Recognition: 2 theorem links
· Lean TheoremPersonaVLM: Long-Term Personalized Multimodal LLMs
Pith reviewed 2026-05-15 07:58 UTC · model grok-4.3
The pith
PersonaVLM equips multimodal language models with long-term memory of user interactions to deliver personalized responses over time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
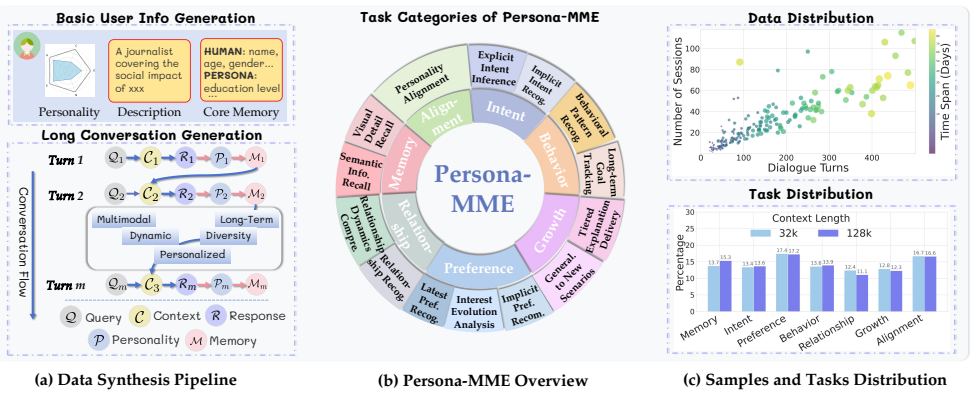
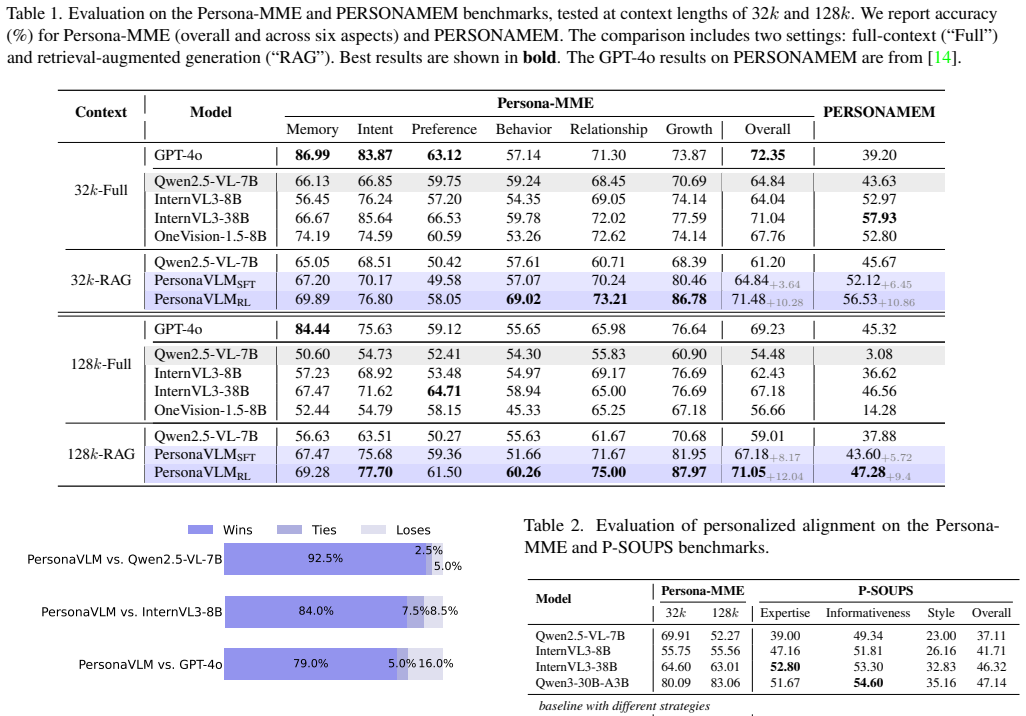
PersonaVLM transforms a general-purpose MLLM into a personalized assistant by integrating remembering through proactive extraction and summarization of chronological multimodal memories into a database, reasoning via retrieval and integration of relevant memories, and response alignment by inferring evolving user personality, leading to improvements of 22.4% on Persona-MME and 9.8% on PERSONAMEM under 128k context while outperforming GPT-4o.
