Recognition: 2 theorem links
· Lean TheoremSpeaker-Reasoner: Scaling Interaction Turns and Reasoning Patterns for Timestamped Speaker-Attributed ASR
Pith reviewed 2026-05-13 18:19 UTC · model grok-4.3
The pith
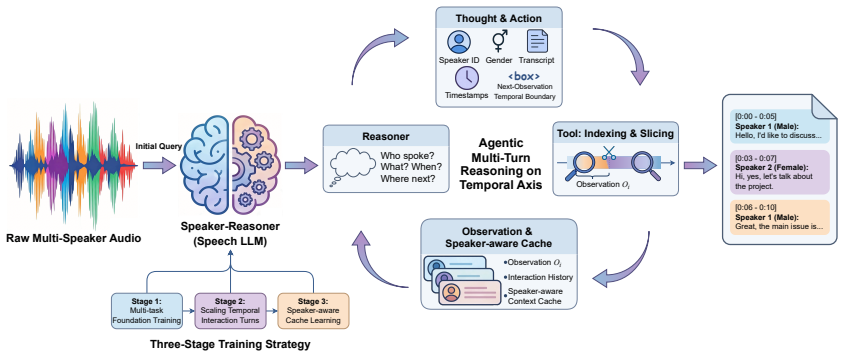
Speaker-Reasoner improves multi-speaker transcription by breaking audio into iterative reasoning steps instead of single-pass processing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Speaker-Reasoner establishes that an agentic multi-turn temporal reasoning process in a speech LLM, paired with a speaker-aware cache and three-stage training, enables joint modeling of speaker attributes, timestamps, and transcription while scaling beyond context limits and outperforming strong baselines on multi-speaker datasets with overlaps.
What carries the argument
The agentic multi-turn temporal reasoning loop that iteratively performs global audio structure analysis, autonomous temporal boundary prediction, and fine-grained segment processing.
If this is right
- Better accuracy on overlapping speech and complex turn-taking compared to conventional single-pass models.
- Extended processing of audio exceeding the model's native context window via the speaker-aware cache.
- Joint output of speaker identity, gender, timestamps, and text in one end-to-end system.
- Reduced need for manual audio segmentation in multi-speaker scenarios.
Where Pith is reading between the lines
- The iterative reasoning pattern could transfer to other audio understanding tasks that require global structure awareness, such as meeting summarization.
- If the cache mechanism proves stable, similar extensions might allow speech models to handle hour-long recordings without retraining.
- The approach opens the possibility of combining this reasoning style with real-time streaming inputs for live captioning systems.
Load-bearing premise
The three-stage training strategy successfully instills reliable autonomous temporal reasoning that generalizes to new audio without additional tuning.
What would settle it
Performance on a held-out dataset containing longer conversations or different overlap densities fails to exceed single-pass baselines after the same training procedure.
Figures
read the original abstract
Transcribing and understanding multi-speaker conversations requires speech recognition, speaker attribution, and timestamp localization. While speech LLMs excel at single-speaker tasks, multi-speaker scenarios remain challenging due to overlapping speech, backchannels, rapid turn-taking, and context window constraints. We propose Speaker-Reasoner, an end-to-end Speech LLM with agentic multi-turn temporal reasoning. Instead of single-pass inference, the model iteratively analyzes global audio structure, autonomously predicts temporal boundaries, and performs fine-grained segment analysis, jointly modeling speaker identity, gender, timestamps, and transcription. A speaker-aware cache further extends processing to audio exceeding the training context window. Trained with a three-stage progressive strategy, Speaker-Reasoner achieves consistent improvements over strong baselines on AliMeeting and AISHELL-4 datasets, particularly in handling overlapping speech and complex turn-taking.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity in derivation chain
full rationale
The provided abstract and description present Speaker-Reasoner as an architectural extension using agentic multi-turn temporal reasoning, iterative analysis, and a speaker-aware cache, trained via a three-stage progressive strategy. No equations, self-definitions, fitted parameters renamed as predictions, or load-bearing self-citations are exhibited that would reduce claimed results to inputs by construction. Improvements are asserted over external baselines on AliMeeting and AISHELL-4 without evidence of tautological reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative multi-turn reasoning can be stably trained in speech LLMs without destabilizing the base model
invented entities (2)
-
Speaker-aware cache
no independent evidence
-
Agentic multi-turn temporal reasoning
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearagentic multi-turn temporal reasoning... global-to-local paradigm... speaker-aware context cache... three-stage progressive training strategy
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleariteratively analyzes global audio structure, autonomously predicts temporal boundaries
Reference graph
Works this paper leans on
-
[1]
Introduction In real-world multi-speaker conversational scenarios such as meetings and phone calls, comprehensive conversation under- standing requires more than speech recognition alone. It de- mands the joint modeling of speaker attribution, fine-grained timestamp localization, and transcription [1, 2]. This task is essential for applications such as me...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Method Speaker-Reasoner addresses speaker-attributed ASR for multi- speaker long-form recordings. The model takes raw multi- speaker audio as input and produces outputs containing speaker identity, gender, timestamps, and transcription through multi- turn interaction. The key challenge is that a single-pass decoder often strug- gles with overlapping speec...
