Circle-RoPE: Cone-like Decoupled Rotary Positional Embedding for Large Vision-Language Models
Pith reviewed 2026-05-22 14:14 UTC · model grok-4.3
The pith
Circle-RoPE remaps 2D image coordinates to an orthogonal annulus so that every text token sits at equal distance from all image tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
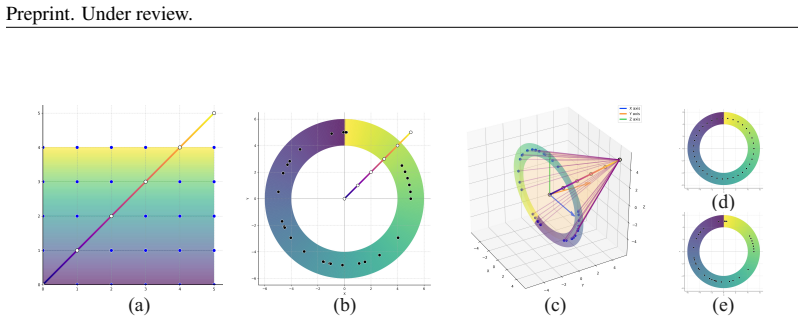
PTD equals zero is a sufficient condition to eliminate the geometric attention bias induced by RoPE. Circle-RoPE achieves this zero by remapping every 2D image-token coordinate onto an annulus that is orthogonal to the text position axis, producing a cone-like geometry in which each text token is equidistant to all image tokens while the relative positions inside the image remain unchanged. Alternating Geometry Encoding then interleaves this cone geometry with standard RoPE on alternate layers.
What carries the argument
The annulus remapping that forces image positions into a plane orthogonal to the text axis, thereby setting Per-Token Distance to zero and producing cone-like equidistance.
If this is right
- Spatial grounding and visual reasoning scores rise consistently across different VLM architectures and multimodal benchmarks.
- Intra-image spatial structure is retained while cross-modal positional coupling disappears.
- Alternating the new geometry with standard RoPE supplies complementary priors that neither method provides alone.
Where Pith is reading between the lines
- The same annulus construction could be tested on other multimodal settings such as video or audio tokens to check whether the cone geometry generalizes beyond static images.
- If the zero-PTD condition proves robust, it may simplify the design of future positional encodings that must handle mixed sequences of different modalities.
Load-bearing premise
The geometric construction of the annulus and cone will not create new cross-modal biases or harm intra-image spatial relations once the embeddings are used inside real transformer attention layers.
What would settle it
Running the same VLM backbone with and without Circle-RoPE on a spatial-grounding benchmark and observing no improvement, or directly computing attention scores from text tokens to image tokens and finding that scores still vary systematically with image coordinates.
Figures


read the original abstract
Rotary Position Embedding (RoPE) is widely adopted in large language models, but when applied to vision-language models (VLMs) it couples text and image position indices and can introduce spurious cross-modal relative-position bias. We propose Per-Token Distance (PTD) to quantify cross-modal positional disentanglement, and prove that PTD = 0 is a sufficient condition to eliminate the geometric attention bias induced by RoPE. Guided by this criterion, we introduce Circle-RoPE, which remaps 2D image-token coordinates onto an annulus orthogonal to the text position axis, yielding a cone-like geometry where each text token is equidistant to all image tokens while preserving intra-image spatial structure. We further propose Alternating Geometry Encoding (AGE) to combine complementary geometric priors by alternating the decoupled geometry of Circle-RoPE and the grid-based prior of standard RoPE across layers. This design enables cross-modal positional disentanglement while preserving fine-grained intra-image spatial structure. Experiments on diverse VLM backbones and multimodal benchmarks show consistent gains in spatial grounding and visual reasoning. The code is available at https://github.com/lose4578/CircleRoPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript defines a Per-Token Distance (PTD) metric to quantify cross-modal positional disentanglement under RoPE, proves that PTD = 0 is a sufficient condition for eliminating geometric attention bias, and introduces Circle-RoPE that remaps 2D image tokens onto an annulus orthogonal to the text-position axis to realize a cone-like geometry in which every text token is equidistant from all image tokens while preserving intra-image spatial relations. It further proposes Alternating Geometry Encoding (AGE) that interleaves Circle-RoPE with standard grid RoPE across layers. Experiments on multiple VLM backbones report consistent gains on spatial-grounding and visual-reasoning benchmarks.
