Recognition: no theorem link
Scalable High-Recall Constraint-Satisfaction-Based Information Retrieval for Clinical Trials Matching
Pith reviewed 2026-05-10 18:24 UTC · model grok-4.3
The pith
SatIR turns patient records and trial rules into formal logical constraints to retrieve far more suitable clinical trials than similarity-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SatIR represents trial eligibility criteria and patient records as constraints in Satisfiability Modulo Theories and relational algebra, with large language models used to translate informal clinical reasoning, ambiguity, and incomplete records into explicit formal constraints. On a test set of 59 patients and 3,621 trials this produces higher numbers of relevant-and-eligible trials per patient, higher recall over the union of useful trials, and coverage for more patients than the TrialGPT baseline while remaining fast.
What carries the argument
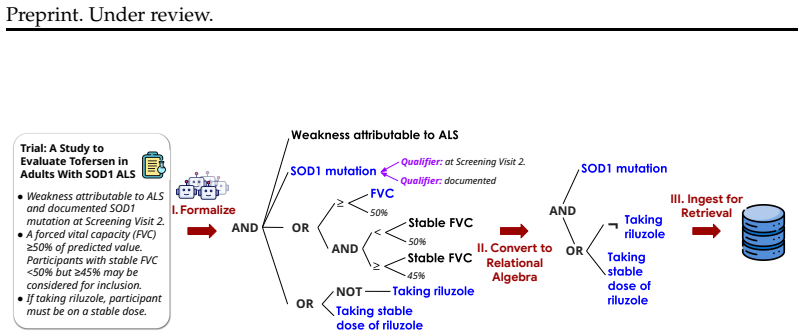
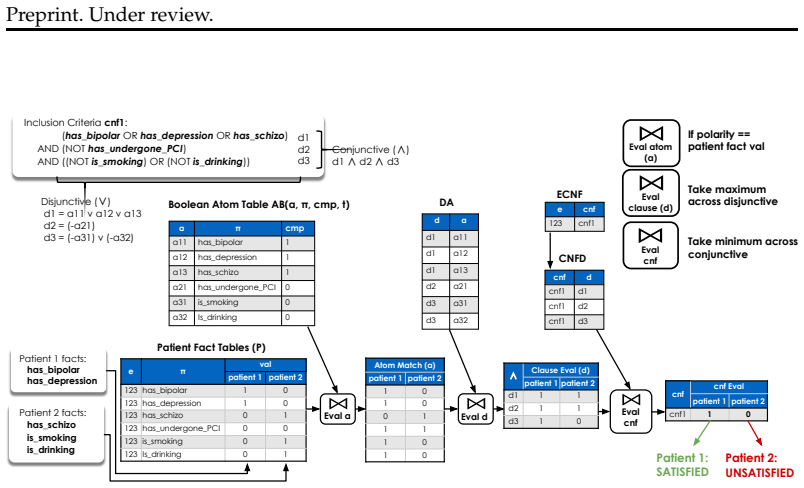
SatIR's constraint satisfaction engine, which encodes eligibility rules as SMT formulas and solves for compatibility after LLM formalization of patient data.
Load-bearing premise
Large language models can convert informal, ambiguous, and incomplete clinical information into accurate formal constraints without introducing systematic errors that reduce matching quality.
What would settle it
An independent evaluation on a larger patient set or with expert review of the LLM-generated constraints that finds frequent inaccuracies in the formal rules or that the reported recall and coverage gains disappear.
