Consensus Entropy: Harnessing Multi-VLM Agreement for Self-Verifying and Self-Improving OCR
Pith reviewed 2026-05-22 20:25 UTC · model grok-4.3
The pith
Multi-VLM agreement entropy verifies OCR quality and enables self-improvement without training or labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
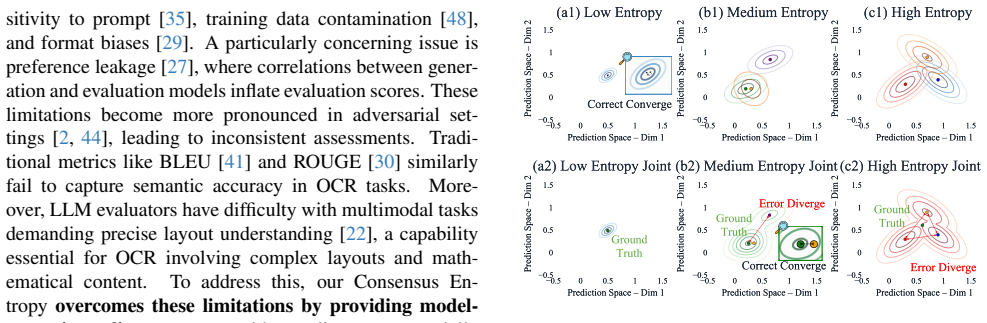
Consensus Entropy estimates OCR reliability by computing the entropy of the output distribution across an ensemble of VLMs; because correct predictions converge in output space while errors diverge, the resulting scalar serves as an unsupervised quality score that enables verification, best-output selection, and adaptive routing in the CE-OCR framework.
What carries the argument
Consensus Entropy: the entropy of the empirical distribution of distinct OCR strings returned by multiple VLMs on the same image.
If this is right
- Quality verification reaches 42.1 percent higher F1 than VLM-as-Judge.
- CE-OCR raises OCR accuracy over self-consistency and single-model baselines at identical cost.
- The method integrates plug-and-play with any set of VLMs and needs no supervision.
- Adaptive routing based on entropy reduces compute on high-agreement samples.
Where Pith is reading between the lines
- The same agreement-entropy signal could be tested on other multimodal generation tasks such as captioning or chart parsing.
- Large-scale curation pipelines for LLM training data could filter OCR-derived text automatically using only model disagreement.
- If the convergence property persists when newer VLMs are added to the ensemble, accuracy gains would compound without changing the metric.
Load-bearing premise
Correct OCR predictions from different VLMs converge in output space while errors cause divergence, supplying a reliable quality signal.
What would settle it
On a held-out OCR dataset with ground-truth labels, high-entropy (low-agreement) samples show lower error rates than low-entropy samples, or the correlation between entropy and error rate is near zero.
Figures




read the original abstract
Optical Character Recognition (OCR) is fundamental to Vision-Language Models (VLMs) and high-quality data generation for LLM training. Yet, despite progress in average OCR accuracy, state-of-the-art VLMs still struggle with detecting sample-level errors and lack effective unsupervised quality control. We introduce Consensus Entropy (CE), a training-free, model-agnostic metric that estimates output reliability by measuring inter-model agreement entropy. The core insight is that correct predictions converge in output space, while errors diverge. Based on CE, we develop CE-OCR, a lightweight multi-model framework that verifies outputs by ensemble agreement, selects the best outputs, and further improves efficiency through adaptive routing. Experiments demonstrate that CE is robust for quality verification, improving F1 scores by 42.1% over VLM-as-Judge. CE-OCR achieves consistent OCR gains, outperforming self-consistency and single-model baselines at the same cost. Notably, CE requires no training or supervision, enabling plug-and-play integration. Code: https://github.com/Aslan-yulong/consensus-entropy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Consensus Entropy (CE), a training-free, model-agnostic metric for estimating OCR output reliability based on the entropy of agreement among multiple VLMs. The central hypothesis is that correct predictions converge in output space while errors diverge. Using CE, they introduce CE-OCR for verification, selection, and adaptive routing, reporting a 42.1% F1 improvement over VLM-as-Judge and consistent gains over baselines at equivalent cost, with open code provided.
