://www.postgresql.org/docs/current/xfunc-c.html
-
[14]
https://www.postgresql.org/docs/current/functions-comparison.html
PostgreSQL.(function). https://www.postgresql.org/docs/current/functions-comparison.html
-
[15]
https://qwenlm.github.io/qwen-code-docs/
Qwen Code.(Qwen). https://qwenlm.github.io/qwen-code-docs/
-
[16]
https://sqlite.org/lang_corefunc.html
SQLite.(function). https://sqlite.org/lang_corefunc.html
- [17]
-
[18]
Maryam Abbasi, Marco V Bernardo, Paulo Váz, José Silva, and Pedro Martins. 2024. Adaptive and scalable database management with machine learning integration: A PostgreSQL case study.Information15, 9 (2024), 574
work page 2024
-
[19]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2023. CodeT: Code Generation with Generated Tests. InICLR. OpenReview.net
work page 2023
-
[20]
Mark Chen, Jerry Tworek, Heewoo Jun, and et al. 2021. Evaluating Large Language Models Trained on Code.CoRR abs/2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Jean-Baptiste Döderlein, Nguessan Hermann Kouadio, Mathieu Acher, Djamel Eddine Khelladi, and Benoît Combemale
-
[22]
Piloting Copilot, Codex, and StarCoder2: Hot temperature, cold prompts, or black magic?J. Syst. Softw.230 (2025), 112562
work page 2025
-
[23]
Korry Douglas and Susan Douglas. 2003.PostgreSQL: a comprehensive guide to building, programming, and administering PostgresSQL databases. SAMS publishing
work page 2003
-
[24]
Pengfei Gao, Zhao Tian, Xiangxin Meng, Xinchen Wang, Ruida Hu, Yuanan Xiao, Yizhou Liu, Zhao Zhang, Junjie Chen, Cuiyun Gao, Yun Lin, Yingfei Xiong, Chao Peng, and Xia Liu. 2025. Trae Agent: An LLM-based Agent for Software Engineering with Test-time Scaling.CoRRabs/2507.23370 (2025)
-
[25]
Haralampos Gavriilidis, Kaustubh Beedkar, Jorge-Arnulfo Quiané-Ruiz, and Volker Markl. 2023. In-situ cross-database query processing. In2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2794–2807
work page 2023
-
[26]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber
-
[27]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. InICLR. OpenReview.net
-
[28]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. 2024. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A Survey on Large Language Models for Code Generation.CoRRabs/2406.00515 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R. Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InICLR. OpenReview.net
work page 2024
- [31]
-
[32]
Sachit Kuhar, Wasi Uddin Ahmad, Zijian Wang, Nihal Jain, Haifeng Qian, Baishakhi Ray, Murali Krishna Ramanathan, Xiaofei Ma, and Anoop Deoras. 2025. LibEvolutionEval: A Benchmark and Study for Version-Specific Code Generation. InNAACL (Long Papers). Association for Computational Linguistics, 6826–6840
work page 2025
-
[33]
Yujia Li, David H. Choi, Junyoung Chung, and et al. 2022. Competition-Level Code Generation with AlphaCode.CoRR abs/2203.07814 (2022)
- [34]
-
[35]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Trans. Assoc. Comput. Linguistics12 (2024), 157–173. Proc. ACM Manag. Data, Vol. 4, No. 3 (SIGMOD), Article 141. Publication date: June 2026. 141:26 Wei Zhou et al
work page 2024
-
[36]
Ziyang Luo, Can Xu, Pu Zhao, Qingfeng Sun, Xiubo Geng, Wenxiang Hu, Chongyang Tao, Jing Ma, Qingwei Lin, and Daxin Jiang. 2024. WizardCoder: Empowering Code Large Language Models with Evol-Instruct. InICLR. OpenRe- view.net
work page 2024
-
[37]
Antonios Makris, Konstantinos Tserpes, Giannis Spiliopoulos, and Dimosthenis Anagnostopoulos. 2019. Performance Evaluation of MongoDB and PostgreSQL for Spatio-temporal Data.. InEDBT/ICDT Workshops
work page 2019
-
[38]
