Recognition: unknown
Asset Harvester: Extracting 3D Assets from Autonomous Driving Logs for Simulation
Pith reviewed 2026-05-10 04:14 UTC · model grok-4.3
The pith
Asset Harvester converts sparse object views from driving logs into complete 3D assets for simulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
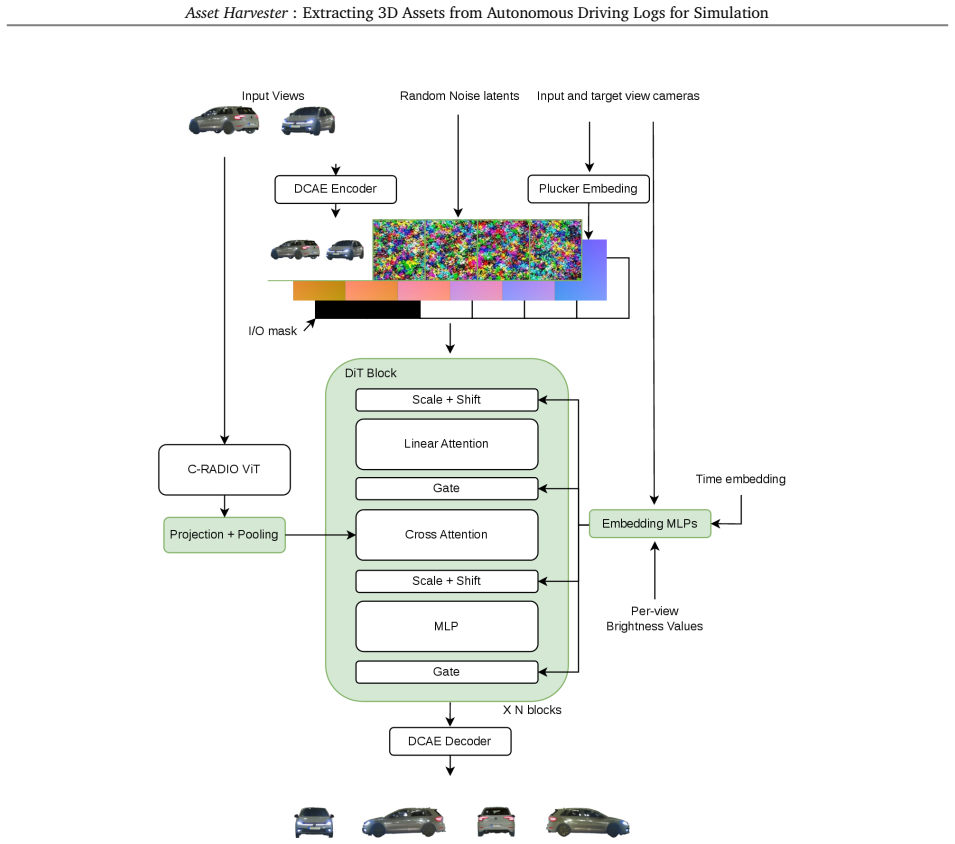
Asset Harvester is an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real driving logs into complete, simulation-ready assets through large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a training recipe that couples sparse-view-conditioned multiview generation with 3D Gaussian lifting inside SparseViewDiT.
What carries the argument
SparseViewDiT, a diffusion transformer that performs sparse-view-conditioned multiview generation and then applies 3D Gaussian lifting to produce complete object geometry from limited-angle inputs.
If this is right
- Simulation environments gain individual, manipulable 3D objects that can be moved or interacted with independently of the background scene.
- Novel-view synthesis becomes possible at large viewpoint changes that scene reconstruction methods cannot handle.
- Real observed objects from driving logs become reusable assets instead of requiring manual modeling or synthetic generation.
- Closed-loop testing scales by automatically populating simulations with objects encountered in actual AV data.
Where Pith is reading between the lines
- The resulting assets could be inserted into existing simulation frameworks to test rare or dangerous object interactions without new data collection.