Significance. If the convergence assumption holds across models and datasets, this represents a meaningful contribution to unsupervised quality control in OCR for VLMs, with potential impact on data generation for LLM training. The work is strengthened by its parameter-free nature, reproducibility via the linked GitHub repository, and empirical gains demonstrated against explicit baselines.
major comments (2)
- [§3.2] §3.2 (Consensus Entropy definition): The paper does not provide a formal characterization of the output-space distance or agreement function used to compute entropy over variable-length OCR strings (e.g., exact lexical match, normalized edit distance, or embedding similarity). This is load-bearing for the central claim because the entropy signal's ability to track correctness versus spurious consensus depends directly on this choice.
- [§5.3] §5.3 (Robustness experiments): While aggregate F1 and accuracy gains are reported, there is no dedicated ablation or failure-case analysis on inputs where correlated model biases are likely (low-contrast text, rare glyphs, layout ambiguities). This leaves the weakest assumption untested at the level required to support the 42.1% gain claim as a general unsupervised signal.
minor comments (3)
- [Abstract] Abstract: The phrase 'inter-model agreement entropy' is introduced without a one-sentence indication of the underlying string comparison method.
- [Table 2] Table 2: The cost column should explicitly state the number of VLM calls per sample for each baseline to make the 'same cost' comparison transparent.
- [§4.1] §4.1: The adaptive routing threshold is described in prose; an equation would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Consensus Entropy definition): The paper does not provide a formal characterization of the output-space distance or agreement function used to compute entropy over variable-length OCR strings (e.g., exact lexical match, normalized edit distance, or embedding similarity). This is load-bearing for the central claim because the entropy signal's ability to track correctness versus spurious consensus depends directly on this choice.
Authors: We agree that a formal characterization strengthens the central claim. The manuscript computes agreement via normalized Levenshtein distance (with a fixed threshold for binary agreement) to accommodate variable-length strings; we will revise §3.2 to include the precise mathematical definition of the agreement function, the resulting distribution over which entropy is taken, and a brief justification for the choice over alternatives such as embedding cosine similarity. revision: yes
-
Referee: [§5.3] §5.3 (Robustness experiments): While aggregate F1 and accuracy gains are reported, there is no dedicated ablation or failure-case analysis on inputs where correlated model biases are likely (low-contrast text, rare glyphs, layout ambiguities). This leaves the weakest assumption untested at the level required to support the 42.1% gain claim as a general unsupervised signal.
Authors: We acknowledge that targeted failure-case analysis would provide stronger support for the convergence assumption. While the reported experiments already span datasets containing low-contrast and ambiguous samples, we will add a dedicated subsection to §5.3 with quantitative ablations on low-contrast text, rare glyphs, and layout ambiguities, reporting CE scores and downstream F1 under these conditions. revision: yes
Circularity Check
No circularity: CE is defined directly from observed inter-model disagreement as an external agreement metric.
full rationale
The paper introduces Consensus Entropy as a training-free metric computed from inter-VLM output agreement entropy, with no parameters fitted to target correctness labels, no self-citations invoked as load-bearing uniqueness theorems, and no reduction of predictions to fitted inputs by construction. The convergence assumption is presented as an empirical hypothesis tested on benchmarks rather than smuggled in via definition or prior self-work. The derivation chain remains self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Correct predictions from different VLMs converge in output space while errors diverge.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost_pos_of_ne_one echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
correct predictions converge in output space, while errors diverge... Consensus Entropy (CE), a training-free, model-agnostic metric that estimates output reliability by measuring inter-model agreement entropy
