Recognition: unknown
NIRVANA: A Comprehensive Dataset for Reproducing How Students Use Generative AI for Essay Writing
Pith reviewed 2026-05-10 16:58 UTC · model grok-4.3
The pith
A dataset of 77 students writing essays with ChatGPT logs every keystroke, prompt, and copy action so the full writing process can be replayed and analyzed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
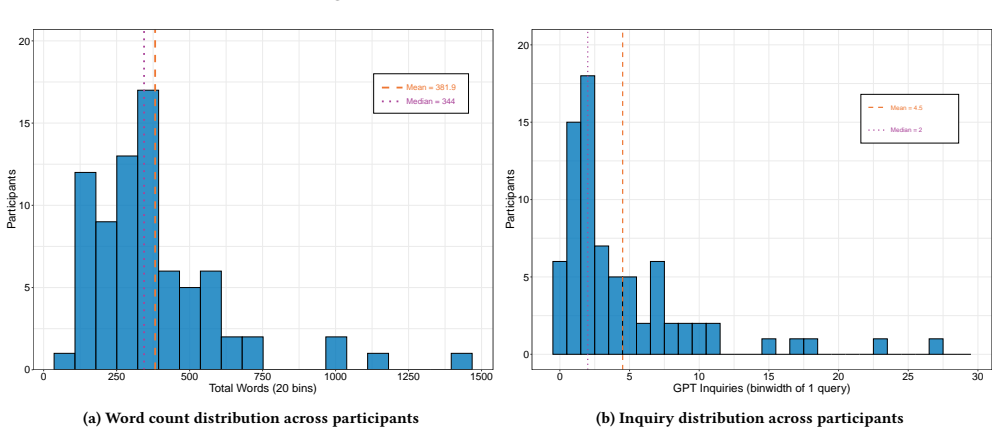
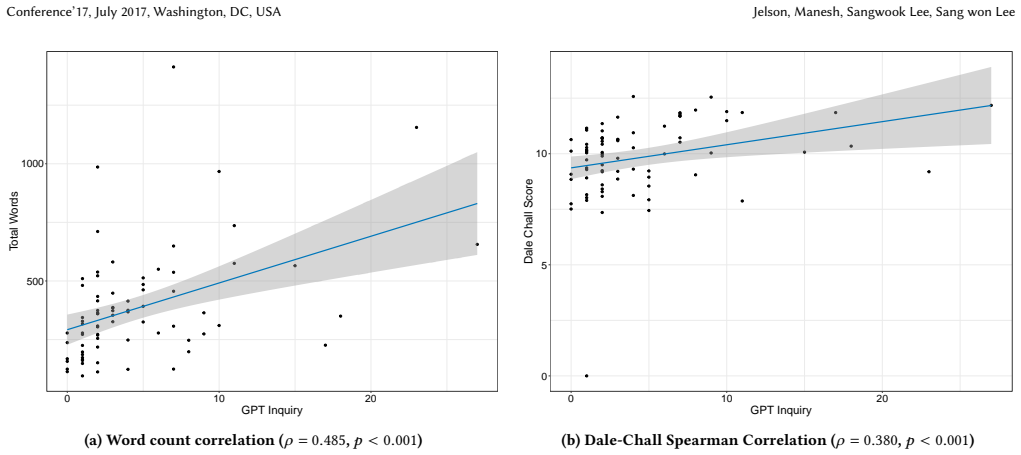
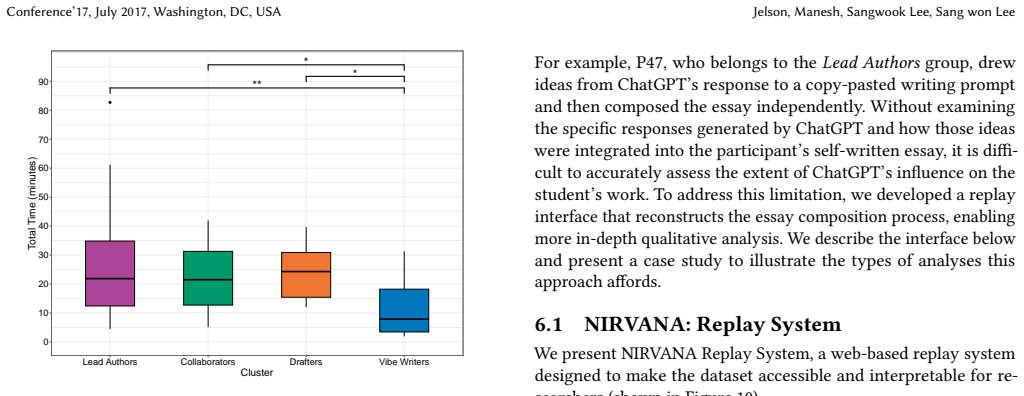
By capturing keystroke-level writing behavior, full ChatGPT conversation histories, and all text copied from ChatGPT, the dataset enables a complete reconstruction of the writing process and reveals how AI assistance shapes student work, including variation in query frequency and its link to essay length and readability, along with four distinct writing profiles defined by contribution and revision patterns: Lead Authors, Collaborators, Drafters, and Vibe Writers.