- The same curation-plus-lifting recipe might apply to other domains that collect sparse object views, such as indoor robotics.
- Combining these object assets with existing neural scene reconstructions could produce fully interactive driving environments.
Load-bearing premise
That real-world driving log data, once curated and preprocessed, supplies enough signal for the model to reliably fill in missing geometry and appearances from limited viewing angles.
What would settle it
Extract assets from a held-out set of driving log observations and measure whether the resulting 3D models produce view-consistent renderings or match independent high-quality scans when viewed from angles absent in the original logs.
Figures






read the original abstract
Closed-loop simulation is a core component of autonomous vehicle (AV) development, enabling scalable testing, training, and safety validation before real-world deployment. Neural scene reconstruction converts driving logs into interactive 3D environments for simulation, but it does not produce complete 3D object assets required for agent manipulation and large-viewpoint novel-view synthesis. To address this challenge, we present Asset Harvester, an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real driving logs into complete, simulation-ready assets. Rather than relying on a single model component, we developed a system-level design for real-world AV data that combines large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a robust training recipe that couples sparse-view-conditioned multiview generation with 3D Gaussian lifting. Within this system, SparseViewDiT is explicitly designed to address limited-angle views and other real-world data challenges. Together with hybrid data curation, augmentation, and self-distillation, this system enables scalable conversion of sparse AV object observations into reusable 3D assets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Asset Harvester, an image-to-3D model and end-to-end pipeline that converts sparse, in-the-wild object observations from real autonomous driving logs into complete, simulation-ready 3D assets. It combines large-scale curation of object-centric training tuples, geometry-aware preprocessing across heterogeneous sensors, and a training recipe coupling sparse-view-conditioned multiview generation with 3D Gaussian lifting in a model called SparseViewDiT, augmented by hybrid data curation, augmentation, and self-distillation to handle limited-angle views and other real-world challenges.
Significance. If the central claims hold with supporting evidence, the work would address a notable gap in neural scene reconstruction for AV simulation by producing reusable, manipulable 3D object assets suitable for agent manipulation and wide-baseline novel-view synthesis, potentially improving the scalability and realism of closed-loop testing and safety validation.
major comments (1)
- [Abstract] Abstract: The manuscript asserts that the system-level design 'enables scalable conversion of sparse AV object observations into reusable 3D assets,' yet the provided description supplies no quantitative results, error metrics (e.g., completeness, PSNR/SSIM for novel views, or mesh quality), ablation studies isolating components such as SparseViewDiT or self-distillation, or comparisons against baselines on real or held-out AV data. This absence leaves the claim that the recipe overcomes the ill-posedness of inferring unseen geometry from limited-angle, noisy observations untested and load-bearing for the central contribution.
minor comments (1)
- [Abstract] Abstract: The term 'SparseViewDiT' is introduced as 'explicitly designed' without a brief definition or reference to its architecture details at first mention, which could be clarified for readers unfamiliar with the DiT backbone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential impact of Asset Harvester on scalable 3D asset creation for AV simulation. We address the major comment point-by-point below and will incorporate revisions to strengthen the presentation of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that the system-level design 'enables scalable conversion of sparse AV object observations into reusable 3D assets,' yet the provided description supplies no quantitative results, error metrics (e.g., completeness, PSNR/SSIM for novel views, or mesh quality), ablation studies isolating components such as SparseViewDiT or self-distillation, or comparisons against baselines on real or held-out AV data. This absence leaves the claim that the recipe overcomes the ill-posedness of inferring unseen geometry from limited-angle, noisy observations untested and load-bearing for the central contribution.
