Recognition: unknown
ReFineVLA: Multimodal Reasoning-Aware Generalist Robotic Policies via Teacher-Guided Fine-Tuning
Pith reviewed 2026-05-10 05:02 UTC · model grok-4.3
The pith
ReFineVLA fine-tunes vision-language-action models on teacher-generated reasoning rationales to improve robotic task performance and multimodal alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
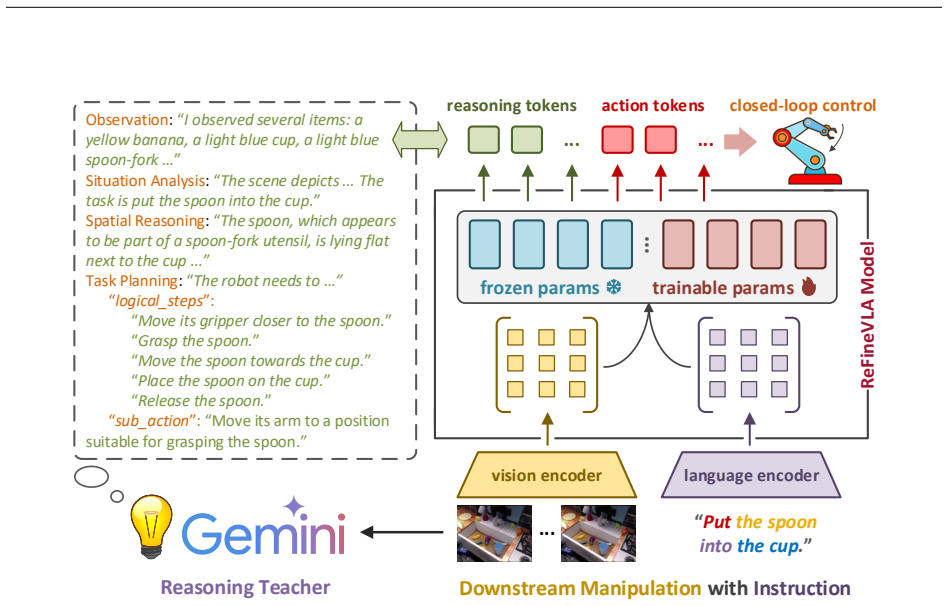
ReFineVLA augments robotic datasets with reasoning rationales from an expert teacher model to guide VLA models in learning to reason about their actions, then fine-tunes pre-trained VLAs on these reasoning-enriched datasets to enhance reasoning while preserving generalization, as evidenced by attention map alignment between visual observations, linguistic prompts, and actions.
What carries the argument
Teacher-guided augmentation and fine-tuning of VLAs with reasoning rationales
Where Pith is reading between the lines
- Such teacher-guided reasoning could be applied to other multimodal models beyond robotics to improve interpretability.
- Future work might test if the same method transfers to real robot hardware where environmental uncertainty is higher.
- The explicit rationales might enable better human oversight or debugging of robot behaviors.
Load-bearing premise
The external teacher model produces accurate reasoning rationales that, when used for fine-tuning, enhance action quality without reducing the base VLA model's ability to generalize to new tasks.
What would settle it
A controlled experiment showing that fine-tuning on the reasoning-augmented dataset results in equal or lower success rates on the benchmarks or poorer performance on held-out tasks would falsify the benefit of the reasoning step.
Figures








read the original abstract
Vision-Language-Action (VLA) models have gained much attention from the research community thanks to their strength in translating multimodal observations with linguistic instructions into desired robotic actions. Despite their advancements, VLAs often overlook explicit reasoning and learn the functional input-action mappings, omitting crucial logical steps, which are especially pronounced in interpretability and generalization for complex, long-horizon manipulation tasks. In this work, we propose ReFineVLA, a multimodal reasoning-aware framework that fine-tunes VLAs with teacher-guided reasons. We first augment robotic datasets with reasoning rationales generated by an expert teacher model, guiding VLA models to learn to reason about their actions. Then, we fine-tune pre-trained VLAs with the reasoning-enriched datasets with ReFineVLA, while maintaining the underlying generalization abilities and boosting reasoning capabilities. We also conduct attention map visualization to analyze the alignment among visual observation, linguistic prompts, and to-be-executed actions of ReFineVLA, reflecting the model is ability to focus on relevant tasks and actions. Through this additional step, we explore that ReFineVLA-trained models exhibit a meaningful agreement between vision-language and action domains, highlighting the enhanced multimodal understanding and generalization. Evaluated across a suite of simulated manipulation benchmarks on SimplerEnv with both WidowX and Google Robot tasks, ReFineVLA achieves state-of-the-art performance, in success rate over the second-best method on the both the WidowX benchmark and Google Robot Tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ReFineVLA, a multimodal reasoning-aware framework that augments robotic datasets with reasoning rationales generated by an external expert teacher model and then fine-tunes pre-trained Vision-Language-Action (VLA) models on the enriched data. The goal is to improve explicit reasoning for complex, long-horizon manipulation tasks while preserving the base model's generalization. The work includes attention-map visualizations to demonstrate alignment between visual observations, language prompts, and actions, and reports state-of-the-art success rates on SimplerEnv benchmarks using both WidowX and Google Robot tasks.
