Recognition: unknown
Don't Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills for QA and RAG
Pith reviewed 2026-05-10 10:27 UTC · model grok-4.3
The pith
Distilling document corpora into hierarchical skill trees lets LLM agents actively navigate and outperform passive retrieval in RAG.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
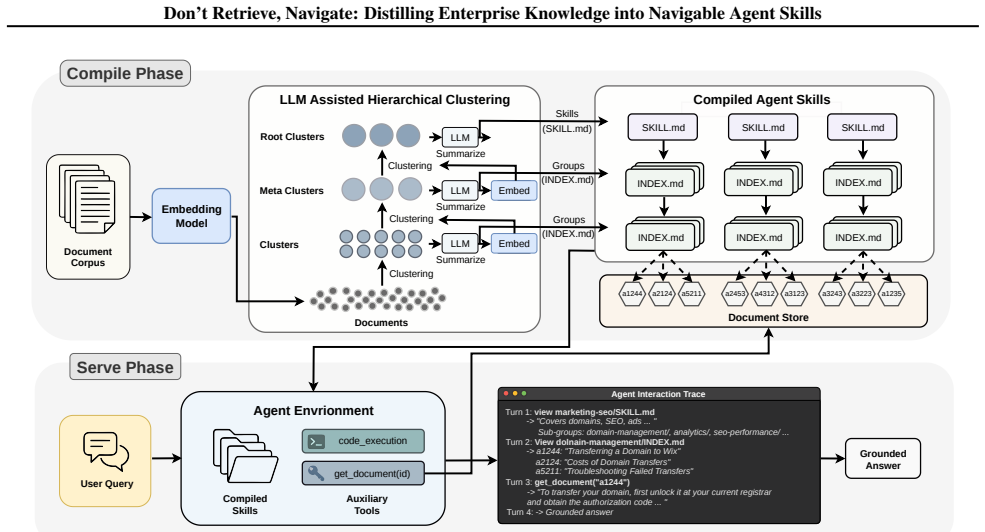
Corpus2Skill converts a static document collection into an explicit, browsable hierarchy of summaries so that an LLM agent can reason about where evidence lives, drill down progressively, and combine findings from multiple branches instead of depending on one-shot vector retrieval.
What carries the argument
The offline Corpus2Skill pipeline of iterative clustering followed by LLM summarization that materializes the corpus as a tree of navigable skill files.
If this is right
- Agents gain visibility into corpus structure and can backtrack from dead-end branches.
- Evidence scattered across documents becomes easier to combine.
- Navigation is the superior primitive for single-domain atomic-document collections.
- Flat retrieval remains better for open-domain or extractive settings.
- Macro-average F1 is highest across the ten-dataset evaluation suite.
Where Pith is reading between the lines
- The method implies that pre-building a knowledge map can turn retrieval into a controllable search process rather than a black-box match.
- Similar hierarchies might help agents in other structured domains such as code repositories or legal archives.
- Performance gains may depend on how well the clustering respects natural topic boundaries in the corpus.
Load-bearing premise
The LLM-generated summaries faithfully represent the underlying documents so the agent can correctly choose which branches contain the answer without overlooking cross-links.
What would settle it
An experiment on a corpus with known cross-topic links where the hierarchy's summaries cause the agent to miss evidence that flat retrieval would surface, resulting in lower answer quality.
Figures




read the original abstract
Retrieval-Augmented Generation (RAG) grounds LLM responses in external evidence but treats the model as a passive consumer of search results: it never sees how the corpus is organized or what it has not yet retrieved, limiting its ability to backtrack or combine scattered evidence. We present Corpus2Skill, which distills a document corpus into a hierarchical skill directory offline and lets an LLM agent navigate it at serve time. The compilation pipeline iteratively clusters documents, generates LLM-written summaries at each level, and materializes the result as a tree of navigable skill files. At serve time, the agent receives a bird's-eye view of the corpus, drills into topic branches via progressively finer summaries, and retrieves full documents by ID. Because the hierarchy is explicitly visible, the agent can reason about where to look, backtrack from unproductive paths, and combine evidence across branches. On WixQA, an enterprise customer-support benchmark for RAG, Corpus2Skill outperforms dense retrieval, RAPTOR, and agentic RAG baselines across all quality metrics. We further evaluate generalization on nine RAGBench subsets reformulated as retrieval-stress benchmarks: Corpus2Skill attains the highest macro-average F1 across the full 10-dataset suite and characterizes a clear regime -- single-domain, atomic-document corpora -- where corpus navigation is the right primitive, while flat retrieval remains preferable for open-domain or extractive pools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Corpus2Skill, a pipeline that distills a document corpus offline into a hierarchical tree of navigable 'skill' nodes via iterative clustering and LLM-generated summaries at each level. At serve time an LLM agent receives a bird's-eye overview of the tree, reasons over progressively finer summaries to drill down or backtrack, and retrieves full documents by ID only when a leaf is reached. The central empirical claim is that this explicit navigation structure outperforms dense retrieval, RAPTOR, and agentic RAG baselines on the WixQA enterprise QA benchmark and attains the highest macro-average F1 across nine RAGBench subsets, with the advantage most pronounced on single-domain atomic-document corpora.
