Recognition: unknown
Enabling AI ASICs for Zero Knowledge Proof
Pith reviewed 2026-05-10 04:20 UTC · model grok-4.3
The pith
MORPH reformulates ZKP operations into matrix multiplications that run on TPUs with up to 10x higher NTT throughput than prior systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MORPH is the first framework to adapt zero-knowledge proof kernels for AI ASICs by introducing a Big-T complexity model that accounts for layout costs ignored in standard Big-O analysis; it then applies an MXU-centric extended-RNS lazy reduction to turn high-precision modular arithmetic into dense low-precision GEMMs without carry chains, together with a unified-sharding layout-stationary Pippenger MSM and an optimized 3/5-step NTT that eliminate on-device shuffles.
What carries the argument
Big-T complexity model that exposes heterogeneous bottlenecks and layout-transformation costs, combined with MXU-centric extended-RNS lazy reduction and unified-sharding layout-stationary dataflow for MSM and NTT.
If this is right
- ZKP provers can exploit the massive matrix throughput and energy efficiency already present in existing AI ASICs.
- Modular arithmetic can be replaced by low-precision GEMM sequences that remove all carry propagation.
- Data layouts for MSM and NTT can be chosen to avoid costly memory reorganizations inside the accelerator.
- Comparable MSM throughput and substantially higher NTT throughput become available on general AI hardware rather than requiring dedicated ZKP chips.
Where Pith is reading between the lines
- The same reformulation strategy could be tested on other matrix-oriented accelerators such as GPUs or emerging AI inference chips.
- If the approach generalizes, it may reduce the hardware barrier for deploying ZK proofs in large-scale privacy-preserving systems.
- Future work could measure end-to-end prover latency on full ZK circuits rather than isolated kernels to confirm practical gains.
- The Big-T model itself might be applied to other cryptographic primitives that are currently analyzed only with asymptotic complexity.
Load-bearing premise
The arithmetic and dataflow reformulations preserve exact mathematical correctness and security guarantees of the original ZKP while incurring no hidden overheads on the target TPU hardware.
What would settle it
Running the published JAX implementation of MORPH on TPUv6e8 and measuring actual proof generation time and proof validity against the GZKP baseline; any gap larger than the reported 10x NTT gain or any incorrect proof output would falsify the claim.
Figures






read the original abstract
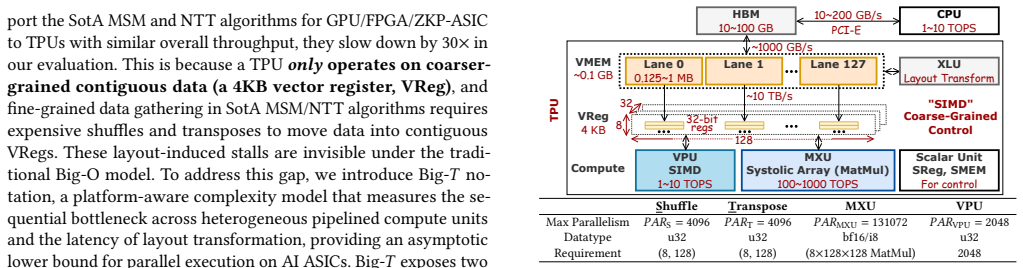
Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime as they need significant computation. AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency. We present MORPH, the first framework that reformulates ZKP kernels to match AI-ASIC execution. We introduce Big-T complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-O. Guided by this analysis, (1) at arithmetic level, MORPH develops an MXU-centric extended-RNS lazy reduction that converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains, and (2) at dataflow level, MORPH constructs a unified-sharding layout-stationary TPU Pippenger MSM and optimized 3/5-step NTT that avoid on-TPU shuffles to minimize costly memory reorganization. Implemented in JAX, MORPH enables TPUv6e8 to achieve up-to 10x higher throughput on NTT and comparable throughput on MSM than GZKP. Our code: https://github.com/EfficientPPML/MORPH.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents MORPH, the first framework to reformulate ZKP kernels (NTT and MSM) for execution on AI ASICs such as TPUs. It introduces a Big-T hardware-aware complexity model, an MXU-centric extended-RNS lazy reduction that maps modular arithmetic to dense low-precision GEMMs, and layout-stationary sharding for a unified Pippenger MSM and optimized 3/5-step NTT. The JAX implementation reports up to 10x higher NTT throughput and comparable MSM throughput on TPUv6e8 versus the GZKP baseline, with public code provided.
