Recognition: 2 theorem links
· Lean TheoremEvaluating the Formal Reasoning Capabilities of Large Language Models through Chomsky Hierarchy
Pith reviewed 2026-05-13 19:47 UTC · model grok-4.3
The pith
Large language models exhibit performance that stratifies by Chomsky hierarchy levels but remain limited by prohibitive computational costs rather than absolute capability bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ChomskyBench provides the first full-coverage benchmark combining all Chomsky hierarchy levels, natural-language process traces, and deterministic symbolic verification. Testing across recognition and generation tasks produces performance stratification that tracks hierarchy complexity, with harder tasks driving longer inference sequences and lower accuracy. Larger models and advanced inference deliver relative improvements but encounter severe efficiency barriers that make practical reliability computationally prohibitive. Time-complexity comparisons confirm LLMs operate far less efficiently than conventional algorithmic programs on the same formal tasks, delineating practical limits and re
What carries the argument
ChomskyBench, a suite of language recognition and generation tasks spanning the full Chomsky hierarchy, evaluated through natural-language process traces with deterministic symbolic verification.
If this is right
- Model accuracy decreases and inference length increases as tasks move up the Chomsky hierarchy.
- Larger models and advanced inference methods produce relative gains yet still face prohibitive costs for reliable performance.
- LLMs prove significantly less efficient than traditional algorithmic programs on the same formal tasks.
- Traditional software tools remain indispensable for practical formal reasoning in automated software engineering.
- Future LLM development should target mechanisms that reduce inference length on complex hierarchical structures.
Where Pith is reading between the lines
- Hybrid LLM-plus-symbolic-verifier systems could bypass the efficiency barrier for software-engineering applications.
- The benchmark could serve as a training signal to improve LLM handling of hierarchical structure rather than relying solely on scale.
- Extending the tasks to real code-generation problems would test whether the observed stratification predicts performance on practical formal-reasoning workloads.
- If inefficiency is the dominant limit, training objectives that explicitly penalize long inference traces on formal tasks may yield more practical models.
Load-bearing premise
The chosen recognition and generation tasks faithfully capture the formal reasoning required for automated software engineering without introducing design biases or evaluation artifacts.
What would settle it
Demonstrating that sufficiently large models with optimized inference achieve high accuracy on context-sensitive or recursively enumerable tasks at computational costs comparable to traditional algorithms would falsify the inefficiency conclusion.
Figures
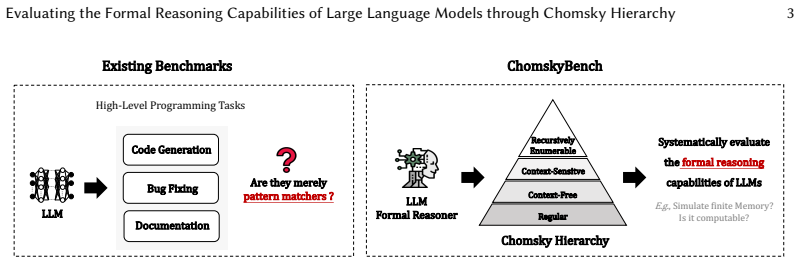
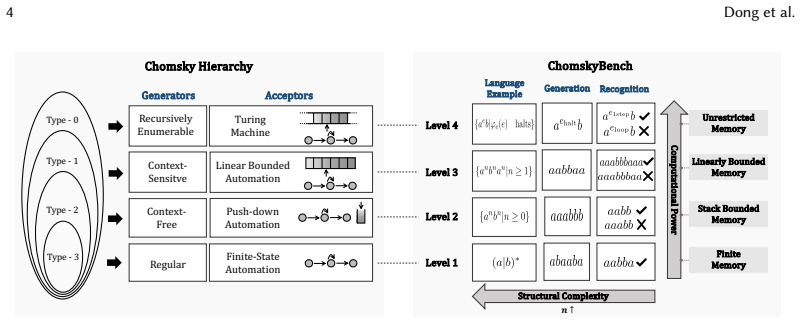
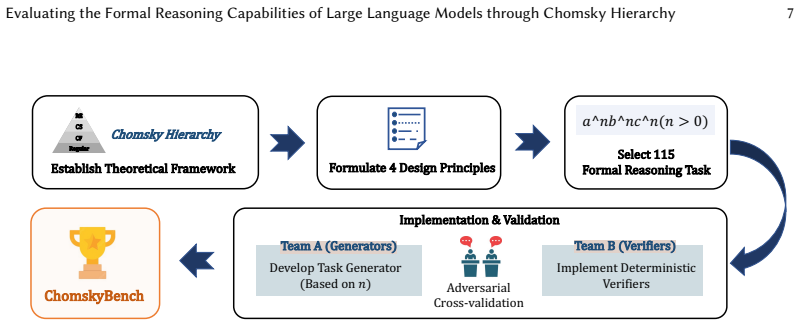


read the original abstract
The formal reasoning capabilities of LLMs are crucial for advancing automated software engineering. However, existing benchmarks for LLMs lack systematic evaluation based on computation and complexity, leaving a critical gap in understanding their formal reasoning capabilities. Therefore, it is still unknown whether SOTA LLMs can grasp the structured, hierarchical complexity of formal languages as defined by Computation Theory. To address this, we introduce ChomskyBench, a benchmark for systematically evaluating LLMs through the lens of Chomsky Hierarchy. Unlike prior work that uses vectorized classification for neural networks, ChomskyBench is the first to combine full Chomsky Hierarchy coverage, process-trace evaluation via natural