Recognition: unknown
Reducing the Offline-Streaming Gap for Unified ASR Transducer with Consistency Regularization
Pith reviewed 2026-05-10 01:43 UTC · model grok-4.3
The pith
A single RNNT model can close the accuracy gap between offline and low-latency streaming ASR by training with mode-consistency regularization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
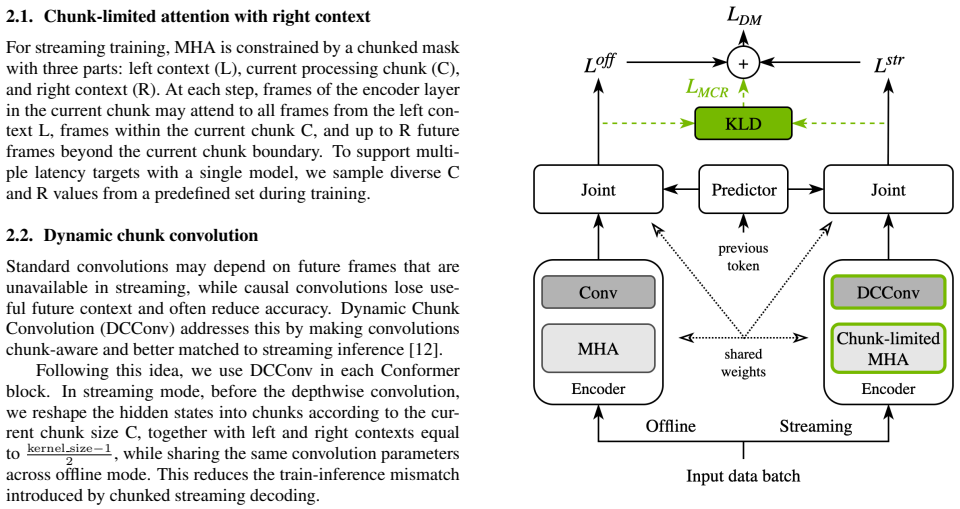
The authors introduce a Unified ASR framework for RNNT that supports both offline and streaming decoding in one model through chunk-limited attention with right context and dynamic chunked convolutions, then add an efficient Triton implementation of mode-consistency regularization (MCR-RNNT) that penalizes disagreement between the offline and streaming forward passes during training; experiments confirm this reduces the performance gap without harming either mode.
What carries the argument
Mode-consistency regularization for RNNT (MCR-RNNT), which adds a loss term that encourages identical token predictions and alignments when the same input is processed under offline versus streaming (chunked) configurations.
If this is right
- Streaming accuracy at low latency improves while offline accuracy stays the same.
- The unified model continues to benefit from scaling to larger sizes and larger training sets.
- A single trained checkpoint can be deployed for both batch transcription and real-time applications.
- The open-sourced English model provides a concrete starting point for further work on unified transducers.
Where Pith is reading between the lines
- The same consistency idea could be tested on other transducer variants or non-transducer ASR architectures to see if the gap closes without architecture-specific changes.
- Production systems might reduce the number of maintained model versions by switching from separate offline and streaming checkpoints to one regularized model.
- Similar regularization between training and inference modes could be explored for other latency-sensitive sequence tasks such as machine translation or speech synthesis.
Load-bearing premise
Enforcing agreement between the offline and streaming forward passes will not prevent the model from learning representations that are optimal for each setting individually.
What would settle it
A controlled ablation in which adding MCR-RNNT increases the offline-streaming word-error-rate gap or raises error rates in both modes on the same training data and model size.
Figures

read the original abstract
Unification of automatic speech recognition (ASR) systems reduces development and maintenance costs, but training a single model to perform well in both offline and low-latency streaming settings remains challenging. We present a Unified ASR framework for Transducer (RNNT) training that supports both offline and streaming decoding within a single model, using chunk-limited attention with right context and dynamic chunked convolutions. To further close the gap between offline and streaming performance, we introduce an efficient Triton implementation of mode-consistency regularization for RNNT (MCR-RNNT), which encourages agreement across training modes. Experiments show that the proposed approach improves streaming accuracy at low latency while preserving offline performance and scaling to larger model sizes and training datasets. The proposed Unified ASR framework and the English model checkpoint are open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a unified RNN-T ASR framework supporting both offline and low-latency streaming decoding in a single model via chunk-limited attention with right context and dynamic chunked convolutions. It introduces an efficient Triton-based mode-consistency regularization (MCR-RNNT) to encourage agreement between training modes and thereby reduce the offline-streaming performance gap. The central empirical claim is that the approach improves streaming accuracy at low latency while preserving offline performance, scales to larger models and datasets, and the framework plus an English checkpoint are open-sourced.