Authors: We agree that the abstract, in its current form, does not explicitly summarize the quantitative evidence supporting the central claims. The full manuscript contains these evaluations in the Experiments section, including PSNR/SSIM and completeness metrics for novel-view synthesis and 3D asset quality, ablation studies isolating SparseViewDiT, hybrid curation, augmentation, and self-distillation, as well as comparisons to baselines on both synthetic and real held-out AV logs. To directly address the referee's concern, we will revise the abstract to concisely incorporate key quantitative highlights from these results, making the empirical support for overcoming limited-angle and noisy observations explicit at the summary level. revision: yes
Circularity Check
No significant circularity; empirical system description only
full rationale
The paper presents Asset Harvester as an end-to-end pipeline combining large-scale object-centric curation, geometry-aware preprocessing, and a SparseViewDiT training recipe (sparse-view multiview generation plus 3D Gaussian lifting) with augmentation and self-distillation. No equations, fitted parameters, predictions, or first-principles derivations appear; the central claim is a system-level empirical design rather than a mathematical reduction. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing steps in the provided text. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SparseViewDiT
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving, 2023. URLhttps://arxiv.org/abs/ 2311.17918. 1
-
[2]
Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025
Jingtao Ding, Yunke Zhang, Yu Shang, Yuheng Zhang, Zefang Zong, Jie Feng, Yuan Yuan, Hongyuan Su, Nian Li, Nicholas Sukiennik, et al. Understanding world or predicting future? a comprehensive survey of world models.ACM Computing Surveys, 58(3):1–38, 2025. 1
2025
-
[3]
Lloyd Russell, Anthony Hu, Lorenzo Bertoni, George Fedoseev, Jamie Shotton, Elahe Arani, and Gianluca Corrado. Gaia-2: A controllable multi-view generative world model for autonomous driving, 2025. URLhttps://arxiv.org/ abs/2503.20523. 1
-
[4]
NVIDIA. Nurec. Website, 2026. URLhttps://research.nvidia.com/labs/sil/nurec/. Accessed 2026-03-08. 1, 17
2026
-
[5]
3dgut: Enabling distorted cameras and secondary rays in gaussian splatting.Conference on Computer Vision and Pattern Recognition ( CVPR),
Qi Wu, Janick Martinez Esturo, Ashkan Mirzaei, Nicolas Moenne-Loccoz, and Zan Gojcic. 3dgut: Enabling distorted cameras and secondary rays in gaussian splatting.Conference on Computer Vision and Pattern Recognition ( CVPR),
-
[6]
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers
Enze Xie, Junsong Chen, Junyu Chen, Han Cai, Haotian Tang, Yujun Lin, Zhekai Zhang, Muyang Li, Ligeng Zhu, Yao Lu, and Song Han. Sana: Efficient high-resolution image synthesis with linear diffusion transformers, 2024. URL https://arxiv.org/abs/2410.10629. 2, 4, 5
work page internal anchor Pith review arXiv 2024
-
[7]
Tokengs: Decoupling 3d gaussian prediction from pixels with learnable tokens
Jiawei Ren, Michal Tyszkiewicz, Jiahui Huang, and Zan Gojcic. Tokengs: Decoupling 3d gaussian prediction from pixels with learnable tokens. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR), 2026. 2, 5
2026
-
[8]
NVIDIA. Ncore. GitHub repository, 2026. URLhttps://github.com/NVIDIA/ncore. Accessed 2026-03-08. 2, 3
2026
-
[9]
YuxuanZhang, KatarínaTóthová, ZianWang, KangxueYin, HaithemTurki, RiccardodeLutio, Yen-YuChang, OrLitany, Sanja Fidler, and Zan Gojcic. Diffusionharmonizer: Bridging neural reconstruction and photorealistic simulation with online diffusion enhancer.arXiv preprint arXiv:2602.24096, 2026. URLhttps://arxiv.org/abs/2602.24096. 2, 15
-
[10]
Juho Kannala and Sami S Brandt. A generic camera model and calibration method for conventional, wide-angle, and fish-eye lenses.IEEE transactions on pattern analysis and machine intelligence, 28(8):1335–1340, 2006. 3
2006
-
[11]
Schwing, and Alexander Kirillov
Bowen Cheng, Alexander G. Schwing, and Alexander Kirillov. Per-pixel classification is not all you need for semantic segmentation. 2021. 3
2021
-
[12]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. 4
2023
-
[14]
Deep compression autoencoder for efficient high-resolution diffusion models
Junyu Chen, Han Cai, Junsong Chen, Enze Xie, Shang Yang, Haotian Tang, Muyang Li, Yao Lu, and Song Han. Deep compression autoencoder for efficient high-resolution diffusion models.arXiv preprint arXiv:2410.10733, 2024. 4
-
[15]
NVIDIA. C-radio. Hugging Face model card, 2026. URLhttps://huggingface.co/nvidia/C-RADIO. Accessed 2026-03-09. 5
2026
-
[16]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. InEuropean Conference on Computer Vision (ECCV),
-
[17]
An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale.ICLR, 2021. 6 19 Asset Harvester: Extracting 3D Assets from Autonomous Dr...