Figures
















read the original abstract
Clinical trials are central to evidence-based medicine, yet many struggle to meet enrollment targets, despite the availability of over half a million trials listed on ClinicalTrials.gov, which attracts approximately two million users monthly. Existing retrieval techniques, largely based on keyword and embedding-similarity matching between patient profiles and eligibility criteria, often struggle with low recall, low precision, and limited interpretability due to complex constraints. We propose SatIR, a scalable clinical trial retrieval method based on constraint satisfaction, enabling high-precision and interpretable matching of patients to relevant trials. Our approach uses formal methods -- Satisfiability Modulo Theories (SMT) and relational algebra -- to efficiently represent and match key constraints from clinical trials and patient records. Beyond leveraging established medical ontologies and conceptual models, we use Large Language Models (LLMs) to convert informal reasoning regarding ambiguity, implicit clinical assumptions, and incomplete patient records into explicit, precise, controllable, and interpretable formal constraints. Evaluated on 59 patients and 3,621 trials, SatIR outperforms TrialGPT on all three evaluated retrieval objectives. It retrieves 32%-72% more relevant-and-eligible trials per patient, improves recall over the union of useful trials by 22-38 points, and serves more patients with at least one useful trial. Retrieval is fast, requiring 2.95 seconds per patient over 3,621 trials. These results show that SatIR is scalable, effective, and interpretable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SatIR, a clinical trial retrieval system that represents eligibility criteria and patient data as formal constraints using Satisfiability Modulo Theories (SMT) and relational algebra. Large language models are used to translate informal clinical reasoning, ambiguities, and incomplete records into explicit formal constraints. On a fixed evaluation set of 59 patients and 3,621 trials, SatIR is reported to outperform TrialGPT on three objectives: retrieving 32-72% more relevant-and-eligible trials per patient, raising recall over the union of useful trials by 22-38 points, and serving more patients with at least one useful trial, while requiring 2.95 seconds per patient.
Significance. If the empirical results hold under rigorous validation, the work would demonstrate that constraint-satisfaction methods can deliver substantially higher recall than embedding-based baselines while remaining interpretable and scalable. The combination of established formal methods with LLM-assisted formalization is a promising direction for domains requiring precise, controllable matching. The reported speed and the explicit handling of complex constraints are practical strengths.
major comments (2)
- [Abstract] Abstract and evaluation description: concrete performance numbers (32-72% more trials, 22-38 point recall lift) are stated for 59 patients, yet no information is supplied on how relevance labels were obtained, how the TrialGPT baseline was configured or prompted, or whether statistical significance testing was performed. This directly affects the verifiability of the central empirical claim.
- [Methods] Methods section on LLM formalization: the central performance gains rest on the assumption that LLMs accurately convert informal clinical assumptions and incomplete records into precise formal constraints without systematic error. No quantitative error analysis, expert review, or inter-rater agreement on the generated constraints is reported, so it remains possible that observed improvements originate in the LLM step rather than the SMT solver.
minor comments (1)
- [Abstract] The abstract states that ClinicalTrials.gov contains 'over half a million trials' while the evaluation uses only 3,621; a brief clarification of the selection criteria for the evaluated subset would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the promise of combining formal methods with LLMs for clinical trial matching. We provide point-by-point responses to the major comments and outline the revisions we will make to address the concerns about evaluation details and LLM formalization.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation description: concrete performance numbers (32-72% more trials, 22-38 point recall lift) are stated for 59 patients, yet no information is supplied on how relevance labels were obtained, how the TrialGPT baseline was configured or prompted, or whether statistical significance testing was performed. This directly affects the verifiability of the central empirical claim.
Authors: We agree that the evaluation protocol requires more explicit documentation to allow independent verification. In the revised manuscript, we will expand the evaluation section to explicitly describe how relevance labels were obtained, including the annotation process and any use of clinical expertise. We will also provide the full configuration details and prompts used for the TrialGPT baseline, as well as the results of statistical significance testing on the reported metrics, such as p-values from paired statistical tests across the 59 patients. revision: yes
-
Referee: [Methods] Methods section on LLM formalization: the central performance gains rest on the assumption that LLMs accurately convert informal clinical assumptions and incomplete records into precise formal constraints without systematic error. No quantitative error analysis, expert review, or inter-rater agreement on the generated constraints is reported, so it remains possible that observed improvements originate in the LLM step rather than the SMT solver.
