Recognition: unknown
Polarization by Default: Auditing Recommendation Bias in LLM-Based Content Curation
Pith reviewed 2026-05-10 07:18 UTC · model grok-4.3
The pith
LLM-based content curators amplify polarization across all providers and prompt strategies
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
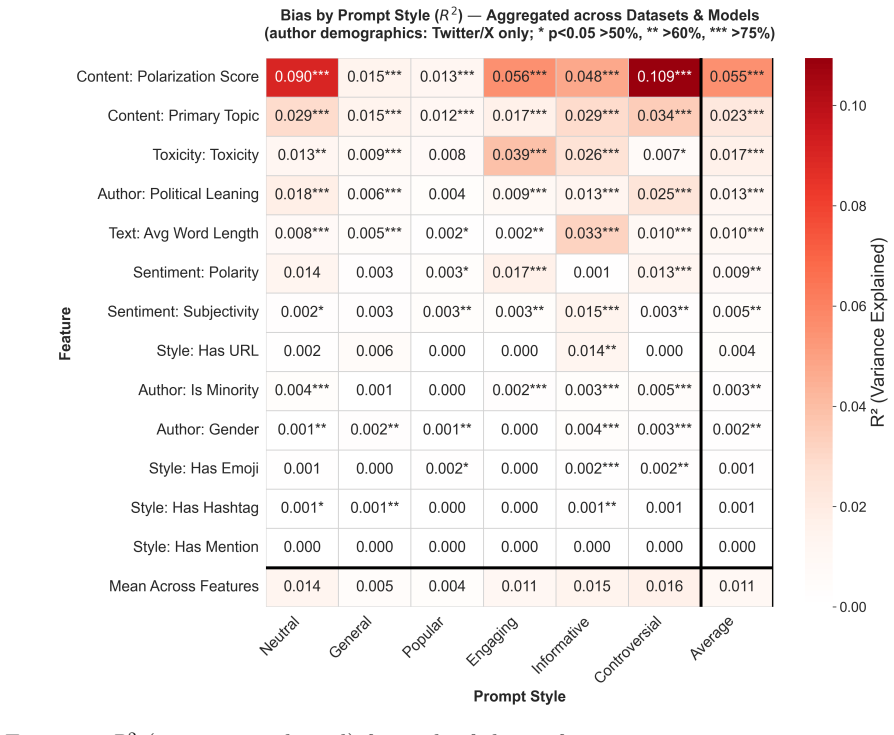
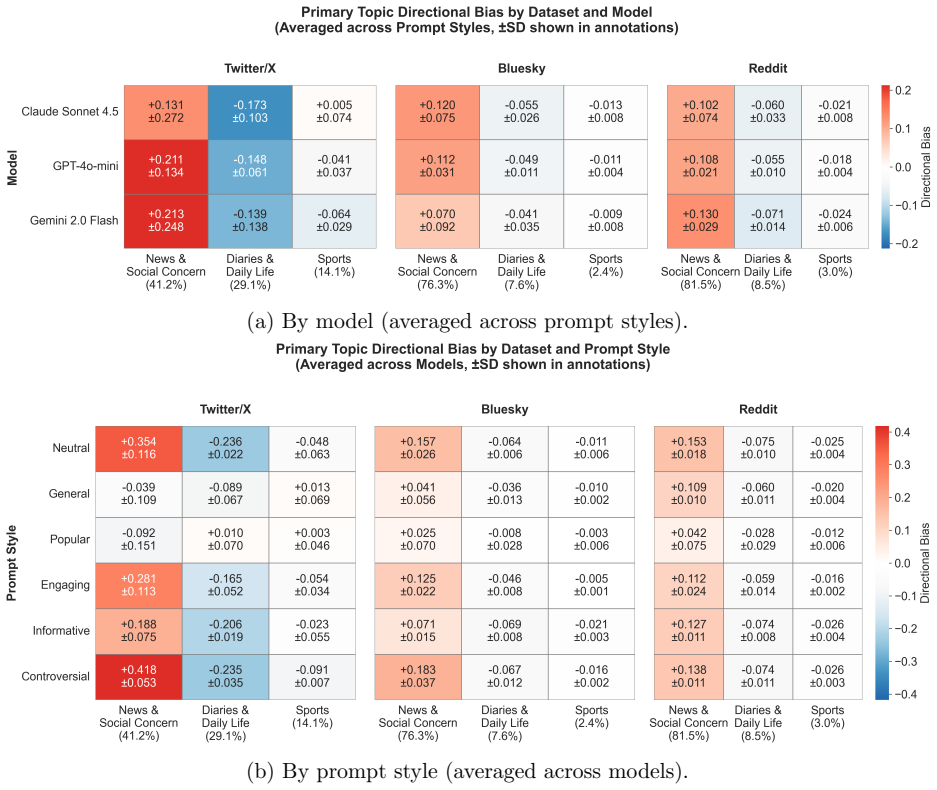
Through 540,000 simulated top-10 selections from pools of 100 posts across 54 conditions on Twitter/X, Bluesky, and Reddit data, polarization is amplified across all configurations, toxicity handling shows a strong inversion between engagement- and information-focused prompts, and sentiment biases are predominantly negative. GPT-4o Mini shows the most consistent behavior across prompts; Claude and Gemini exhibit high adaptivity in toxicity handling; Gemini shows the strongest negative sentiment preference. On Twitter/X, left-leaning authors are systematically over-represented despite right-leaning authors forming the pool plurality, and this pattern largely persists across prompts.
What carries the argument
Controlled simulation of top-10 selections from fixed pools of 100 posts using six prompting strategies (general, popular, engaging, informative, controversial, neutral) across three LLM providers, which isolates structural biases from prompt effects.
If this is right
- Polarization increases in LLM-curated feeds even when prompts are designed to be neutral or informative.
- Toxicity selection can be inverted by shifting from engagement to information prompts, but polarization remains elevated.
- Sentiment bias stays negative across most prompt and provider combinations.
- Political leaning bias favors left-leaning authors on Twitter/X data regardless of prompt wording.
- Different providers trade off consistency against adaptivity, so platform choice affects which biases dominate.
Where Pith is reading between the lines
- Real deployed systems may produce even stronger polarization once user history and engagement loops are added to the selection process.
- Auditing standards for LLM recommenders could focus on measuring polarization deltas rather than absolute toxicity scores.
- Prompt engineering alone is unlikely to eliminate demographic skews such as the over-representation of left-leaning authors.
- Testing the same simulation on newer model releases would reveal whether the observed provider trade-offs persist or shift.
Load-bearing premise
The simulation of selections from fixed post pools with static prompts accurately reflects the biases that appear when LLMs curate content in live, dynamic user contexts on real platforms.