What carries the argument
The chronological multimodal memory database built through proactive extraction and summarization, which supports multi-turn reasoning and personality inference for aligned responses.
If this is right
- Models can maintain consistent personalization across long interaction histories exceeding 128k tokens.
- Performance on personalized multimodal tasks improves substantially over general-purpose baselines and even GPT-4o.
- Users receive responses that reflect their unique evolving characteristics rather than generic outputs.
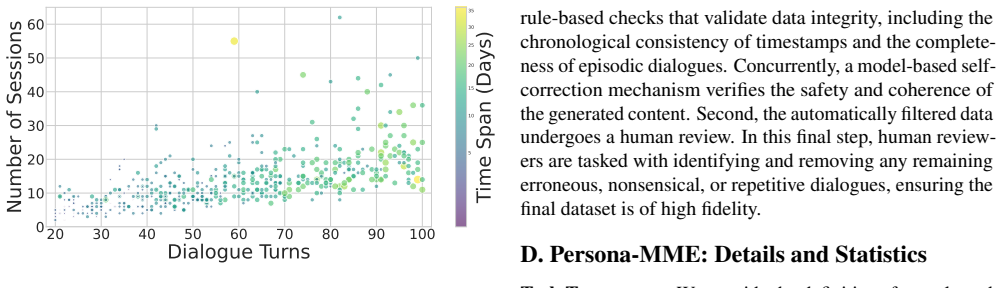
- Evaluation across seven aspects and 14 tasks in Persona-MME shows effectiveness in long-term scenarios.
Where Pith is reading between the lines
- Such memory mechanisms could extend to other domains like personalized recommendation systems or long-term planning assistants.
- Privacy concerns arise if the memory database stores detailed user histories without strong safeguards.
- Testing on even longer contexts or real-world user studies would further validate the approach.
Load-bearing premise
The base multimodal model can reliably extract and summarize key user-specific details from long sequences of interactions without systematic errors or omissions.
What would settle it
Running the memory extraction on a controlled set of 100+ simulated long-term interactions and finding that critical personality traits are missed or distorted in the resulting database.
Figures



















read the original abstract
Multimodal Large Language Models (MLLMs) serve as daily assistants for millions. However, their ability to generate responses aligned with individual preferences remains limited. Prior approaches enable only static, single-turn personalization through input augmentation or output alignment, and thus fail to capture users' evolving preferences and personality over time (see Fig.1). In this paper, we introduce PersonaVLM, an innovative personalized multimodal agent framework designed for long-term personalization. It transforms a general-purpose MLLM into a personalized assistant by integrating three key capabilities: (a) Remembering: It proactively extracts and summarizes chronological multimodal memories from interactions, consolidating them into a personalized database. (b) Reasoning: It conducts multi-turn reasoning by retrieving and integrating relevant memories from the database. (c) Response Alignment: It infers the user's evolving personality throughout long-term interactions to ensure outputs remain aligned with their unique characteristics. For evaluation, we establish Persona-MME, a comprehensive benchmark comprising over 2,000 curated interaction cases, designed to assess long-term MLLM personalization across seven key aspects and 14 fine-grained tasks. Extensive experiments validate our method's effectiveness, improving the baseline by 22.4% (Persona-MME) and 9.8% (PERSONAMEM) under a 128k context, while outperforming GPT-4o by 5.2% and 2.0%, respectively. Project page: https://PersonaVLM.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PersonaVLM, a framework that converts a general-purpose MLLM into a long-term personalized multimodal assistant via three integrated modules: Remembering (proactive extraction and summarization of chronological multimodal interaction memories into a personalized database), Reasoning (multi-turn retrieval and integration of relevant memories), and Response Alignment (inference of evolving user personality to align outputs). It presents the new Persona-MME benchmark (>2,000 curated cases across 7 aspects and 14 tasks) and reports empirical gains of 22.4% on Persona-MME and 9.8% on PERSONAMEM (128k context) over baseline, plus 5.2% and 2.0% over GPT-4o.