language, and deterministic symbolic verifiability. ChomskyBench is composed of a comprehensive suite of language recognition and generation tasks designed to test capabilities at each level. Extensive experiments indicate a clear performance stratification that correlates with the hierarchy's levels of complexity. Our analysis reveals a direct relationship where increasing task difficulty substantially impacts both inference length and performance. Furthermore, we find that while larger models and advanced inference methods offer notable relative gains, they face severe efficiency barriers: achieving practical reliability would require prohibitive computational costs, revealing that current limitations stem from inefficiency rather than absolute capability bounds. A time complexity analysis further indicates that LLMs are significantly less efficient than traditional algorithmic programs for these formal tasks. These results delineate the practical limits of current LLMs, highlight the indispensability of traditional software tools, and provide insights to guide the development of future LLMs with more powerful formal reasoning capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChomskyBench, a benchmark spanning the full Chomsky Hierarchy with language recognition and generation tasks, process-trace evaluation in natural language, and deterministic symbolic verification. Experiments on SOTA LLMs show clear performance stratification by hierarchy level, with task difficulty increasing inference length and degrading accuracy. Larger models and advanced inference yield relative gains, yet the authors conclude that practical reliability remains blocked by prohibitive computational costs, implying current formal-reasoning limits arise from inefficiency rather than absolute capability ceilings; a time-complexity comparison further shows LLMs are less efficient than classical algorithms.
Significance. If the central claims hold, the work supplies a theory-grounded, verifiable benchmark that directly ties LLM performance to computational complexity classes, a useful addition for automated software engineering research. Credit is due for the first full Chomsky coverage combined with process traces and external symbolic checking, plus the explicit efficiency comparison to algorithms. The results usefully delineate practical limits and motivate hybrid LLM-plus-tool systems.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the claim that 'current limitations stem from inefficiency rather than absolute capability bounds' rests on relative gains from scale and inference methods, yet no scaling curves, saturation analysis, or near-perfect accuracy results on context-sensitive or type-0 tasks are reported; without these, the inference that further compute would reach practical reliability remains untested.
- [Section 3] ChomskyBench construction (Section 3): task design, sample sizes, exclusion criteria, and controls for evaluation artifacts are not described in sufficient detail, so the reported performance stratification cannot be independently verified or checked for bias in how recognition versus generation tasks map to Chomsky levels.
minor comments (2)
- [Figures and Tables] Figure captions and tables should explicitly state the number of trials per cell and whether error bars represent standard deviation or standard error.
- [Section 4] Clarify the exact prompting template used for process-trace generation so that reproducibility is possible.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim that 'current limitations stem from inefficiency rather than absolute capability bounds' rests on relative gains from scale and inference methods, yet no scaling curves, saturation analysis, or near-perfect accuracy results on context-sensitive or type-0 tasks are reported; without these, the inference that further compute would reach practical reliability remains untested.