2021
-
[18]
Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation.arXiv preprint arXiv:2402.05054, 2024. 6
-
[19]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects.arXiv preprint arXiv:2212.08051,
-
[20]
Qwen2.5-vl, January 2025
Qwen Team. Qwen2.5-vl, January 2025. URLhttps://qwenlm.github.io/blog/qwen2.5-vl/. 7
2025
-
[21]
Nvidia omniverse replicator
NVIDIA. Nvidia omniverse replicator. Website, 2026. URL https://developer.nvidia.com/omniverse/ replicator. Accessed 2026-02-27. 7
2026
-
[22]
Renderpeople
RenderPeople. Renderpeople. Website, 2026. URLhttps://renderpeople.com/. Accessed 2026-02-27. 7
2026
-
[23]
Polyhaven
Poly Haven. Polyhaven. Website, 2026. URLhttps://polyhaven.com/. Accessed 2026-02-27. 7
2026
-
[24]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page internal anchor Pith review arXiv 2025
-
[25]
OpenAI. Gpt-5.2. OpenAI, 2026. URLhttps://openai.com/index/introducing-gpt-5-2/. Accessed 2026-03-26. 9
2026
-
[26]
Oriane Simeoni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julien ...
2025
-
[27]
Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989,
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Dollar, and Kris Kitani. Sam 3d body: Robust full-body human mesh recovery.arXiv preprint arXiv:2602.15989, 2026. 10
-
[28]
SAM 3D: 3Dfy Anything in Images
SAM 3D Team, Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, Aohan Lin, Jiawei Liu, Ziqi Ma, Anushka Sagar, Bowen Song, Xiaodong Wang, Jianing Yang, Bowen Zhang, Piotr Dollár, Georgia Gkioxari, Matt Feiszli, and Jitendra Malik. Sam 3d: 3dfy anything in images, 2025. URLht...