Significance. If the reported gains are robust, the work advances long-term personalization in MLLMs beyond static single-turn methods by explicitly modeling memory accumulation, multi-turn reasoning, and personality drift; the new benchmark and the three-module architecture could serve as a useful reference point for future personalized agent research.
major comments (2)
- [Abstract / Remembering module] Abstract and Remembering module description: the 22.4% and 9.8% gains are presented as evidence that proactive memory extraction works reliably, yet no independent fidelity metric, human verification, or error analysis of the extracted/summarized memories is described; because this step feeds directly into Reasoning and Response Alignment, any systematic extraction errors would undermine the central performance claims.
- [Evaluation section] Evaluation protocol (Persona-MME and PERSONAMEM results): the abstract states specific percentage improvements but supplies no details on statistical significance testing, exact prompt templates, controls for prompt-engineering effects, or variance across runs; without these, it is unclear whether the reported margins fully support the superiority claims over the baseline and GPT-4o.
minor comments (2)
- [Figure 1] Figure 1 caption and legend: the contrast between prior static approaches and the proposed long-term framework would be clearer if the three capabilities (Remembering, Reasoning, Response Alignment) were explicitly labeled on the diagram.
- [Benchmark section] Benchmark description: the claim that Persona-MME covers “seven key aspects and 14 fine-grained tasks” would benefit from an explicit table mapping aspects to tasks and example interaction cases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger validation of memory extraction and more rigorous evaluation reporting. We address each major comment below and have revised the manuscript accordingly to improve transparency and robustness.
read point-by-point responses
-
Referee: [Abstract / Remembering module] Abstract and Remembering module description: the 22.4% and 9.8% gains are presented as evidence that proactive memory extraction works reliably, yet no independent fidelity metric, human verification, or error analysis of the extracted/summarized memories is described; because this step feeds directly into Reasoning and Response Alignment, any systematic extraction errors would undermine the central performance claims.
Authors: We agree that independent validation of memory extraction quality is necessary to substantiate the performance claims. In the revised manuscript we have added a new subsection (Section 4.3) reporting human verification on a random sample of 300 extracted memories (94% accuracy per annotator agreement) together with a categorized error analysis of omission, hallucination, and temporal misalignment cases. The analysis shows low overall error rates (<6%) with no systematic correlation to downstream task failures, thereby supporting the reliability of the reported gains. revision: yes
-
Referee: [Evaluation section] Evaluation protocol (Persona-MME and PERSONAMEM results): the abstract states specific percentage improvements but supplies no details on statistical significance testing, exact prompt templates, controls for prompt-engineering effects, or variance across runs; without these, it is unclear whether the reported margins fully support the superiority claims over the baseline and GPT-4o.
