Recognition: unknown
The Salami Slicing Threat: Exploiting Cumulative Risks in LLM Systems
Pith reviewed 2026-05-10 16:02 UTC · model grok-4.3
The pith
Chaining numerous low-risk inputs can accumulate harmful intent to jailbreak LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
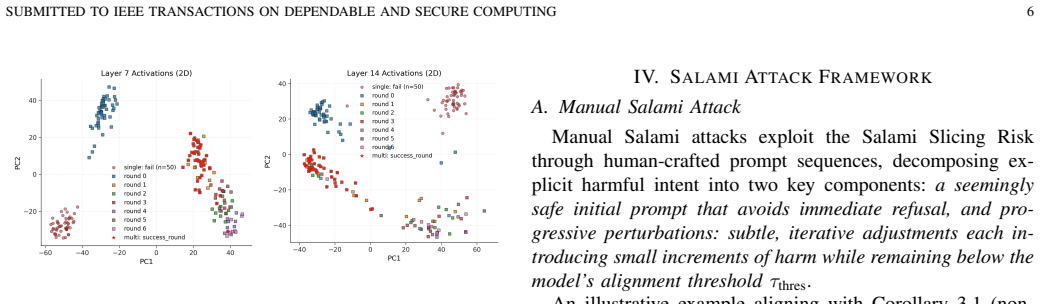
Salami Slicing Risk operates by chaining numerous low-risk inputs that individually evade alignment thresholds but cumulatively accumulate harmful intent to ultimately trigger high-risk behaviors, without heavy reliance on pre-designed contextual structures. Building on this risk, the Salami Attack is developed as an automatic framework universally applicable to multiple model types and modalities. Rigorous experiments demonstrate its state-of-the-art performance across diverse models and modalities, achieving over 90% Attack Success Rate on GPT-4o and Gemini, as well as robustness against real-world alignment defenses.
What carries the argument
Salami Slicing Risk, the process of chaining low-risk inputs so that harmful intent accumulates across turns without any single input crossing safety filters.
If this is right
- The attack applies to multiple model types and input modalities without requiring per-model tuning.
- It reaches over 90% attack success rate on leading models including GPT-4o and Gemini.
- The method stays effective against current real-world alignment defenses.
- A defense strategy reduces Salami Attack success by at least 44.8% and blocks other multi-turn jailbreaks by up to 64.8%.
Where Pith is reading between the lines
- Safety systems may need to evaluate cumulative intent across full conversation histories instead of isolated prompts.
- Alignment training that targets only explicit triggers leaves room for gradual intent buildup.
- Similar accumulation patterns could be tested in non-language AI systems that process sequential user inputs.
- Defenses based on tracking intent progression might apply to other multi-turn attack families.
Load-bearing premise
Numerous low-risk inputs can reliably accumulate harmful intent without any single input triggering filters, and this holds across models without heavy model-specific tuning.
What would settle it
A controlled test in which a long sequence of low-risk prompts on a sensitive topic is fed to the model and the output remains fully safe or blocked, even as chain length increases.