Significance. If the reported gains are reproducible, the work usefully distinguishes retrieval from navigation primitives and shows that making corpus organization explicitly visible to the agent can improve evidence combination and error recovery in RAG, particularly for focused enterprise collections. The characterization of a 'regime' where navigation is preferable supplies a concrete, testable hypothesis for future system design.
major comments (3)
- [§3] §3 (Corpus2Skill compilation pipeline): the clustering procedure, embedding model, similarity metric, and stopping criteria for hierarchy construction are not specified. Because the agent's drill-down decisions rest entirely on the fidelity of the resulting node summaries, this omission prevents assessment of whether the hierarchy is faithful or merely an artifact of a particular clustering choice.
- [§4.1] §4.1 and §4.2 (experimental setup): no description is given of the LLM prompts used for summarization, the exact agent policy for choosing branches versus retrieving, or any ablation that isolates the contribution of the hierarchy versus the base LLM. These details are load-bearing for the claim that navigation itself, rather than prompt engineering or model scale, drives the observed gains over RAPTOR and agentic baselines.
- [Table 1] Table 1 / results on WixQA and RAGBench: the reported F1, precision, and recall improvements are presented without statistical significance tests, confidence intervals, or per-query error analysis. In the absence of these, it is impossible to determine whether the consistent outperformance is robust or could be explained by variance or dataset-specific artifacts.
minor comments (2)
- [Abstract] The term 'atomic-document corpora' is used to characterize the favorable regime but is never formally defined; a short operational definition or example would help readers apply the finding.
- [Figure 1] Figure 1 (system overview) would benefit from an explicit legend showing how node summaries are generated and how the agent state is updated during navigation.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments identify important areas for improving clarity, reproducibility, and statistical rigor in the manuscript. We address each point below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Corpus2Skill compilation pipeline): the clustering procedure, embedding model, similarity metric, and stopping criteria for hierarchy construction are not specified. Because the agent's drill-down decisions rest entirely on the fidelity of the resulting node summaries, this omission prevents assessment of whether the hierarchy is faithful or merely an artifact of a particular clustering choice.
Authors: We agree that these details are critical for evaluating the pipeline and ensuring reproducibility. The original submission omitted them due to space constraints, but we will expand §3 in the revised manuscript to fully describe the clustering procedure, the embedding model, similarity metric, and stopping criteria used to build the hierarchy. This will enable assessment of the node summaries' fidelity. revision: yes
-
Referee: [§4.1] §4.1 and §4.2 (experimental setup): no description is given of the LLM prompts used for summarization, the exact agent policy for choosing branches versus retrieving, or any ablation that isolates the contribution of the hierarchy versus the base LLM. These details are load-bearing for the claim that navigation itself, rather than prompt engineering or model scale, drives the observed gains over RAPTOR and agentic baselines.
Authors: We acknowledge this gap in the experimental description. In the revision, we will provide the full LLM prompts for both summarization and agent decision-making in an appendix. We will also detail the agent's policy for navigation decisions. To isolate the hierarchy's contribution, we will include additional ablation studies comparing the full Corpus2Skill system to variants without the hierarchical navigation, using the same base LLM and prompts. revision: yes
-
Referee: [Table 1] Table 1 / results on WixQA and RAGBench: the reported F1, precision, and recall improvements are presented without statistical significance tests, confidence intervals, or per-query error analysis. In the absence of these, it is impossible to determine whether the consistent outperformance is robust or could be explained by variance or dataset-specific artifacts.