Significance. If the performance numbers hold and mathematical equivalence is preserved, the work is significant for the ZKP and hardware-acceleration communities: it demonstrates how AI-ASIC matrix engines can be leveraged for previously intractable kernels, supplies a reusable complexity model that accounts for layout costs ignored by Big-O, and ships reproducible JAX code with direct baseline comparisons. These elements lower the barrier to further ASIC-ZKP co-design.
major comments (2)
- [Results/Evaluation] Results and evaluation sections: the reported 10x NTT and comparable MSM speedups on TPUv6e8 are load-bearing for the central claim, yet the manuscript provides limited detail on exact benchmark conditions (input sizes, batching, number of runs), error bars, or statistical significance; without these, it is difficult to assess whether the gains are robust or sensitive to particular test vectors.
- [Arithmetic reformulation / Implementation] Arithmetic and correctness sections: the claim that the MXU-centric extended-RNS lazy reduction and dataflow preserve exact modular arithmetic and ZKP security guarantees is central, but the manuscript does not include a dedicated verification subsection, formal equivalence argument, or exhaustive test-suite results (beyond the public JAX code) that would allow independent confirmation of no overflow, carry-chain elimination, or security degradation.
minor comments (3)
- [Big-T model] The Big-T complexity model is introduced as a key analysis tool but its notation and derivation steps could be clarified with an explicit example comparing it to standard Big-O on a small NTT instance.
- [Figures/Tables] Figure captions and table headers should explicitly label hardware-specific terms (MXU, extended-RNS, layout-stationary) to aid readers unfamiliar with TPU internals.
- [Abstract] The abstract mentions 'up-to 10x' without specifying the precise NTT size or configuration that achieves the peak; adding this would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. The comments highlight opportunities to strengthen the evaluation and correctness sections, which we will address in the revised manuscript while preserving the core contributions.
read point-by-point responses
-
Referee: [Results/Evaluation] Results and evaluation sections: the reported 10x NTT and comparable MSM speedups on TPUv6e8 are load-bearing for the central claim, yet the manuscript provides limited detail on exact benchmark conditions (input sizes, batching, number of runs), error bars, or statistical significance; without these, it is difficult to assess whether the gains are robust or sensitive to particular test vectors.
Authors: We agree that more granular benchmark details will improve reproducibility and allow readers to better assess robustness. In the revised manuscript, we will expand the evaluation section with a dedicated 'Benchmark Setup' paragraph (or table) that specifies: (i) exact input sizes (NTT lengths from 2^16 to 2^24 and MSM scalar counts up to 2^20), (ii) batching configurations (single and batched workloads), (iii) number of runs (10 independent executions per configuration), and (iv) reported statistics (mean throughput with standard deviation). These details are already implemented in the public JAX repository and can be directly inspected; the revision will simply surface them in the paper text. revision: yes
-
Referee: [Arithmetic reformulation / Implementation] Arithmetic and correctness sections: the claim that the MXU-centric extended-RNS lazy reduction and dataflow preserve exact modular arithmetic and ZKP security guarantees is central, but the manuscript does not include a dedicated verification subsection, formal equivalence argument, or exhaustive test-suite results (beyond the public JAX code) that would allow independent confirmation of no overflow, carry-chain elimination, or security degradation.
