Dynamic-TreeRPO: Breaking the Independent Trajectory Bottleneck with Structured Sampling
Pith reviewed 2026-05-21 21:23 UTC · model grok-4.3
The pith
Dynamic-TreeRPO replaces independent trajectories with a tree-structured search that shares prefixes and varies noise by layer to improve RL for text-to-image flow matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
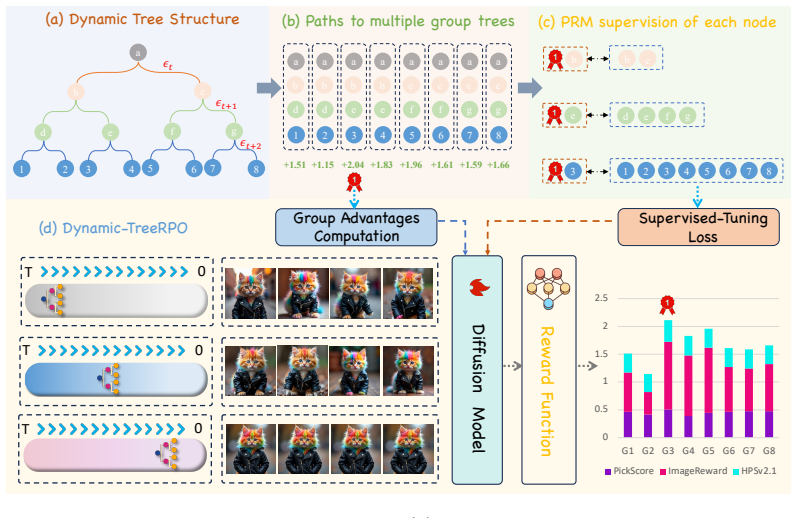
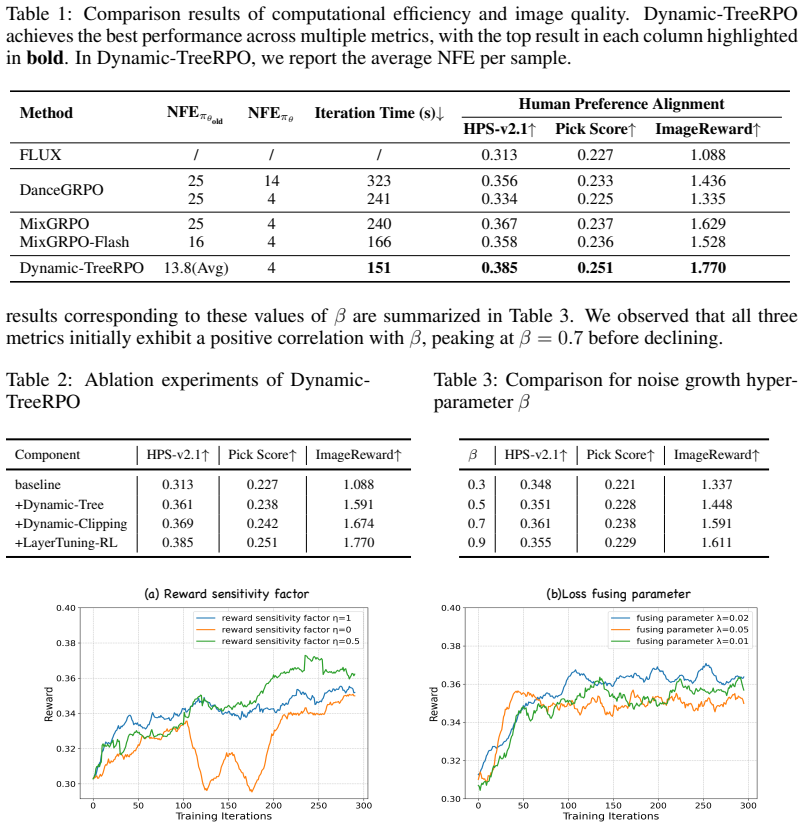
Dynamic-TreeRPO implements sliding-window sampling as a tree-structured search with dynamic noise intensities along depth, performs GRPO-guided optimization and constrained SDE sampling while sharing prefix paths, and integrates SFT and RL by reformulating the SFT loss as a weighted Progress Reward Model paired with dynamic-adaptive clipping bounds; the resulting LayerTuning-RL paradigm lets the model explore a diverse search space along effective directions and yields 4.9 percent, 5.91 percent, and 8.66 percent gains on HPS-v2.1, PickScore, and ImageReward respectively together with a nearly 50 percent improvement in training efficiency.