Significance. If the geometric construction and the PTD = 0 sufficiency result translate to the effective attention logits inside a trained multi-head transformer, the method offers a principled, parameter-light way to mitigate a known source of cross-modal bias in VLMs without discarding the spatial inductive bias that RoPE provides for vision. The open-source implementation is a clear strength for reproducibility.
major comments (2)
- [§3.2, Theorem 1] §3.2, Theorem 1 and the subsequent derivation of the annulus mapping: the proof that PTD = 0 eliminates geometric bias is conducted on raw position vectors before any linear projections. It therefore does not establish that the same zero-bias property holds for the actual attention scores after the learned W_Q and W_K matrices and per-head frequency assignments are applied; a concrete counter-example or extension showing invariance under these transformations would be required to support the central claim.
- [§4.3] §4.3, the AGE alternation schedule: because Circle-RoPE and standard RoPE are applied in alternating layers, the PTD = 0 property is only guaranteed in the Circle-RoPE layers. The manuscript provides no analysis of whether the intervening standard-RoPE layers re-couple the modalities or whether the learned projections can compensate for the alternation, which directly affects whether the claimed cross-modal disentanglement is preserved through the full network depth.
minor comments (2)
- [Figure 2] Figure 2: the visual depiction of the cone-like geometry would be clearer if the text-position axis were explicitly labeled and the annulus radius parameter were tied to an equation number.
- [§5] The experimental section would benefit from an ablation that isolates the contribution of the annulus remapping from the AGE schedule so that readers can attribute gains specifically to the PTD = 0 condition.
Simulated Author's Rebuttal
We thank the referee for the thorough review and valuable suggestions. We address the major comments point by point below, proposing revisions where appropriate to strengthen the theoretical and empirical support for our claims.
read point-by-point responses
-
Referee: [§3.2, Theorem 1] §3.2, Theorem 1 and the subsequent derivation of the annulus mapping: the proof that PTD = 0 eliminates geometric bias is conducted on raw position vectors before any linear projections. It therefore does not establish that the same zero-bias property holds for the actual attention scores after the learned W_Q and W_K matrices and per-head frequency assignments are applied; a concrete counter-example or extension showing invariance under these transformations would be required to support the central claim.
Authors: We appreciate this observation. Theorem 1 proves sufficiency of PTD=0 for eliminating geometric bias at the level of positional encodings. Since RoPE rotations are applied to the projected query and key vectors, and the projections are position-independent linear maps, the relative positional angles determine the bias term in the attention computation. We will revise §3.2 to explicitly state that the zero-bias property pertains to the positional contribution and provide a brief extension demonstrating that the uniformity holds post-projection under standard RoPE frequency settings. We will also include empirical attention visualization to support the claim in practice. revision: yes
-
Referee: [§4.3] §4.3, the AGE alternation schedule: because Circle-RoPE and standard RoPE are applied in alternating layers, the PTD = 0 property is only guaranteed in the Circle-RoPE layers. The manuscript provides no analysis of whether the intervening standard-RoPE layers re-couple the modalities or whether the learned projections can compensate for the alternation, which directly affects whether the claimed cross-modal disentanglement is preserved through the full network depth.
