Recognition: unknown
LMGenDrive: Bridging Multimodal Understanding and Generative World Modeling for End-to-End Driving
Pith reviewed 2026-05-10 17:30 UTC · model grok-4.3
The pith
LMGenDrive unifies LLM understanding with generative video prediction for closed-loop driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
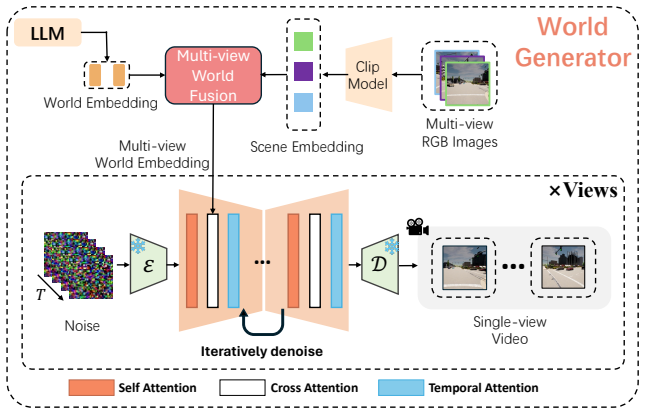
LMGenDrive is the first framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, LMGenDrive generates both future driving videos and control signals. This design provides complementary benefits: video prediction improves spatio-temporal scene modeling, while the LLM contributes strong semantic priors and instruction grounding from large-scale pretraining. A progressive three-stage training strategy, from vision pretraining to multi-step long-horizon driving, improves stability and performance. LMGenDrive supports both low-latency online planning and autoregress
What carries the argument
The LMGenDrive joint generator that outputs future video sequences together with control signals, using LLM components for semantic and instruction grounding alongside world-model components for scene dynamics.
If this is right
- The model can run in low-latency online mode for real-time planning or in autoregressive mode for offline video simulation.
- Complementary semantic priors and spatio-temporal prediction improve robustness on rare and long-tail driving cases.
- Instruction grounding becomes more reliable because language understanding is trained alongside visual future prediction.
- The three-stage progressive training reduces instability when scaling to longer driving horizons.
Where Pith is reading between the lines
- This style of unification could transfer to other embodied tasks such as robotic manipulation where both language commands and visual future modeling matter.
- If the joint training proves stable, similar architectures might reduce the need for separate modules in perception-planning stacks.
- Real-world deployment would benefit from testing whether the generated videos remain consistent with actual sensor data over extended sequences.
Load-bearing premise
That fusing video prediction with LLM semantic priors will produce additive gains without creating new prediction inconsistencies or training instabilities.
What would settle it
A controlled test showing LMGenDrive performs no better than a pure LLM planner or a standalone generative world model on the same closed-loop benchmarks, or produces video predictions that lead to unsafe controls.
Figures



read the original abstract
Recent years have seen remarkable progress in autonomous driving, yet generalization to long-tail and open-world scenarios remains a major bottleneck for large-scale deployment. To address this challenge, some works use LLMs and VLMs for vision-language understanding and reasoning, enabling vehicles to interpret rare and safety-critical situations when generating actions. Others study generative world models to capture the spatio-temporal evolution of driving scenes, allowing agents to imagine possible futures before acting. Inspired by human intelligence, which unifies understanding and imagination, we explore a unified model for autonomous driving. We present LMGenDrive, the first framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, LMGenDrive generates both future driving videos and control signals. This design provides complementary benefits: video prediction improves spatio-temporal scene modeling, while the LLM contributes strong semantic priors and instruction grounding from large-scale pretraining. We further propose a progressive three-stage training strategy, from vision pretraining to multi-step long-horizon driving, to improve stability and performance. LMGenDrive supports both low-latency online planning and autoregressive offline video generation. Experiments show that it significantly outperforms prior methods on challenging closed-loop benchmarks, with clear gains in instruction following, spatio-temporal understanding, and robustness to rare scenarios. These results suggest that unifying multimodal understanding and generation is a promising direction for more generalizable and robust embodied decision-making systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LMGenDrive, the first unified framework that combines LLM-based multimodal understanding with generative world models for end-to-end closed-loop driving. Given multi-view camera inputs and natural-language instructions, the model generates both future driving videos and control signals. It employs a progressive three-stage training strategy (vision pretraining to multi-step long-horizon driving) to improve stability. Experiments demonstrate significant outperformance over prior methods on challenging closed-loop benchmarks, with gains in instruction following, spatio-temporal understanding, and robustness to rare scenarios.