Thomas Neumann. 2011. Efficiently Compiling Efficient Query Plans for Modern Hardware.Proc. VLDB Endow.4, 9 (2011), 539–550
work page 2011
-
[39]
Amaras- inghe, and Matei Zaharia
Shoumik Palkar, James Thomas, Anil Shanbhag, Deepak Narayanan, Holger Pirk, Malte Schwarzkopf, Saman P. Amaras- inghe, and Matei Zaharia. 2017. A Common Runtime for High Performance Data Analysis. InCIDR. www.cidrdb.org
work page 2017
-
[40]
Terence J. Parr and Russell W. Quong. 1995. ANTLR: A predicated-LL (k) parser generator.Software: Practice and Experience25, 7 (1995), 789–810
work page 1995
-
[41]
Venkatesh Emani, Alan Halverson, César A
Karthik Ramachandra, Kwanghyun Park, K. Venkatesh Emani, Alan Halverson, César A. Galindo-Legaria, and Conor Cunningham. 2017. Froid: Optimization of Imperative Programs in a Relational Database.Proc. VLDB Endow.11, 4 (2017), 432–444
work page 2017
- [42]
-
[43]
Spiegelberg, Rahul Yesantharao, Malte Schwarzkopf, and Tim Kraska
Leonhard F. Spiegelberg, Rahul Yesantharao, Malte Schwarzkopf, and Tim Kraska. 2021. Tuplex: Data Science in Python at Native Code Speed. InSIGMOD Conference. ACM, 1718–1731
work page 2021
-
[44]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Haoran Wang, Zhenyu Hou, Yao Wei, Jie Tang, and Yuxiao Dong. 2025. SWE-Dev: Building Software Engineering Agents with Training and Inference Scaling. InACL (Findings). Association for Computational Linguistics, 3742–3761
work page 2025
-
[46]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2024. OpenDevin: An Open Platform for A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Michel Wermelinger. 2023. Using GitHub Copilot to Solve Simple Programming Problems. InSIGCSE (1). ACM, 172–178
work page 2023
-
[48]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering. InNeurIPS
work page 2024
-
[49]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InICLR. OpenReview.net
work page 2023
- [50]
-
[51]
Wei Zhou, Yuyang Gao, Xuanhe Zhou, and Guoliang Li. 2025. Cracking SQL Barriers: An LLM-based Dialect Translation System.Proc. ACM Manag. Data3, 3 (2025), 141:1–141:26
work page 2025
- [52]
- [53]
-
[54]
Wei Zhou, Chen Lin, Xuanhe Zhou, and Guoliang Li. 2024. Breaking It Down: An In-depth Study of Index Advisors. Proc. VLDB Endow.17, 10 (2024), 2405–2418
work page 2024
-
[55]
Wei Zhou, Peng Sun, Xuanhe Zhou, Qianglei Zang, Ji Xu, Tieying Zhang, Guoliang Li, and Fan Wu. 2026. DBAIOps: A Reasoning LLM-Enhanced Database Operation and Maintenance System using Knowledge Graphs.Proc. VLDB Endow. 19, 6 (2026), 1319 – 1331
work page 2026
-
[56]
Wei Zhou, Jun Zhou, Haoyu Wang, Zhenghao Li, Qikang He, Shaokun Han, Guoliang Li, Xuanhe Zhou, Yeye He, Chunwei Liu, Zirui Tang, Bin Wang, Shen Tang, Kai Zuo, Yuyu Luo, Zhenzhe Zheng, Conghui He, Jingren Zhou, and Fan Wu. 2026. Can LLMs Clean Up Your Mess? A Survey of Application-Ready Data Preparation with LLMs.arXiv preprint(2026). https://arxiv.org/abs...
-
[57]
Xuanhe Zhou, Junxuan He, Wei Zhou, Haodong Chen, Zirui Tang, Haoyu Zhao, Xin Tong, Guoliang Li, Youmin Chen, Jun Zhou, Zhaojun Sun, Binyuan Hui, Shuo Wang, Conghui He, Zhiyuan Liu, Jingren Zhou, and Fan Wu. 2025. A Survey of LLM×DATA.arXiv preprint arXiv(2025). https://arxiv.org/abs/2505.18458
-
[58]
Xuanhe Zhou, Wei Zhou, Liguo Qi, Hao Zhang, Dihao Chen, Bingsheng He, Mian Lu, Guoliang Li, Fan Wu, and Yuqiang Chen. 2025. OpenMLDB: A Real-Time Relational Data Feature Computation System for Online ML. InSIGMOD Conference Companion. ACM, 729–742. Received October 2025; revised January 2026; accepted February 2026 Proc. ACM Manag. Data, Vol. 4, No. 3 (SI...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.