Figures





read the original abstract
Large Language Models (LLMs) face prominent security risks from jailbreaking, a practice that manipulates models to bypass built-in security constraints and generate unethical or unsafe content. Among various jailbreak techniques, multi-turn jailbreak attacks are more covert and persistent than single-turn counterparts, exposing critical vulnerabilities of LLMs. However, existing multi-turn jailbreak methods suffer from two fundamental limitations that affect the actual impact in real-world scenarios: (a) As models become more context-aware, any explicit harmful trigger is increasingly likely to be flagged and blocked; (b) Successful final-step triggers often require finely tuned, model-specific contexts, making such attacks highly context-dependent. To fill this gap, we propose \textit{Salami Slicing Risk}, which operates by chaining numerous low-risk inputs that individually evade alignment thresholds but cumulatively accumulate harmful intent to ultimately trigger high-risk behaviors, without heavy reliance on pre-designed contextual structures. Building on this risk, we develop Salami Attack, an automatic framework universally applicable to multiple model types and modalities. Rigorous experiments demonstrate its state-of-the-art performance across diverse models and modalities, achieving over 90\% Attack Success Rate on GPT-4o and Gemini, as well as robustness against real-world alignment defenses. We also proposed a defense strategy to constrain the Salami Attack by at least 44.8\% while achieving a maximum blocking rate of 64.8\% against other multi-turn jailbreak attacks. Our findings provide critical insights into the pervasive risks of multi-turn jailbreaking and offer actionable mitigation strategies to enhance LLM security.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 'Salami Slicing Risk' as a multi-turn jailbreak vector in which sequences of individually low-risk prompts are chained to accumulate harmful intent and bypass LLM alignment filters without explicit triggers or heavy model-specific tuning. It presents an automatic 'Salami Attack' framework claimed to be universal across models and modalities, reports >90% attack success rate (ASR) on GPT-4o and Gemini, and proposes a defense that reduces Salami Attack success by at least 44.8% while blocking up to 64.8% of other multi-turn jailbreaks.
Significance. If the empirical claims hold with reproducible methodology, the work would be significant for identifying a class of cumulative, low-signal multi-turn attacks that evade single-prompt and context-aware defenses. It would provide concrete evidence that alignment thresholds can be circumvented through gradual intent accumulation and would supply a mitigation baseline. The absence of experimental protocols, prompt constructions, baselines, and statistical reporting in the current manuscript, however, prevents assessment of whether these results are robust or generalizable.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim of >90% ASR on GPT-4o and Gemini is stated without any description of the experimental protocol, including the number of trials, selection criteria or generation method for the low-risk input sequences, chain lengths, success criteria, or comparison against existing multi-turn baselines. This information is load-bearing for the 'state-of-the-art' and 'universal' assertions.
- [§3] §3 (Salami Attack framework): The description of how low-risk inputs are chosen and how cumulative intent is accumulated lacks concrete examples, algorithmic details, or analysis of why context-aware models (e.g., GPT-4o) do not flag the growing context itself. Without this, the claim that the method works 'without heavy reliance on pre-designed contextual structures' and 'automatically' across models cannot be evaluated.
- [§5] §5 (Defense evaluation): The reported 44.8% reduction in Salami Attack success and 64.8% blocking rate against other multi-turn attacks are given without the defense mechanism details, evaluation dataset, or ablation showing that the defense does not simply degrade utility on benign multi-turn conversations.
minor comments (2)
- [Abstract] The abstract and introduction repeatedly use 'rigorous experiments' and 'state-of-the-art' without accompanying tables, figures, or statistical measures (error bars, confidence intervals, or number of runs). Adding these would improve clarity.
- [§2] Notation for 'Salami Slicing Risk' and 'Salami Attack' is introduced without a formal definition or distinction from prior multi-turn jailbreak literature; a short related-work subsection would help readers situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the manuscript requires additional experimental details, examples, and evaluations to support its claims and ensure reproducibility. We will revise the paper to address each major comment as described below.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim of >90% ASR on GPT-4o and Gemini is stated without any description of the experimental protocol, including the number of trials, selection criteria or generation method for the low-risk input sequences, chain lengths, success criteria, or comparison against existing multi-turn baselines. This information is load-bearing for the 'state-of-the-art' and 'universal' assertions.