Significance. If the performance gains can be causally attributed to the teacher-guided reasoning component rather than generic fine-tuning effects, the approach would offer a practical route to more interpretable and capable generalist robotic policies. The attention visualization provides a useful diagnostic for multimodal alignment, and the pipeline is straightforward to implement on existing VLAs. These elements would be of interest to the robotics and multimodal learning communities, particularly for long-horizon tasks where implicit mapping alone is insufficient.
major comments (1)
- [Experiments] Experiments section: The central SOTA claim attributes performance improvements on WidowX and Google Robot tasks to the multimodal reasoning-aware fine-tuning step. However, the manuscript provides no ablation that holds dataset size, fine-tuning procedure, and base VLA fixed while removing or randomizing the content of the teacher-generated rationales. Without this control, observed gains could stem from additional training data volume or optimization rather than the reasoning mechanism itself, weakening the attribution required by the title and abstract.
minor comments (2)
- [Abstract] Abstract: The claim of 'state-of-the-art performance, in success rate over the second-best method' is stated without any numerical values, baseline names, or trial counts, making the headline result impossible to assess from the abstract alone.
- [Method] Method description: The precise format in which the generated rationales are concatenated or tokenized into the VLA input (e.g., as additional text tokens or separate modality) is not specified, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and describe the revisions we will make to strengthen the attribution of our results.
read point-by-point responses
-
Referee: The central SOTA claim attributes performance improvements on WidowX and Google Robot tasks to the multimodal reasoning-aware fine-tuning step. However, the manuscript provides no ablation that holds dataset size, fine-tuning procedure, and base VLA fixed while removing or randomizing the content of the teacher-generated rationales. Without this control, observed gains could stem from additional training data volume or optimization rather than the reasoning mechanism itself, weakening the attribution required by the title and abstract.
Authors: We agree that a controlled ablation isolating the effect of the reasoning content is necessary to strengthen the causal attribution of performance gains to the teacher-guided reasoning mechanism. While the current manuscript reports comparisons against multiple baselines (including other fine-tuned VLAs) on the SimplerEnv WidowX and Google Robot benchmarks, it does not include an ablation that keeps dataset size, fine-tuning procedure, and base model identical while replacing the teacher-generated rationales with random or null content. In the revised manuscript, we will add this ablation: we will fine-tune the base VLA on the same augmented dataset volume but with randomized rationales (e.g., shuffled sentences or empty strings) and report the resulting success rates alongside the original ReFineVLA results. This will clarify whether the structured reasoning provides benefits beyond additional training data or optimization. revision: yes
Circularity Check
No significant circularity in empirical fine-tuning pipeline
full rationale
The paper presents an empirical fine-tuning framework that augments datasets with external teacher-generated rationales and evaluates resulting VLA policies on WidowX and Google Robot benchmarks. No equations, derivations, or analytical reductions appear in the abstract or described method; performance claims rest on reported success rates rather than any quantity defined in terms of itself. No self-citation chains, fitted inputs renamed as predictions, or ansatzes smuggled via prior work are present. The evaluation is externally benchmarked and does not reduce to internal definitions by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An external teacher model can produce useful and accurate reasoning rationales for robotic actions
invented entities (1)
-
ReFineVLA framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone.arXiv preprint arXiv:2404.14219,