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Low CE indicates high agreement and reliability; high CE signals ambiguity and potential error
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
High-Entropy Tokens as Multimodal Failure Points in Vision-Language Models
High-entropy tokens act as concentrated multimodal failure points in VLMs, enabling sparse Entropy-Guided Attacks that achieve 93-95% success and 30-38% harmful rates with cross-model transfer.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Llm-safety evaluations lack robustness, 2025
Tim Beyer, Sophie Xhonneux, Simon Geisler, Gauthier Gidel, Leo Schwinn, and Stephan G ¨unnemann. Llm-safety evaluations lack robustness, 2025. 3
work page 2025
-
[3]
Nougat: Neural Optical Understanding for Academic Documents
Lukas Blecher, Guillem Cucurull, Thomas Scialom, and Robert Stojnic. Nougat: Neural optical understanding for academic documents.arXiv:2308.13418, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large lan- guage models.ACM transactions on intelligent systems and technology, 15(3):1–45, 2024. 2
work page 2024
-
[5]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi- lingual, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation, 2024. 5, 8
work page 2024
-
[6]
Kedi Chen, Qin Chen, Jie Zhou, Xinqi Tao, Bowen Ding, Jingwen Xie, Mingchen Xie, Peilong Li, Feng Zheng, and Liang He. Enhancing uncertainty modeling with se- mantic graph for hallucination detection.arXiv preprint arXiv:2501.02020, 2025. 3
-
[7]
Beyond factuality: A comprehensive evaluation of large lan- guage models as knowledge generators
Liang Chen, Yang Deng, Yatao Bian, Zeyu Qin, and et al. Beyond factuality: A comprehensive evaluation of large lan- guage models as knowledge generators. InEMNLP 2023, pages 6325–6341. Association for Computational Linguis- tics, 2023. 3
work page 2023
-
[8]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhang- wei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test- time scaling.arXiv preprint arXiv:2412.05271, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhang- wei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites.Science China Information Sciences, 67(12):220101,
-
[10]
Zhijun Chen, Jingzheng Li, Pengpeng Chen, Zhuoran Li, Kai Sun, Yuankai Luo, Qianren Mao, Dingqi Yang, Hailong Sun, and Philip S. Yu. Harnessing multiple large language mod- els: A survey on llm ensemble, 2025. 3, 9
work page 2025
-
[11]
Collective reasoning among llms a framework for answer validation without ground truth, 2025
Seyed Pouyan Mousavi Davoudi, Alireza Shafiee Fard, and Alireza Amiri-Margavi. Collective reasoning among llms a framework for answer validation without ground truth, 2025. 9
work page 2025
-
[12]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024. 5
work page 2024
-
[13]
Post-processing techniques applied to speech recognition output
Jonathan G Fiscus. Post-processing techniques applied to speech recognition output. InDARPA Speech Recognition Workshop, pages 59–62, 1997. Also known as ROVER (Rec- ognizer Output V oting Error Reduction). 5, 8
work page 1997
-
[14]
Ling Fu, Biao Yang, Zhebin Kuang, Jiajun Song, Yuzhe Li, Linghao Zhu, Qidi Luo, Xinyu Wang, Hao Lu, Mingxin Huang, Zhang Li, Guozhi Tang, Bin Shan, Chunhui Lin, Qi Liu, Binghong Wu, Hao Feng, Hao Liu, Can Huang, Jingqun Tang, Wei Chen, Lianwen Jin, Yuliang Liu, and Xiang Bai. Ocrbench v2: An improved benchmark for evaluating large multimodal models on vis...
-
[15]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. Ininternational conference on machine learning, pages 1050–1059. PMLR, 2016. 3
work page 2016
-
[16]
Zhangwei Gao, Zhe Chen, Erfei Cui, Yiming Ren, Weiyun Wang, Jinguo Zhu, Hao Tian, Shenglong Ye, Junjun He, Xizhou Zhu, et al. Mini-internvl: a flexible-transfer pocket multi-modal model with 5% parameters and 90% perfor- mance.Visual Intelligence, 2(1):1–17, 2024. 2
work page 2024
-
[17]
Chatglm: A family of large language mod- els from glm-130b to glm-4 all tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page 2024
-
[18]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xue- hao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.arXiv preprint arXiv:2411.15594, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Smoothie: Label free language model routing
Neel Guha, Mayee F Chen, Trevor Chow, Ishan S Khare, and Christopher Re. Smoothie: Label free language model routing. InNeuIPS, 2024. 3