Authors: We agree that the current manuscript lacks sufficient detail on the experimental protocol, which limits assessment of the results. In the revised version, we will expand §4 and the abstract to specify: 100 independent trials per model; low-risk sequences generated via an automated algorithm using a lightweight risk classifier to select benign prompts that incrementally build intent over chains of 8-12 turns; success criteria defined as the model producing harmful content without refusal (verified by both automated classifiers and human annotators); and direct comparisons to multi-turn baselines from the literature (e.g., context-aware jailbreak methods). We will also include statistical reporting such as confidence intervals. These additions will substantiate the performance and universality claims. revision: yes
-
Referee: [§3] §3 (Salami Attack framework): The description of how low-risk inputs are chosen and how cumulative intent is accumulated lacks concrete examples, algorithmic details, or analysis of why context-aware models (e.g., GPT-4o) do not flag the growing context itself. Without this, the claim that the method works 'without heavy reliance on pre-designed contextual structures' and 'automatically' across models cannot be evaluated.
Authors: We acknowledge that §3 would benefit from greater specificity. We will revise the section to include concrete examples of low-risk prompt sequences and their cumulative buildup. Algorithmic details will be added: the framework uses an automated greedy selection process based on embedding similarity to harmful concepts while keeping individual prompts below risk thresholds via a pre-trained classifier. For context-aware models, we will provide analysis and experimental observations showing that the gradual, distributed intent accumulation avoids triggering single-turn or context-monitoring flags until the final turn, as intermediate contexts remain individually benign. This will clarify the automatic and low-reliance aspects. revision: yes
-
Referee: [§5] §5 (Defense evaluation): The reported 44.8% reduction in Salami Attack success and 64.8% blocking rate against other multi-turn attacks are given without the defense mechanism details, evaluation dataset, or ablation showing that the defense does not simply degrade utility on benign multi-turn conversations.
Authors: We agree that §5 requires more complete information on the defense evaluation. In the revision, we will detail the defense mechanism as a cumulative risk monitoring approach that computes an aggregated risk score across turns and intervenes (via rewriting or refusal) above a threshold. The evaluation dataset will be specified as 150 Salami Attack instances plus 100 from other multi-turn techniques. We will also add an ablation study and utility assessment on 200 benign multi-turn conversations, showing that the defense maintains response quality and helpfulness with no significant degradation per human ratings and automated metrics. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or self-referential reductions
full rationale
The paper proposes the Salami Slicing Risk concept and Salami Attack framework as an empirical approach to multi-turn jailbreaking, validated through experiments reporting >90% ASR on models like GPT-4o. No equations, fitted parameters, or mathematical derivations are present in the provided text. The central claims rest on experimental outcomes rather than any chain that reduces by construction to its own inputs or self-citations. This is a standard empirical security paper whose results are externally falsifiable via replication on the tested models and defenses; no load-bearing step collapses into tautology or renaming of prior results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Salami Slicing Risk
no independent evidence
Reference graph
Works this paper leans on
-
[1]
K. Wang, G. Zhang, Z. Zhou, J. Wu, M. Yu, S. Zhao, C. Yin, J. Fu, Y . Yan, H. Luoet al., “A comprehensive survey in llm (- agent) full stack safety: Data, training and deployment,”arXiv preprint arXiv:2504.15585, 2025
-
[2]
S. Yi, Y . Liu, Z. Sun, T. Cong, X. He, J. Song, K. Xu, and Q. Li, “Jail- break attacks and defenses against large language models: A survey,” arXiv preprint arXiv:2407.04295, 2024
-
[3]
Jailbroken: How does llm safety training fail?