Authors: We acknowledge that isolating the accuracy of the LLM formalization step would help attribute performance gains more precisely. In the revised manuscript, we will add a subsection providing qualitative examples of LLM-generated constraints alongside original text, a categorization of common formalization issues observed, and results from a targeted expert review of a sample of constraints. Full-scale quantitative inter-rater agreement metrics would require a new dedicated study beyond the current scope, which we will note as future work while still strengthening the current analysis. revision: partial
Circularity Check
No circularity: results are direct empirical comparisons against external baseline
full rationale
The paper presents SatIR as an SMT-based retrieval system whose performance claims rest on measured recall and trial counts over a fixed test set of 59 patients and 3,621 trials, compared to the external TrialGPT baseline. No equations, fitted parameters, or self-citations are invoked to derive these quantities; the reported 32-72% gains and 22-38 point recall lifts are obtained by running the implemented pipeline and counting matches. The LLM formalization step is described as a preprocessing aid rather than a self-referential definition, and no uniqueness theorems or ansatzes from prior author work are used to force the outcome. The derivation chain therefore terminates in observable retrieval metrics rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption SMT solvers can efficiently decide the conjunction of constraints extracted from trial eligibility criteria and patient records.
- ad hoc to paper Large language models can translate informal clinical assumptions and incomplete records into explicit, precise formal constraints without material loss of accuracy.
Reference graph
Works this paper leans on
-
[1]
Matching patients to clinical trials with large language models