Authors: We acknowledge the importance of these details for reproducibility and claim strength. The revised evaluation section now includes paired t-test p-values (all <0.01 for key comparisons), standard deviations across five independent runs, and explicit controls for prompt-engineering effects via fixed prompt templates applied uniformly to all models. The exact templates and generation settings have been moved to Appendix C. These additions confirm that the 22.4% and 5.2% margins are statistically significant and robust. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PersonaVLM as a framework that augments a base MLLM with remembering (proactive extraction/summarization into a database), reasoning (multi-turn retrieval), and response alignment modules. It evaluates on the newly introduced Persona-MME benchmark (over 2,000 cases) and reports gains versus external baselines including GPT-4o. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the text. The performance numbers are measured against independent external models and the new benchmark rather than reducing to quantities defined by the method's own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- context window size
axioms (1)
- domain assumption Multimodal LLMs can extract and summarize chronological user memories from interaction histories without catastrophic loss of detail.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Remembering: It proactively extracts and summarizes chronological multimodal memories... Reasoning: It conducts multi-turn reasoning by retrieving... Response Alignment: It infers the user’s evolving personality
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Personality Evolving Mechanism (PEM)... exponential moving average... Big Five scores
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Myvlm: Personalizing vlms for user-specific queries
Yuval Alaluf, Elad Richardson, Sergey Tulyakov, Kfir Aber- man, and Daniel Cohen-Or. Myvlm: Personalizing vlms for user-specific queries. InECCV, 2024
work page 2024
-
[3]
Rawan AlSaad, Alaa Abd-Alrazaq, Sabri Boughorbel, Arfan Ahmed, Max-Antoine Renault, Rafat Damseh, and Javaid Sheikh. Multimodal large language models in health care: ap- plications, challenges, and future outlook.Journal of medical Internet research, 2024
work page 2024
-
[4]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training. arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
When large language models meet personalization: Perspectives of challenges and opportunities
Jin Chen, Zheng Liu, Xu Huang, Chenwang Wu, Qi Liu, Gangwei Jiang, Yuanhao Pu, Yuxuan Lei, Xiaolong Chen, Xingmei Wang, et al. When large language models meet personalization: Perspectives of challenges and opportunities. World Wide Web, 2024
work page 2024
-
[7]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodal- ity, long context, and next generation agentic capabilities. arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv:2406.20094, 2024
Tao Ge, Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv:2406.20094, 2024
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning ca- pability in llms via reinforcement learning.arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Rap: Retrieval-augmented personalization for multimodal large language models
Haoran Hao, Jiaming Han, Changsheng Li, Yu-Feng Li, and Xiangyu Yue. Rap: Retrieval-augmented personalization for multimodal large language models. InCVPR, 2025
work page 2025
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Joel Jang, Seungone Kim, Bill Yuchen Lin, Yizhong Wang, Jack Hessel, Luke Zettlemoyer, Hannaneh Hajishirzi, Yejin Choi, and Prithviraj Ammanabrolu. Personalized soups: Per- sonalized large language model alignment via post-hoc pa- rameter merging.arXiv:2310.11564, 2023
-
[14]
Bowen Jiang, Zhuoqun Hao, Young-Min Cho, Bryan Li, Yuan Yuan, Sihao Chen, Lyle Ungar, Camillo J Taylor, and Dan Roth. Know me, respond to me: Benchmarking llms for dynamic user profiling and personalized responses at scale. arXiv:2504.14225, 2025
-
[15]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search- r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
The big-five trait tax- onomy: History, measurement, and theoretical perspectives
Oliver P John, Sanjay Srivastava, et al. The big-five trait tax- onomy: History, measurement, and theoretical perspectives. 1999
work page 1999
-
[17]
Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 2019
work page 2019
-
[18]
Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai. Mem- ory os of ai agent. 2025
work page 2025
-
[19]
Multimodal founda- tion models: From specialists to general-purpose assistants