What carries the argument
The tree-structured sampling strategy with dynamic noise intensities along depth, which shares prefix paths to amortize the cost of trajectory search while increasing exploration variation.
If this is right
- Generated images show measurable gains in semantic consistency, visual fidelity, and alignment with human preferences on standard benchmarks.
- Training runs complete in roughly half the time of prior RL baselines for the same flow-matching backbone.
- The combined tree sampling and LayerTuning-RL approach allows the optimizer to follow more varied yet still effective trajectories.
- Prefix sharing keeps the total number of SDE steps comparable to independent sampling while expanding the reachable search space.
Where Pith is reading between the lines
- The same prefix-sharing idea could be tested in other generative settings where multiple rollouts are currently run independently, such as video or 3D synthesis.
- If the dynamic-noise schedule proves robust, it might simplify hyper-parameter search for future RL fine-tuning of diffusion or flow models.
- LayerTuning-RL suggests a route to merge supervised and reinforcement stages without separate pre-training phases, which could shorten overall development cycles.
Load-bearing premise
Well-designed noise intensities for each tree layer can increase exploration variation without raising computation, and pairing the weighted PRM with dynamic-adaptive clipping bounds prevents the integration step from disrupting the exploration process.
What would settle it
An ablation that disables the tree structure or removes the per-layer noise schedule and measures whether benchmark scores fall and training time rises would directly test whether the claimed gains depend on those design choices.
Figures






read the original abstract
The integration of Reinforcement Learning (RL) into flow matching models for text-to-image (T2I) generation has driven substantial advances in generation quality. However, these gains often come at the cost of exhaustive exploration and inefficient sampling strategies due to slight variation in the sampling group. Building on this insight, we propose Dynamic-TreeRPO, which implements the sliding-window sampling strategy as a tree-structured search with dynamic noise intensities along depth. We perform GRPO-guided optimization and constrained Stochastic Differential Equation (SDE) sampling within this tree structure. By sharing prefix paths of the tree, our design effectively amortizes the computational overhead of trajectory search. With well-designed noise intensities for each tree layer, Dynamic-TreeRPO can enhance the variation of exploration without any extra computational cost. Furthermore, we seamlessly integrate Supervised Fine-Tuning (SFT) and RL paradigm within Dynamic-TreeRPO to construct our proposed LayerTuning-RL, reformulating the loss function of SFT as a dynamically weighted Progress Reward Model (PRM) rather than a separate pretraining method. By associating this weighted PRM with dynamic-adaptive clipping bounds, the disruption of exploration process in Dynamic-TreeRPO is avoided. Benefiting from the tree-structured sampling and the LayerTuning-RL paradigm, our model dynamically explores a diverse search space along effective directions. Compared to existing baselines, our approach demonstrates significant superiority in terms of semantic consistency, visual fidelity, and human preference alignment on established benchmarks, including HPS-v2.1, PickScore, and ImageReward. In particular, our model outperforms SoTA by $4.9\%$, $5.91\%$, and $8.66\%$ on those benchmarks, respectively, while improving the training efficiency by nearly $50\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dynamic-TreeRPO for RL fine-tuning of flow-matching text-to-image models. It replaces independent trajectories with a tree-structured search that applies a sliding-window strategy and depth-dependent dynamic noise intensities, performs GRPO-guided optimization together with constrained SDE sampling, and amortizes cost by sharing prefix paths. LayerTuning-RL unifies SFT and RL by recasting the SFT loss as a dynamically weighted Progress Reward Model (PRM) paired with dynamic-adaptive clipping bounds. The paper reports that these choices yield 4.9 %, 5.91 %, and 8.66 % gains over SoTA on HPS-v2.1, PickScore, and ImageReward while improving training efficiency by nearly 50 %.