doi: 10.1038/s41467-024-53081-z. Bevan Koopman and Guido Zuccon. A test collection for matching patients to clinical trials. InProceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 669–672. ACM, 2016. doi: 10.1145/2911451.2914672. Mingyu Lee, Kyuri Kim, Yoojin Shin, Yoonji Lee, and Tae-Jung Ki...
-
[2]
https://conf.spaces.snomed.org/wiki/spaces/RMT/pages/131957448/SNOMED+ CT+Managed+Service+-+US+Edition+Release+Notes+-+March+2019, 2019. Accessed: 2026- 03-26. SNOMED International. Snomed ct concept model: An overview. https://confluence. ihtsdotools.org/display/DOCTSG/Concept+Model+-+An+Overview, 2025a. Accessed: 2025-08-12. SNOMED International. SNOMED...
-
[3]
Experimental results and evaluation.Presents aggregate and per-patient results, re- trieval objectives, the annotation interface, clinician review details, failure-case analysis, and experimental settings
-
[4]
Representation and subsumption.Describes subsumption rules, qualifier handling, and the relation vocabularies used in the system
-
[5]
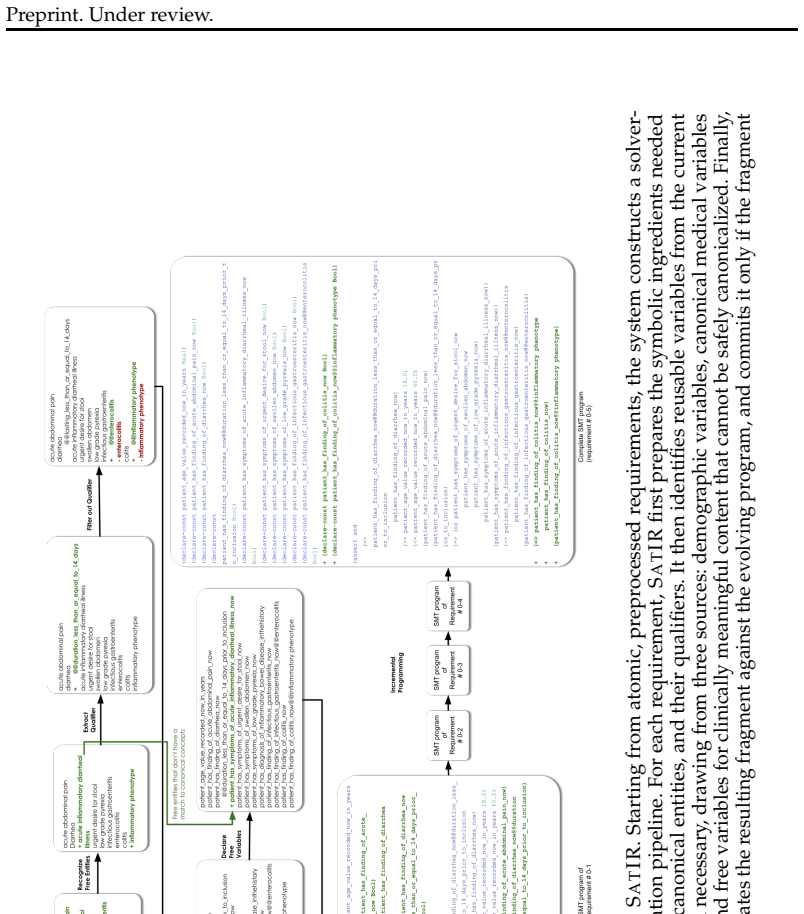
Semantic parsing.Covers requirement preprocessing, canonicalization, SMT program- ming, repair, and patient-side semantic parsing
-
[6]
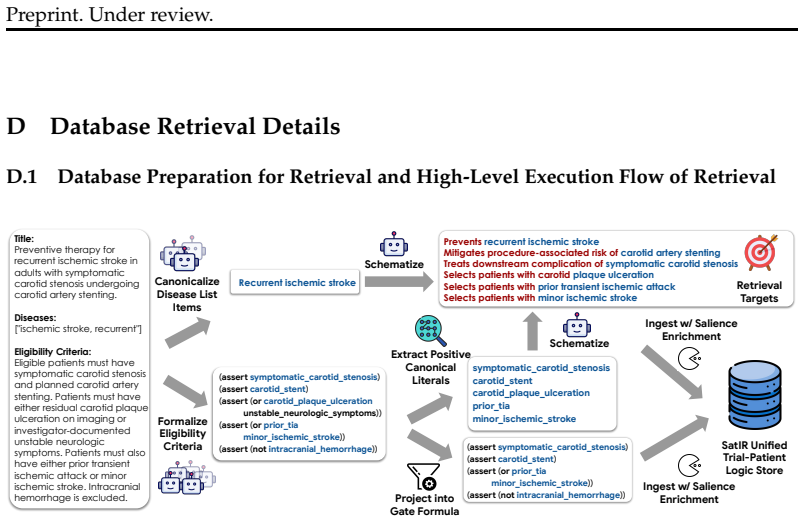
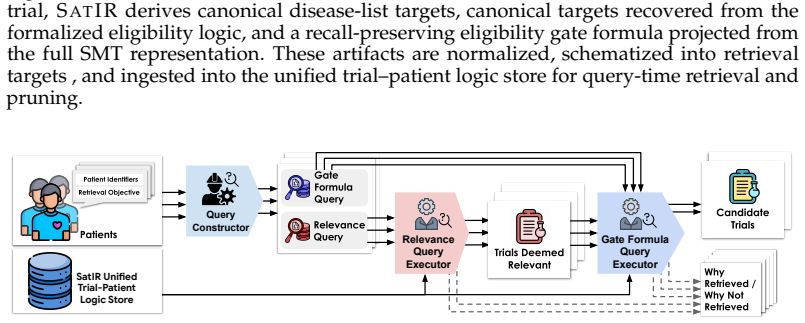
5.Others.Includes: (a)Limitations.Discusses limitations of the current system
Database retrieval details.Explains how symbolic constraints are prepared, projected, and executed in the database. 5.Others.Includes: (a)Limitations.Discusses limitations of the current system. (b) Natural-language matching.Describes the auxiliary natural-language matching component. (c) Example SMT program.Provides an example SMT program produced by our...
-
[7]
directly treating
The chance agreement is Pe = 1 − ∑k p2 k = 1 − 49 54 2 + 1 27 2 + 1 18 2 ≈ 0.172. Thus, AC1= Po−Pe 1−Pe = 0.852−0.172 1−0.172 ≈0.82. A.4 Failure Case Analysis In this appendix, we present a structured analysis of failure cases described in Section 7. These cases were manually reviewed and categorized to better understand the sources of error across differ...