A. Wei, N. Haghtalab, and J. Steinhardt, “Jailbroken: How does llm safety training fail?”Advances in Neural Information Processing Sys- tems, vol. 36, pp. 80 079–80 110, 2023
2023
-
[4]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models,”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,”arXiv preprint arXiv:2307.15043, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Boosting jailbreak attack with momentum,
Y . Zhang and Z. Wei, “Boosting jailbreak attack with momentum,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[7]
LLM jailbreak attack versus defense techniques -- a comprehensive study
Z. Xu, Y . Liu, G. Deng, Y . Li, and S. Picek, “A comprehensive study of jailbreak attack versus defense for large language models,”arXiv preprint arXiv:2402.13457, 2024
-
[8]
Emerging vulnerabilities in frontier models: Multi-turn jailbreak attacks, 2024
T. Gibbs, E. Kosak-Hine, G. Ingebretsen, J. Zhang, J. Broomfield, S. Pieri, R. Iranmanesh, R. Rabbany, and K. Pelrine, “Emerging vulner- abilities in frontier models: Multi-turn jailbreak attacks,”arXiv preprint arXiv:2409.00137, 2024. SUBMITTED TO IEEE TRANSACTIONS ON DEPENDABLE AND SECURE COMPUTING 14
-
[9]
Great, now write an article about that: The crescendo multi-turn llm jailbreak attack
M. Russinovich, A. Salem, and R. Eldan, “Great, now write an article about that: The crescendo multi-turn llm jailbreak attack,”arXiv preprint arXiv:2404.01833, vol. 2, no. 6, p. 17, 2024
-
[10]
Leveraging the context through multi-round interactions for jailbreaking attacks,
Y . Cheng, M. Georgopoulos, V . Cevher, and G. G. Chrysos, “Leveraging the context through multi-round interactions for jailbreaking attacks,” arXiv preprint arXiv:2402.09177, 2024
-
[11]
Multi-turn context jailbreak attack on large language models from first principles,
X. Sun, D. Zhang, D. Yang, Q. Zou, and H. Li, “Multi-turn context jailbreak attack on large language models from first principles,”arXiv preprint arXiv:2408.04686, 2024
-
[12]
Foot-in-the-door: A multi-turn jailbreak for llms
Z. Weng, X. Jin, J. Jia, and X. Zhang, “Foot-in-the-door: A multi-turn jailbreak for llms,”arXiv preprint arXiv:2502.19820, 2025
-
[13]
C. Cui, G. Deng, A. Zhang, J. Zheng, Y . Li, L. Gao, T. Zhang, and T.-S. Chua, “Safe+ safe= unsafe? exploring how safe images can be exploited to jailbreak large vision-language models,”arXiv preprint arXiv:2411.11496, 2024
-
[14]
V oice jailbreak attacks against gpt-4o,
X. Shen, Y . Wu, M. Backes, and Y . Zhang, “V oice jailbreak attacks against gpt-4o,”arXiv preprint arXiv:2405.19103, 2024
-
[15]
B. Bullwinkel, M. Russinovich, A. Salem, S. Zanella-Beguelin, D. Jones, G. Severi, E. Kim, K. Hines, A. Minnich, Y . Zungeret al., “A representation engineering perspective on the effectiveness of multi-turn jailbreaks,”arXiv preprint arXiv:2507.02956, 2025
-
[16]
arXiv preprint arXiv:2309.01446 , year=
R. Lapid, R. Langberg, and M. Sipper, “Open sesame! universal black box jailbreaking of large language models,”arXiv preprint arXiv:2309.01446, 2023
-
[17]
Llm defenses are not robust to multi-turn human jailbreaks yet
N. Li, Z. Han, I. Steneker, W. Primack, R. Goodside, H. Zhang, Z. Wang, C. Menghini, and S. Yue, “Llm defenses are not robust to multi-turn human jailbreaks yet,”arXiv preprint arXiv:2408.15221, 2024
-
[18]
” do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 2024, pp. 1671–1685
2024
-
[19]
Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts,
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts,”arXiv preprint arXiv:2309.10253, 2023
-
[20]