Significance. If the headline gains and efficiency claims survive rigorous controls, the work would usefully demonstrate that structured prefix sharing can increase trajectory diversity without extra compute in RL-for-generation pipelines. The LayerTuning-RL formulation that folds SFT into a weighted PRM is a compact unification worth examining. The manuscript does not yet supply the derivations, schedules, or ablation data needed to evaluate these contributions.
major comments (3)
- [Abstract and §4] Abstract and §4 (Dynamic-TreeRPO description): the claim that 'well-designed noise intensities for each tree layer' enhance exploration variation 'without any extra computational cost' is unsupported; no explicit per-layer noise schedule, injection equation inside the constrained SDE, or FLOPs accounting is provided to show that prefix sharing fully offsets the added stochasticity.
- [Abstract and §5] Abstract and §5 (experiments): the reported 4.9–8.66 % improvements and ~50 % efficiency gain rest on unreported baseline implementations, post-hoc hyperparameter choices (noise schedules, clipping bounds), and absence of statistical significance or multiple-run variance; this directly affects the central empirical claim.
- [§3.2] §3.2 (LayerTuning-RL): the dynamic-adaptive clipping bounds paired with the weighted PRM lack a formal definition or validation that they preserve gradient variance and exploration; without this, the assertion that they 'avoid disruption of the exploration process' cannot be assessed.
minor comments (2)
- [§4] A diagram or pseudocode for the tree construction, prefix sharing, and depth-dependent noise would substantially improve clarity of the sampling procedure.
- [§3] Notation for the constrained SDE, GRPO objective, and weighted PRM should be introduced with explicit equations on first use rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment below, indicating the specific revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Dynamic-TreeRPO description): the claim that 'well-designed noise intensities for each tree layer' enhance exploration variation 'without any extra computational cost' is unsupported; no explicit per-layer noise schedule, injection equation inside the constrained SDE, or FLOPs accounting is provided to show that prefix sharing fully offsets the added stochasticity.
Authors: We agree that the current description is high-level and would benefit from explicit supporting material. In the revised manuscript we will insert the precise per-layer noise schedule (defined as a depth-dependent function), the exact noise-injection equation used inside the constrained SDE, and a FLOPs accounting table that demonstrates how prefix-path sharing fully amortizes the added stochasticity. These additions will appear in Section 4. revision: yes
-
Referee: [Abstract and §5] Abstract and §5 (experiments): the reported 4.9–8.66 % improvements and ~50 % efficiency gain rest on unreported baseline implementations, post-hoc hyperparameter choices (noise schedules, clipping bounds), and absence of statistical significance or multiple-run variance; this directly affects the central empirical claim.
Authors: We acknowledge that fuller experimental transparency is required. The revision will document the exact baseline implementations, list all hyperparameter choices (including noise schedules and clipping bounds), report means and standard deviations over at least three independent random seeds, include statistical significance tests, and add targeted ablations on the efficiency gains. These details will be placed in Section 5 and the supplementary material. revision: yes
-
Referee: [§3.2] §3.2 (LayerTuning-RL): the dynamic-adaptive clipping bounds paired with the weighted PRM lack a formal definition or validation that they preserve gradient variance and exploration; without this, the assertion that they 'avoid disruption of the exploration process' cannot be assessed.
Authors: We recognize the need for a more rigorous treatment. In the revised §3.2 we will supply the formal definition of the dynamic-adaptive clipping bounds, provide an analysis (theoretical bound or empirical measurement) showing that gradient variance is preserved, and include validation experiments confirming that exploration remains undisrupted. This will directly support the claim that the weighted PRM integration avoids disruption. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes Dynamic-TreeRPO using tree-structured sampling with depth-dependent noise and LayerTuning-RL that reformulates SFT loss as a weighted PRM with adaptive clipping. These are presented as architectural and algorithmic choices whose benefits (diversity, efficiency, benchmark gains) are validated empirically on external metrics (HPS-v2.1, PickScore, ImageReward). No equations, parameter fits, or self-citations are shown that reduce the claimed performance or efficiency improvements to tautological redefinitions of the inputs. The design assumptions are stated explicitly rather than derived from the target results, making the central claims independent of the inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
With well-designed noise intensities for each tree layer, Dynamic-TreeRPO can enhance the variation of exploration without any extra computational cost... gt(k) = gt × (1 + β k/d)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reformulating the loss function of SFT as a dynamically weighted Progress Reward Model (PRM)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 6 Pith papers
-
TMPO: Trajectory Matching Policy Optimization for Diverse and Efficient Diffusion Alignment
TMPO replaces scalar reward maximization with trajectory-level matching to a Boltzmann distribution via Softmax-TB, improving generative diversity by 9.1% while keeping competitive reward performance.