Chunyuan Li, Zhe Gan, Zhengyuan Yang, Jianwei Yang, Lin- jie Li, Lijuan Wang, Jianfeng Gao, et al. Multimodal founda- tion models: From specialists to general-purpose assistants. Foundations and Trends® in Computer Graphics and Vision, 2024
work page 2024
-
[20]
Hello again! llm-powered personalized agent for long-term dialogue.arXiv:2406.05925, 2024
Hao Li, Chenghao Yang, An Zhang, Yang Deng, Xiang Wang, and Tat-Seng Chua. Hello again! llm-powered personalized agent for long-term dialogue.arXiv:2406.05925, 2024
-
[21]
Jia-Nan Li, Jian Guan, Songhao Wu, Wei Wu, and Rui Yan. From 1,000,000 users to every user: Scaling up personalized preference for user-level alignment.arXiv:2503.15463, 2025
-
[22]
MemOS: A Memory OS for AI System
Zhiyu Li, Shichao Song, Chenyang Xi, Hanyu Wang, Chen Tang, Simin Niu, Ding Chen, Jiawei Yang, Chunyu Li, Qingchen Yu, et al. Memos: A memory os for ai system. arXiv:2507.03724, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InNeurIPS, 2023
work page 2023
-
[24]
A survey of personalized large language models: Progress and future directions
Jiahong Liu, Zexuan Qiu, Zhongyang Li, Quanyu Dai, Wenhao Yu, Jieming Zhu, Minda Hu, Menglin Yang, Tat- Seng Chua, and Irwin King. A survey of personalized large language models: Progress and future directions. arXiv:2502.11528, 2025
-
[25]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InECCV, 2024
work page 2024
-
[26]
Lin Long, Yichen He, Wentao Ye, Yiyuan Pan, Yuan Lin, Hang Li, Junbo Zhao, and Wei Li. Seeing, listening, remem- bering, and reasoning: A multimodal agent with long-term memory.arXiv:2508.09736, 2025
-
[27]
Query rewriting in retrieval-augmented large language models
Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting in retrieval-augmented large language models. InEMNLP, 2023
work page 2023
-
[28]
Yo’llava: Your personalized language and vision assistant
Thao Nguyen, Haotian Liu, Yuheng Li, Mu Cai, Utkarsh Ojha, and Yong Jae Lee. Yo’llava: Your personalized language and vision assistant. InNeurIPS, 2024
work page 2024
-
[29]
Yeongtak Oh, Jisoo Mok, Dohyun Chung, Juhyeon Shin, Sangha Park, Johan Barthelemy, and Sungroh Yoon. Repic: Reinforced post-training for personalizing multi-modal lan- guage models.arXiv:2506.18369, 2025
-
[30]
Training lan- guage models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Car- roll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training lan- guage models to follow instructions with human feedback. In NeurIPS, 2022
work page 2022
-
[31]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir_G Patil, Kevin Lin, Sarah Wooders, and Joseph_E Gonzalez. Memgpt: Towards llms as operating systems.arXiv:2310.08560, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Personalized visual instruction tuning
Renjie Pi, Jianshu Zhang, Tianyang Han, Jipeng Zhang, Rui Pan, and Tong Zhang. Personalized visual instruction tuning. arXiv:2410.07113, 2024
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
work page 2021
-
[34]
Direct prefer- ence optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct prefer- ence optimization: Your language model is secretly a reward model. InNeurIPS, 2023
work page 2023
-
[35]
The big five personality factors and personal values
Sonia Roccas, Lilach Sagiv, Shalom H Schwartz, and Ariel Knafo. The big five personality factors and personal values. Personality and social psychology bulletin, 2002
work page 2002
-
[36]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms.arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
Democratizing large lan- guage models via personalized parameter-efficient fine-tuning
Zhaoxuan Tan, Qingkai Zeng, Yijun Tian, Zheyuan Liu, Bing Yin, and Meng Jiang. Democratizing large lan- guage models via personalized parameter-efficient fine-tuning. arXiv:2402.04401, 2024
-
[38]
Towards next-generation llm-based recommender systems: A survey and beyond.arXiv:2410.19744, 2024
Qi Wang, Jindong Li, Shiqi Wang, Qianli Xing, Runliang Niu, He Kong, Rui Li, Guodong Long, Yi Chang, and Chengqi Zhang. Towards next-generation llm-based recommender systems: A survey and beyond.arXiv:2410.19744, 2024
-
[39]
Augmenting language models with long-term memory
Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory. InNeurIPS, 2023
work page 2023
-
[40]
MIRIX: Multi-Agent Memory System for LLM-Based Agents
Yu Wang and Xi Chen. Mirix: Multi-agent memory system for llm-based agents.arXiv:2507.07957, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Ai-native memory 2.0: Second me
Jiale Wei, Xiang Ying, Tao Gao, Fangyi Bao, Felix Tao, and Jingbo Shang. Ai-native memory 2.0: Second me. arXiv:2503.08102, 2025
-
[42]
Rossi, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, Jiuxiang Gu, Nesreen K
Junda Wu, Hanjia Lyu, Yu Xia, Zhehao Zhang, Joe Barrow, Ishita Kumar, Mehrnoosh Mirtaheri, Hongjie Chen, Ryan A Rossi, Franck Dernoncourt, et al. Personalized multimodal large language models: A survey.arXiv:2412.02142, 2024