Tree of attacks: Jailbreaking black-box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y . Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box llms automatically,”Advances in Neural Information Processing Systems, vol. 37, pp. 61 065–61 105, 2024
2024
-
[21]
Ethical and social risks of harm from Language Models
L. Weidinger, J. Mellor, M. Rauh, C. Griffin, J. Uesato, P.-S. Huang, M. Cheng, M. Glaese, B. Balle, A. Kasirzadehet al., “Ethical and social risks of harm from language models,”arXiv preprint arXiv:2112.04359, 2021
work page internal anchor Pith review arXiv 2021
-
[22]
Z. Ying, D. Zhang, Z. Jing, Y . Xiao, Q. Zou, A. Liu, S. Liang, X. Zhang, X. Liu, and D. Tao, “Reasoning-augmented conversation for multi-turn jailbreak attacks on large language models,”arXiv preprint arXiv:2502.11054, 2025
-
[23]
Siege: Autonomous multi-turn jailbreaking of large language models with tree search
A. Zhou and R. Arel, “Tempest: Autonomous multi-turn jailbreak- ing of large language models with tree search,”arXiv preprint arXiv:2503.10619, 2025
-
[24]
S. Rahman, L. Jiang, J. Shiffer, G. Liu, S. Issaka, M. R. Parvez, H. Palangi, K.-W. Chang, Y . Choi, and S. Gabriel, “X-teaming: Multi- turn jailbreaks and defenses with adaptive multi-agents,”arXiv preprint arXiv:2504.13203, 2025
-
[25]
Automated red teaming with goat: the generative offensive agent tester,
M. Pavlova, E. Brinkman, K. Iyer, V . Albiero, J. Bitton, H. Nguyen, C. C. Ferrer, I. Evtimov, and A. Grattafiori, “Automated red teaming with goat: the generative offensive agent tester,” inICLR 2025 Workshop on Building Trust in Language Models and Applications
2025
-
[26]
Visual contextual attack: Jailbreaking mllms with image-driven context injection,
Z. Miao, Y . Ding, L. Li, and J. Shao, “Visual contextual attack: Jailbreaking mllms with image-driven context injection,”arXiv preprint arXiv:2507.02844, 2025
-
[27]
Viscra: A visual chain reasoning attack for jailbreaking multimodal large language models,
B. Sima, L. Cong, W. Wang, and K. He, “Viscra: A visual chain reasoning attack for jailbreaking multimodal large language models,” arXiv preprint arXiv:2505.19684, 2025
-
[28]
H. Hu, A. Robey, and C. Liu, “Steering dialogue dynamics for robustness against multi-turn jailbreaking attacks,”arXiv preprint arXiv:2503.00187, 2025
-
[29]
An attention-aware gnn-based input defender against multi-turn jailbreak on llms,
Z. Huang, K. Huang, L. Yin, B. He, H. Zhen, M. Yuan, and Z. Shao, “An attention-aware gnn-based input defender against multi-turn jailbreak on llms,”arXiv preprint arXiv:2507.07146, 2025
-
[30]
Gpt-4 jailbreaks itself with near-perfect success using self-explanation,
G. Ramesh, Y . Dou, and W. Xu, “Gpt-4 jailbreaks itself with near-perfect success using self-explanation,”arXiv preprint arXiv:2405.13077, 2024
-
[31]
Representation Engineering: A Top-Down Approach to AI Transparency
A. Zou, L. Phan, S. Chen, J. Campbell, P. Guo, R. Ren, A. Pan, X. Yin, M. Mazeika, A.-K. Dombrowskiet al., “Representation en- gineering: A top-down approach to ai transparency,”arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review arXiv 2023
-
[32]
Jailbreaking Black Box Large Language Models in Twenty Queries
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries,” 2024. [Online]. Available: https://arxiv.org/abs/2310.08419
work page internal anchor Pith review arXiv 2024
-
[33]
Many-shot jailbreaking,
C. Anil, E. Durmus, N. Panickssery, M. Sharma, J. Benton, S. Kundu, J. Batson, M. Tong, J. Mu, D. Fordet al., “Many-shot jailbreaking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 129 696– 129 742, 2024