Authors: Our claim draws from the consistent relative gains observed across multiple model scales and inference methods in the reported experiments, which show no evidence of hard saturation within the tested regime. We acknowledge that this supports an inference about inefficiency rather than a direct demonstration via scaling curves or near-perfect accuracy on higher levels. In revision we will rephrase the abstract and experiments discussion to present the conclusion as grounded in observed trends while explicitly noting the absence of full scaling analysis and the value of future work on larger regimes. This is a partial revision limited to clarification of scope. revision: partial
-
Referee: [Section 3] ChomskyBench construction (Section 3): task design, sample sizes, exclusion criteria, and controls for evaluation artifacts are not described in sufficient detail, so the reported performance stratification cannot be independently verified or checked for bias in how recognition versus generation tasks map to Chomsky levels.
Authors: We agree that greater detail is required for independent verification and bias assessment. In the revised manuscript we will expand Section 3 with explicit descriptions of task design per Chomsky level, exact sample sizes, exclusion criteria, and controls for evaluation artifacts, including how recognition and generation tasks are balanced and mapped to hierarchy classes. revision: yes
Circularity Check
Empirical benchmark evaluation exhibits no circular derivation
full rationale
The paper defines ChomskyBench as an independent suite of recognition and generation tasks spanning the Chomsky hierarchy, then reports LLM performance, inference-length correlations, and efficiency comparisons to symbolic algorithms. All central claims—including the interpretation that limitations arise from inefficiency rather than absolute bounds—follow directly from these experimental measurements and time-complexity contrasts. No load-bearing step reduces by construction to a fitted parameter, self-referential definition, or self-citation chain; the derivation remains self-contained through external symbolic verification and direct empirical observation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tasks based on Chomsky hierarchy levels accurately capture formal reasoning capabilities relevant to automated software engineering
invented entities (1)
-
ChomskyBench
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearChomskyBench is the first to combine full Chomsky Hierarchy coverage, process-trace evaluation via natural language, and deterministic symbolic verifiability.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLLM performance is strictly stratified by the Chomsky Hierarchy, with a significant performance cliff at the transition from context-free to context-sensitive languages.
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL] https://arxiv.org/abs/2108.07732
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Ayers, Dragomir Radev, and Jeremy Avigad
Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad
-
[3]
arXiv:2302.12433 [cs.CL] https://arxiv.org/abs/2302.12433
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics. arXiv:2302.12433 [cs.CL] https://arxiv.org/abs/2302.12433
- [4]
-
[5]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of artificial general intelligence: early experiments with GPT-4 (2023).arXiv preprint arXiv:2303.127121 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [6]
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
Noam Chomsky. 1956. Three models for the description of language.IRE Transactions on information theory2, 3 (1956), 113–124
work page 1956
- [9]
-
[10]
Chris Cummins, Volker Seeker, Dejan Grubisic, Baptiste Roziere, Jonas Gehring, Gabriel Synnaeve, and Hugh Leather
-
[11]
InProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction
Llm compiler: Foundation language models for compiler optimization. InProceedings of the 34th ACM SIGPLAN International Conference on Compiler Construction. 141–153. , Vol. 1, No. 1, Article . Publication date: April 2026. 20 Dong et al
work page 2026
- [12]
-
[13]