What carries the argument
The NIRVANA dataset, which combines keystroke logging, full AI conversation records, and copied text segments to support exact replay of each student's writing process.
If this is right
- Educators can examine specific moments when students request AI help to design better guidance on when and how to use such tools.
- The four profiles indicate that different students rely on AI in distinct ways, suggesting tailored feedback rather than uniform rules.
- Correlations between query frequency and essay traits such as length and readability provide measurable indicators of AI influence on output quality.
- The replay interface allows systematic review of individual interactions, turning raw logs into observable sequences of student-AI collaboration.
Where Pith is reading between the lines
- Similar detailed logging could be extended to other writing tasks or AI tools to test whether the same profiles appear across subjects.
- If the profiles prove stable over time, assignment design could deliberately steer students toward profiles that emphasize original contribution.
- The dataset opens the possibility of comparing monitored versus unmonitored conditions to quantify any effect of awareness on behavior.
- Policy discussions on AI in education could use the observed patterns to set limits on acceptable AI use based on measurable student actions rather than self-reports.
Load-bearing premise
Students used ChatGPT in their usual way even though they knew every action was being recorded and that the patterns seen in this group of 77 participants apply to students more broadly.
What would settle it
A follow-up study that logs the same essay task without any monitoring and finds markedly different query rates, revision amounts, or profile distributions would show that the recorded behaviors do not match natural use.
Figures







read the original abstract
With the rapid adoption of AI writing assistants in education, educators and researchers need empirical evidence to understand the impact on student writing and inform effective pedagogical design. Despite widespread use, we lack systematic understanding of how students engage with these tools during authentic writing tasks: when they seek assistance, what they ask, and how they incorporate AI-generated content into their essays. This gap limits evidence-based policy development and rigorous evaluation of generative AI's learning effects. To address this gap, we introduce NIRVANA, a dataset capturing how university students use generative AI while writing an analytical essay. The dataset includes 77 students who completed an essay task with access to ChatGPT, recording keystroke-level writing behavior, full ChatGPT conversation histories, and all text copied from ChatGPT, enabling a complete reconstruction of the writing process and revealing how AI assistance shapes student work. Our analysis identifies key behavioral patterns, including variation in ChatGPT query frequency and its relationship to essay characteristics such as length and readability. We identify four writing profiles based on students' contribution and revision patterns: Lead Authors, Collaborators, Drafters, and Vibe Writers. To support deeper investigation, we developed a replay interface that reconstructs the writing process; qualitative analysis of sampled replays demonstrates how this tool enables systematic examination of student-AI interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the NIRVANA dataset collected from 77 university students who completed an analytical essay task with access to ChatGPT. It records keystroke-level writing behavior, full ChatGPT conversation histories, and all text copied from ChatGPT, enabling complete reconstruction of the writing process. The authors report behavioral patterns such as variation in query frequency and its relation to essay length and readability, and classify students into four profiles (Lead Authors, Collaborators, Drafters, and Vibe Writers) based on contribution and revision patterns. A replay interface is provided to support qualitative examination of student-AI interactions.
Significance. If the data collection procedures are sound and the observed patterns are not substantially distorted by the monitored setting, NIRVANA would constitute a valuable resource for HCI and education research. The multimodal logs (keystrokes, full histories, copied text) allow fine-grained process reconstruction that is rare in this domain and could support reproducible studies of how generative AI shapes writing strategies and outcomes.
major comments (3)
- [Data collection and experimental setup] The manuscript provides no discussion of potential observer or Hawthorne effects arising from the explicit recording of every keystroke and conversation. This is load-bearing for the central claim that the dataset captures how students 'use generative AI' in a manner that reveals authentic shaping of student work, as the controlled, monitored task may have systematically altered query frequency, revision behavior, or strategy selection.