Significance. If the empirical results hold under scrutiny, this work could meaningfully advance autonomous driving and embodied AI research. Unifying semantic priors from large-scale LLM pretraining with spatio-temporal modeling from generative video prediction directly targets the long-tail generalization bottleneck. The three-stage training strategy offers a practical recipe for stable hybrid model optimization, and the dual support for low-latency online planning and autoregressive offline generation increases applicability. Credit is due for the closed-loop evaluation focus and the explicit attempt to demonstrate complementary benefits between understanding and generation modules.
minor comments (3)
- [Abstract] Abstract: The statement that LMGenDrive 'significantly outperforms prior methods on challenging closed-loop benchmarks' would be strengthened by naming at least one benchmark (e.g., CARLA closed-loop) and reporting a key quantitative metric (e.g., success rate or collision reduction) rather than leaving the claim entirely qualitative.
- [Section 3] Section 3 (Method): The precise mechanism by which the LLM semantic priors condition the generative world model (and vice versa) during joint video-and-control prediction is described at a high level; adding a short equation or pseudocode snippet for the cross-modal conditioning would improve reproducibility.
- [Figure 2] Figure 2 / Section 4.2: The architecture diagram and training-stage illustrations are clear, but the caption for the three-stage progression could explicitly state the loss terms active in each stage to make the stability claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of LMGenDrive and the recommendation for minor revision. We appreciate the recognition of the unified framework's potential to address long-tail generalization in autonomous driving through the integration of LLM priors and generative world modeling.
Circularity Check
No significant circularity; empirical framework with independent experimental validation
full rationale
The paper describes an empirical system (LMGenDrive) that integrates pretrained LLM/VLM components with a generative video model, trained progressively in three stages and evaluated on closed-loop driving benchmarks. No mathematical derivations, equations, or first-principles predictions are presented that could reduce to fitted parameters or self-citations by construction. Performance gains are reported via external benchmarks and ablations rather than internal self-referential loops. Self-citations, if present, are not load-bearing for any claimed uniqueness theorem or ansatz. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- model architecture hyperparameters
axioms (2)
- domain assumption Generative video models can capture useful spatio-temporal dynamics of driving scenes
- domain assumption LLM pretraining provides strong semantic priors and instruction grounding transferable to driving
invented entities (1)
-
LMGenDrive unified framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Advances in neural infor- mation processing systems35, 23716–23736 (2022) 2
Alayrac, J.B., Donahue, J., Luc, P., Miech, A., Barr, I., Hasson, Y ., Lenc, K., Mensch, A., Millican, K., Reynolds, M., et al.: Flamingo: a visual language model for few-shot learning. Advances in neural infor- mation processing systems35, 23716–23736 (2022) 2
2022
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025) 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Ball, P.J., Bauer, J., Belletti, F., et al.: Genie 3: A new frontier for world models (2025) 2
2025
-
[4]
CARLA Team: Carla autonomous driving leader- board.https://leaderboard.carla.org/ (2020), accessed: 2021-02-11 7
2020
-
[5]
In: Conference on Robot Learning