2025
-
[8]
High systolic arterial pressure
-
[10]
Systolic essential hypertension Candidates of entity 2:
-
[11]
Systolic essential hypertension
-
[12]
Systolic hypertension
-
[13]
High systolic arterial pressure Candidates of entity 3:
-
[14]
Primary hypertension
-
[15]
Isolated systolic high blood pressure
Raised blood pressure Systolic hypertension Systolic hypertension Hypertension ① Entity Span Identification ② Dense Retrieval in SNOMED ③ Reranking ④ Filtering: Is the top candidate the same as extracted entity? Not same Same Same Which is more specific? Canonicalized result: Systolic hypertension “Isolated systolic high blood pressure” “systolic high blo...
-
[16]
identifying which previously declared symbols should be reused,
-
[17]
resolving which qualifiers modify which entities or predicates,
-
[18]
constructing any new variables needed for the current requirement,
-
[19]
translating the requirement into a local SMT fragment, and
-
[20]
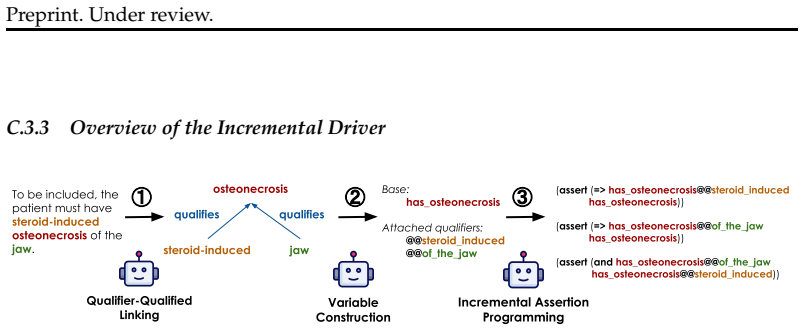
steroid-induced osteonecrosis of the jaw
validating that fragment both logically and semantically before committing it. This decomposition makes the overall synthesis process more stable and more auditable than monolithic generation. C.3.4 Stage 0: Free-Entity Prepass Before per-requirement translation, SATIR runs a recall-oriented prepass that extracts additional clinically meaningful content n...
2016
-
[21]
Preserve original wording where feasible; lightly clean formatting (e.g., bullets, deduping) when needed.,→
Minimal edits & fidelity: Use only the provided contextual_text; make no external assumptions. Preserve original wording where feasible; lightly clean formatting (e.g., bullets, deduping) when needed.,→
-
[22]
Detect cohorts (explicit or implicit): Create a new cohort for each labeled arm/part/group or for implicit alternatives on the same concept (see Implicit Cohortizer).,→
-
[23]
Implicit Cohortizer (required): if inclusion bullets give alternative ways to qualify on the same entity/measure, make separate cohorts even without labels. Triggers:,→ - Comparator splits on same variable (e.g., > 2 cm vs < 2 cm (+ risk)), - Conditional gates (``if risk factors\ldots{}'',``either/or'', ICU vs non-ICU, cases vs controls), - Partitioning q...
-
[24]
Shared vs per-cohort + propagation (must): Put trial-level fields (brief_title, phase, drugs, enrollment, summary) in shared_context.If an inclusion/exclusion applies to all participants, copy it verbatim into every cohort and also summarize it in shared_context. ,→ ,→
-
[25]
Cleanup placeholders: Remove dangling cross-refs like``defined below/above''; if a section would be empty, set it to "".,→
-
[26]
- Do not nest shared_context under enrollment_cohorts
Output schema (strict) - inclusion_criteria and exclusion_criteria are single strings containing bullet lists (each line starts with - ).,→ - Do not use arrays. - Do not nest shared_context under enrollment_cohorts. - Only return "Overall" if there are no explicit labels and no implicit cues (Rule 3)
-
[27]
- Shared criteria replicated into each cohort? - Placeholders removed? - JSON matches schema? - Count of cohorts matches what you inferred? # === Cues & Fallback ===
Self-check before finalizing - Any implicit cues? Then $\ge$2 cohorts. - Shared criteria replicated into each cohort? - Placeholders removed? - JSON matches schema? - Count of cohorts matches what you inferred? # === Cues & Fallback ===
-
[28]
Name unlabeled cohorts: Cohort A: <verbatim>, Cohort B: <verbatim>
Create separate cohorts for labeled arms/parts or when bullets present alternative ways to qualify on the same measure/entity (e.g., > 2 cm vs < 2 cm + risk,``either/or'', ICU vs non-ICU, cases vs controls). Name unlabeled cohorts: Cohort A: <verbatim>, Cohort B: <verbatim>. ,→ ,→
-
[29]
# === Cleanup & propagation ===
Use a single "Overall" cohort only if none of the above cues appear. # === Cleanup & propagation ===
-
[30]
Under review
Copy any inclusion/exclusion that applies to all participants into every cohort and summarize it in shared_context.,→ 97 Preprint. Under review
-
[31]
". === EXAMPLES === Use the followings as examples of how we will go about subcohorting. Some subcohorting may be implicit. <example_1> <example_1_input> {
Remove placeholders like``defined below/above''; leave empty sections as "". === EXAMPLES === Use the followings as examples of how we will go about subcohorting. Some subcohorting may be implicit. <example_1> <example_1_input> {"_id": "NCT01387828", "title": "Comparison Between Open and Laparoscopic Splenic Aneurysms Repair", "text": "Summary: The purpos...
