HyperAdapt: Simple High-Rank Adaptation
Pith reviewed 2026-05-18 13:39 UTC · model grok-4.3
The pith
HyperAdapt adapts foundation models by scaling rows and columns of each weight matrix with diagonal matrices to produce high-rank updates from only n plus m trainable parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
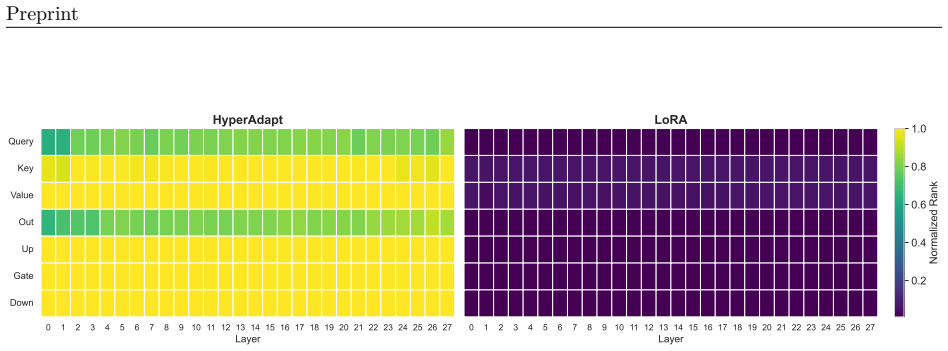
HyperAdapt adapts a pre-trained weight matrix by applying row- and column-wise scaling through diagonal matrices, thereby inducing a high-rank update while requiring only n+m trainable parameters for an n × m matrix. Theoretically, we establish an upper bound on the rank of HyperAdapt's updates, and empirically, we confirm that it consistently induces high-rank transformations across model layers. Experiments on GLUE, arithmetic reasoning, and commonsense reasoning benchmarks with models up to 14B parameters demonstrate that HyperAdapt matches or nearly matches the performance of full fine-tuning and state-of-the-art PEFT methods while using orders of magnitude fewer trainable parameters.
What carries the argument
Row- and column-wise scaling through diagonal matrices applied to a weight matrix to generate the adaptation update.
If this is right
- Fine-tuning large models becomes feasible on hardware with limited memory because only a tiny fraction of parameters require gradients and optimizer states.
- High-rank adaptations can be obtained without paying the full parameter cost or restricting to low-rank forms.
- The same scaling approach works across model sizes up to at least 14 billion parameters on standard language and reasoning tasks.
- Training runs finish with substantially lower compute because the number of updated values scales linearly with matrix dimensions rather than quadratically.
Where Pith is reading between the lines
- The simplicity of diagonal scalings suggests that many adaptation problems may not need intricate low-rank decompositions.
- The method could serve as a lightweight baseline when testing new parameter-efficient techniques on different model families.
- Applying the same row-column scaling idea inside attention or feed-forward blocks might further reduce the parameter budget.
- Testing whether the induced updates remain effective after the model is quantized would show how well the approach combines with other efficiency tools.
Load-bearing premise
That row- and column-wise scaling through diagonal matrices will produce updates whose effective rank and expressivity are sufficient to achieve competitive task performance across diverse benchmarks.
What would settle it
A clear performance drop below full fine-tuning on one of the reported benchmarks or on a new task when the only change is the use of these diagonal scalings instead of updating the full matrix.
Figures




read the original abstract
Foundation models excel across diverse tasks, but adapting them to specialized applications often requires fine-tuning, an approach that is memory and compute-intensive. Parameter-efficient fine-tuning (PEFT) methods mitigate this by updating only a small subset of weights. In this paper, we introduce HyperAdapt, a parameter-efficient fine-tuning method that significantly reduces the number of trainable parameters compared to state-of-the-art methods like LoRA. Specifically, HyperAdapt adapts a pre-trained weight matrix by applying row- and column-wise scaling through diagonal matrices, thereby inducing a high-rank update while requiring only $n+m$ trainable parameters for an $n \times m$ matrix. Theoretically, we establish an upper bound on the rank of HyperAdapt's updates, and empirically, we confirm that it consistently induces high-rank transformations across model layers. Experiments on GLUE, arithmetic reasoning, and commonsense reasoning benchmarks with models up to 14B parameters demonstrate that HyperAdapt matches or nearly matches the performance of full fine-tuning and state-of-the-art PEFT methods while using orders of magnitude fewer trainable parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HyperAdapt, a PEFT method that adapts an n×m pre-trained weight matrix W via row- and column-wise diagonal scalings to produce an update of the form diag(r)W diag(c) − W using only n+m trainable parameters. It derives a theoretical upper bound on the rank of this update, empirically confirms that the resulting transformations are high-rank across layers, and reports that the method matches or nearly matches full fine-tuning and SOTA PEFT baselines on GLUE, arithmetic reasoning, and commonsense reasoning benchmarks with models up to 14B parameters while using orders of magnitude fewer trainable parameters.