Chen, D., Zhou, B., Koltun, V ., Kr¨ahenb¨uhl, P.: Learn- ing by cheating. In: Conference on Robot Learning. pp. 66–75. PMLR (2020) 5
2020
-
[6]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Chen, J., Xu, Z., Pan, X., Hu, Y ., Qin, C., Gold- stein, T., Huang, L., Zhou, T., Xie, S., Savarese, S., et al.: Blip3-o: A family of fully open unified multi- modal models-architecture, training and dataset. arXiv preprint arXiv:2505.09568 (2025) 2
work page Pith review arXiv 2025
-
[7]
arXiv preprint arXiv:2310.01957 (2023) 3
Chen, L., Sinavski, O., H ¨unermann, J., Karnsund, A., Willmott, A.J., Birch, D., Maund, D., Shotton, J.: Driving with llms: Fusing object-level vector modal- ity for explainable autonomous driving. arXiv preprint arXiv:2310.01957 (2023) 3
-
[8]
See https://vicuna
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y ., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y ., Gon- zalez, J.E., et al.: Vicuna: An open-source chat- bot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023) 2(3), 6 (2023) 7
2023
-
[9]
Emerging Properties in Unified Multimodal Pretraining
Deng, C., Zhu, D., Li, K., Gou, C., Li, F., Wang, Z., Zhong, S., Yu, W., Nie, X., Song, Z., et al.: Emerg- 9 ing properties in unified multimodal pretraining. arXiv preprint arXiv:2505.14683 (2025) 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
In: Conference on robot learning
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V .: Carla: An open urban driving simulator. In: Conference on robot learning. pp. 1–16. PMLR (2017) 7
2017
-
[11]
In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision
Fu, H., Zhang, D., Zhao, Z., Cui, J., Liang, D., Zhang, C., Zhang, D., Xie, H., Wang, B., Bai, X.: Orion: A holistic end-to-end autonomous driving framework by vision-language instructed action generation. In: Pro- ceedings of the IEEE/CVF International Conference on Computer Vision. pp. 24823–24834 (2025) 3
2025
-
[12]
Gao, R., Chen, K., Xie, E., Hong, L., Li, Z., Ye- ung, D.Y ., Xu, Q.: Magicdrive: Street view genera- tion with diverse 3d geometry control. arXiv preprint arXiv:2310.02601 (2023) 2, 3
-
[13]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y ., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile controlla- bility. arXiv preprint arXiv:2405.17398 (2024) 2, 3
-
[14]
Blog post, April 1(2023) 4
Geng, X., Gudibande, A., Liu, H., Wallace, E., Abbeel, P., Levine, S., Song, D.: Koala: A dia- logue model for academic research. Blog post, April 1(2023) 4
2023
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek- r1: Incentivizing reasoning capability in llms via rein- forcement learning. arXiv preprint arXiv:2501.12948 (2025) 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Guo, Y ., Yang, C., Rao, A., Liang, Z., Wang, Y ., Qiao, Y ., Agrawala, M., Lin, D., Dai, B.: Animate- diff: Animate your personalized text-to-image diffu- sion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023) 5, 7
work page internal anchor Pith review arXiv 2023
-
[17]
Ha, D., Schmidhuber, J.: World models. arXiv preprint arXiv:1803.10122 (2018) 2
work page internal anchor Pith review arXiv 2018
-
[18]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 4
2016
-
[19]
Advances in neural information pro- cessing systems33, 6840–6851 (2020) 5
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion prob- abilistic models. Advances in neural information pro- cessing systems33, 6840–6851 (2020) 5
2020
-
[20]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023) 2, 3
work page internal anchor Pith review arXiv 2023
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Hu, Y ., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning- oriented autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 17853–17862 (2023) 3
2023
-
[22]
arXiv preprint arXiv:2306.07957 (2023) 3, 4