- [Analysis and profile identification] The identification of the four writing profiles is described only at a high level in the abstract and analysis summary. No quantitative definitions of 'contribution and revision patterns,' clustering or classification method, threshold criteria, or stability checks across subsamples are provided, undermining the claim that these profiles are stable and reproducible.
- [Methods] Essential methodological details are absent: participant recruitment procedures, demographics, informed consent process, IRB/ethics approval, data cleaning steps, and any controls for task-specific effects. These omissions prevent evaluation of selection bias, generalizability beyond the single essay task, and reproducibility of the reported patterns.
minor comments (2)
- The replay interface is introduced as enabling systematic examination, but no details on its implementation, data format, or public release are given; adding these would strengthen the dataset's utility without altering the core claims.
- [Abstract] The abstract references relationships between query frequency and essay characteristics (length, readability) but does not preview any quantitative results, effect sizes, or figures; including a brief summary would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment point by point below, indicating the revisions we will make to strengthen the paper's clarity, completeness, and transparency.
read point-by-point responses
-
Referee: [Data collection and experimental setup] The manuscript provides no discussion of potential observer or Hawthorne effects arising from the explicit recording of every keystroke and conversation. This is load-bearing for the central claim that the dataset captures how students 'use generative AI' in a manner that reveals authentic shaping of student work, as the controlled, monitored task may have systematically altered query frequency, revision behavior, or strategy selection.
Authors: We agree that the absence of an explicit discussion of observer or Hawthorne effects is a limitation in the current manuscript. The data collection occurred in a monitored setting with keystroke logging and full conversation capture, which may have influenced participants' query strategies or revision behaviors compared to unmonitored use. In the revised version, we will add a dedicated paragraph in the Limitations section acknowledging this effect, describing the steps taken to make the task feel as natural as possible (e.g., framing it as a standard course assignment), and cautioning readers about generalizability to fully private writing contexts. This addition will provide a more balanced interpretation of the dataset without overstating its ecological validity. revision: yes
-
Referee: [Analysis and profile identification] The identification of the four writing profiles is described only at a high level in the abstract and analysis summary. No quantitative definitions of 'contribution and revision patterns,' clustering or classification method, threshold criteria, or stability checks across subsamples are provided, undermining the claim that these profiles are stable and reproducible.
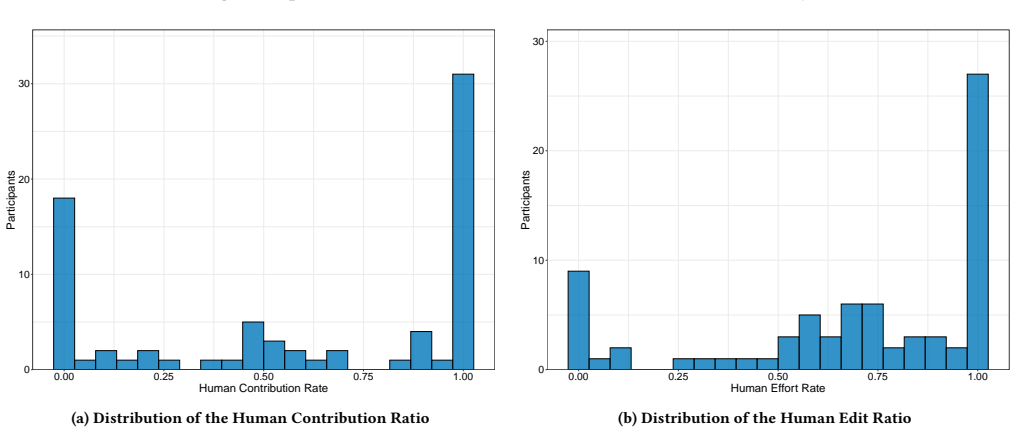
Authors: The referee correctly identifies that the profile descriptions lack sufficient quantitative detail and methodological transparency. The four profiles (Lead Authors, Collaborators, Drafters, and Vibe Writers) were derived from two primary dimensions: (1) contribution, measured as the percentage of final essay text originating from the student versus copied AI output, and (2) revision patterns, quantified via edit distance and number of post-copy modifications per paragraph. These features were normalized and used for classification. However, we acknowledge the manuscript does not specify the exact clustering procedure, any thresholds applied, or validation metrics. In the revision, we will expand the Analysis section with a new subsection providing precise definitions of all metrics, the classification algorithm and parameters, example threshold values, and stability assessments (e.g., consistency across bootstrap subsamples). This will make the profiles fully reproducible. revision: yes
-
Referee: [Methods] Essential methodological details are absent: participant recruitment procedures, demographics, informed consent process, IRB/ethics approval, data cleaning steps, and any controls for task-specific effects. These omissions prevent evaluation of selection bias, generalizability beyond the single essay task, and reproducibility of the reported patterns.