Authors: We recognize the value of an explicit verification subsection. While the current manuscript relies on the open-source JAX implementation (which includes unit tests comparing MORPH outputs against reference CPU implementations for bit-exact equivalence on small-to-medium instances and overflow checks via extended RNS bounds), we will add a new 'Correctness and Security Verification' subsection. This will contain: (1) a concise formal argument showing that the chosen extended-RNS parameters and lazy-reduction thresholds eliminate carry chains while preserving exact modular semantics (no overflow under the selected bit widths), and (2) a summary of the test-suite results (including NTT/ MSM sizes tested, observed maximum error, and confirmation that ZKP security parameters remain unchanged). The public code will continue to serve as the exhaustive test harness. revision: yes
Circularity Check
No significant circularity; derivation is self-contained engineering mapping
full rationale
The paper's core contribution is a hardware-specific reformulation of NTT and MSM kernels (MXU-centric extended-RNS lazy reduction plus layout-stationary sharding) guided by the introduced Big-T complexity model, with throughput results compared to the external GZKP baseline. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the Big-T model is an analysis tool rather than a proof substitute, the arithmetic mappings preserve exact modular semantics by explicit construction, and public JAX code enables direct external verification. The performance claims are therefore falsifiable against independent hardware runs and do not collapse to the inputs by definition.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Residue number system (RNS) supports lazy reduction without carry propagation for modular multiplication
- standard math Pippenger's algorithm for multi-scalar multiplication can be sharded in a layout-stationary manner on matrix units
invented entities (2)
-
Big-T complexity model
no independent evidence
-
MXU-centric extended-RNS lazy reduction
no independent evidence
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Benchmark harness for FPGA MSM implementations in the ZPRIZE competition. https://github.com/z-prize/prize-gpu-fpga-msm/tree/main/harness. Accessed: April 1, 2025
2025
-
[2]
[n. d.]. XYZZ coordinates for short Weierstrass curves. https://www.hyperelliptic. org/EFD/g1p/auto-shortw-xyzz.html. Accessed: April 9, 2025
2025
-
[3]
[n. d.]. ZK Rollup Architecture. Online. https://zksync.io/faq/tech.html#zk- rollup-architecture Accessed: April 2025
2025
-
[4]
Amazon Trainium
2025. Amazon Trainium. https://aws.amazon.com/ai/machine-learning/ trainium/. Accessed: [Insert Date Accessed, e.g., April 9, 2025]
2025
-
[5]
Perfetto Trace Viewer
2025. Perfetto Trace Viewer. https://perfetto.dev/. Accessed: [Insert Date Accessed, e.g., April 9, 2025]
2025
-
[6]
yrrid GPU MSM Library
2025. yrrid GPU MSM Library. https://github.com/yrrid/combined-msm-gpu. Accessed: [Insert Date Accessed, e.g., April 9, 2025]
2025
-
[7]
2022.CycloneMSM: FPGA Acceleration of Multi-Scalar Multipli- cation
Kaveh Aasaraai, Don Beaver, Emanuele Cesena, Rahul Maganti, Nicolas Stalder, and Javier Varela. 2022.CycloneMSM: FPGA Acceleration of Multi-Scalar Multipli- cation. Technical Report. IACR. https://eprint.iacr.org/2022/1396.pdf
2022
-
[8]
Jacob Austin, Sholto Douglas, Roy Frostig, Anselm Levskaya, Charlie Chen, Sharad Vikram, Federico Lebron, Peter Choy, Vinay Ramasesh, Albert Webson, and Reiner Pope. 2025. How to Scale Your Model. Online. (2025). Retrieved from https://jax-ml.github.io/scaling-book/
2025
-
[9]
2014.Zerocash: Decentralized Anonymous Payments from Bitcoin
Eli Ben-Sasson, Alessandro Chiesa, Christina Garman, Matthew Green, Ian Miers, Eran Tromer, and Madars Virza. 2014.Zerocash: Decentralized Anonymous Payments from Bitcoin. Technical Report. Zerocash Project. http://zerocash- project.org/media/pdf/zerocash-extended-20140518.pdf
2014
-
[10]
2018.JAX: composable transformations of Python+NumPy programs
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018.JAX: composable transformations of Python+NumPy programs. http://github.com/jax-ml/jax
2018
-
[11]
Jeff Buss et al. 2021. Intel HEXL: High-Performance Homomorphic Encryption Primitives. InProceedings of the Workshop on Encrypted Computing & Applied Homomorphic Cryptography (W AHC)