Significance. If the empirical results are reproducible, HyperAdapt would constitute a strikingly simple and lightweight PEFT approach that achieves high effective rank with minimal parameters, potentially offering a practical alternative to low-rank methods such as LoRA for adapting large models. The explicit rank bound and high-rank empirical verification are positive features that distinguish it from many existing PEFT techniques.
major comments (3)
- [Abstract, §4] Abstract and §4 (Experiments): the central claim that HyperAdapt 'matches or nearly matches' full fine-tuning performance is presented without reported standard deviations, multiple random seeds, or statistical significance tests across the GLUE and reasoning benchmarks. This information is load-bearing for assessing whether the observed parity is reliable rather than within noise.
- [§3] §3 (Method): the exact update formula (including whether the diagonal matrices are applied as left/right multiplications, how they are initialized, and the precise optimization of the n+m parameters) is not stated with numbered equations. Without this, the claimed rank upper bound cannot be independently verified and the implementation details required for reproduction are missing.
- [§3, §4] §3 and §4: while the paper shows that the (n+m)-parameter family can produce high-rank matrices, there is no analysis or ablation demonstrating that the reachable directions align with task-specific gradients; the empirical success on GLUE and reasoning tasks therefore rests on the unexamined assumption that this particular structured manifold is sufficiently expressive, which is the weakest link in the central claim.
minor comments (2)
- [§3] Notation for the diagonal scaling vectors (r and c) should be introduced consistently with a single equation in the method section rather than described only in prose.
- [§4] The manuscript would benefit from a short table comparing the exact number of trainable parameters for HyperAdapt versus LoRA and full fine-tuning on the 14B model experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Experiments): the central claim that HyperAdapt 'matches or nearly matches' full fine-tuning performance is presented without reported standard deviations, multiple random seeds, or statistical significance tests across the GLUE and reasoning benchmarks. This information is load-bearing for assessing whether the observed parity is reliable rather than within noise.
Authors: We agree that reporting variability across runs is important for substantiating performance parity claims. In the revised manuscript we will rerun the GLUE and reasoning experiments with at least three random seeds, report mean performance together with standard deviations, and add a brief discussion of statistical significance for the closest comparisons. revision: yes
-
Referee: [§3] §3 (Method): the exact update formula (including whether the diagonal matrices are applied as left/right multiplications, how they are initialized, and the precise optimization of the n+m parameters) is not stated with numbered equations. Without this, the claimed rank upper bound cannot be independently verified and the implementation details required for reproduction are missing.
Authors: We apologize for the missing numbered equations. The update is computed as diag(r) W diag(c) − W, with r ∈ ℝ^n and c ∈ ℝ^m initialized to the zero vector (yielding a zero initial update) and optimized jointly with the rest of the model via standard first-order methods such as Adam. In the revision we will insert numbered equations in §3 that explicitly define the forward pass, initialization, and optimization of the n + m parameters, enabling direct verification of the rank bound. revision: yes
-
Referee: [§3, §4] §3 and §4: while the paper shows that the (n+m)-parameter family can produce high-rank matrices, there is no analysis or ablation demonstrating that the reachable directions align with task-specific gradients; the empirical success on GLUE and reasoning tasks therefore rests on the unexamined assumption that this particular structured manifold is sufficiently expressive, which is the weakest link in the central claim.