Authors: We accept that the Methods section in the submitted manuscript is insufficiently detailed on these points. The revised manuscript will expand this section to include: recruitment via university-wide email lists and course announcements targeting students in writing-related classes; summary demographics from a pre-task survey (age, gender, major, and prior generative AI experience); the electronic informed consent procedure with specifics on data anonymization and usage; reference to the IRB approval (including protocol number); data cleaning protocols (e.g., exclusion criteria for incomplete logs or technical errors); and rationale for the analytical essay task with discussion of potential task-specific effects. These additions will allow readers to better evaluate selection bias, generalizability, and reproducibility. revision: yes
Circularity Check
No circularity: purely empirical dataset and observational profile identification
full rationale
The paper is an observational study that collects keystroke logs, ChatGPT histories, and copied text from 77 students completing a single essay task, then reports behavioral patterns and four profiles (Lead Authors, Collaborators, Drafters, Vibe Writers) derived directly from those observations. No equations, fitted parameters, predictions, or derivation chains exist that could reduce to self-definition or self-citation. Profile labels are post-hoc categorizations of measured contribution/revision metrics; the central claim that the dataset enables reconstruction rests on the recorded data itself rather than any circular reduction. External-validity concerns (observer effects) are separate from circularity and do not appear in any load-bearing step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The recorded interactions reflect students' typical behavior with generative AI outside the study setting.
- domain assumption The sample of 77 students is adequate to identify stable behavioral profiles applicable beyond this cohort.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. https://www.act.org/content/act/en/products-and-services/the-act/test- preparation/writing-sample-essays.html?page=0&chapter=0
-
[2]
Jisuanke/CodeMirror-Record
2025. Jisuanke/CodeMirror-Record. https://github.com/Jisuanke/CodeMirror- Record original-date: 2019-05-08T13:32:58Z
2025
-
[3]
Catherine Adams, Patti Pente, Gillian Lemermeyer, Joni Turville, and Geoffrey Rockwell. 2022. Artificial Intelligence and Teachers’ New Ethical Obligations.The International Review of Information Ethics31, 1 (Nov. 2022). doi:10.29173/irie483 Number: 1
-
[4]
Tazin Afrin, Omid Kashefi, Christopher Olshefski, Diane Litman, Rebecca Hwa, and Amanda Godley. 2021. Effective Interfaces for Student-Driven Revision Sessions for Argumentative Writing. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems (CHI ’21). Association for Computing Machinery, New York, NY, USA, 1–13. doi:10.1145/341176...