Authors: We agree that the alternation means the PTD=0 property is layer-specific. The design of AGE aims to let the model integrate both the decoupled cross-modal geometry and the intra-image grid structure. In the revised manuscript, we will add a new subsection or appendix with analysis of the effective cross-modal distances across layers, possibly using the PTD metric on intermediate representations or attention patterns from trained models to assess if re-coupling occurs and how the projections mitigate it. revision: yes
Circularity Check
No circularity: derivation is a direct geometric construction from newly defined criterion
full rationale
The paper defines Per-Token Distance (PTD) as a new metric to quantify cross-modal positional disentanglement, proves PTD=0 suffices to remove geometric attention bias via coordinate analysis, and constructs Circle-RoPE by remapping image tokens to an annulus orthogonal to the text axis so that equidistance holds by explicit coordinate choice. This satisfies the defined criterion by design rather than by fitting parameters to outputs or reducing via self-citation chains. AGE alternation and experiments on external benchmarks provide independent content. No load-bearing step collapses to its own inputs by construction; the central claim is a proposed architecture guided by the metric, not a tautological renaming or fitted prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PTD = 0 is a sufficient condition to eliminate geometric attention bias induced by RoPE
invented entities (1)
-
Circle-RoPE annulus mapping
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
project image token indices onto a ring that is orthogonal to the linear axis of text token indices, thereby forming a cone-like structure... each text token (point on the linear text axis) becomes the apex of a cone and maintains an equal distance to all image tokens (points on the circular image ring)
-
IndisputableMonolith/Foundation/AlexanderDualityProof.leanlinking_forces_d3_cert echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
PTD = 0 is a sufficient condition to eliminate the geometric attention bias induced by RoPE... yielding a cone-like geometry where each text token is equidistant to all image tokens while preserving intra-image spatial structure
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Mitigating Mask Prior Drift and Positional Attention Collapse in Large Diffusion Vision-Language Models
Mask prior drift and positional attention collapse cause failures in LDVLMs for long generations, fixed by training-free Mask Prior Suppression and Monotonic RoPE Scaling.
-
Mitigating Mask Prior Drift and Positional Attention Collapse in Large Diffusion Vision-Language Models
Diagnoses mask prior drift and positional attention collapse in LDVLMs and introduces two plug-and-play decoding interventions that raise long-form generation quality without retraining.
-
MODIX: A Training-Free Multimodal Information-Driven Positional Index Scaling for Vision-Language Models
MODIX dynamically rescales positional indices in VLMs using intra-modal covariance-based entropy and inter-modal alignment scores to allocate finer granularity to informative content.
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone, 2024.URL https://arxiv. org/abs/2404.14219, 2024. 10 Preprint. Under review
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Are We on the Right Way for Evaluating Large Vision-Language Models?
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision-language models?arXiv preprint arXiv:2403.20330, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shen- glong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Scalable vision language model training via high quality data curation
Hongyuan Dong, Zijian Kang, Weijie Yin, Xiao Liang, Chao Feng, and Jiao Ran. Scalable vision language model training via high quality data curation.arXiv preprint arXiv:2501.05952, 2025
-
[6]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models, 2024
Haodong Duan, Junming Yang, Yuxuan Qiao, Xinyu Fang, Lin Chen, Yuan Liu, Xiaoyi Dong, Yuhang Zang, Pan Zhang, Jiaqi Wang, Dahua Lin, and Kai Chen. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models, 2024. URL https://arxiv.org/abs/ 2407.11691
-
[7]
On path to multimodal generalist: General-level and general-bench, 2025
Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, Qingyu Shi, Zhiyuan Zhou, Liangtao Shi, Minghe Gao, Daoan Zhang, Zhiqi Ge, Weiming Wu, Siliang Tang, Kaihang Pan, Yaobo Ye, Haobo Yuan, Tao Zhang, Tianjie Ju, Zixiang Meng, Shilin Xu, Liyu Jia, Wentao Hu, Meng Luo, Jiebo Luo, Tat-Seng...