What would settle it
Running the same top-10 selection task on a live platform feed and measuring whether polarization metrics rise by the same amount as in the fixed-pool simulations.
Figures








read the original abstract
Large Language Models (LLMs) are increasingly deployed to curate and rank human-created content, yet the nature and structure of their biases in these tasks remains poorly understood: which biases are robust across providers and platforms, and which can be mitigated through prompt design. We present a controlled simulation study mapping content selection biases across three major LLM providers (OpenAI, Anthropic, Google) on real social media datasets from Twitter/X, Bluesky, and Reddit, using six prompting strategies (\textit{general}, \textit{popular}, \textit{engaging}, \textit{informative}, \textit{controversial}, \textit{neutral}). Through 540,000 simulated top-10 selections from pools of 100 posts across 54 experimental conditions, we find that biases differ substantially in how structural and how prompt-sensitive they are. Polarization is amplified across all configurations, toxicity handling shows a strong inversion between engagement- and information-focused prompts, and sentiment biases are predominantly negative. Provider comparisons reveal distinct trade-offs: GPT-4o Mini shows the most consistent behavior across prompts; Claude and Gemini exhibit high adaptivity in toxicity handling; Gemini shows the strongest negative sentiment preference. On Twitter/X, where author demographics can be inferred from profile bios, political leaning bias is the clearest demographic signal: left-leaning authors are systematically over-represented despite right-leaning authors forming the pool plurality in the dataset, and this pattern largely persists across prompts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a controlled simulation study of biases in LLM-based content curation across three providers (OpenAI, Anthropic, Google) and six prompting strategies (general, popular, engaging, informative, controversial, neutral). Using 540,000 top-10 selections from fixed 100-post pools drawn from Twitter/X, Bluesky, and Reddit datasets, it reports that polarization is amplified in all configurations, toxicity handling inverts between engagement- and information-focused prompts, sentiment biases are predominantly negative, GPT-4o Mini is most consistent while Claude and Gemini show high adaptivity, Gemini has the strongest negative sentiment preference, and left-leaning authors are over-represented on Twitter/X despite pool plurality of right-leaning authors.