-
[5]
James B. Avey, Bruce J. Avolio, Craig D. Crossley, and Fred Luthans. 2009. Psy- chological ownership: theoretical extensions, measurement and relation to work outcomes.Journal of Organizational Behavior30, 2 (2009), 173–191. doi:10.1002/ job.583 _eprint: https://onlinelibrary.wiley.com/doi/pdf/10.1002/job.583
-
[6]
Alex Barrett and Austin Pack. 2023. Not quite eye to A.I.: student and teacher perspectives on the use of generative artificial intelligence in the writing process. International Journal of Educational Technology in Higher Education20, 1 (Nov. 2023), 59. doi:10.1186/s41239-023-00427-0
-
[7]
Matt Bower, Jodie Torrington, Jennifer W. M. Lai, Peter Petocz, and Mark Alfano
-
[8]
How should we change teaching and assessment in response to increasingly powerful generative Artificial Intelligence? Outcomes of the ChatGPT teacher survey.Education and Information Technologies29, 12 (Aug. 2024), 15403–15439. doi:10.1007/s10639-023-12405-0
-
[9]
Kauffman, Courtney McKim, and Sharon Zumbrunn
Roger Bruning, Michael Dempsey, Douglas F. Kauffman, Courtney McKim, and Sharon Zumbrunn. 2013. Examining dimensions of self-efficacy for writing. Journal of Educational Psychology105, 1 (2013), 25–38. doi:10.1037/a0029692 Place: US Publisher: American Psychological Association
-
[10]
Tuhin Chakrabarty, Philippe Laban, Divyansh Agarwal, Smaranda Muresan, and Chien-Sheng Wu. 2024. Art or Artifice? Large Language Models and the False Promise of Creativity. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–34. doi:10.1145/3613904.3642731
-
[11]
Tuhin Chakrabarty, Vishakh Padmakumar, Faeze Brahman, and Smaranda Mure- san. 2024. Creativity Support in the Age of Large Language Models: An Empirical Study Involving Professional Writers. InProceedings of the 16th Conference on Creativity & Cognition (C&C ’24). Association for Computing Machinery, New York, NY, USA, 132–155. doi:10.1145/3635636.3656201
-
[12]
Olckers Chantal. 2012. Psychological ownership: Development of an instrument. SA Journal of Industrial Psychology39 (Dec. 2012), 1–13. doi:10.4102/sajip.v39i2. 1105
-
[13]
Fumian Chen, Sotheara Veng, Joshua Wilson, Xiaoming Li, and Hui Fang. 2025. CoachGPT: A Scaffolding-based Academic Writing Assistant. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25). Association for Computing Machinery, New York, NY, USA, 4051–4055. doi:10.1145/3726302.3730143
-
[14]
Erin Cherry and Celine Latulipe. 2014. Quantifying the Creativity Support of Digital Tools through the Creativity Support Index.ACM Trans. Comput.-Hum. Interact.21, 4 (June 2014), 21:1–21:25. doi:10.1145/2617588
-
[15]
William Condon and Diane Kelly-Riley. 2004. Assessing and teaching what we value: The relationship between college-level writing and critical thinking abilities.Assessing Writing9, 1 (2004), 56–75
2004
-
[16]
Debby R. E. Cotton, Peter A. Cotton, and J. Reuben Shipway. 2023. Chatting and cheating: Ensuring academic integrity in the era of ChatGPT.Innovations in Education and Teaching International0, 0 (2023), 1–12. doi:10.1080/14703297. 2023.2190148 _eprint: https://doi.org/10.1080/14703297.2023.2190148
-
[17]
Helen Crompton and Diane Burke. 2023. Artificial intelligence in higher edu- cation: the state of the field.International Journal of Educational Technology in Higher Education20, 1 (April 2023), 22. doi:10.1186/s41239-023-00392-8
-
[18]
Edgar Dale and Jeanne S. Chall. 1948. A Formula for Predicting Readability. Educational Research Bulletin27, 1 (1948), 11–28. https://www.jstor.org/stable/ 1473169
1948
-
[19]
Fred D. Davis. 1989. Perceived Usefulness, Perceived Ease of Use, and User Acceptance of Information Technology.MIS Quarterly13, 3 (1989), 319–340. doi:10.2307/249008 Publisher: Management Information Systems Research Center, University of Minnesota
-
[20]
Damian Okaibedi Eke. 2023. ChatGPT and the rise of generative AI: Threat to academic integrity?Journal of Responsible Technology13 (2023), 100060. doi:10.1016/j.jrt.2023.100060
