Mitigating Visual Context Degradation in Large Multimodal Models: A Training-Free Decoupled Agentic Framework
Pith reviewed 2026-05-18 12:24 UTC · model grok-4.3
The pith
A training-free framework decouples reasoning from perception to stop multimodal models from losing visual grounding in long chains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
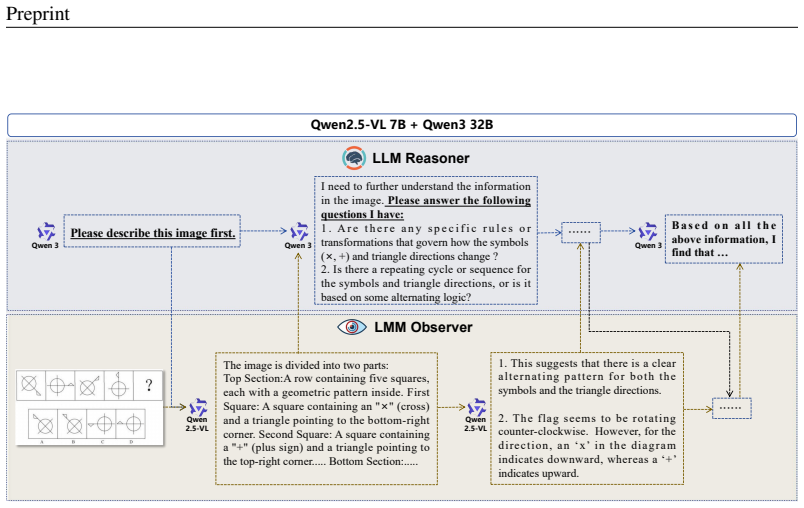
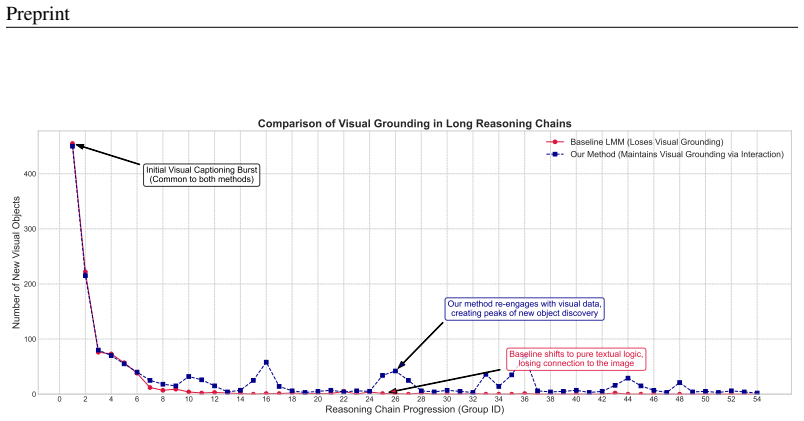
The central discovery is a training-free agentic paradigm called DRP that decouples cognitive reasoning from visual perception. A powerful LLM acts as the strategic Reasoner that orchestrates inference by explicitly querying an LMM as Observer to retrieve fine-grained visual details on demand. This regulates the visual reasoning trajectory, significantly mitigates reasoning drift, and enforces robust visual grounding.
What carries the argument
The DRP framework, where the LLM Reasoner queries the LMM Observer for specific visual information as the reasoning progresses.
If this is right
- The visual reasoning trajectory is regulated to stay close to the image content.
- Reasoning drift is significantly mitigated, reducing visually implausible conclusions.
- Robust visual grounding is enforced throughout the inference process.