work page internal anchor Pith review arXiv
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164,
work page internal anchor Pith review arXiv
-
[3]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817,
work page internal anchor Pith review arXiv
-
[4]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control.arXiv preprint arXiv:2307.15818,
work page internal anchor Pith review arXiv
-
[5]
Contrastive chain-of-thought prompting
Lawrence Yunliang Chen, Simeon Adebola, and Ken Goldberg. Berkeley UR5 demonstration dataset. https://sites.google.com/view/berkeley-ur5/home. Yew Ken Chia, Guizhen Chen, Luu Anh Tuan, Soujanya Poria, and Lidong Bing. Contrastive chain-of-thought prompting.arXiv preprint arXiv:2311.09277,
-
[6]
Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs,
Hao-Tien Lewis Chiang, Zhuo Xu, Zipeng Fu, Mithun George Jacob, Tingnan Zhang, Tsang-Wei Edward Lee, Wenhao Yu, Connor Schenck, David Rendleman, Dhruv Shah, et al. Mobility vla: Multimodal instruction navigation with long-context vlms and topological graphs.arXiv preprint arXiv:2407.07775,
-
[8]
What matters in employing vision language models for tokenizing actions in robot control? InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024,
14 Nicolai Dorka, Chenguang Huang, Tim Welschehold, and Wolfram Burgard. What matters in employing vision language models for tokenizing actions in robot control? InFirst Workshop on Vision-Language Models for Navigation and Manipulation at ICRA 2024,
2024
-
[9]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378,
work page internal anchor Pith review arXiv
-
[10]
Vision-language models as success detectors.arXiv preprint arXiv:2303.07280, 2023
Yuqing Du, Ksenia Konyushkova, Misha Denil, Akhil Raju, Jessica Landon, Felix Hill, Nando de Freitas, and Serkan Cabi. Vision-language models as success detectors.arXiv preprint arXiv:2303.07280,
-
[11]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Frederik Ebert, Yanlai Yang, Karl Schmeckpeper, Bernadette Bucher, Georgios Georgakis, Kostas Daniilidis, Chelsea Finn, and Sergey Levine. Bridge data: Boosting generalization of robotic skills with cross-domain datasets.arXiv preprint arXiv:2109.13396,
work page internal anchor Pith review arXiv
-
[12]
Samir Yitzhak Gadre, Mitchell Wortsman, Gabriel Ilharco, Ludwig Schmidt, and Shuran Song. Clip on wheels: Zero-shot object navigation as object localization and exploration.arXiv preprint arXiv:2203.10421, 3(4):7,
-
[13]
Polytask: Learning unified policies through behavior distillation.arXiv preprint arXiv:2310.08573,
Siddhant Haldar and Lerrel Pinto. Polytask: Learning unified policies through behavior distillation.arXiv preprint arXiv:2310.08573,
-
[14]
Baku: An efficient transformer for multi-task policy learning.arXiv preprint arXiv:2406.07539, 2024
Siddhant Haldar, Zhuoran Peng, and Lerrel Pinto. Baku: An efficient transformer for multi-task policy learning.arXiv preprint arXiv:2406.07539,
-
[15]
Visual chain-of-thought diffusion models.arXiv preprint arXiv:2303.16187,
William Harvey and Frank Wood. Visual chain-of-thought diffusion models.arXiv preprint arXiv:2303.16187,
-
[16]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models, 2024
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Ostendorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.arXiv preprint arXiv:2406.09403,
-
[17]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang
URLhttps: //arxiv.org/abs/2410.22325. Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. Your large vision-language model only needs a few attention heads for visual grounding.arXiv preprint arXiv:2503.06287,
-
[18]
arXiv preprint arXiv:2302.12766 , year=
Siddharth Karamcheti, Suraj Nair, Annie S Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics.arXiv preprint arXiv:2302.12766,
-
[19]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
work page internal anchor Pith review arXiv
-
[20]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
work page internal anchor Pith review arXiv
-
[21]
15 Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024a. Xinghang Li, Peiyan Li, Minghuan Liu, Dong Wang, Jirong Liu, Bingyi Kang, Xiao ...
-
[22]
RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36, 2024a. Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024b. Gu...