-
[43]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Kai Mei, Hang Gao, Juntao Tan, Zujie Liang, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv:2502.12110, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Zhenyu Xu, Hailin Xu, Zhouyang Lu, Yingying Zhao, Rui Zhu, Yujiang Wang, Mingzhi Dong, Yuhu Chang, Qin Lv, Robert P Dick, et al. Can large language models be good com- panions? an llm-based eyewear system with conversational common ground. InIMWUT, 2024
work page 2024
-
[45]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
A survey on multimodal large language models.National Science Review, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 2024
work page 2024
-
[48]
From mooc to maic: Reshap- ing online teaching and learning through llm-driven agents
Jifan Yu, Zheyuan Zhang, Daniel Zhang-li, Shangqing Tu, Zhanxin Hao, Rui Miao Li, Haoxuan Li, Yuanchun Wang, Hanming Li, Linlu Gong, et al. From mooc to maic: Reshap- ing online teaching and learning through llm-driven agents. arXiv:2409.03512, 2024
-
[49]
Zhehao Zhang, Ryan A Rossi, Branislav Kveton, Yijia Shao, Diyi Yang, Hamed Zamani, Franck Dernoncourt, Joe Bar- row, Tong Yu, Sungchul Kim, et al. Personalization of large language models: A survey.arXiv:2411.00027, 2024
-
[50]
Siyan Zhao, Mingyi Hong, Yang Liu, Devamanyu Haz- arika, and Kaixiang Lin. Do llms recognize your prefer- ences? evaluating personalized preference following in llms. arXiv:2502.09597, 2025
-
[51]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shen- glong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Per- sonality alignment of large language models
Minjun Zhu, Yixuan Weng, Linyi Yang, and Yue Zhang. Per- sonality alignment of large language models. InICLR, 2025
work page 2025
-
[53]
Yuchen Zhuang, Haotian Sun, Yue Yu, Rushi Qiang, Qifan Wang, Chao Zhang, and Bo Dai. Hydra: Model factorization framework for black-box llm personalization. InNeurIPS, 2024. PersonaVLM: Long-Term Personalized Multimodal LLMs Supplementary Material This supplementary material provides comprehensive details to complement the main paper, organized as follows...
work page 2024
-
[54]
Adapt & Personalize: Your tone and style must adapt to the user’s Big Five Personality scores (e.g., be reassuring for high Neuroticism, practical for low Openness)
-
[55]
Natural Weaving: Naturally weave in relevant details from memories to show you remember, but avoid repeating recent information
-
[56]
Decide Your Action: Based on the user’s query and context, first decide if you have enough information to answer directly or if you need to search your long-term memory. # Output Format Your output must consist of a ‘<think>‘ block, followed by **one and only one of the following blocks (‘<answer>‘ or ‘<retrieve>‘): <think>Your reasoning process goes here...
-
[57]
Analyze: Based on the linguistic and emotional cues in the ‘User Input‘ and its context, infer the user’s momentary Big Five personality state
-
[58]
Score: Assign an integer score from 1 to 5 for each trait. # OUTPUT INSTRUCTIONS Provide your response as a series of key-value pairs, one item per line. "openness": [integer from 1 to 5] "conscientiousness": [integer from 1 to 5] "extraversion": [integer from 1 to 5] "agreeableness": [integer from 1 to 5] "neuroticism": [integer from 1 to 5] Figure 18. P...
-
[59]
Consolidate related behaviors into a single core habit
Identify & Update: Extract user-centric, long-term goals or repetitive habits from the conversation. Consolidate related behaviors into a single core habit. Update or remove goals/habits that are completed or changed
-
[60]
User runs every Thursday morning
Core Content (‘content‘): Each memory must be a single, simple third-person sentence describing the user’s habit or goal. Include time/trigger context if available (e.g., "User runs every Thursday morning")
-
[61]
Unique Keys (‘unique key‘): Assign a concise, unique key for each memory
-
[62]
* Strictly prohibited from creating information not present in the input
Constraints: * The final output must not exceed 5 entries. * Strictly prohibited from creating information not present in the input. * If no relevant habits/goals are found, output an empty object. # Input
-
[63]
Current User Profile: {UserProfile}
-
[64]
Current Procedural Memory: {CurrentProceduralMemory}
-
[65]
Recent Conversations: {DialogHistory} # Output Format Provide your response as key-value pairs, one per line. "unique key 1": string, A single sentence describing the habit. "unique key 2": string, Another single sentence describing the goal. Figure 19. Prompt for updating procedural memories. Prompt for semantic memory creation You are an AI memory analy...