Jaeger, B., Chitta, K., Geiger, A.: Hidden bi- ases of end-to-end driving models. arXiv preprint arXiv:2306.07957 (2023) 3, 4
-
[23]
arXiv preprint arXiv:2503.22231 (2025) 2, 3
Ji, Y ., Zhu, Z., Zhu, Z., Xiong, K., Lu, M., Li, Z., Zhou, L., Sun, H., Wang, B., Lu, T.: Cogen: 3d con- sistent video generation via adaptive conditioning for autonomous driving. arXiv preprint arXiv:2503.22231 (2025) 2, 3
-
[24]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Jia, X., Gao, Y ., Chen, L., Yan, J., Liu, P.L., Li, H.: Driveadapter: Breaking the coupling barrier of perception and planning in end-to-end autonomous driving. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 7953– 7963 (2023) 3
2023
-
[25]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Jia, X., Wu, P., Chen, L., Xie, J., He, C., Yan, J., Li, H.: Think twice before driving: Towards scal- able decoders for end-to-end autonomous driving. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 21983– 21994 (2023) 3
2023
-
[26]
Jia, X., You, J., Zhang, Z., Yan, J.: Drivetrans- former: Unified transformer for scalable end-to-end autonomous driving. arXiv preprint arXiv:2503.07656 (2025) 3
-
[27]
In: Interna- tional conference on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrap- ping language-image pre-training for unified vision- language understanding and generation. In: Interna- tional conference on machine learning. pp. 12888– 12900. PMLR (2022) 2
2022
-
[28]
Li, Y ., Fan, L., He, J., Wang, Y ., Chen, Y ., Zhang, Z., Tan, T.: Enhancing end-to-end au- tonomous driving with latent world model. arXiv preprint arXiv:2406.08481 (2024) 4
-
[29]
Liao, C., Liu, L., Wang, X., Luo, Z., Zhang, X., Zhao, W., Wu, J., Li, L., Tian, Z., Huang, W.: Mogao: An omni foundation model for interleaved multi-modal generation. arXiv preprint arXiv:2505.05472 (2025) 2
-
[30]
arXiv preprint arXiv:2402.05935 , year=
Liu, D., Zhang, R., Qiu, L., Huang, S., Lin, W., Zhao, S., Geng, S., Lin, Z., Jin, P., Zhang, K., et al.: Sphinx-x: Scaling data and parameters for a family of multi-modal large language models. arXiv preprint arXiv:2402.05935 (2024) 3
-
[31]
Advances in neural information process- ing systems36, 34892–34916 (2023) 2, 3, 4
Liu, H., Li, C., Wu, Q., Lee, Y .J.: Visual instruc- tion tuning. Advances in neural information process- ing systems36, 34892–34916 (2023) 2, 3, 4
2023
-
[32]
In: International Conference on Learn- ing Representations (2018) 6
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. In: International Conference on Learn- ing Representations (2018) 6
2018
-
[33]
Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415,
Mao, J., Qian, Y ., Ye, J., Zhao, H., Wang, Y .: Gpt- driver: Learning to drive with gpt. arXiv preprint arXiv:2310.01415 (2023) 2, 3
-
[34]
A language agent for au- tonomous driving
Mao, J., Ye, J., Qian, Y ., Pavone, M., Wang, Y .: A 10 language agent for autonomous driving. arXiv preprint arXiv:2311.10813 (2023) 3
-
[35]
Advances in Neural Information Processing Systems34, 5416– 5429 (2021) 3
Qian, S., Shao, H., Zhu, Y ., Li, M., Jia, J.: Blend- ing anti-aliasing into vision transformer. Advances in Neural Information Processing Systems34, 5416– 5429 (2021) 3
2021
-
[36]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence
Renz, K., Chen, L., Arani, E., Sinavski, O.: Sim- lingo: Vision-only closed-loop autonomous driving with language-action alignment. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence. pp. 11993–12003 (2025) 3
2025
-
[37]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 7
2022
-
[38]
In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- ference, Munich, Germany, October 5-9, 2015, pro- ceedings, part III 18
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convo- lutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international con- ference, Munich, Germany, October 5-9, 2015, pro- ceedings, part III 18. pp. 234–241. Springer (2015) 5