Authors: This is a valid critique of the expressivity argument. While the theoretical rank bound and layer-wise empirical rank measurements establish that the updates are high-rank, we did not provide an explicit alignment analysis with task gradients. The competitive empirical results across diverse benchmarks nevertheless indicate that the reachable manifold is expressive enough for the tasks considered. In the revision we will add a concise discussion paragraph in §3 or §4 explaining why row- and column-wise scaling can capture salient feature adjustments and, space permitting, include a brief qualitative inspection of the learned scaling vectors. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines HyperAdapt explicitly via row- and column-wise diagonal scaling on a weight matrix, derives a mathematical upper bound on update rank directly from the resulting matrix factorization, and evaluates adaptation quality on independent external benchmarks (GLUE, arithmetic and commonsense reasoning tasks). No claimed result is obtained by fitting a parameter to a subset of the target data and then relabeling it as a prediction, nor does any load-bearing step reduce to a self-citation whose content is itself unverified. The trainable parameters are the explicit diagonal entries, and performance claims rest on measured task accuracy rather than internal fitted quantities, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (2)
- row scaling diagonal entries
- column scaling diagonal entries
axioms (1)
- standard math Matrix multiplication distributes over addition and is associative
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ΔW = A W0 B − W0 where A∈R^{n×n} and B∈R^{m×m} are diagonal matrices... rank(ΔW)≤min{2·rank(W0),n,m} (Lemma 1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2412.08905. Armen Aghajanyan, Luke Zettlemoyer, and Sonal Gupta. Intrinsic dimensionality explains the effectiveness of language model fine-tuning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arxiv.org/abs/2012.13255. Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. BitFit: Simple parameter-efficient fine-tuning for transformer-based masked language-models. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short P...
-
[3]
doi: 10.18653/v1/2022.acl-short.1
Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-short.1. URLhttps://aclanthology.org/2022.acl-short.1/. Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language,
-
[4]
URLhttps://arxiv.org/abs/1911.11641. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, M...
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[5]
Language Models are Few-Shot Learners
URLhttps://arxiv.org/abs/2005.14165. Daniel Cer, Mona Diab, Eneko Agirre, Iñigo Lopez-Gazpio, and Lucia Specia. SemEval-2017 task 1: Semantic textual similarity multilingual and crosslingual focused evaluation. In Steven Bethard, Marine Carpuat, Marianna Apidianaki, Saif M. Mohammad, Daniel Cer, and David Jurgens, editors,Proceedings of the 11th Internati...
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[6]
Association for Computational Linguistics. doi: 10.18653/v1/S17-2001. URL https://aclanthology.org/S17-2001/. Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions,
-
[7]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
URLhttps://arxiv.org/ abs/1905.10044. Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[8]
URL https://arxiv.org/abs/1803.05457. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Training Verifiers to Solve Math Word Problems
URLhttps://arxiv.org/abs/2110.14168. Ido Dagan, Dan Roth, Fabio Zanzotto, and Graeme Hirst.Recognizing Textual Entailment. Morgan & Claypool Publishers,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
ISBN 1598298348. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186,
work page 2019
-
[11]
Gradient Descent Provably Optimizes Over-parameterized Neural Networks
URLhttps://arxiv.org/abs/1810.02054. Aaron Grattafiori et al. The llama 3 herd of models,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URLhttps://arxiv.org/abs/2407.21783. 11 Preprint Google. Gemini 2.0 flash thinking mode (gemini-2.0-flash-thinking-exp-1219), December
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Soufiane Hayou, Nikhil Ghosh, and Bin Yu
URLhttps: //cloud.google.com/vertex-ai/generative-ai/docs/thinking-mode. Soufiane Hayou, Nikhil Ghosh, and Bin Yu. The impact of initialization on lora finetuning dynamics, 2024a. URLhttps://arxiv.org/abs/2406.08447. Soufiane Hayou, Nikhil Ghosh, and Bin Yu. Lora+: Efficient low rank adaptation of large models, 2024b. URLhttps://arxiv.org/abs/2402.12354. ...
-
[14]
Training Compute-Optimal Large Language Models
URLhttps://arxiv.org/abs/2203.15556. Mohammad Javad Hosseini, Hannaneh Hajishirzi, Oren Etzioni, and Nate Kushman. Learning to solve arithmetic word problems with verb categorization. In Alessandro Moschitti, Bo Pang, and Walter Daelemans, editors,Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 523–533...