Yihong Dong, Jiazheng Ding, Xue Jiang, Ge Li, Zhuo Li, and Zhi Jin. 2025. CodeScore: Evaluating Code Generation by Learning Code Execution.ACM Trans. Softw. Eng. Methodol.34, 3, Article 77 (Feb. 2025), 22 pages. doi:10.1145/3695991
-
[14]
Yihong Dong, Xue Jiang, Zhi Jin, and Ge Li. 2024. Self-Collaboration Code Generation via ChatGPT.ACM Trans. Softw. Eng. Methodol.33, 7 (2024), 189:1–189:38
work page 2024
-
[15]
Yihong Dong, Xue Jiang, Huanyu Liu, Zhi Jin, Bin Gu, Mengfei Yang, and Ge Li. 2024. Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models. InACL (Findings). Association for Computational Linguistics, 12039–12050
work page 2024
- [16]
-
[17]
Yihong Dong, Xue Jiang, Yongding Tao, Huanyu Liu, Kechi Zhang, Lili Mou, Rongyu Cao, Yingwei Ma, Jue Chen, Binhua Li, Zhi Jin, Fei Huang, Yongbin Li, and Ge Li. 2025. RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization.CoRRabs/2508.00222 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Yihong Dong, Yuchen Liu, Xue Jiang, Bin Gu, Zhi Jin, and Ge Li. 2025. Rethinking Repetition Problems of LLMs in Code Generation. InACL (1). Association for Computational Linguistics, 965–985
work page 2025
-
[19]
Yihong Dong, Zhaoyu Ma, Xue Jiang, Zhiyuan Fan, Jiaru Qian, Yongmin Li, Jianha Xiao, Zhi Jin, Rongyu Cao, Binhua Li, Fei Huang, Yongbin Li, and Ge Li. 2025. Saber: An Efficient Sampling with Adaptive Acceleration and Backtracking Enhanced Remasking for Diffusion Language Model.CoRRabs/2510.18165 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Shubhang Shekhar Dvivedi, Vyshnav Vijay, Sai Leela Rahul Pujari, Shoumik Lodh, and Dhruv Kumar. 2024. A comparative analysis of large language models for code documentation generation. InProceedings of the 1st ACM international conference on AI-powered software. 65–73
work page 2024
- [21]
-
[22]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. 2021. Measuring Coding Challenge Competence With APPS. InNeurIPS Datasets and Benchmarks
work page 2021
-
[23]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2020. The Curious Case of Neural Text Degeneration. InICLR. OpenReview.net
work page 2020
-
[24]
John E Hopcroft, Rajeev Motwani, and Jeffrey D Ullman. 2001. Introduction to automata theory, languages, and computation.Acm Sigact News32, 1 (2001), 60–65
work page 2001
-
[25]
1969.Formal languages and their relation to automata
John E Hopcroft and Jeffrey D Ullman. 1969.Formal languages and their relation to automata. Addison-Wesley Longman Publishing Co., Inc
work page 1969
-
[26]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large language models for software engineering: A systematic literature review.ACM Transactions on Software Engineering and Methodology33, 8 (2024), 1–79
work page 2024
-
[27]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2024. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv:2403.07974 [cs.SE] https://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Jiang, Wenda Li, and Mateja Jamnik
Albert Q. Jiang, Wenda Li, and Mateja Jamnik. 2024. Multi-language Diversity Benefits Autoformalization. InThe Thirty- eighth Annual Conference on Neural Information Processing Systems. https://openreview.net/forum?id=2jjfRm2R6D
work page 2024
-
[29]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2024. A survey on large language models for code generation.arXiv preprint arXiv:2406.00515(2024)
work page internal anchor Pith review arXiv 2024
- [30]
-
[31]
Xue Jiang, Yihong Dong, Mengyang Liu, Hongyi Deng, Tian Wang, Yongding Tao, Rongyu Cao, Binhua Li, Zhi Jin, Wenpin Jiao, Fei Huang, Yongbin Li, and Ge Li. 2025. CodeRL+: Improving Code Generation via Reinforcement with Execution Semantics Alignment.CoRRabs/2510.18471 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Xue Jiang, Yihong Dong, Yongding Tao, Huanyu Liu, Zhi Jin, and Ge Li. 2025. ROCODE: Integrating Backtracking Mechanism and Program Analysis in Large Language Models for Code Generation. InICSE. IEEE, 334–346
work page 2025
-
[33]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-Planning Code Generation with Large Language Models.ACM Trans. Softw. Eng. Methodol.33, 7 (2024), 182:1–182:30
work page 2024
-
[34]