-
TMPO: Trajectory Matching Policy Optimization for Diverse and Efficient Diffusion Alignment
TMPO uses Softmax Trajectory Balance to match policy probabilities over multiple trajectories to a Boltzmann reward distribution, improving diversity by 9.1% in diffusion alignment tasks.
-
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
This survey introduces the Generate-Filter-Control-Replay (GFCR) taxonomy to structure rollout pipelines for RL-based post-training of reasoning LLMs.
-
When Policy Entropy Constraint Fails: Preserving Diversity in Flow-based RLHF via Perceptual Entropy
Policy entropy remains constant in flow-matching models during RLHF due to fixed noise schedules while perceptual diversity collapses from mode-seeking policy gradients, so perceptual entropy constraints are introduce...
-
Power Reinforcement Post-Training of Text-to-Image Models with Super-Linear Advantage Shaping
Super-Linear Advantage Shaping (SLAS) introduces a non-linear geometric policy update for RL post-training of text-to-image models that reshapes the local policy space via advantage-dependent Fisher-Rao weighting to r...
-
FP4 Explore, BF16 Train: Diffusion Reinforcement Learning via Efficient Rollout Scaling
Sol-RL decouples FP4-based candidate exploration from BF16 policy optimization in diffusion RL, delivering up to 4.64x faster convergence with maintained or superior alignment performance on models like FLUX.1 and SD3.5.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models. arXiv preprint arXiv:2504.11468, 2025a. Liang Chen, Xueting Han, Li Shen, Jing Bai, and Kam-Fai Wong. Beyond two-stage training: Cooperative sft and rl for llm reaso...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Diffusion meets flow matching: Two sides of the same coin
Ruiqi Gao, Emiel Hoogeboom, Jonathan Heek, Valentin De Bortoli, Kevin P Murphy, and Tim Salimans. Diffusion meets flow matching: Two sides of the same coin. 2024.URL https://diffusionflow. github. io,
work page 2024
-
[4]
Yuan Gong, Xionghui Wang, Jie Wu, Shiyin Wang, Yitong Wang, and Xinglong Wu. Onereward: Unified mask-guided image generation via multi-task human preference learning.arXiv preprint arXiv:2508.21066,
-
[5]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang. Tempflow-grpo: When timing matters for grpo in flow models.arXiv preprint arXiv:2508.04324,
work page internal anchor Pith review arXiv
-
[6]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
15 Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419,
Xingtai Lv, Yuxin Zuo, Youbang Sun, Hongyi Liu, Yuntian Wei, Zhekai Chen, Lixuan He, Xuekai Zhu, Kaiyan Zhang, Bingning Wang, et al. Towards a unified view of large language model post-training.arXiv preprint arXiv:2509.04419,
-
[12]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. Bram Wallace, Meihua ...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[15]
Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl
Junke Wang, Zhi Tian, Xun Wang, Xinyu Zhang, Weilin Huang, Zuxuan Wu, and Yu-Gang Jiang. Simplear: Pushing the frontier of autoregressive visual generation through pretraining, sft, and rl. arXiv preprint arXiv:2504.11455,
-
[16]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to- image synthesis.arXiv preprint arXiv:2306.09341,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
DanceGRPO: Unleashing GRPO on Visual Generation
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2508.11408 , year=
16 Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. On-policy rl meets off-policy experts: Harmonizing supervised fine-tuning and reinforcement learning via dynamic weighting.arXiv preprint arXiv:2508.11408, 2025a. Yu Zhang, Yunqi Li, Yifan Yang, Rui Wang, Yuqing Yang, Dai Qi, Jianmin Bao, Dongdon...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.