-
[34]
Extract inclusion requirements from requirement_text only, do NOT extract contextual_text
-
[35]
Each requirement must be self-contained and small enough to map directly to a logical clause
-
[37]
Always phrase the subject as the goal and a single patient (e.g.,``To be included, the patient must ...''), even if the source text says``patients'', to ensure logical preciseness in later SMT translation.,→
-
[40]
It is very simple
You should just mimic breaking by new lines. It is very simple. You just also address the noisy parts (e.g., also include examples/explanations broken by newlines and put them together as a single contiguous requirement).,→ 100 Preprint. Under review
-
[41]
Phrase it as``A patient is included if the patient is in the <GROUP> group and \ldots{}''
If the text introduces subgroup labels (e.g., AD group:, non-AD group:, Arm A:, Cohort 1:), prepend that label as a condition to every requirement under it until another label or the section ends. Phrase it as``A patient is included if the patient is in the <GROUP> group and \ldots{}''. Treat each group separately (even if requirements repeat). Requiremen...
-
[42]
patients with a cardiac history including myocardial infarction, heart failure, or coronary artery disease should have a cardiology review
You should rewrite everything into strictly requirement format. Sometimes the input is not in the imperative requirement format. We want to reword those into imperative requirement format. For example, "patients with a cardiac history including myocardial infarction, heart failure, or coronary artery disease should have a cardiology review" must be reword...
-
[43]
To be included, the patient must have a caregiver / parent / child who is
Note that some criteria may not be about the patient themselves, but rather someone that is related to the patient. In those cases, the requirements should be like "To be included, the patient must have a caregiver / parent / child who is ...". Everything should still be framed with the patient being the subject! ,→ ,→ =================== OUTPUT FORMAT ==...
-
[44]
Use only information that is verbatim in the texts or unambiguously entailed
-
[45]
Do NOT rely on external knowledge or assumptions
-
[46]
Each requirement must be self-contained enough to map directly to a logical clause
-
[47]
Provide exact provenance: quote the sentence(s) or phrase(s) that support each requirement
-
[48]
Always phrase the subject as the goal and a single patient (e.g.,``A patient is excluded if the patient ...''), even if the source text says``patients'', to ensure logical preciseness in later SMT translation.,→
-
[49]
Do not alter the meaning of the requirements!
-
[50]
Do not skip, ignore, or omit any part of the requirement text (even if requirements repeat)
-
[51]
It is very simple
You should just mimic breaking by new lines. It is very simple. You just also address the noisy parts (e.g., also include examples/explanations broken by newlines and put them together as a single contiguous requirement).,→
-
[52]
AD group
Under some cases, one requirement may be only applicable to a subset of patients (e.g., using nested bullet points structure where the top level lines specify where all the nested requirements apply to). There may also be cases that specify those restrictions in a different way. Be careful of those cases! When extracting requirements, make sure to apply t...