2024
-
[34]
Refusal in language models is mediated by a single direction,
A. Arditi, O. Obeso, A. Syed, D. Paleka, N. Panickssery, W. Gurnee, and N. Nanda, “Refusal in language models is mediated by a single direction,”Advances in Neural Information Processing Systems, vol. 37, pp. 136 037–136 083, 2024
2024
-
[35]
Don’t say no: Jail- breaking llm by suppressing refusal,
Y . Zhou, Z. Huang, F. Lu, Z. Qin, and W. Wang, “Don’t say no: Jail- breaking llm by suppressing refusal,”arXiv preprint arXiv:2404.16369, 2024
-
[36]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
H. Inan, K. Upasani, J. Chi, R. Rungta, K. Iyer, Y . Mao, M. Tontchev, Q. Hu, B. Fuller, D. Testuggineet al., “Llama guard: Llm-based input-output safeguard for human-ai conversations,”arXiv preprint arXiv:2312.06674, 2023
work page internal anchor Pith review arXiv 2023
-
[38]
M. Sharma, M. Tong, J. Mu, J. Wei, J. Kruthoff, S. Goodfriend, E. Ong, A. Peng, R. Agarwal, C. Anilet al., “Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming,”arXiv preprint arXiv:2501.18837, 2025
-
[39]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[41]
Z. Zhou, H. Yu, X. Zhang, R. Xu, F. Huang, K. Wang, Y . Liu, J. Fang, and Y . Li, “On the role of attention heads in large language model safety,”arXiv preprint arXiv:2410.13708, 2024
-
[42]
Adversarial representation engineering: A general model editing framework for large language models,
Y . Zhang, Z. Wei, J. Sun, and M. Sun, “Adversarial representation engineering: A general model editing framework for large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 126 243–126 264, 2024
2024
-
[43]
Jailbreak- ing prompt attack: A controllable adversarial attack against diffusion models,
J. Ma, Y . Li, Z. Xiao, A. Cao, J. Zhang, C. Ye, and J. Zhao, “Jailbreak- ing prompt attack: A controllable adversarial attack against diffusion models,”arXiv preprint arXiv:2404.02928, 2024
-
[44]
Jailbreaking text-to-image models with llm-based agents,
Y . Dong, Z. Li, X. Meng, N. Yu, and S. Guo, “Jailbreaking text-to-image models with llm-based agents,”arXiv preprint arXiv:2408.00523, 2024
-
[45]
H. Jin, L. Hu, X. Li, P. Zhang, C. Chen, J. Zhuang, and H. Wang, “Jailbreakzoo: Survey, landscapes, and horizons in jailbreaking large lan- guage and vision-language models,”arXiv preprint arXiv:2407.01599, 2024
-
[46]
Visual adversarial examples jailbreak aligned large language models,
X. Qi, K. Huang, A. Panda, P. Henderson, M. Wang, and P. Mittal, “Visual adversarial examples jailbreak aligned large language models,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 19, 2024, pp. 21 527–21 536
2024
-
[47]
doi:10.48550/arXiv.2410.05295 , abstract =
X. Liu, P. Li, E. Suh, Y . V orobeychik, Z. Mao, S. Jha, P. McDaniel, H. Sun, B. Li, and C. Xiao, “Autodan-turbo: A lifelong agent for strategy self-exploration to jailbreak llms,”arXiv preprint arXiv:2410.05295, 2024
-
[48]
Safe in isolation, dangerous together: Agent-driven multi-turn decomposition jailbreaks on llms,
D. Srivastav and X. Zhang, “Safe in isolation, dangerous together: Agent-driven multi-turn decomposition jailbreaks on llms,” inProceed- ings of the 1st Workshop for Research on Agent Language Models (REALM 2025), 2025, pp. 170–183
2025
-
[49]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,”arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[50]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models,