-
[21]
Linda Flower and John R. Hayes. 1981. A Cognitive Process Theory of Writing. College Composition and Communication32, 4 (1981), 365–387. doi:10.2307/356600 Publisher: National Council of Teachers of English
-
[22]
Katy Ilonka Gero, Tao Long, and Lydia B Chilton. 2023. Social Dynamics of AI Support in Creative Writing. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems (CHI ’23). Association for Computing Machinery, New York, NY, USA, 1–15. doi:10.1145/3544548.3580782
-
[23]
grammarly. 2023. grammarly. https://www.grammarly.com/. Accessed: 2024-10- 29
2023
-
[24]
Alicia Guo, Shreya Sathyanarayanan, Leijie Wang, Jeffrey Heer, and Amy Zhang
-
[25]
doi:10.48550/arXiv.2411.03137 arXiv:2411.03137 [cs]
From Pen to Prompt: How Creative Writers Integrate AI into their Writing Practice. doi:10.48550/arXiv.2411.03137 arXiv:2411.03137 [cs]
-
[26]
Andreas Göldi, Thiemo Wambsganss, Seyed Parsa Neshaei, and Roman Rietsche
-
[27]
InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24)
Intelligent Support Engages Writers Through Relevant Cognitive Processes. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–12. doi:10.1145/3613904.3642549
-
[28]
Jieun Han, Haneul Yoo, Yoonsu Kim, Junho Myung, Minsun Kim, Hyunseung Lim, Juho Kim, Tak Yeon Lee, Hwajung Hong, So-Yeon Ahn, and Alice Oh. 2023. RECIPE: How to Integrate ChatGPT into EFL Writing Education. InProceedings of the Tenth ACM Conference on Learning @ Scale. ACM, Copenhagen Denmark, 416–420. doi:10.1145/3573051.3596200
-
[29]
Hui-Wen Huang, Zehui Li, and Linda Taylor. 2020. The Effectiveness of Using Grammarly to Improve Students’ Writing Skills. InProceedings of the 5th Interna- tional Conference on Distance Education and Learning (ICDEL ’20). Association for Computing Machinery, New York, NY, USA, 122–127. doi:10.1145/3402569. 3402594
-
[30]
Andrew Jelson, Daniel Manesh, Alice Jang, Daniel Dunlap, Young-Ho Kim, and Sang Won Lee. 2025. An Empirical Study to Understand How Students Use ChatGPT for Writing Essays. doi:10.48550/arXiv.2501.10551 arXiv:2501.10551 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.10551 2025
-
[31]
Nikhita Joshi and Daniel Vogel. 2025. Writing with AI Lowers Psychologi- cal Ownership, but Longer Prompts Can Help. doi:10.48550/arXiv.2404.03108 Conference’17, July 2017, Washington, DC, USA Jelson, Manesh, Sangwook Lee, Sang won Lee arXiv:2404.03108 [cs]
- [32]
-
[33]
Simon Knight, Antonette Shibani, Sophie Abel, Andrew Gibson, Philippa Ryan, Nicole Sutton, Raechel Wight, Cherie Lucas, Ágnes Sándor, Kirsty Kitto, Ming Liu, Radhika Vijay Mogarkar, and Simon Buckingham Shum. 2020. AcaWriter: A learning analytics tool for formative feedback on academic writing.Journal of Writing Research12, 1 (June 2020), 141–186. doi:10....
-
[34]
Svetlana Koltovskaia. 2020. Student engagement with automated written correc- tive feedback (AWCF) provided byGrammarly: A multiple case study.Assessing Writing44 (April 2020), 100450. doi:10.1016/j.asw.2020.100450
-
[35]
Nataliya Kosmyna, Eugene Hauptmann, Ye Tong Yuan, Jessica Situ, Xian-Hao Liao, Ashly Vivian Beresnitzky, Iris Braunstein, and Pattie Maes. 2025. Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv:2506.08872 [cs.AI] https://arxiv.org/abs/2506.08872
-
[36]
Mina Lee, Percy Liang, and Qian Yang. 2022. CoAuthor: Designing a Human-AI Collaborative Writing Dataset for Exploring Language Model Capabilities. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems (CHI ’22). Association for Computing Machinery, New York, NY, USA, 1–19. doi:10.1145/3491102.3502030
-
[37]
Rongxin Liu, Carter Zenke, Charlie Liu, Andrew Holmes, Patrick Thornton, and David J. Malan. 2024. Teaching CS50 with AI: Leveraging Generative Artificial Intelligence in Computer Science Education. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1 (SIGCSE 2024). Association for Computing Machinery, New York, NY, USA, 75...