-
[3]
Experiments 3.1. Implementation Details We initialize Speaker-Reasoner from Qwen3-Omni, a 30B- parameter multimodal LLM with a MoE architecture that ac- tivates 3B parameters per forward pass. Training is conducted using the MS-Swift framework [23] with Megatron-LM back- end on 8 NVIDIA A100 GPUs. We apply LoRA with rank 8 and scaling factor 32 to all lin...
-
[4]
Conclusion In this work, we present Speaker-Reasoner, an end-to-end Speech LLM for timestamped speaker-attributed ASR. We in- troduce an agentic multi-turn reasoning mechanism that shifts inference from single-pass decoding to iterative global-to-local reasoning. This enables the model to autonomously resolve complex multi-speaker scenarios, while a speak...
-
[5]
M. Gao, S. Wu, H. Chen, J. Du, C.-H. Lee, S. Watanabe, J. Chen, S. M. Siniscalchi, and O. Scharenborg, “The multimodal infor- mation based speech processing (MISP) 2025 challenge: Audio- visual diarization and recognition,” inProc. Interspeech, 2025
work page 2025
-
[6]
H. Yin, Y . Chen, C. Deng, L. Cheng, H. Wang, C.-H. Tan, Q. Chen, W. Wang, and X. Li, “Speakerlm: End-to-end versa- tile speaker diarization and recognition with multimodal large lan- guage models,”CoRR, vol. abs/2508.06372, 2025
-
[7]
D. Raj, P. Denisov, Z. Chen, H. Erdogan, Z. Huang, M. He, S. Watanabe, J. Du, T. Yoshioka, Y . Luo, N. Kanda, J. Li, S. Wis- dom, and J. R. Hershey, “Integration of speech separation, diariza- tion, and recognition for multi-speaker meetings: System descrip- tion, comparison, and analysis,” inProc. SLT. IEEE, 2021, pp. 897–904
work page 2021
-
[8]
Summary on the ICASSP 2022 multi-channel multi- party meeting transcription grand challenge,
F. Yu, S. Zhang, P. Guo, Y . Fu, Z. Du, S. Zheng, W. Huang, L. Xie, Z.-H. Tan, D. Wang, Y . Qian, K. A. Lee, Z. Yan, B. Ma, X. Xu, and H. Bu, “Summary on the ICASSP 2022 multi-channel multi- party meeting transcription grand challenge,” inProc. ICASSP. IEEE, 2022, pp. 9156–9160
work page 2022
-
[9]
One model to rule them all ? towards end-to-end joint speaker diarization and speech recognition,
S. Cornell, J.-W. Jung, S. Watanabe, and S. Squartini, “One model to rule them all ? towards end-to-end joint speaker diarization and speech recognition,” inProc. ICASSP. IEEE, 2024, pp. 11 856– 11 860
work page 2024
-
[10]
TS-SEP: Joint diarization and separation con- ditioned on estimated speaker embeddings,
C. B ¨oddeker, A. S. Subramanian, G. Wichern, R. Haeb-Umbach, and J. Le Roux, “TS-SEP: Joint diarization and separation con- ditioned on estimated speaker embeddings,”IEEE ACM Trans. Audio Speech Lang. Process., vol. 32, pp. 1185–1197, 2024
work page 2024
-
[11]
S. Cornell, M. Wiesner, S. Watanabe, D. Raj, X. Chang, P. Garc´ıa, Y . Masuyama, Z.-Q. Wang, S. Squartini, and S. Khu- danpur, “The chime-7 DASR challenge: Distant meeting tran- scription with multiple devices in diverse scenarios,”CoRR, vol. abs/2306.13734, 2023
-
[12]
Speaker diarization: A review of objectives and methods,
D. O’Shaughnessy, “Speaker diarization: A review of objectives and methods,”Applied Sciences, vol. 15, no. 4, 2025
work page 2025
-
[13]
Seri- alized output training for end-to-end overlapped speech recogni- tion,
N. Kanda, Y . Gaur, X. Wang, Z. Meng, and T. Yoshioka, “Seri- alized output training for end-to-end overlapped speech recogni- tion,” inProc. Interspeech, 2020, pp. 2797–2801
work page 2020
-
[14]
Adapting multi-lingual ASR models for handling multiple talkers,
C. Li, Y . Qian, Z. Chen, N. Kanda, D. Wang, T. Yoshioka, Y . Qian, and M. Zeng, “Adapting multi-lingual ASR models for handling multiple talkers,” inProc. Interspeech, 2023, pp. 1314–1318
work page 2023
-
[15]
Y . Chu, J. Xu, Q. Yang, H. Wei, X. Wei, Z. Guo, Y . Leng, Y . Lv, J. He, J. Lin, C. Zhou, and J. Zhou, “Qwen2-audio technical re- port,”CoRR, vol. abs/2407.10759, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