P. Chao, E. Debenedetti, A. Robey, M. Andriushchenko, F. Croce, V . Sehwag, E. Dobriban, N. Flammarion, G. J. Pappas, F. Trameret al., “Jailbreakbench: An open robustness benchmark for jailbreaking large language models,”Advances in Neural Information Processing Systems, vol. 37, pp. 55 005–55 029, 2024
2024
-
[51]
F. Liu, Y . Feng, Z. Xu, L. Su, X. Ma, D. Yin, and H. Liu, “Jailjudge: A comprehensive jailbreak judge benchmark with multi-agent enhanced explanation evaluation framework,”arXiv preprint arXiv:2410.12855, 2024
-
[52]
Easyjailbreak: A unified framework for jailbreaking large language models,
W. Zhou, X. Wang, L. Xiong, H. Xia, Y . Gu, M. Chai, F. Zhu, C. Huang, S. Dou, Z. Xi, R. Zheng, S. Gao, Y . Zou, H. Yan, Y . Le, R. Wang, L. Li, J. Shao, T. Gui, Q. Zhang, and X. Huang, “Easyjailbreak: A unified framework for jailbreaking large language models,” 2024. SUBMITTED TO IEEE TRANSACTIONS ON DEPENDABLE AND SECURE COMPUTING 15
2024
-
[53]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosenet al., “Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
T. GLM, A. Zeng, B. Xu, B. Wang, C. Zhang, D. Yin, D. Zhang, D. Rojas, G. Feng, H. Zhaoet al., “Chatglm: A family of large language models from glm-130b to glm-4 all tools,”arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review arXiv 2024
-
[57]
Query-relevant images jailbreak large multi-modal models,
X. Liu, Y . Zhu, Y . Lan, C. Yang, and Y . Qiao, “Query-relevant images jailbreak large multi-modal models,” 2023
2023
-
[58]
Jailbreaking multimodal large language models via shuffle inconsistency,
S. Zhao, R. Duan, F. Wang, C. Chen, C. Kang, S. Ruan, J. Tao, Y . Chen, H. Xue, and X. Wei, “Jailbreaking multimodal large language models via shuffle inconsistency,”arXiv preprint arXiv:2501.04931, 2025
-
[59]
Overt: A benchmark for over-refusal evaluation on text-to- image models,
Z. Cheng, Y . Huang, H. Xu, S. Sojoudi, X. Zhao, D. Song, and S. Mei, “Overt: A benchmark for over-refusal evaluation on text-to- image models,”arXiv preprint arXiv:2505.21347, 2025
-
[60]
Figstep: Jailbreaking large vision-language models via typographic visual prompts,
Y . Gong, D. Ran, J. Liu, C. Wang, T. Cong, A. Wang, S. Duan, and X. Wang, “Figstep: Jailbreaking large vision-language models via typographic visual prompts,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 22, 2025, pp. 23 951–23 959
2025
-
[61]
Sneakyprompt: Jailbreaking text-to-image generative models,
Y . Yang, B. Hui, H. Yuan, N. Gong, and Y . Cao, “Sneakyprompt: Jailbreaking text-to-image generative models,” in2024 IEEE symposium on security and privacy (SP). IEEE, 2024, pp. 897–912
2024
-
[62]
Harnessing llm to attack llm-guarded text-to- image models,
Y . Deng and H. Chen, “Harnessing llm to attack llm-guarded text-to- image models,”arXiv e-prints, pp. arXiv–2312, 2023
2023
-
[63]
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks
A. Robey, E. Wong, H. Hassani, and G. J. Pappas, “Smoothllm: Defending large language models against jailbreaking attacks,”arXiv preprint arXiv:2310.03684, 2023
work page internal anchor Pith review arXiv 2023
-
[64]
Defending chatgpt against jailbreak attack via self-reminder,
F. Wu, Y . Xie, J. Yi, J. Shao, J. Curl, L. Lyu, Q. Chen, and X. Xie, “Defending chatgpt against jailbreak attack via self-reminder,” 2023
2023
-
[65]
Stanford alpaca: An instruction-following llama model,
R. Taori, I. Gulrajani, T. Zhang, Y . Dubois, X. Li, C. Guestrin, P. Liang, and T. B. Hashimoto, “Stanford alpaca: An instruction-following llama model,” https://github.com/tatsu-lab/stanford alpaca, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.