Significance. If the empirical results hold under rigorous validation, the work would be significant for practical ASR systems by enabling cost-effective unified models that avoid separate offline and streaming deployments. The open-sourcing of code and a checkpoint is a clear strength for reproducibility.
major comments (2)
- [Abstract / Experiments] The abstract asserts experimental improvements in streaming accuracy at low latency while preserving offline performance, yet supplies no quantitative metrics, baselines, dataset sizes, or error analysis; without these the data-to-claim link cannot be verified (see also Experiments section).
- [Method (MCR-RNNT)] The mode-consistency regularization is presented as encouraging agreement across modes without reducing capacity for optimal representations in either setting. If the consistency term is applied to joint-network or prediction-network outputs (as implied by the RNNT formulation), it implicitly penalizes mode-specific deviations; this can only preserve offline performance if the offline optimum already lies close to the streaming optimum, which is not guaranteed a priori and is not directly tested by a single joint training run or by ablations comparing to separately optimized models.
minor comments (3)
- [Method] Clarify the precise mathematical form of the consistency loss (e.g., which outputs are compared and the weighting schedule) with an equation reference.
- [Experiments] Add explicit statements of chunk size, right-context length, and latency targets in the experimental setup for reproducibility.
- [Experiments] Ensure all tables report both absolute WER/CER and relative improvements with confidence intervals or multiple runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below, proposing targeted revisions to strengthen the manuscript while preserving its core contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] The abstract asserts experimental improvements in streaming accuracy at low latency while preserving offline performance, yet supplies no quantitative metrics, baselines, dataset sizes, or error analysis; without these the data-to-claim link cannot be verified (see also Experiments section).
Authors: We agree that including key quantitative results in the abstract would improve verifiability. In the revised version, we will add specific WER reductions for low-latency streaming (e.g., relative improvements over baselines), confirmation of offline WER parity, training dataset scale (hours of audio), and reference to the main experimental tables. The full baselines, dataset details, and error analysis remain in Section 4; this change makes the abstract self-contained without altering its length substantially. revision: yes
-
Referee: [Method (MCR-RNNT)] The mode-consistency regularization is presented as encouraging agreement across modes without reducing capacity for optimal representations in either setting. If the consistency term is applied to joint-network or prediction-network outputs (as implied by the RNNT formulation), it implicitly penalizes mode-specific deviations; this can only preserve offline performance if the offline optimum already lies close to the streaming optimum, which is not guaranteed a priori and is not directly tested by a single joint training run or by ablations comparing to separately optimized models.
Authors: This is a valid concern about the implicit assumption in joint training. Our experiments (Table 3 and ablations in Section 4.3) show that the unified model achieves offline WER statistically indistinguishable from or better than the offline-only baseline while improving streaming, suggesting the optima are sufficiently close under our chunking and regularization. The MCR-RNNT loss is applied with a small weighting factor (0.1) and only on selected outputs to avoid over-constraining capacity. However, we acknowledge the absence of an explicit side-by-side comparison against independently optimized offline and streaming models. We will add this ablation experiment in the revision to directly address the point. revision: yes
Circularity Check
No circularity; empirical results rest on independent training experiments
full rationale
The paper presents a training framework (chunk-limited attention, dynamic convolutions, and MCR-RNNT regularization) whose central claims are validated by direct experiments on streaming vs. offline WER across model scales and datasets. No derivation chain, equation, or uniqueness theorem reduces the reported gains to quantities defined by the method itself; the consistency term is an added loss applied during joint training, and performance differences are measured against baselines rather than forced by construction. No self-citations are load-bearing for the core results.