Authors: We agree that the results section would benefit from greater statistical analysis. We will revise the paper to include statistical significance tests (such as paired t-tests or bootstrap resampling) with confidence intervals for the reported metrics. Additionally, we will add a per-query error analysis to examine the robustness of the improvements and identify any dataset-specific patterns. revision: yes
Circularity Check
No significant circularity; empirical pipeline evaluated on external benchmarks
full rationale
The paper presents Corpus2Skill as an offline clustering + LLM summarization pipeline that builds an explicit hierarchical skill tree, which an agent then navigates at serve time. Performance is reported as empirical results on WixQA and nine RAGBench subsets against external baselines (dense retrieval, RAPTOR, agentic RAG). No equations, fitted parameters, self-definitional reductions, or load-bearing self-citations appear in the provided text. The central claim reduces to an observable advantage on single-domain atomic-document corpora rather than any derivation that collapses to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-generated summaries at each cluster level faithfully represent the underlying documents and their relationships
Forward citations
Cited by 1 Pith paper
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
InProceedings of the 1st Workshop on NLP for COVID-19 at ACL 2020, 2020. Nandy, A., Sharma, S., Maddhashiya, S., Sachdeva, K., Goyal, P., and Ganguly, N. Question answering over elec- tronic devices: A new benchmark dataset and a multi-task learning based QA framework. InFindings of the Associ- ation for Computational Linguistics: EMNLP 2021, pp. 4600–460...
work page internal anchor Pith review arXiv 2020
-
[4]
Name actual features, products, or processes
Key TERMS or features mentioned across documents Be specific and concrete. Name actual features, products, or processes. Documents ({N} total, showing up to 15): --- Document 1 --- {doc_text[:600]} 15 Don’t Retrieve, Navigate: Distilling Enterprise Knowledge into Navigable Agent Skills --- Document 2 --- {doc_text[:600]} [...] Summary: Cluster-level summa...
-
[7]
What types of user QUESTIONS this group can answer Be specific -- name the main product areas, features, or workflows. Sub-group summaries: - Sub-group 1: {summary[:300]} - Sub-group 2: {summary[:300]} [...] Overview: Labeling prompt.Used to generate a filesystem-safe di- rectory name from a cluster summary. The response is post-processed: lowercased, non...
-
[8]
The common TOPIC area these documents cover
-
[9]
The types of QUESTIONS these documents answer
-
[10]
Name actual features, products, or processes
Key TERMS or features mentioned across documents Be specific and concrete. Name actual features, products, or processes. Documents ({N} total, showing up to 15): --- Document 1 --- {doc_text[:600]} --- Document 2 --- {doc_text[:600]} [...] Summary: Cluster-level summarization.Used at higher levels to summarize a group of sub-cluster summaries into a broad...
-
[11]
The broad DOMAIN these sub-groups cover
-
[12]
The range of TOPICS within this domain
-
[13]
Sub-group summaries: - Sub-group 1: {summary[:300]} - Sub-group 2: {summary[:300]} [...] Overview: Labeling.Used to generate a filesystem-safe directory name from a cluster summary
What types of user QUESTIONS this group can answer Be specific -- name the main product areas, features, or workflows. Sub-group summaries: - Sub-group 1: {summary[:300]} - Sub-group 2: {summary[:300]} [...] Overview: Labeling.Used to generate a filesystem-safe directory name from a cluster summary. The response is post- processed: lowercased, non-alphanu...
-
[14]
Read the SKILL.md of the 1-2 most relevant skills for your query
-
[15]
Drill into the most relevant sub-group: Read its INDEX.md
-
[16]
Pick the most relevant document IDs
At the leaf level, INDEX.md lists document IDs with brief titles. Pick the most relevant document IDs
-
[17]
Call get_document with each relevant doc_id to retrieve the full text
-
[18]
contact support
Read at least one full document before answering. ## Tools - Code execution: Use ‘ls‘ and ‘cat‘ to navigate the skills hierarchy. - get_document(doc_id): Retrieve the full text of a document by its ID. The doc_id values are listed in leaf-level INDEX.md files. ## Answer Format - First sentence = direct answer. No preamble. - Factual questions: 1-3 sentenc...
-
[19]
Go to Settings in your dashboard
-
[20]
Click Language & Region
-
[21]
Scroll to Currency and select your desired currency
-
[22]
LLM only
Click Save. This applies to all Wix products including Online Programs. Your currency must match your payment provider’s currency." Navigation paths: 6221 -> 1513 -> 107 -> 18 -> 1 (programs) 6221 -> 1513 -> 68 -> 18 -> 1 (billing) This trace demonstrates cross-branch navigation: the agent first explored the online-programs subgroup to understand the rela...
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.