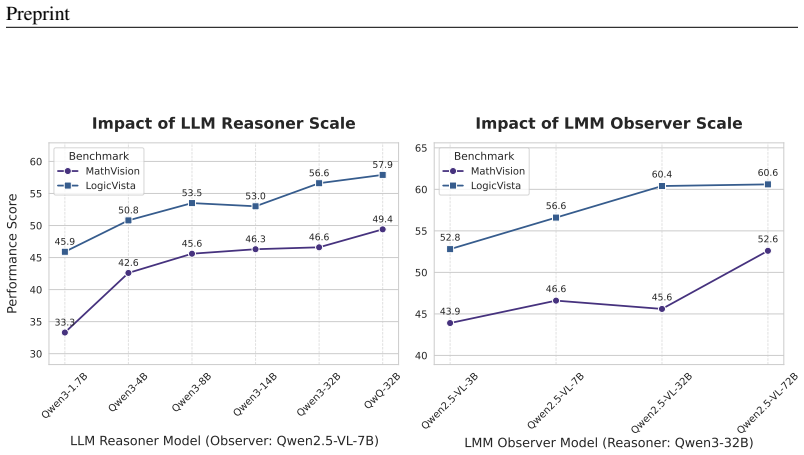
- Performance improves on challenging benchmarks, such as reaching 47.2% accuracy on MathVision with Qwen models, outperforming GPT-4o.
- The method applies to any LMM in a plug-and-play manner without modifications or training.
Where Pith is reading between the lines
- This decoupling strategy might apply to other modalities or sequential tasks where models lose fidelity to initial inputs over time.
- Combining different sized models in this observer-reasoner setup could lead to more efficient AI systems overall.
- Explicit querying could be optimized further to minimize the number of visual checks needed for a given task.
Load-bearing premise
The LMM can provide accurate and fine-grained visual details in response to explicit queries from the LLM without requiring any training or model changes.
What would settle it
If the LMM Observer returns incorrect visual information in response to queries on a test set of images with clear but detailed features, the framework would produce the same errors as standard models.
Figures



read the original abstract
With the continuous expansion of Large Language Models (LLMs) and advances in reinforcement learning, LLMs have demonstrated exceptional reasoning capabilities, enabling them to address a wide range of complex problems. Inspired by these achievements, researchers have extended related techniques to Large Multimodal Models (LMMs). However, a critical limitation has emerged, reflected in the progressive loss of visual grounding. As the reasoning chain grows longer, LMMs tend to rely increasingly on the textual information generated in earlier steps, while the initially extracted visual information is rarely revisited or incorporated. This phenomenon often causes the reasoning process to drift away from the actual image content, resulting in visually implausible or even erroneous conclusions. To overcome this fundamental limitation, we propose a novel, training-free agentic paradigm that Decouples cognitive Reasoning from visual Perception (DRP). In this framework, a powerful LLM serves as a strategic Reasoner, orchestrating the inference process by explicitly querying an LMM-acting as a dedicated Observer-to retrieve fine-grained visual details on demand. This approach is lightweight, model-agnostic, and plug-and-play, necessitating no additional training or architectural modifications. Extensive experiments demonstrate our framework DRP's efficacy in regulating the visual reasoning trajectory, significantly mitigating reasoning drift, and enforcing robust visual grounding. Notably, on the MathVision benchmark, the integration of Qwen2.5-VL-7B and Qwen3-32B achieves an accuracy of 47.2\%, outperforming GPT-4o's 40.6\%. These findings underscore the potential of our approach to enhance multimodal reasoning reliability without the need for costly retraining. Our code is publicly available at https://github.com/hongruijia/DRP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DRP, a training-free agentic framework that decouples visual perception (LMM as Observer) from cognitive reasoning (LLM as Reasoner). The Reasoner explicitly queries the Observer for fine-grained visual details on demand to mitigate progressive loss of visual grounding and reasoning drift in long chains. Experiments on MathVision report 47.2% accuracy using Qwen2.5-VL-7B with Qwen3-32B, outperforming GPT-4o at 40.6%, with the method described as lightweight, model-agnostic, and plug-and-play.
Significance. If the central results hold under scrutiny, the work offers a practical, training-free route to improve visual grounding in multimodal reasoning without architectural changes or fine-tuning. The public code release at https://github.com/hongruijia/DRP supports reproducibility and enables further testing of the agentic decoupling idea.
major comments (2)
- [Abstract / Framework] Abstract and framework description: the performance gain (47.2% on MathVision) is attributed to enforced visual grounding via on-demand queries, yet no quantitative evaluation or error analysis of the Observer LMM's response accuracy, hallucination rate, or completeness is provided. This leaves the load-bearing assumption—that an unmodified LMM reliably supplies faithful fine-grained details throughout multi-step reasoning—unverified and open to the possibility that gains arise from other factors such as prompt engineering or model combination.