2021
-
[12]
Wonseok Choi, Jongmin Kim, and Jung Ho Ahn. 2025. Cheddar: A Swift Fully Ho- momorphic Encryption Library Designed for GPU Architectures. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1(USA)(ASPLOS ’26). Association for Computing Machinery. doi:10.1145/3760250.3762223
-
[13]
Alhad Daftardar, Brandon Reagen, and Siddharth Garg. 2024. SZKP: A Scalable Accelerator Architecture for Zero-Knowledge Proofs. InProceedings of the 2024 International Conference on Parallel Architectures and Compilation Techniques (Long Beach, CA, USA)(PACT ’24). Association for Computing Machinery, New York, NY, USA, 271–283. doi:10.1145/3656019.3676898
-
[14]
Wei Dai and Berk Sunar. 2015. cuHE: A Homomorphic Encryption Accelerator Library.IACR Cryptology ePrint Archive2015 (2015), 1043
2015
-
[15]
Dark Forest Team. [n. d.]. Announcing Dark Forest. Blog post. https://blog.zkga. me/announcing-darkforest Accessed: April 2025
2025
-
[16]
Shengyu Fan, Zhiwei Wang, Weizhi Xu, Rui Hou, Dan Meng, and Mingzhe Zhang
-
[17]
arXiv:2212.14191 [cs.AR] https://arxiv.org/abs/2212.14191
TensorFHE: Achieving Practical Computation on Encrypted Data Using GPGPU. arXiv:2212.14191 [cs.AR] https://arxiv.org/abs/2212.14191
-
[18]
Williamson, and Oana Ciobotaru
Ariel Gabizon, Zachary J. Williamson, and Oana Ciobotaru. 2019. Plonk: Permuta- tions over Lagrange-bases for Oecumenical Noninteractive arguments of Knowl- edge.IACR Cryptol. ePrint Arch.2019 (2019), 953. https://eprint.iacr.org/2019/953
2019
-
[19]
Jens Groth. 2016. On the Size of Pairing-based Non-interactive Arguments. In Advances in Cryptology - EUROCRYPT 2016 (Lecture Notes in Computer Science, Vol. 9666). Springer, 305–326. doi:10.1007/978-3-662-49896-5_11
-
[20]
David Jacquemin, Ahmet Can Mert, and Sujoy Sinha Roy. 2022. Exploring RNS for Isogeny-based Cryptography. Cryptology ePrint Archive, Paper 2022/1289
2022
-
[21]
Zhuoran Ji et al . 2024. Accelerating Multi-Scalar Multiplication for Efficient Zero Knowledge Proofs with Multi-GPU Systems. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3(La Jolla, CA, USA)(ASPLOS ’24). Association for Computing Machinery, New York, NY, USA, 57–70...
-
[22]
Norman P. Jouppi et al . 2023. TPU v4: An Optically Reconfigurable Su- percomputer for Machine Learning with Hardware Support for Embeddings. arXiv:2304.01433 [cs.AR] https://arxiv.org/abs/2304.01433
-
[23]
Jongmin Kim, Sangpyo Kim, Jaewan Choi, Jaiyoung Park, Donghwan Kim, and Jung Ho Ahn. 2023. SHARP: A Short-Word Hierarchical Accelerator for Robust and Practical Fully Homomorphic Encryption. InProceedings of the 50th Annual International Symposium on Computer Architecture(Orlando, FL, USA)(ISCA ’23). Association for Computing Machinery. doi:10.1145/357937...
-
[24]
Kim Laine, Rachel Player, and Hao Chen. 2018. Microsoft SEAL: A Homomorphic Encryption Library. InProceedings of the IEEE Symposium on Security and Privacy Workshops (SPW). IEEE, 123–126
2018
-
[25]
Simon Langowski and Srinivas Devadas. 2025. Efficient Modular Multiplication Using Vector Instructions on Commodity Hardware. Cryptology ePrint Archive, Paper 2025/1068. https://eprint.iacr.org/2025/1068
2025
-
[26]
Changxu Liu et al . 2024. Gypsophila: A Scalable and Bandwidth-Optimized Multi-Scalar Multiplication Architecture. InProceedings of the 61st ACM/IEEE Design Automation Conference(San Francisco, CA, USA)(DAC ’24). Association for Computing Machinery, New York, NY, USA. doi:10.1145/3649329.3658259
-
[27]
Changxu Liu, Hao Zhou, Patrick Dai, Li Shang, and Fan Yang. 2023. PriorMSM: An Efficient Acceleration Architecture for Multi-Scalar Multiplication. InProceedings of the ACM/SIGDA International Symposium on Field-Programmable Gate Arrays. doi:10.1145/3678006 https://dl.acm.org/doi/10.1145/3678006
-
[28]
Edward Suh
Tianyu Ma, Zhen Zhang, Yuhao Zhang, and G. Edward Suh. 2023. gZKP: GPU- Accelerated Zero-Knowledge Proof Generation. InProceedings of the IEEE Inter- national Symposium on High-Performance Computer Architecture (HPCA). IEEE
2023
-
[29]
Weiliang Ma, Qian Xiong, Xuanhua Shi, Xiaosong Ma, Hai Jin, Haozhao Kuang, Mingyu Gao, Ye Zhang, Haichen Shen, and Weifang Hu. 2023. GZKP: A GPU Accelerated Zero-Knowledge Proof System. InProceedings of the 28th ACM In- ternational Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2 (ASPLOS 2023). Association for ...