- [38]
-
[39]
Fiammetta Marulli, Lelio Campanile, Maria Stella de Biase, Stefano Marrone, Laura Verde, and Marianna Bifulco. 2024. Understanding Readability of Large Language Models Output: An Empirical Analysis.Procedia Computer Science246 (Jan. 2024), 5273–5282. doi:10.1016/j.procs.2024.09.636
-
[40]
Melissa Romoff, Madison Brunette, Melanie K. Peterson, Sohaib Z. Hashmi, and Michael S. Kim. 2025. The role of large language models in improving the read- ability of orthopaedic spine patient educational material.Journal of Orthopaedic Surgery and Research20 (May 2025), 531. doi:10.1186/s13018-025-05955-1
-
[41]
Advait Sarkar and Ian Drosos. 2025. Vibe coding: programming through conver- sation with artificial intelligence. doi:10.48550/arXiv.2506.23253 arXiv:2506.23253 [cs]
-
[42]
Turing Test
Peter Scarfe, Kelly Watcham, Alasdair Clarke, and Etienne Roesch. 2024. A real-world test of artificial intelligence infiltration of a university examinations system: A “Turing Test” case study.PloS one19, 6 (2024), e0305354
2024
-
[43]
Mei Tan, Christopher Mah, and Dorottya Demszky. 2024. Reframing Authority: A Computational Measure of Power-Affirming Feedback on Student Writing. In Proceedings of the Eleventh ACM Conference on Learning @ Scale. ACM, Atlanta GA USA, 417–421. doi:10.1145/3657604.3664680
-
[44]
Robert L. Thorndike. 1953. Who Belongs in the Family?Psychometrika18, 4 (Dec. 1953), 267–276. doi:10.1007/BF02289263
-
[45]
Don Vandewalle, Linn Van Dyne, and Tatiana Kostova. 1995. Psychological Own- ership: An Empirical Examination of its Consequences.Group & Organization Management20, 2 (June 1995), 210–226. doi:10.1177/1059601195202008 Publisher: SAGE Publications Inc
-
[46]
Carole Wade. 1995. Using writing to develop and assess critical thinking.Teaching of psychology22, 1 (1995), 24–28
1995
-
[47]
Jin Wang and Wenxiang Fan. 2025. The effect of ChatGPT on students’ learning performance, learning perception, and higher-order thinking: insights from a meta-analysis.Humanities and Social Sciences Communications12, 1 (May 2025),
2025
-
[48]
doi:10.1057/s41599-025-04787-y
-
[49]
Azmine Toushik Wasi, Mst Rafia Islam, and Raima Islam. 2024. LLMs as Writing Assistants: Exploring Perspectives on Sense of Ownership and Reasoning. In Proceedings of the Third Workshop on Intelligent and Interactive Writing Assistants. 38–42. doi:10.1145/3690712.3690723 arXiv:2404.00027 [cs]
-
[50]
Florian Weber, Thiemo Wambsganss, Seyed Parsa Neshaei, and Matthias Soellner
-
[51]
LegalWriter: An Intelligent Writing Support System for Structured and Persuasive Legal Case Writing for Novice Law Students. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems (CHI ’24). Association for Computing Machinery, New York, NY, USA, 1–23. doi:10.1145/3613904.3642743
-
[52]
Simon Wilbers, Johanna Gröpler, Bastian Prell, and Jörg Reiff-Stephan. 2024. Overall Writing Effectiveness: Exploring Students’ Use of LLMs, Pushing the Limits of Automated Text Generation. InSmart Technologies for a Sustainable Future, Michael E. Auer, Reinhard Langmann, Dominik May, and Kim Roos (Eds.). Springer Nature Switzerland, Cham, 11–22. doi:10.1...
-
[53]
Ye Xiong and Yi-Fang Brook Wu. 2019. An Automated Feedback System to Support Student Learning in Writing-to-Learn Activities. InProceedings of the Sixth (2019) ACM Conference on Learning @ Scale (L@S ’19). Association for Computing Machinery, New York, NY, USA, 1–4. doi:10.1145/3330430.3333657
-
[54]
Chao Zhang, Kexin Ju, Peter Bidoshi, Yu-Chun Grace Yen, and Jeffrey M. Rzes- zotarski. 2025. Friction: Deciphering Writing Feedback into Writing Revisions through LLM-Assisted Reflection. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Ma- chinery, New York, NY, USA, 1–27. doi:10.1145/370...
-
[55]
1989.Writing to learn
William K Zinsser. 1989.Writing to learn. Harper & Row, New York. A Appendix A.1 Full List of Dataset Columns Here, we provide a full description of all the dataset columns. •Participant Sheet – id- Participant id to correspond to the essay_num in the Essay Data sheet – Gender- Participant gender – Age- Participant age in age bands – Race- Participant rac...
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.