- [Experiments] Methods and experiments: the manuscript lacks ablations on query formulation, number of Observer calls, or failure modes when the Observer returns incomplete or erroneous details. Without these, it is difficult to isolate the contribution of the decoupled architecture from baseline LMM capabilities or the specific LLM-LMM pairing.
minor comments (1)
- [Implementation Details] Clarify the exact prompting templates used for Observer queries and how the Reasoner integrates the returned text to ensure the process is fully reproducible from the released code.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Framework] Abstract and framework description: the performance gain (47.2% on MathVision) is attributed to enforced visual grounding via on-demand queries, yet no quantitative evaluation or error analysis of the Observer LMM's response accuracy, hallucination rate, or completeness is provided. This leaves the load-bearing assumption—that an unmodified LMM reliably supplies faithful fine-grained details throughout multi-step reasoning—unverified and open to the possibility that gains arise from other factors such as prompt engineering or model combination.
Authors: We appreciate this observation. The end-to-end gains, including outperforming GPT-4o, provide supporting evidence that on-demand querying helps maintain visual grounding. However, we agree that direct metrics on Observer accuracy and hallucination would better isolate the mechanism. In the revision we will add a quantitative analysis of Observer response quality (accuracy, hallucination rate, completeness) on a sampled subset of MathVision queries, along with examples of how the Reasoner uses or corrects these outputs. revision: yes
-
Referee: [Experiments] Methods and experiments: the manuscript lacks ablations on query formulation, number of Observer calls, or failure modes when the Observer returns incomplete or erroneous details. Without these, it is difficult to isolate the contribution of the decoupled architecture from baseline LMM capabilities or the specific LLM-LMM pairing.
Authors: We concur that targeted ablations would clarify the contribution of the decoupling strategy. The current experiments focus on demonstrating overall efficacy and plug-and-play applicability across model pairs. In the revised manuscript we will include ablations varying query formulation and the number of Observer calls, plus a discussion of failure modes (e.g., incomplete Observer replies) and how the Reasoner mitigates them via iterative querying. These additions will help separate architectural effects from prompt or pairing factors. revision: yes
Circularity Check
No significant circularity detected in DRP framework
full rationale
The paper proposes a training-free decoupled agentic framework (DRP) that uses an LLM as Reasoner to query an LMM as Observer for on-demand visual details. No equations, mathematical derivations, parameter fittings, or predictions are present in the provided text. Claims of mitigating reasoning drift rest on empirical benchmark results (e.g., MathVision accuracy) rather than any self-referential definitions or reductions. No self-citations appear as load-bearing elements for uniqueness theorems or ansatzes. The framework is described as model-agnostic and plug-and-play with external evaluations, making the contribution self-contained against benchmarks without circular reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models possess strong reasoning capabilities suitable for strategic orchestration of inference steps.
- domain assumption Large multimodal models can extract and return accurate fine-grained visual details when explicitly prompted for specific information.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
decouples cognitive Reasoning from visual Perception (DRP)... LLM Reasoner... LMM Observer... iterative dialogue
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Claude 3.7 Sonnet and Claude Code
Anthropic . Claude 3.7 Sonnet and Claude Code . https://www.anthropic.com/news/claude-3-7-sonnet, 2025. Accessed: 2025-02-25
work page 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. Trans. Mach. Learn. Res., 2023, 2022. URL https://api.semanticscholar.org/CorpusID:253801709
work page 2023
-