Xue Jiang, Jiaru Qian, Xianjie Shi, Chenjie Li, Hao Zhu, Ziyu Wang, Jielun Zhang, Zheyu Zhao, Kechi Zhang, Jia Li, Wenpin Jiao, Zhi Jin, Ge Li, and Yihong Dong. 2026. KOCO-BENCH: Can Large Language Models Leverage Domain Knowledge in Software Development?CoRRabs/2601.13240 (2026). , Vol. 1, No. 1, Article . Publication date: April 2026. Evaluating the For...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Xue Jiang, Tianyu Zhang, Ge Li, Mengyang Liu, Taozhi Chen, Zhenhua Xu, Binhua Li, Wenpin Jiao, Zhi Jin, Yongbin Li, and Yihong Dong. 2026. Think Anywhere in Code Generation.CoRRabs/2603.29957 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/ 2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Haonan Li, Yu Hao, Yizhuo Zhai, and Zhiyun Qian. 2024. Enhancing static analysis for practical bug detection: An llm-integrated approach.Proceedings of the ACM on Programming Languages8, OOPSLA1 (2024), 474–499
work page 2024
- [38]
-
[39]
Jia Li, Ge Li, Yunfei Zhao, Yongmin Li, Huanyu Liu, Hao Zhu, Lecheng Wang, Kaibo Liu, Zheng Fang, Lanshen Wang, Jiazheng Ding, Xuanming Zhang, Yuqi Zhu, Yihong Dong, Zhi Jin, Binhua Li, Fei Huang, and Yongbin Li
-
[40]
arXiv:2405.19856 [cs.CL] https://arxiv.org/abs/2405.19856
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories. arXiv:2405.19856 [cs.CL] https://arxiv.org/abs/2405.19856
- [41]
-
[42]
Jianqiao Lu, Yingjia Wan, Zhengying Liu, Yinya Huang, Jing Xiong, Chengwu Liu, Jianhao Shen, Hui Jin, Jipeng Zhang, Haiming Wang, Zhicheng Yang, Jing Tang, and Zhijiang Guo. 2024. Process-Driven Autoformalization in Lean 4. arXiv:2406.01940 [cs.CL] https://arxiv.org/abs/2406.01940
-
[43]
Ziyu Mao, Jingyi Wang, Jun Sun, Shengchao Qin, and Jiawen Xiong. 2025. LLM-aided Automatic Modelling for Security Protocol Verification. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE Computer Society, 734–734
work page 2025
-
[44]
Fangwen Mu, Lin Shi, Song Wang, Zhuohao Yu, Binquan Zhang, ChenXue Wang, Shichao Liu, and Qing Wang. 2024. Clarifygpt: A framework for enhancing llm-based code generation via requirements clarification.Proceedings of the ACM on Software Engineering1, FSE (2024), 2332–2354
work page 2024
- [45]
-
[46]
Ernest Nagel. 1979.The structure of science. Vol. 411. Hackett publishing company Indianapolis
work page 1979
-
[47]
Jorge Pérez, Pablo Barceló, and Javier Marinkovic. 2021. Attention is turing complete. 22, 1, Article 75 (2021), 35 pages
work page 2021
- [48]
-
[49]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300 [cs.CL] https://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [50]
-
[51]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2023. Attention Is All You Need. arXiv:1706.03762 [cs.CL] https://arxiv.org/abs/1706.03762
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Haiming Wang, Mert Unsal, Xiaohan Lin, Mantas Baksys, Junqi Liu, Marco Dos Santos, Flood Sung, Marina Vinyes, Zhenzhe Ying, Zekai Zhu, Jianqiao Lu, Hugues de Saxcé, Bolton Bailey, Chendong Song, Chenjun Xiao, Dehao Zhang, Ebony Zhang, Frederick Pu, Han Zhu, Jiawei Liu, Jonas Bayer, Julien Michel, Longhui Yu, Léo Dreyfus-Schmidt, Lewis Tunstall, Luigi Paga...
-
[53]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InNeurIPS
work page 2022
-
[54]
Yuhuai Wu, Albert Q. Jiang, Wenda Li, Markus N. Rabe, Charles Staats, Mateja Jamnik, and Christian Szegedy. 2022. Autoformalization with Large Language Models. arXiv:2205.12615 [cs.LG] https://arxiv.org/abs/2205.12615
- [55]
-
[56]
Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. 2023. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. arXiv:2306.15626 [cs.LG] https://arxiv.org/abs/2306.15626
- [57]
-
[58]
Yifan Zhang, Wenyu Du, Dongming Jin, Jie Fu, and Zhi Jin. 2025. Finite State Automata Inside Transformers with Chain-of-Thought: A Mechanistic Study on State Tracking. arXiv:2502.20129 [cs.CL] https://arxiv.org/abs/2502.20129 , Vol. 1, No. 1, Article . Publication date: April 2026. 22 Dong et al
- [59]
-
[60]
Xin Zhou, Kisub Kim, Bowen Xu, DongGyun Han, and David Lo. 2024. Out of sight, out of mind: Better automatic vulnerability repair by broadening input ranges and sources. InProceedings of the IEEE/ACM 46th international conference on software engineering. 1–13. , Vol. 1, No. 1, Article . Publication date: April 2026
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.