-
[53]
patient should
You should rewrite everything into strictly requirement format. Sometimes the input is not in the imperative requirement format. We want to reword those into imperative requirement format. For example, "patient should ..." should be rewritten into "patient must have ..." format. ,→ ,→
-
[54]
A patient is excluded if the patient has a caregiver / parent / child who is
Note that some criteria may not be about the patient themselves, but rather someone that is related to the patient. In those cases, the requirements should be like "A patient is excluded if the patient has a caregiver / parent / child who is ...". Everything should still be framed with the patient being the subject! ,→ ,→ =================== OUTPUT FORMAT...
-
[56]
Verify that the set of extracted requirements, when considered together, fully represents the meaning of the original inclusion text. Because inclusion requires all conditions to be satisfied, mark anding_list_gives_same_meaning = true only if the combined interpretation matches the original intent, even if there is overlap or redundancy. ,→ ,→ ,→
-
[57]
To be included, the patient must
Check if everything correctly starts with "To be included, the patient must ...". Answer true or false in "starts_with_semantic_template".,→
-
[58]
overall_good_extraction
If all of the above are true, mark "overall_good_extraction" as true and leave "explanation" empty. Otherwise, mark "overall_good_extraction" as false and explain in "explanation" what went wrong.,→ # === RULES === If there are no requirements, and we correctly extracted no requirement, just set everything to be True. # === FORMAT === Return ONLY a JSON o...
-
[59]
all_covered
Check if extraction covers every bullet / numbered line in the source. Answer true or false in "all_covered"
-
[60]
Verify that the set of extracted exclusion requirements, when interpreted together, accurately represents the meaning of the original exclusion section. Because exclusion is triggered when any single requirement is met, mark oring_list_gives_same_meaning = true only if the combined interpretation preserves that intent, even if there is overlap or redundan...
-
[61]
The/A patient is excluded if the patient
Check if everything correctly starts with "The/A patient is excluded if the patient ...". Answer true or false in "starts_with_semantic_template".,→
-
[62]
overall_good_extraction
If all of the above are are true, mark "overall_good_extraction" as true and leave "explanation" empty. Otherwise, mark "overall_good_extraction" as false and explain in "explanation" what went wrong.,→ # === RULES === If there are no requirements, and we correctly extracted no requirement, just set everything to be True. # === FORMAT === Return ONLY a JS...
-
[63]
fracture of tibia and fibula
Shared-head expansion of entities -- "fracture of tibia and fibula" should be rewritten to "fracture of tibia and fracture of fibula" -- "retropharyngeal or buccal cellulitis" should be rewritten to "retropharyngeal cellulitis or buccal cellulitis",→
-
[64]
submission of a throat swab specimen for bacterial culture, identification, and antibiotic-susceptibility testing
Do not duplicate non-entity action phrases -- "submission of a throat swab specimen for bacterial culture, identification, and antibiotic-susceptibility testing" stays exactly the same (the medical act is one unit; only the purpose list is medical).,→ - "Patients with cough or shortness of breath" **stays exactly the same**
-
[65]
Convert adjectival medical descriptors into explicit noun-form expressions (e.g.,``hypertensive patients'' should be rewritten to``patients with hypertension'').,→
-
[66]
of any race
Remove clauses that always evaluate to true: for example, "of any race" and "of any sex/gender" can be safely omitted as it is not meaning anything useful.,→ - "the patient must be male or female" cannot be safely omitted
-
[67]
A sore and scratchy throat
Preserve original logical relationships after rewriting (ANDs should stay ANDs, ORs should stay ORs), depending on the context:,→ - "A sore and scratchy throat" should be rewritten to "A sore throat AND a scratchy throat". The adjectives describe distinct findings, so they should be split.,→ - If multiple medical descriptors jointly used to qualify a medi...
-
[68]
Patients of chronic stable angina with abnormal Exercise Myocardial Perfusion Spect Scan with reversible and partially reversible ischemic changes
Mutually Exclusive Diagnostic Findings: If multiple descriptors within a diagnostic result represent mutually exclusive findings (i.e., the same test cannot show both at once), rewrite them using OR rather than AND.,→ - Example: "Patients of chronic stable angina with abnormal Exercise Myocardial Perfusion Spect Scan with reversible and partially reversib...