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[15]
Association for Computational Linguistics. doi: 10.3115/v1/D14-1058. URLhttps://aclanthology.org/D14-1058/. Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp,
-
[16]
Parameter-Efficient Transfer Learning for NLP
URL https://arxiv.org/abs/1902.00751. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[17]
URLhttps://arxiv.org/abs/2304.01933. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models,
-
[18]
Scaling Laws for Neural Language Models
URL https://arxiv.org/abs/2001.08361. Rik Koncel-Kedziorski, Hannaneh Hajishirzi, Ashish Sabharwal, Oren Etzioni, and Siena Dumas Ang. Parsing algebraic word problems into equations.Transactions of the Association for Computational Linguistics, 3: 585–597,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[19]
URLhttps://aclanthology.org/Q15-1042/
doi: 10.1162/tacl_a_00160. URLhttps://aclanthology.org/Q15-1042/. Dawid J. Kopiczko, Tijmen Blankevoort, and Yuki M. Asano. Vera: Vector-based random matrix adaptation,
-
[20]
Brian Lester, Rami Al-Rfou, and Noah Constant
URLhttps://arxiv.org/abs/2310.11454. Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, Online and Punta Cana, Dominican Republic, November
-
[21]
doi: 10.18653/v1/2021.emnlp-main.243
Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.243. URLhttps://aclanthology.org/2021.emnlp-main.243. Chunyuan Li, Heerad Farkhoor, Rosanne Liu, and Jason Yosinski. Measuring the intrinsic dimension of objective landscapes,
-
[22]
Measuring the Intrinsic Dimension of Objective Landscapes
URLhttps://arxiv.org/abs/1804.08838. Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, Online, August
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.353. URL https://aclanthology.org/2021.acl-long.353. 12 Preprint Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.acl-long.353 2021
-
[24]
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
URLhttps://arxiv.org/abs/1705.04146. Vijay Lingam, Atula Tejaswi, Aditya Vavre, Aneesh Shetty, Gautham Krishna Gudur, Joydeep Ghosh, Alex Dimakis, Eunsol Choi, Aleksandar Bojchevski, and Sujay Sanghavi. Svft: Parameter-efficient fine-tuning with singular vectors,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URLhttps://arxiv.org/abs/2405.19597. Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation,
-
[26]
DoRA: Weight-Decomposed Low-Rank Adaptation
URLhttps://arxiv.org/ abs/2402.09353. Weiyang Liu, Zeju Qiu, Yao Feng, Yuliang Xiu, Yuxuan Xue, Longhui Yu, Haiwen Feng, Zhen Liu, Juyeon Heo, Songyou Peng, et al. Parameter-efficient orthogonal finetuning via butterfly factorization.arXiv preprint arXiv:2311.06243,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
URLhttps://arxiv.org/abs/1809.02789. Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candès, and Tatsunori Hashimoto. s1: Simple test-time scaling,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
URL https://arxiv.org/abs/2501.19393. Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
URLhttps://arxiv.org/abs/2103.07191. Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin...
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
URLhttps://arxiv.org/abs/2412.15115. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Lan- guage models are unsupervised multitask learners.OpenAI,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
URLhttps://arxiv.org/abs/1606.05250. Subhro Roy and Dan Roth. Solving general arithmetic word problems,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Solving General Arithmetic Word Problems
URLhttps://arxiv.org/ abs/1608.01413. Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
URLhttps://arxiv.org/abs/1907.10641. Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions,
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
SocialIQA: Commonsense Reasoning about Social Interactions
URLhttps://arxiv.org/abs/1904.09728. Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In David Yarowsky, Timothy Baldwin, Anna Korhonen, Karen Livescu, and Steven Bethard, editors, 13 Preprint Proceedings of the 20...
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[36]
GLUE: A multi- taskbenchmarkandanalysisplatformfornaturallanguageunderstanding
Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. GLUE: A multi- taskbenchmarkandanalysisplatformfornaturallanguageunderstanding. InTalLinzen, GrzegorzChrupała, and Afra Alishahi, editors,Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pages 353–355, Brussels, Belg...
work page 2018
-
[37]
Association for Computational Linguistics. doi: 10.18653/v1/W18-5446. URLhttps://aclanthology.org/W18-5446/. Shaowen Wang, Linxi Yu, and Jian Li. Lora-ga: Low-rank adaptation with gradient approximation,
-
[38]
Alex Warstadt, Amanpreet Singh, and Samuel R
URLhttps://arxiv.org/abs/2407.05000. Alex Warstadt, Amanpreet Singh, and Samuel R. Bowman. Neural network acceptability judgments,
-
[39]
URLhttps://arxiv.org/abs/1805.12471. Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M....
-
[40]
URL https://www.aclweb.org/anthology/2020.emnlp-demos.6
Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6. Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence?,
work page 2020
-
[41]
HellaSwag: Can a Machine Really Finish Your Sentence?
URLhttps://arxiv.org/abs/1905.07830. 14 Preprint A Experiments and Hyperparameters A.1 GLUE Benchmark To keep results consistent, we use the same†setup as Hu et al. (2022) for RoBERTa Large. All of our GLUE experiments have the same max sequence length and epochs for each task. We use the learning rate for DoRA from Hu et al. (2022) since both LoRA and Do...
work page internal anchor Pith review Pith/arXiv arXiv 1905
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.