2015
-
[39]
Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shot- ton, J., Arani, E., Corrado, G.: Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523 (2025) 2, 3
-
[40]
Languagempc: Large language models as deci- sion makers for autonomous driving,
Sha, H., Mu, Y ., Jiang, Y ., Chen, L., Xu, C., Luo, P., Li, S.E., Tomizuka, M., Zhan, W., Ding, M.: Languagempc: Large language models as deci- sion makers for autonomous driving. arXiv preprint arXiv:2310.03026 (2023) 3
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Shao, H., Hu, Y ., Wang, L., Song, G., Waslander, S.L., Liu, Y ., Li, H.: Lmdrive: Closed-loop end-to-end driv- ing with large language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 15120–15130 (2024) 2, 3, 4, 7
2024
-
[42]
Advances in Neural Information Processing Sys- tems37, 8612–8642 (2024) 2, 3
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y ., Li, H.: Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reason- ing. Advances in Neural Information Processing Sys- tems37, 8612–8642 (2024) 2, 3
2024
-
[43]
In: Conference on Robot Learning
Shao, H., Wang, L., Chen, R., Li, H., Liu, Y .: Safety- enhanced autonomous driving using interpretable sen- sor fusion transformer. In: Conference on Robot Learning. pp. 726–737. PMLR (2023) 3, 6
2023
-
[44]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Shao, H., Wang, L., Chen, R., Waslander, S.L., Li, H., Liu, Y .: Reasonnet: End-to-end driving with tem- poral and global reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 13723–13733 (2023) 3, 4
2023
-
[45]
Shi, W., Han, X., Zhou, C., Liang, W., Lin, X.V ., Zettlemoyer, L., Yu, L.: Lmfusion: Adapting pre- trained language models for multimodal generation. arXiv preprint arXiv:2412.15188 (2024) 2
-
[46]
In: European Conference on Computer Vision
Sima, C., Renz, K., Chitta, K., Chen, L., Zhang, H., Xie, C., Beißwenger, J., Luo, P., Geiger, A., Li, H.: Drivelm: Driving with graph visual question answer- ing. In: European Conference on Computer Vision. pp. 256–274. Springer (2024) 3
2024
-
[47]
DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models
Tian, X., Gu, J., Li, B., Liu, Y ., Wang, Y ., Zhao, Z., Zhan, K., Jia, P., Lang, X., Zhao, H.: Drivevlm: The convergence of autonomous driving and large vision- language models. arXiv preprint arXiv:2402.12289 (2024) 3
work page internal anchor Pith review arXiv 2024
-
[48]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.A., Lacroix, T., Rozi `ere, B., Goyal, N., Hambro, E., Azhar, F., et al.: Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023) 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[49]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Alma- hairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhar- gava, P., Bhosale, S., et al.: Llama 2: Open foun- dation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023) 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
arXiv preprint arXiv:2503.12170 (2025) 3
Wang, T., Zhang, C., Qu, X., Li, K., Liu, W., Huang, C.: Diffad: A unified diffusion modeling approach for autonomous driving. arXiv preprint arXiv:2503.12170 (2025) 3
-
[51]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025) 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
arXiv preprint arXiv:2505.18650 (2025) 2, 3
Wang, X., Peng, P.: Prophetdwm: A driving world model for rolling out future actions and videos. arXiv preprint arXiv:2505.18650 (2025) 2, 3
-
[53]
In: European Confer- ence on Computer Vision
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-drive world models for autonomous driving. In: European Confer- ence on Computer Vision. pp. 55–72. Springer (2024) 2, 3
2024
-