work page internal anchor Pith review arXiv 2025
-
[29]
arXiv preprint arXiv:2412.01506 (2024) 4
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d generation.arXiv preprint arXiv:2412.01506, 2024. 11, 15
-
[30]
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Zibo Zhao, Zeqiang Lai, Qingxiang Lin, et al. Hunyuan3d 2.0: Scaling diffusion models for high resolution textured 3d assets generation.arXiv preprint arXiv:2501.12202, 2025. 11, 15
work page Pith review arXiv 2025
-
[31]
Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material, 2025
Tencent Hunyuan3D Team. Hunyuan3d 2.1: From images to high-fidelity 3d assets with production-ready pbr material, 2025. 11
2025
-
[32]
Gemini 3 flash (nano banana 2)
Google. Gemini 3 flash (nano banana 2). [Large language model], 2026. URLhttps://gemini.google.com/. Accessed 2026-03-18. 14
2026
-
[33]
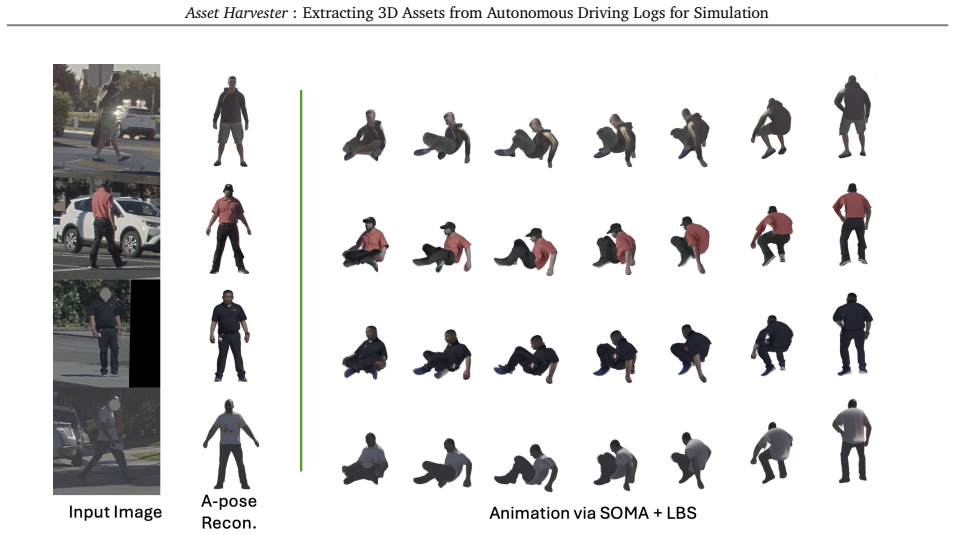
Soma: Unifying parametric human body models.arXiv preprint arXiv:2603.16858, 2026
Jun Saito, Jiefeng Li, Michael de Ruyter, Miguel Guerrero, Edy Lim, Ehsan Hassani, Roger Blanco Ribera, Hyejin Moon, Magdalena Dadela, Marco Di Lucca, Qiao Wang, Xueting Li, Jan Kautz, Simon Yuen, and Umar Iqbal. Soma: Unifying parametric human body models.arXiv preprint arXiv:2603.16858, 2026. URLhttps://arxiv.org/abs/2603.16858. 15
-
[34]
Genmo: A generalist model for human motion
Jiefeng Li, Jinkun Cao, Haotian Zhang, Davis Rempe, Jan Kautz, Umar Iqbal, and Ye Yuan. Genmo: A generalist model for human motion. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. 15 20 Asset Harvester: Extracting 3D Assets from Autonomous Driving Logs for Simulation
2025
-
[35]
Kimodo: Scaling controllable human motion generation.arXiv, 2026
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, Jiefeng Li, Chen Tessler, Edy Lim, Eugene Jeong, Sam Wu, Ehsan Hassani, Michael Huang, Jin-Bey Yu, Chaeyeon Chung, Lina Song, Olivier Dionne, Jan Kautz, Simon Yuen, and Sanja Fidler. Kimodo: Scaling controllable human...