-
[69]
Turn abbreviations into full names; keep only the full name if both appear
-
[70]
If two alternative, equivalent names exist, keep only the one that is more likely to match to a SNOMED concept using SapBert-based embedding serach.,→
-
[71]
and/or" means
Beware that "and/or" means "or", and should always be expanded as "or". For example, "a contraindication to EGD and/or biopsies" should be expanded as "a contraindication to EGD or a contradication to biopsies".,→
-
[72]
Do not import details from any other requirements
Rewrite each requirement using only its own content. Do not import details from any other requirements. Do not import details from trial context.,→
-
[73]
A patient is excluded if the patient has an infection of the deep tissues of the upper respiratory tract or of the suprapharyngeal respiratory tract and its connecting structures
All pronoun's should be fully expanded. 10.1. Example: {"A patient is excluded if the patient has an infection of the deep tissues of the upper respiratory tract or of the suprapharyngeal respiratory tract and its connecting structures.": "A patient is excluded if the patient has an infection of the deep tissues of the upper respiratory tract or of the su...
-
[74]
A patient is excluded if the patient was previously enrolled in the study during prior hospitalization (for multiple admissions; only data from the first admission will be used)
Be careful about pluarity and singularity, be sure to preserve. # === EDGE CASE EXAMPLE ==== DO NOT Change the original requirement's meaning. Particularly, preserve all parantheses, explanation relationships, and qualifier relationships. Don't drop parantheses in the original requirement.,→ <example_1> <example_input_1> "A patient is excluded if the pati...
-
[75]
To be included, the patient must be at average risk or higher for colorectal cancer and scheduled for colonoscopy with any of the following indications: prior colorectal cancer, prior colorectal adenoma, strong family history of colorectal neoplasia, or iron deficiency. ,→ ,→
-
[77]
To be included, the patient must have known or highly suspected primary colorectal neoplasms greater than 10 mm.,→
-
[78]
,→ ,→ </example_input_3> <example_output_3>
To be included, the patient must be at higher than average risk for colorectal cancer and scheduled for colonoscopy with any of the following indications: prior colorectal cancer, prior colorectal adenoma, strong family history of colorectal neoplasia, or iron deficiency. ,→ ,→ </example_input_3> <example_output_3>
-
[79]
,→ ,→ ,→
To be included, the patient must be at average risk for colorectal cancer or must be at higher than average risk for colorectal cancer, and the patient must be scheduled for colonoscopy with any of the following indications: prior colorectal cancer, prior colorectal adenoma, strong family history of colorectal neoplasia, or iron deficiency. ,→ ,→ ,→
-
[80]
To be included, the patient must be aged between 40 and 100 years inclusive
-
[81]
To be included, the patient must have known primary colorectal neoplasms greater than 10 mm or must have highly suspected primary colorectal neoplasms greater than 10 mm.,→
-
[82]
,→ ,→ </example_output_3> </example_3> # === RULES === Return the same number of lines, each prefixed with its original 0-based index:
To be included, the patient must be at higher than average risk for colorectal cancer and scheduled for colonoscopy with any of the following indications: prior colorectal cancer, prior colorectal adenoma, strong family history of colorectal neoplasia, or iron deficiency. ,→ ,→ </example_output_3> </example_3> # === RULES === Return the same number of lin...
-
[86]
It checks that all medically relevant entities are expressed as clear, standalone phrases, and that the rewritten requirements remain semantically identical to the originals
\ldots{} </rewritten_requirement_list> F.1.7 Preprocessing: Entity Expansion Checker Purpose.This prompt verifies that entity expansion is correct and meaning-preserving. It checks that all medically relevant entities are expressed as clear, standalone phrases, and that the rewritten requirements remain semantically identical to the originals. In particul...
-
[87]
No information is lost
-
[88]
107 Preprint
No extra information is added. 107 Preprint. Under review
-
[89]
Shared-head / coordinated entities are fully expanded
-
[90]
Abbreviations are fully expanded
-
[91]
Pronouns are resolved to their explicit referents
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.