[54]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Y ., He, J., Fan, L., Li, H., Chen, Y ., Zhang, Z.: Driving into the future: Multiview visual forecasting and planning with world model for autonomous driv- ing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14749– 14759 (2024) 2, 3, 5
2024
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition
Weng, X., Ivanovic, B., Wang, Y ., Wang, Y ., Pavone, M.: Para-drive: Parallelized architecture for real- time autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition. pp. 15449–15458 (2024) 3 11
2024
-
[56]
Winter, K., Azer, M., Flohr, F.B.: Bevdriver: Lever- aging bev maps in llms for robust closed-loop driving. arXiv preprint arXiv:2503.03074 (2025) 3, 7
-
[57]
Xiang, J., Liu, G., Gu, Y ., Gao, Q., Ning, Y ., Zha, Y ., Feng, Z., Tao, T., Hao, S., Shi, Y ., et al.: Pandora: Towards general world model with natu- ral language actions and video states. arXiv preprint arXiv:2406.09455 (2024) 2, 5
-
[58]
Wong, Zhenguo Li, and Hengshuang Zhao
Xu, Z., Zhang, Y ., Xie, E., Zhao, Z., Guo, Y ., Wong, K.K., Li, Z., Zhao, H.: Drivegpt4: Interpretable end- to-end autonomous driving via large language model. arXiv preprint arXiv:2310.01412 (2023) 3
-
[59]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025) 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Yang, J., Gao, S., Qiu, Y ., Chen, L., Li, T., Dai, B., Chitta, K., Wu, P., Zeng, J., Luo, P., et al.: Gener- alized predictive model for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 14662– 14672 (2024) 2, 3
2024
-
[61]
DriveMoE: Mixture-of-experts for vision-language-action model in end-to-end autonomous driving
Yang, Z., Chai, Y ., Jia, X., Li, Q., Shao, Y ., Zhu, X., Su, H., Yan, J.: Drivemoe: Mixture-of-experts for vision-language-action model in end-to-end au- tonomous driving. arXiv preprint arXiv:2505.16278 (2025) 3
-
[62]
OPT: Open Pre-trained Transformer Language Models
Zhang, S., Roller, S., Goyal, N., Artetxe, M., Chen, M., Chen, S., Dewan, C., Diab, M., Li, X., Lin, X.V ., et al.: Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 (2022) 7
work page internal anchor Pith review arXiv 2022
-
[63]
arXiv preprint arXiv:2406.03474 (2024) 3, 7
Zhang, Z., Tang, S., Zhang, Y ., Fu, T., Wang, Y ., Liu, Y ., Wang, D., Shao, J., Wang, L., Lu, H.: Ad-h: Autonomous driving with hierarchical agents. arXiv preprint arXiv:2406.03474 (2024) 3, 7
-
[64]
Zheng, L., Chiang, W.L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging llm-as- a-judge with mt-bench and chatbot arena (2023) 4
2023
-
[65]
arXiv preprint arXiv:2501.15564 , year =
Zheng, Y ., Liang, R., Zheng, K., Zheng, J., Mao, L., Li, J., Gu, W., Ai, R., Li, S.E., Zhan, X., et al.: Diffusion-based planning for autonomous driving with flexible guidance. arXiv preprint arXiv:2501.15564 (2025) 3
-
[66]
In: Pro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition
Zhou, Y ., Shao, H., Wang, L., Waslander, S.L., Li, H., Liu, Y .: Smartrefine: A scenario-adaptive refinement framework for efficient motion prediction. In: Pro- ceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition. pp. 15281–15290 (2024) 3
2024
-
[67]
Zhou, Y ., Shao, H., Wang, L., Zong, Z., Li, H., Waslander, S.L.: Drivinggen: A comprehensive benchmark for generative video world models in au- tonomous driving. arXiv preprint arXiv:2601.01528 (2026) 2
-
[68]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023) 3, 4
work page internal anchor Pith review arXiv 2023
-
[69]
Advances in Neural Information Processing Systems37, 103305–103333 (2024) 3 12
Zong, Z., Ma, B., Shen, D., Song, G., Shao, H., Jiang, D., Li, H., Liu, Y .: Mova: Adapting mixture of vision experts to multimodal context. Advances in Neural Information Processing Systems37, 103305–103333 (2024) 3 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.