-
[66]
Briefly explain the reason for the ‘decision‘
‘reason‘ (string): * Required. Briefly explain the reason for the ‘decision‘
-
[67]
‘decision‘ (boolean): * Set to ‘true‘: User explicitly instructs to remember; user mentions new core facts, preferences, dislikes, important corrections, long-term goals/states. * Set to ‘false‘: Information is already in the user profile/recent history with no updates; temporary questions, meaningless small talk
-
[68]
‘content‘ (string): * If ‘decision‘ is ‘true‘, extract and summarize the memory content. * Text Memory: Pure text information, dates, events, concepts, or non-specific object descriptions of images (e.g., atmosphere). * Image Object Memory: User indicates remembering a specific object in an image, format is ‘[User Description/Naming] (Image Object: [Objec...
-
[69]
‘keywords‘ (string): * If ‘decision‘ is ‘true‘, list a few core keywords, separated by English commas. * If ‘decision‘ is ‘false‘, set to ‘""‘. Core Constraint: Strictly prohibited from creating or supplementing information not present in the current input and history. # Output Format (four key-value pairs, one per line.) "reason": string "decision": true...
-
[70]
Core Identity: New information directly overwrites old values (e.g., name, occupation, long-term residence)
-
[71]
Emphasize recency and intensity
Core Preferences/Hobbies: Intelligently replace/condense/add. Emphasize recency and intensity. Limit list length (e.g., 5-7 items). Ignore temporary/weak preferences
-
[72]
Temporary Information: Strictly ignore (e.g., short-term itineraries, one-time activities)
-
[73]
XX": string // HUMAN Aspect, e.g., age, gender, preferences, life status, etc
No Fabrication: All fields and information must originate from the input; strictly prohibited from creating new information. # Output Format (mutiple key-value pairs, one per line) "XX": string // HUMAN Aspect, e.g., age, gender, preferences, life status, etc. "XX": string // PERSONA Aspect, e.g., occupation, education background, etc. Figure 21. Prompt f...
-
[74]
Topic Summary (‘topic_summary‘): Coherent, complete third-person summary
-
[75]
Keywords (‘keywords‘): Extract core keywords
-
[76]
Source Indices (‘source_dialog_indices‘): Contains indices of all relevant dialogues. # Input User Profile: {UserProfile} Recent Conversations: {DialogHistory} # Core Constraint Strictly prohibited from creating or supplementing information not present in the dialogue history. # Output Format (each topic includes the following three key-value pairs) "topi...
-
[77]
User’s Query: {query}
-
[78]
Reference Answer (Ground Truth): {reference_answer} # RESPONSES TO COMPARE - Response A: {response_A} - Response B: {response_B} # EVALUATION INSTRUCTIONS Your task is to compare Response A and Response B to decide which one is superior. You will base your decision on the two criteria below. The final output must be a single word: "Wins" if A is better, "...
-
[79]
- Use the **Reference Answer ** as the ground truth for what a perfect answer should contain
Accuracy: - Evaluate which response is more factually correct and completely addresses the user’s query. - Use the **Reference Answer ** as the ground truth for what a perfect answer should contain. - A more accurate response directly reflects the information and intent of the Reference Answer
-
[80]
Personalization: - Evaluate which response’s tone, style, and language better adapt to the user’s stated **Personality Traits **. - A more personalized response feels tailored to the user, not generic. ## Decision Logic: - Output "Wins" if: Response A is clearly superior to Response B on at least one criterion and is not worse on the other. - Output "Lose...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.