KimiTeam, D. Ding, Z. Ju, Y . Leng, S. Liu, T. Liu, Z. Shang, K. Shen, W. Song, X. Tan, H. Tang, Z. Wang, C. Wei, Y . Xin, X. Xu, J. Yu, Y . Zhang, X. Zhou, Y . Charles, J. Chen, Y . Chen, Y . Du, W. He, Z. Hu, G. Lai, Q. Li, Y . Liu, W. Sun, J. Wang, Y . Wang, Y . Wu, Y . Wu, D. Yang, H. Yang, Y . Yang, Z. Yang, A. Yin, R. Yuan, Y . Zhang, and Z. Zhou, “...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,
A. Goel, S. Ghosh, J. Kim, S. Kumar, Z. Kong, S.-g. Lee, C.-H. H. Yang, R. Duraiswami, D. Manocha, R. Valle, and B. Catanzaro, “Audio flamingo 3: Advancing audio intelligence with fully open large audio language models,”CoRR, vol. abs/2507.08128, 2025
-
[18]
Step-audio 2 technical report,
StepFun Audio Team, “Step-audio 2 technical report,”CoRR, vol. abs/2507.16632, 2025
-
[19]
Mimo-audio: Audio language models are few-shot learners,
LLM-Core Xiaomi, “Mimo-audio: Audio language models are few-shot learners,”CoRR, vol. abs/2512.23808, 2025
-
[20]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu, Y . Lv, Y . Wang, D. Guo, H. Wang, L. Ma, P. Zhang, X. Zhang, H. Hao, Z. Guo, B. Yang, B. Zhang, Z. Ma, X. Wei, S. Bai, K. Chen, X. Liu, P. Wang, M. Yang, D. Liu, X. Ren, B. Zheng, R. Men, F. Zhou, B. Yu, J. Yang, L. Yu, J. Zhou, and J. Lin, “Qwen3-omni technical report,”CoRR,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
VIBEVOICE-ASR technical re- port,
Z. Peng, J. Yu, Y . Chang, Z. Wang, L. Dong, Y . Hao, Y . Tu, C. Yang, W. Wang, S. Xu, Y . Sun, H. Bao, W. Xu, Y . Zhu, Z. Wang, T. Song, Y . Xia, Z. Chi, S. Huang, L. Wang, C. Ding, S. Wang, X. Chen, and F. Wei, “VIBEVOICE-ASR technical re- port,”CoRR, vol. abs/2601.18184, 2026
-
[22]
Tagspeech: End-to-end multi- speaker ASR and diarization with fine-grained temporal ground- ing,
M. Huo, Y . Shao, and Y . Zhang, “Tagspeech: End-to-end multi- speaker ASR and diarization with fine-grained temporal ground- ing,”CoRR, vol. abs/2601.06896, 2026
-
[23]
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and di- arization on long audio,”CoRR, vol. abs/2511.16046, 2025
-
[24]
Large language model can transcribe speech in multi-talker scenarios with versatile instructions,
L. Meng, S. Hu, J. Kang, Z. Li, Y . Wang, W. Wu, X. Wu, X. Liu, and H. Meng, “Large language model can transcribe speech in multi-talker scenarios with versatile instructions,” in Proc. ICASSP. IEEE, 2025, pp. 1–5
work page 2025
-
[25]
Mini-o3: Scaling up reasoning patterns and interaction turns for visual search
X. Lai, J. Li, W. Li, T. Liu, T. Li, and H. Zhao, “Mini-o3: Scal- ing up reasoning patterns and interaction turns for visual search,” CoRR, vol. abs/2509.07969, 2025
-
[26]
Open-o3 video: Grounded video reasoning with explicit spatio-temporal evi- dence,
J. Meng, X. Li, H. Wang, Y . Tan, T. Zhang, L. Kong, Y . Tong, A. Wang, Z. Teng, Y . Wang, and Z. Wang, “Open-o3 video: Grounded video reasoning with explicit spatio-temporal evi- dence,”CoRR, vol. abs/2510.20579, 2025
-
[27]
SWIFT: A scal- able lightweight infrastructure for fine-tuning,
Y . Zhao, J. Huang, J. Hu, X. Wang, Y . Mao, D. Zhang, Z. Jiang, Z. Wu, B. Ai, A. Wang, W. Zhou, and Y . Chen, “SWIFT: A scal- able lightweight infrastructure for fine-tuning,” inProc. AAAI, 2025, pp. 29 733–29 735
work page 2025
-
[28]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. ICLR, 2019
work page 2019
-
[29]
Y . Liang, M. Shi, F. Yu, Y . Li, S. Zhang, Z. Du, Q. Chen, L. Xie, Y . Qian, J. Wu, Z. Chen, K. A. Lee, Z. Yan, and H. Bu, “The second multi-channel multi-party meeting transcription challenge (m2met 2.0): A benchmark for speaker-attributed ASR,” inProc. ASRU. IEEE, 2023, pp. 1–8
work page 2023
-
[30]
Y . Fu, L. Cheng, S. Lv, Y . Jv, Y . Kong, Z. Chen, Y . Hu, L. Xie, J. Wu, H. Bu, X. Xu, J. Du, and J. Chen, “AISHELL-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,” inProc. Inter- speech, 2021, pp. 3665–3669
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.