[4]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Jun-Mei Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiaoling Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bing-Li Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Dama...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Openvlthinker: Complex vision-language reasoning via iterative sft-rl cycles, 2025
Yihe Deng, Hritik Bansal, Fan Yin, Nanyun Peng, Wei Wang, and Kai-Wei Chang. Openvlthinker: Complex vision-language reasoning via iterative sft-rl cycles, 2025. URL https://arxiv.org/abs/2503.17352
-
[6]
Virgo: A preliminary exploration on reproducing o1-like mllm
Yifan Du, Zikang Liu, Yifan Li, Wayne Xin Zhao, Yuqi Huo, Bingning Wang, Weipeng Chen, Zheng Liu, Zhongyuan Wang, and Ji-Rong Wen. Virgo: A preliminary exploration on reproducing o1-like mllm, 2025. URL https://arxiv.org/abs/2501.01904
-
[7]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team GLM, :, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Jingyu Sun, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems, 2024. URL https://arxiv.org/abs/2402.14008
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu. Reinforce++: A simple and efficient approach for aligning large language models. arXiv preprint arXiv:2501.03262, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Tab-cot: Zero-shot tabular chain of thought
Ziqi Jin and Wei Lu. Tab-cot: Zero-shot tabular chain of thought. In Annual Meeting of the Association for Computational Linguistics, 2023. URL https://api.semanticscholar.org/CorpusID:258960483
work page 2023
-
[11]
Mingi Jung, Saehyung Lee, Eunji Kim, and Sungroh Yoon. Visual attention never fades: Selective progressive attention recalibration for detailed image captioning in multimodal large language models, 2025. URL https://arxiv.org/abs/2502.01419
-
[12]
Imagine while Reasoning in Space: Multimodal Visualization-of-Thought
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vulić, and Furu Wei. Imagine while reasoning in space: Multimodal visualization-of-thought, 2025 a . URL https://arxiv.org/abs/2501.07542
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Perception, reason, think, and plan: A survey on large multimodal reasoning models
Yunxin Li, Zhenyu Liu, Zitao Li, Xuanyu Zhang, Zhenran Xu, Xinyu Chen, Haoyuan Shi, Shenyuan Jiang, Xintong Wang, Jifang Wang, et al. Perception, reason, think, and plan: A survey on large multimodal reasoning models. arXiv preprint arXiv:2505.04921, 2025 b
-
[14]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step, 2023. URL https://arxiv.org/abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly, 2025
Yexin Liu, Zhengyang Liang, Yueze Wang, Xianfeng Wu, Feilong Tang, Muyang He, Jian Li, Zheng Liu, Harry Yang, Sernam Lim, and Bo Zhao. Unveiling the ignorance of mllms: Seeing clearly, answering incorrectly, 2025. URL https://arxiv.org/abs/2406.10638
-
[16]
Minheng Ni, Yutao Fan, Lei Zhang, and Wangmeng Zuo. Visual-o1: Understanding ambiguous instructions via multi-modal multi-turn chain-of-thoughts reasoning. arXiv preprint arXiv:2410.03321, 2024
-
[17]
Skeleton-of-thought: Prompting llms for efficient parallel generation
Xuefei Ning, Zinan Lin, Zixuan Zhou, Zifu Wang, Huazhong Yang, and Yu Wang. Skeleton-of-thought: Prompting llms for efficient parallel generation. arXiv preprint arXiv:2307.15337, 2023
-
[18]
Introducing openai o3 and o4-mini, 2024
OpenAI. Introducing openai o3 and o4-mini, 2024. https://openai.com/index/introducing-o3-and-o4-mini/
work page 2024
-
[19]
Introducing GPT-4.1 in the API , April 2025
OpenAI. Introducing GPT-4.1 in the API , April 2025. URL https://openai.com/index/gpt-4-1/
work page 2025
-
[20]
OpenAI, :, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Mądry, Alex Baker-Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alex...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
OpenAI, :, Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondri...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Yingzhe Peng, Gongrui Zhang, Miaosen Zhang, Zhiyuan You, Jie Liu, Qipeng Zhu, Kai Yang, Xingzhong Xu, Xin Geng, and Xu Yang. Lmm-r1: Empowering 3b lmms with strong reasoning abilities through two-stage rule-based rl, 2025. URL https://arxiv.org/abs/2503.07536
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Mutual reasoning makes smaller llms stronger problem-solvers
Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller llms stronger problem-solvers. arXiv preprint arXiv:2408.06195, 2024
-
[25]
We-Math: Does Your Large Multimodal Model Achieve Human-like Mathematical Reasoning?