work page 2024
-
[21]
Conghui He, Wei Li, Zhenjiang Jin, Chao Xu, Bin Wang, and Dahua Lin. Opendatalab: Empowering general ar- 9 tificial intelligence with open datasets.arXiv preprint arXiv:2407.13773, 2024. 2
-
[22]
Layoutlmv3: Pre-training for document ai with unified text and image masking
Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. Layoutlmv3: Pre-training for document ai with unified text and image masking. InProceedings of the 30th ACM international conference on multimedia, pages 4083–4091,
-
[23]
Yuheng Huang, Jiayang Song, Zhijie Wang, Huaming Chen, and Lei Ma. Look before you leap: An exploratory study of uncertainty measurement for large language models.CoRR, abs/2307.10236, 2023. 3
-
[24]
Llm- blender: Ensembling large language models with pairwise ranking and generative fusion
Dongfu Jiang, Xiang Ren, and Bill Yuchen Lin. Llm- blender: Ensembling large language models with pairwise ranking and generative fusion. InACL, 2023. 3
work page 2023
-
[25]
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision?Advances in neural information processing systems, 30, 2017. 3
work page 2017
-
[26]
Prometheus: Inducing fine- grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sung- dong Kim, James Thorne, et al. Prometheus: Inducing fine- grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representa- tions, 2023. 2
work page 2023
-
[27]
Preference leakage: A contamination problem in llm- as-a-judge, 2025
Dawei Li, Renliang Sun, Yue Huang, Ming Zhong, Bohan Jiang, Jiawei Han, Xiangliang Zhang, Wei Wang, and Huan Liu. Preference leakage: A contamination problem in llm- as-a-judge, 2025. 3
work page 2025
-
[28]
Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and De- heng Ye. More agents is all you need.arXiv preprint arXiv:2402.05120, 2024. 3
-
[29]
Evaluating object hallucination in large vision- language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision- language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292–305, 2023. 3
work page 2023
-
[30]
ROUGE: A package for automatic evaluation of summaries
Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, Barcelona, Spain, 2004. Association for Computa- tional Linguistics. 3
work page 2004
-
[31]
Focus anywhere for fine- grained multi-page document understanding
Chenglong Liu, Haoran Wei, Jinyue Chen, Lingyu Kong, Zheng Ge, Zining Zhu, Liang Zhao, Jianjian Sun, Chunrui Han, and Xiangyu Zhang. Focus anywhere for fine-grained multi-page document understanding.arXiv:2405.14295,
-
[32]
Visual instruction tuning, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. 2
work page 2023
-
[33]
Uncertainty quantification and confidence calibration in large language models: A survey, 2025
Xiaoou Liu, Tiejin Chen, Longchao Da, Chacha Chen, Zhen Lin, and Hua Wei. Uncertainty quantification and confidence calibration in large language models: A survey, 2025. 3
work page 2025
-
[34]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models.Science China Information Sciences, 67(12), 2024. 2, 5
work page 2024
-
[35]
Calibrating llm-based evaluator
Yuxuan Liu, Tianchi Yang, Shaohan Huang, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Calibrating llm-based evaluator. InProceed- ings of the 2024 Joint International Conference on Com- putational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 2638–2656, 2024. 3
work page 2024
-
[36]
Patrice Lopez. Grobid.https : / / github . com / kermitt2/grobid, 2008–2025. 2
work page 2008
-
[37]
Urg: A unified ranking and generation method for ensembling language models
Bo Lv, Chen Tang, Yanan Zhang, Xin Liu, Ping Luo, and Yue Yu. Urg: A unified ranking and generation method for ensembling language models. InFindings of the ACL, 2024. 3
work page 2024
-
[38]
Potsawee Manakul, Adian Liusie, and Mark J. F. Gales. Self- checkgpt: Zero-resource black-box hallucination detection for generative large language models. InEMNLP 2023, pages 9004–9017. Association for Computational Linguis- tics, 2023. 3
work page 2023
-
[39]
His- torical review of ocr research and development.Proceedings of the IEEE, 80(7):1029–1058, 1992
Shunji Mori, Ching Y Suen, and Kazuhiko Yamamoto. His- torical review of ocr research and development.Proceedings of the IEEE, 80(7):1029–1058, 1992. 2
work page 1992
-
[40]
Gpt-4o technical overview.https://openai
OpenAI. Gpt-4o technical overview.https://openai. com/index/gpt- 4o- system- card/, 2024. Ac- cessed: 2025-04-06. 2, 5
work page 2024
-
[41]