Significance. If the directional patterns hold beyond the simulation, the work would be significant for social information systems research by providing a comparative audit of biases in LLM recommenders and identifying prompt-sensitive versus structural effects. The scale of the experiment and cross-provider analysis offer a useful empirical baseline for future auditing and mitigation efforts in AI-driven content platforms.
major comments (1)
- [Methods / Experimental Setup] The central claims about polarization amplification, toxicity inversion, and sentiment biases rest on top-10 selections from static pools of 100 posts using six fixed, hand-crafted prompts without user history, engagement signals, or large-scale dynamic retrieval. This controlled setup is load-bearing for generalizing the findings to deployed LLM curation systems, which typically operate over millions of items with personalization and platform-specific fine-tuning; the observed effects could be artifacts of pool size and lack of context rather than robust LLM properties.
minor comments (1)
- [Abstract / Results] The abstract and results sections would benefit from explicit reporting of the statistical tests or confidence intervals used to establish the directional findings (e.g., over-representation of left-leaning authors) rather than relying solely on descriptive patterns.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for acknowledging the potential significance of our comparative audit of LLM curation biases. We address the major comment on the experimental setup below, clarifying our design rationale while acknowledging its limitations for generalization.
read point-by-point responses
-
Referee: The central claims about polarization amplification, toxicity inversion, and sentiment biases rest on top-10 selections from static pools of 100 posts using six fixed, hand-crafted prompts without user history, engagement signals, or large-scale dynamic retrieval. This controlled setup is load-bearing for generalizing the findings to deployed LLM curation systems, which typically operate over millions of items with personalization and platform-specific fine-tuning; the observed effects could be artifacts of pool size and lack of context rather than robust LLM properties.
Authors: We agree that the controlled simulation uses static pools of 100 posts and fixed prompts without user history or dynamic retrieval, and that this design limits direct generalization to production systems with millions of items and personalization. The setup was chosen deliberately to isolate LLM and prompt effects by holding the input pool constant across 54 conditions and 540,000 selections, enabling attribution of polarization amplification, toxicity inversion, and sentiment biases to the models themselves rather than retrieval confounders. The consistent polarization increase across all providers, prompts, and datasets suggests a structural pattern rather than a pool-size artifact. We do not claim equivalence to deployed systems. In revision we will expand the Limitations section to explicitly discuss these constraints, note that real-world interactions with personalization remain untested, and outline future work on dynamic and personalized setups. This partially addresses the concern while preserving the value of the current baseline audit. revision: partial
Circularity Check
Empirical simulation with no circular derivations or self-referential reductions
full rationale
The paper performs a controlled empirical audit by generating 540,000 top-10 selections from static 100-post pools using six fixed prompting strategies across three LLM providers. All reported patterns (polarization amplification, toxicity inversion, negative sentiment bias, provider differences) are direct observational outputs from these simulations rather than outputs of any mathematical derivation, fitted parameter, or equation that reduces to the input data by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the methodology is self-contained and externally falsifiable via replication of the described simulation protocol. This matches the default case of an honest non-finding for an observational study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The six prompting strategies (general, popular, engaging, informative, controversial, neutral) represent distinct and meaningful real-world use cases for content curation.
- domain assumption Top-10 selections from fixed pools of 100 posts simulate the core selection mechanism of LLM-based recommendation systems.
Reference graph
Works this paper leans on
-
[1]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[2]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[3]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.