work page internal anchor Pith review arXiv
-
[23]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. InThe 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (IJCNLP-AACL 2023),
2023
-
[25]
Nghia Nguyen, Minh Nhat Vu, Tung D Ta, Baoru Huang, Thieu Vo, Ngan Le, and Anh Nguyen. Robotic-clip: Fine-tuning clip on action data for robotic applications.arXiv preprint arXiv:2409.17727,
-
[26]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Abby O’Neill, Abdul Rehman, Abhinav Gupta, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864,
work page internal anchor Pith review arXiv
-
[27]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
16 Emilio Parisotto, Jimmy Lei Ba, and Ruslan Salakhutdinov. Actor-mimic: Deep multitask and transfer reinforcement learning.arXiv preprint arXiv:1511.06342,
-
[29]
Visual chain of thought: bridging logical gaps with multimodal infillings
ISSN 2835-8856. URL https://openreview.net/forum?id=1ikK0kHjvj. Featured Certification, Outstanding Certification. Daniel Rose, Vaishnavi Himakunthala, Andy Ouyang, Ryan He, Alex Mei, Yujie Lu, Michael Saxon, Chinmay Sonar, Diba Mirza, and William Yang Wang. Visual chain of thought: bridging logical gaps with multimodal infillings.arXiv preprint arXiv:2305.02317,
-
[30]
Andrei A Rusu, Sergio Gomez Colmenarejo, Caglar Gulcehre, Guillaume Desjardins, James Kirkpatrick, Razvan Pascanu, Volodymyr Mnih, Koray Kavukcuoglu, and Raia Hadsell. Policy distillation.arXiv preprint arXiv:1511.06295,
-
[31]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Unleashing chain-of-thought reasoning in multi-modal language models.arXiv preprint arXiv:2403.16999,
-
[32]
arXiv preprint arXiv:2412.03555 (2024) 1
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555,
-
[33]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
work page internal anchor Pith review arXiv
-
[35]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786,
work page internal anchor Pith review arXiv
-
[37]
Scaling image tokenizers with grouped spherical quantization.arXiv preprint arXiv:2412.02632,
17 Jiangtao Wang, Zhen Qin, Yifan Zhang, Vincent Tao Hu, Björn Ommer, Rania Briq, and Stefan Kesselheim. Scaling image tokenizers with grouped spherical quantization.arXiv preprint arXiv:2412.02632,
-
[38]
Finetuned Language Models Are Zero-Shot Learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners.arXiv preprint arXiv:2109.01652,
work page internal anchor Pith review arXiv
-
[39]
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning.arXiv preprint arXiv:2401.00025,
-
[40]
Tinyvla: To- wards fast, data-efficient vision-language-action models for robotic manipulation, 2024
Junjie Wen, Yichen Zhu, Jinming Li, Minjie Zhu, Kun Wu, Zhiyuan Xu, Ran Cheng, Chaomin Shen, Yaxin Peng, Feifei Feng, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation.arXiv preprint arXiv:2409.12514,
-
[41]
Vila-u: a unified foundation model integrating visual understanding and generation
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, et al. Vila-u: a unified foundation model integrating visual understanding and generation.arXiv preprint arXiv:2409.04429,
-
[42]
Tian-Yu Xiang, Ao-Qun Jin, Xiao-Hu Zhou, Mei-Jiang Gui, Xiao-Liang Xie, Shi-Qi Liu, Shuang-Yi Wang, Sheng-Bin Duang, Si-Cheng Wang, Zheng Lei, et al. Vla model-expert collaboration for bi-directional manipulation learning.arXiv preprint arXiv:2503.04163,
-
[43]
Beyond Chain-of-Thought, Effec- tive Graph-of-Thought Reasoning in Language Models,
Yao Yao, Zuchao Li, and Hai Zhao. Beyond chain-of-thought, effective graph-of-thought reasoning in language models.arXiv preprint arXiv:2305.16582,
-
[44]
Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693,
-
[45]
arXiv preprint arXiv:2411.03540 , year=
Haochen Zhang, Nader Zantout, Pujith Kachana, Zongyuan Wu, Ji Zhang, and Wenshan Wang. Vla-3d: A dataset for 3d semantic scene understanding and navigation.arXiv preprint arXiv:2411.03540,
-
[46]
Jianke Zhang, Yanjiang Guo, Yucheng Hu, Xiaoyu Chen, Xiang Zhu, and Jianyu Chen. Up-vla: A unified understanding and prediction model for embodied agent.arXiv preprint arXiv:2501.18867,
-
[47]
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, et al. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models.arXiv preprint arXiv:2503.22020,
-
[48]
3D-VLA: A 3D Vision-Language-Action Generative World Model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model.arXiv preprint arXiv:2403.09631, 2024a. Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world mod...
work page internal anchor Pith review arXiv
-
[49]
Chatvla: Unified multimodal understanding and robot control with vision-language-action model, 2025
Zhongyi Zhou, Yichen Zhu, Minjie Zhu, Junjie Wen, Ning Liu, Zhiyuan Xu, Weibin Meng, Ran Cheng, Yaxin Peng, Chaomin Shen, et al. Chatvla: Unified multimodal understanding and robot control with vision-language-action model.arXiv preprint arXiv:2502.14420,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.