Bleu: a method for automatic evaluation of machine translation
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. InProceedings of the 40th annual meeting of the Association for Computational Linguistics, pages 311–318,
-
[42]
Un- certainty quantification via stable distribution propagation,
Felix Petersen, Aashwin Mishra, Hilde Kuehne, Christian Borgelt, Oliver Deussen, and Mikhail Yurochkin. Un- certainty quantification via stable distribution propagation,
-
[43]
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models, 2025
Jake Poznanski, Jon Borchardt, Jason Dunkelberger, Regan Huff, Daniel Lin, Aman Rangapur, Christopher Wilhelm, Kyle Lo, and Luca Soldaini. olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models, 2025. 2
work page 2025
-
[44]
Adversarial ml problems are getting harder to solve and to evaluate, 2025
Javier Rando, Jie Zhang, Nicholas Carlini, and Florian Tram`er. Adversarial ml problems are getting harder to solve and to evaluate, 2025. 3
work page 2025
-
[45]
Zejiang Shen, Kyle Lo, Lucy Lu Wang, Bailey Kuehl, Daniel S Weld, and Doug Downey. Vila: Improving struc- tured content extraction from scientific pdfs using visual lay- out groups.Transactions of the Association for Computa- tional Linguistics, 10:376–392, 2022. 2
work page 2022
-
[46]
Getting more out of mixture of lan- guage model reasoning experts
Chenglei Si, Weijia Shi, Chen Zhao, Luke Zettlemoyer, and Jordan Boyd-Graber. Getting more out of mixture of lan- guage model reasoning experts. InFindings of EMNLP,
-
[47]
Bernard W Silverman.Density estimation for statistics and data analysis. Routledge, 2018. 3
work page 2018
-
[48]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri `a Garriga- Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models.arXiv preprint arXiv:2206.04615, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Llm-topla: Efficient llm ensemble by maximising diversity
Selim Tekin, Fatih Ilhan, Tiansheng Huang, Sihao Hu, and Ling Liu. Llm-topla: Efficient llm ensemble by maximising diversity. InFindings of EMNLP, 2024. 3 10
work page 2024
-
[51]
Mineru: An open-source solution for precise document content extrac- tion, 2024
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, Bo Zhang, Liqun Wei, Zhihao Sui, Wei Li, Botian Shi, Yu Qiao, Dahua Lin, and Conghui He. Mineru: An open-source solution for precise document content extrac- tion, 2024. 2
work page 2024
-
[52]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Jun- yang Lin. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Yiming Wang, Pei Zhang, Baosong Yang, Derek F Wong, and Rui Wang. Latent space chain-of-embedding en- ables output-free llm self-evaluation.arXiv preprint arXiv:2410.13640, 2024. 3, 9
-
[55]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
Haoran Wei, Chenglong Liu, Jinyue Chen, Jia Wang, Lingyu Kong, Yanming Xu, Zheng Ge, Liang Zhao, Jianjian Sun, Yuang Peng, et al. General ocr theory: Towards ocr-2.0 via a unified end-to-end model.arXiv:2409.01704, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Can LLMs express their un- certainty? an empirical evaluation of confidence elicitation in LLMs
Miao Xiong, Zhiyuan Hu, Xinyang Lu, YIFEI LI, Jie Fu, Junxian He, and Bryan Hooi. Can LLMs express their un- certainty? an empirical evaluation of confidence elicitation in LLMs. InThe Twelfth International Conference on Learn- ing Representations, 2024. 3
work page 2024
-
[57]
Pub- laynet: largest dataset ever for document layout analysis
Zhong Xu, Jianbin Tang, and Antonio Jimeno Yepes. Pub- laynet: largest dataset ever for document layout analysis. In2019 International conference on document analysis and recognition, pages 1015–1022, 2019. 2
work page 2019
-
[58]
Zhibo Yang, Jun Tang, Zhaohai Li, Pengfei Wang, Jianqiang Wan, Humen Zhong, Xuejing Liu, Mingkun Yang, Peng Wang, Shuai Bai, LianWen Jin, and Junyang Lin. Cc-ocr: A comprehensive and challenging ocr benchmark for evalu- ating large multimodal models in literacy, 2024. 2, 5
work page 2024
-
[59]
Ruiyang Zhang, Hu Zhang, and Zhedong Zheng. Vl- uncertainty: Detecting hallucination in large vision-language model via uncertainty estimation, 2024. 3
work page 2024
-
[60]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in Neural Information Processing Systems, 36:46595–46623, 2023. 2
work page 2023
-
[61]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint, 2023
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint, 2023. 2 11
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.