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Zhuoma GongQue, Shanglin Lei, Zhe Wei, Miaoxuan Zhang, Runfeng Qiao, Yifan Zhang, Xiao Zong, Yida Xu, Muxi Diao, Zhimin Bao, Chen Li, and Honggang Zhang. We-math: Does your large multimodal model achieve human-like mathematical reasoning?, 2024. URL https://arxiv.org/abs/2407.01284
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Visual chain of thought: bridging logical gaps with multimodal infillings
Daniel Rose, Vaishnavi Himakunthala, Andy Ouyang, Ryan He, Alex Mei, Yujie Lu, Michael Saxon, Chinmay Sonar, Diba Mirza, and William Yang Wang. Visual chain of thought: bridging logical gaps with multimodal infillings. arXiv preprint arXiv:2305.02317, 2023
-
[27]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model, 2025. URL https://arxiv.org/abs/2504.07615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. ArXiv, abs/2408.03314, 2024. URL https://api.semanticscholar.org/CorpusID:271719990
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Kai Sun, Yushi Bai, Ji Qi, Lei Hou, and Juanzi Li. Mm-math: Advancing multimodal math evaluation with process evaluation and fine-grained classification, 2024. URL https://arxiv.org/abs/2404.05091
-
[32]
Mm-verify: Enhancing multimodal reasoning with chain-of-thought verification, 2025
Linzhuang Sun, Hao Liang, Jingxuan Wei, Bihui Yu, Tianpeng Li, Fan Yang, Zenan Zhou, and Wentao Zhang. Mm-verify: Enhancing multimodal reasoning with chain-of-thought verification, 2025. URL https://arxiv.org/abs/2502.13383
-
[33]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms. arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Qvq: To see the world with wisdom, 2024
Qwen Team. Qvq: To see the world with wisdom, 2024. https://qwenlm.github.io/blog/qvq-72b-preview/
work page 2024
-
[35]
Llamav-o1: Rethinking step-by-step visual reasoning in llms
Omkar Thawakar, Dinura Dissanayake, Ketan More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, Hisham Cholakkal, Ivan Laptev, Mubarak Shah, Fahad Shahbaz Khan, and Salman Khan. Llamav-o1: Rethinking step-by-step visual reasoning in llms, 2025. URL https://arxiv.org/abs/2501.06186
-
[36]
Seekworld: Geolocation is a natural rl task for o3-like visual clue-tracking reasoning, 2025
Kaibin Tian, Zijie Xin, and Jiazhen Liu. Seekworld: Geolocation is a natural rl task for o3-like visual clue-tracking reasoning, 2025. https://huggingface.co/datasets/TheEighthDay/SeekWorld
work page 2025
-
[37]
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset, 2024. URL https://arxiv.org/abs/2402.14804
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Multimodal Chain-of-Thought Reasoning: A Comprehensive Survey
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey. arXiv preprint arXiv:2503.12605, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models, 2023. URL https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Boosting multimodal reasoning with mcts-automated structured thinking
Jinyang Wu, Mingkuan Feng, Shuai Zhang, Ruihan Jin, Feihu Che, Zengqi Wen, and Jianhua Tao. Boosting multimodal reasoning with mcts-automated structured thinking. arXiv preprint arXiv:2502.02339, 2025
-
[42]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts, 2024. URL https://arxiv.org/abs/2407.04973
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
LLaVA-CoT: Let Vision Language Models Reason Step-by-Step
Guowei Xu, Peng Jin, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vision language models reason step-by-step, 2025. URL https://arxiv.org/abs/2411.10440
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
R1-Onevision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, Bo Zhang, and Wei Chen. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization, 2025 b . URL https://arxiv.org/abs/2503.10615
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. ArXiv, abs/2305.10601, 2023. URL https://api.semanticscholar.org/CorpusID:258762525
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2024. URL https://arxiv.org/abs/2308.02490
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, and Hongsheng Li. Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems?, 2024. URL https://arxiv.org/abs/2403.14624
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of-thought reasoning in language models. arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, Zhangwei Gao, Erfei Cui, Xuehui Wang, Yue Cao, Yangzhou Liu, Xingguang Wei, Hongjie Zhang, Haomin Wang, Weiye Xu, Hao Li, Jiahao Wang, Nianchen Deng, Songze Li, Yinan He, Tan Jiang, Jiapeng Luo, Yi Wang, Conghui He, Botian Shi, Xingcheng Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[52]
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[53]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[54]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.