-
[8]
Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale
Jarvis Guo, Tuney Zheng, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Yizhi Li, Graham Neubig, Wenhu Chen, and Xiang Yue. Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale.arXiv preprint arXiv:2412.05237, 2024
-
[9]
A diagram is worth a dozen images
Aniruddha Kembhavi, Mike Salvato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. InComputer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14, pp. 235–251. Springer, 2016
work page 2016
-
[10]
Weixian Lei, Jiacong Wang, Haochen Wang, Xiangtai Li, Jun Hao Liew, Jiashi Feng, and Zilong Huang. The scalability of simplicity: Empirical analysis of vision-language learning with a single transformer, 2025. URLhttps://arxiv.org/abs/2504.10462
-
[11]
Transformer-based visual segmentation: A survey
Xiangtai Li, Henghui Ding, Haobo Yuan, Wenwei Zhang, Jiangmiao Pang, Guangliang Cheng, Kai Chen, Ziwei Liu, and Chen Change Loy. Transformer-based visual segmentation: A survey. IEEE transactions on pattern analysis and machine intelligence, 2024
work page 2024
-
[12]
Baichuan-omni-1.5 technical report
Yadong Li, Jun Liu, Tao Zhang, Song Chen, Tianpeng Li, Zehuan Li, Lijun Liu, Lingfeng Ming, Guosheng Dong, Da Pan, et al. Baichuan-omni-1.5 technical report.arXiv preprint arXiv:2501.15368, 2025
-
[13]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023. URLhttps://arxiv.org/abs/2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Llava-plus: Learning to use tools for creating multimodal agents, 2023
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang, Jianfeng Gao, and Chunyuan Li. Llava-plus: Learning to use tools for creating multimodal agents, 2023. URLhttps://arxiv.org/abs/2311.05437
-
[15]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
Shiyin Lu, Yang Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Han-Jia Ye. Ovis: Structural embedding alignment for multimodal large language model.arXiv preprint arXiv:2405.20797, 2024. 11 Preprint. Under review
- [17]
-
[18]
Miao Rang, Zhenni Bi, Chuanjian Liu, Yehui Tang, Kai Han, and Yunhe Wang. Eve: Efficient multimodal vision language models with elastic visual experts.arXiv preprint arXiv:2501.04322, 2025
-
[19]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
work page 2024
-
[20]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Videorope: What makes for good video rotary position embedding?arXiv preprint arXiv:2502.05173, 2025
Xilin Wei, Xiaoran Liu, Yuhang Zang, Xiaoyi Dong, Pan Zhang, Yuhang Cao, Jian Tong, Haodong Duan, Qipeng Guo, Jiaqi Wang, et al. Videorope: What makes for good video rotary position embedding?arXiv preprint arXiv:2502.05173, 2025
-
[24]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision- language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Grok-1.5 vision preview.https://x.ai/blog/grok-1.5v, 2024
X.AI. Grok-1.5 vision preview.https://x.ai/blog/grok-1.5v, 2024
work page 2024
-
[26]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Jiabo Ye, Haiyang Xu, Haowei Liu, Anwen Hu, Ming Yan, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl3: Towards long image-sequence understanding in multi-modal large language models.arXiv preprint arXiv:2408.04840, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, and Ming-Hsuan Yang. Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos, 2025. URLhttps://arxiv.org/abs/2501.04001
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9556–9567, 2024
work page 2024
-
[30]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, et al. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark.arXiv preprint arXiv:2409.02813, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Pixel-sail: Single transformer for pixel-grounded understanding,
Tao Zhang, Xiangtai Li, Zilong Huang, Yanwei Li, Weixian Lei, Xueqing Deng, Shihao Chen, Shunping Ji, and Jiashi Feng. Pixel-sail: Single transformer for pixel-grounded understanding,
-
[32]
URLhttps://arxiv.org/abs/2504.10465. 12 Preprint. Under review. APPENDIX A FURTHERANALYSIS ANDDISCUSSION A.1 THEADAPTATIONCOST OFINTRODUCINGCIRCLE-ROPE We instantiate Circle-RoPE on the architecturally closest backbone,Qwen2.5-VL, and monitor step- wise training dynamics under SFT. We observed that even minor architectural modifications—such as altering t...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.