- [30]
-
[31]
Xander Pottier, Thomas de Ruijter, Jonas Bertels, Wouter Legiest, Michiel Van Beirendonck, and Ingrid Verbauwhede. 2025. OPTIMSM: FPGA hardware accelerator for Zero-Knowledge MSM.IACR Transactions on Cryptographic Hardware and Embedded Systems2025, 2 (2025), 489–510
2025
-
[32]
Andy Ray, Benjamin Devlin, Fu Yong Quah, and Rahul Yesantharao. 2023. Hard- caml MSM: A High-Performance Split CPU-FPGA Multi-Scalar Multiplication Engine. InProceedings of the ACM Symposium on Field-Programmable Gate Arrays. doi:10.1145/3626202.3637577 https://dl.acm.org/doi/10.1145/3626202.3637577
-
[33]
Brandon Reagen, Woojoo Choi, David Brooks, Gu-Yeon Wei, and Hsien-Hsin S. Lee. 2021. HEAX: An Architecture for Computing on Encrypted Data. InProceed- ings of the ACM/IEEE International Symposium on Computer Architecture (ISCA). IEEE, 1113–1126
2021
-
[34]
Nikola Samardzic, Simon Langowski, Srinivas Devadas, and Daniel Sanchez. 2024. Accelerating Zero-Knowledge Proofs Through Hardware-Algorithm Co-Design. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). 366–379. doi:10.1109/MICRO61859.2024.00035
-
[35]
Roman Storm, Alexey Pertsev, and Roman Semenov. 2020. Tornado Cash Privacy Solution. https://tornado.cash/Tornado.cash_whitepaper_v1.4.pdf White Paper
2020
-
[36]
Edward Suh, and Tushar Krishna
Jianming Tong, Tianhao Huang, Jingtian Dang, Leo de Castro, Anirudh Itagi, Anupam Golder, Asra Ali, Jeremy Kun, Jevin Jiang, Arvind, G. Edward Suh, and Tushar Krishna. 2026. Leveraging ASIC AI Chips for Homomorphic Encryption. In2026 IEEE International Symposium on High Performance Computer Architecture (HPCA). 1–18. doi:10.1109/HPCA68181.2026.11408507
-
[37]
Jianming Tong, Anirudh Itagi, Parsanth Chatarasi, and Tushar Krishna. 2024. FEATHER: A Reconfigurable Accelerator with Data Reordering Support for Low- Cost On-Chip Dataflow Switching. InProceedings of the 51th Annual International Symposium on Computer Architecture(Argentina)(ISCA ’24). Association for Computing Machinery, Argentina
2024
-
[38]
Jianming Tong, Yujie Li, Devansh Jain, Charith Mendis, and Tushar Krishna
-
[39]
InProceedings of the 34th Annual International Symposium on Performance Analysis of Systems and Software(Seoul, Korea)(ISPASS ’26)
MINISA: Minimal Instruction Set Architecture for Next-gen Reconfigurable Inference Accelerator. InProceedings of the 34th Annual International Symposium on Performance Analysis of Systems and Software(Seoul, Korea)(ISPASS ’26)
-
[40]
Cheng Wang and Mingyu Gao. 2025. UniZK: Accelerating Zero-Knowledge Proof with Unified Hardware and Flexible Kernel Mapping. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1(Rotterdam, Netherlands)(ASPLOS ’25). Association for Computing Machinery, New York, NY, USA, 1...
-
[41]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures.Commun. ACM 52, 4 (April 2009), 65–76. doi:10.1145/1498765.1498785
-
[42]
Zhengbang Yang et al. 2025. LegoZK: A Dynamically Reconfigurable Acceler- ator for Zero-Knowledge Proof. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA). doi:10.1109/HPCA61900.2025.00020
-
[43]
Yancheng Zhang et al . 2025. zkVC: Fast Zero-Knowledge Proof for Private and Verifiable Computing. InProceedings of the 62nd Annual ACM/IEEE Design Automation Conference(San Francisco, California, United States)(DAC ’25). IEEE Press. doi:10.1109/DAC63849.2025.11132681
-
[44]
Ye Zhang, Shuo Wang, Xian Zhang, et al . 2021. PipeZK: Accelerating Zero- Knowledge Proof with a Pipelined Architecture. InProceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). 7
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.