2026
-
[36]
Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation, 2024
Tencent Hunyuan3D Team. Hunyuan3d 1.0: A unified framework for text-to-3d and image-to-3d generation, 2024. 15
2024
-
[37]
arXiv preprint arXiv:2506.16504 , year=
Tencent Hunyuan3D Team. Hunyuan3d 2.5: Towards high-fidelity 3d assets generation with ultimate details, 2025. URLhttps://arxiv.org/abs/2506.16504. 15
-
[38]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, and Jiaolong Yang. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025. 15
-
[39]
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object.arXiv preprint arXiv:2303.11328, 2023. 16
-
[40]
MVDream: Multi-view Diffusion for 3D Generation
Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation.arXiv preprint arXiv:2308.16512, 2023. 16
work page internal anchor Pith review arXiv 2023
-
[41]
arXiv preprint arXiv:2312.02201 , year=
Peng Wang and Yichun Shi. Imagedream: Image-prompt multi-view diffusion for 3d generation.arXiv preprint arXiv:2312.02201, 2023. 16
-
[42]
Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer
Shuang Wu, Youtian Lin, Feihu Zhang, Yifei Zeng, Jingxi Xu, Philip Torr, Xun Cao, and Yao Yao. Direct3d: Scalable image-to-3d generation via 3d latent diffusion transformer.arXiv preprint arXiv:2405.14832, 2024. 16
-
[43]
Cat3d: Create any- thing in 3d with multi-view diffusion models,
Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin-Brualla, Pratul Srinivasan, Jonathan T. Barron, and Ben Poole. Cat3d: Create anything in 3d with multi-view diffusion models.arXiv preprint arXiv:2405.10314, 2024. 16
-
[44]
Genassets: Generating in-the-wild 3d assets in latent space
Ze Yang, Jingkang Wang, Haowei Zhang, Sivabalan Manivasagam, Yun Chen, and Raquel Urtasun. Genassets: Generating in-the-wild 3d assets in latent space. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR), 2025. 16
2025
-
[45]
Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, and Dragomir Anguelov
Bokui Shen, Xinchen Yan, Charles R. Qi, Mahyar Najibi, Boyang Deng, Leonidas Guibas, Yin Zhou, and Dragomir Anguelov. Gina-3d: Learning to generate implicit neural assets in the wild.arXiv preprint arXiv:2304.02163, 2023. 16
-
[46]
Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction.IEEE Robotics and Automation Letters, 10(2):1840–1847, 2024
Xiaobiao Du, Haiyang Sun, Ming Lu, Tianqing Zhu, and Xin Yu. Dreamcar: Leveraging car-specific prior for in-the-wild 3d car reconstruction.IEEE Robotics and Automation Letters, 10(2):1840–1847, 2024. 16
2024
-
[47]
Urbancad: Towards highly controllable and photorealistic 3d vehicles for urban scene simulation
Yichong Lu, Yichi Cai, Shangzhan Zhang, Hongyu Zhou, Haoji Hu, Huimin Yu, Andreas Geiger, and Yiyi Liao. Urbancad: Towards highly controllable and photorealistic 3d vehicles for urban scene simulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 27519–27530, 2025. 16
2025
-
[48]
Xiaoxue Chen, Jv Zheng, Hao Huang, Haoran Xu, Weihao Gu, Kangliang Chen, Huan-ang Gao, Hao Zhao, Guyue Zhou, Yaqin Zhang, et al. Rgm: Reconstructing high-fidelity 3d car assets with relightable 3d-gs generative model from a single image.arXiv preprint arXiv:2410.08181, 2024. 16
-
[49]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics ( SIGGRAPH), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk"uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics ( SIGGRAPH), 2023. 16
2023
-
[50]
Neural scene graphs for dynamic scenes
Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition ( CVPR), 2021. 16
2021
-
[51]
Omnire: Omni urban scene reconstruction
Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. Omnire: Omni urban scene reconstruction. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=11xgiMEI5o. 16 21 Asset Harveste...
2025
-
[52]
Carla documentation: Nvidia nurec
CARLA Team. Carla documentation: Nvidia nurec. Website, 2026. URL https://carla.readthedocs.io/en/ latest/nvidia_nurec/. Accessed 2026-03-09. 17
2026
-
[53]
Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving
NVIDIA, Yulong Cao, Riccardo de Lutio, Sanja Fidler, Guillermo Garcia Cobo, Zan Gojcic, Maximilian Igl, Boris Ivanovic, Peter Karkus, Janick Martinez Esturo, Marco Pavone, Aaron Smith, Ellie Tanimura, Michal Tyszkiewicz, Michael Watson, Qi Wu, and Le Zhang. Alpasim: A modular, lightweight, and data-driven research simulator for autonomous driving. Softwar...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.