Axiom & Free-Parameter Ledger
free parameters (1)
- chunk size and right-context length
axioms (1)
- domain assumption The RNN-T loss remains a suitable objective for both offline and streaming modes when context is limited.
Reference graph
Works this paper leans on
-
[1]
Maintaining separate mod- els for these regimes increases the cost of model development, training, validation, and deployment
Introduction Deploying automatic speech recognition (ASR) systems com- monly requires both high-accuracy offline transcription and low-latency streaming performance. Maintaining separate mod- els for these regimes increases the cost of model development, training, validation, and deployment. All of these motivate ef- forts to train a single unified model ...
-
[2]
Reducing the Offline-Streaming Gap for Unified ASR Transducer with Consistency Regularization
Method We train a single RNNT model with shared parameters to sup- port both offline and streaming decoding. The model follows the standard Transducer design with encoder, predictor, and joint. Our encoder uses Conformer-style blocks with multi-head attention (MHA) and convolution modules. To enable stream- ing, we restrict MHA and convolution context dur...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
ASR modeling and evaluation As the main ASR architecture, we used RNNT model based on FastConformer encoder [22] with 123M parameters
Experimental setup 3.1. ASR modeling and evaluation As the main ASR architecture, we used RNNT model based on FastConformer encoder [22] with 123M parameters. The input features are 128-dim FBanks with x8 initial subsampling. The prediction network (decoder) is a single-layer LSTM with 640 units, which increased the total model size to 128M parameters. Al...
-
[4]
Table 2:Average WER (%) on Open ASR Leaderboard for dif- ferent training configurations of KLD teacher, KLD weightλ, and offlineαfor the same unified RNNT L-size model
Results Table 1 presents the main evaluation results for the considered models in the offline and streaming decoding scenarios. Table 2:Average WER (%) on Open ASR Leaderboard for dif- ferent training configurations of KLD teacher, KLD weightλ, and offlineαfor the same unified RNNT L-size model. Configuration Variable Offline 1.12s 0.56s 0.32s KLD Teacher...
-
[5]
Conclusion We propose a new Unified ASR framework that achieves robust Transducer performance in both offline and streaming decod- ing scenarios. In addition to using chunk-limited attention and dynamic chunked convolutions, we introduce a novel mode- consistency regularization loss (MCR-RNNT), which further reduces the gap between offline and streaming e...
-
[6]
Transformer transducer: One model unifying streaming and non-streaming speech recognition,
A. Tripathi, J. Kim, Q. Zhang, H. Lu, and H. Sak, “Transformer transducer: One model unifying streaming and non-streaming speech recognition,”ArXiv, vol. abs/2010.03192, 2020
-
[7]
Dual-mode asr: Unify and improve streaming asr with full-context modeling,
J. Yu, W. Han, A. Gulati, C.-C. Chiu, B. Li, T. N. Sainath, Y . Wu, and R. Pang, “Dual-mode asr: Unify and improve streaming asr with full-context modeling,”ICLR, 2021
2021
-
[8]
Wenet: Production oriented stream- ing and non-streaming end-to-end speech recognition toolkit,
Z. Yao, D. Wu, X. Wang, B. Zhang, F. Yu, C. Yang, Z. Peng, X. Chen, L. Xie, and X. Lei, “Wenet: Production oriented stream- ing and non-streaming end-to-end speech recognition toolkit,” in Interspeech, 2021
2021
-
[9]
Learning a dual-mode speech recognition model via self-pruning,
C. Liu, Y . Shangguan, H. Yang, Y . Shi, R. Krishnamoorthi, and O. Kalinli, “Learning a dual-mode speech recognition model via self-pruning,”SLT, pp. 273–279, 2022
2022
-
[10]
Sequence transduction with recurrent neural net- works,
A. Graves, “Sequence transduction with recurrent neural net- works,” inICML, 2012
2012
-
[11]
Conformer: Convolution- augmented transformer for speech recognition,
A. Gulati, J. Qin, C.-C. Chiuet al., “Conformer: Convolution- augmented transformer for speech recognition,”Proc. Interspeech 2020, pp. 5036–5040, 2020
2020
-
[12]
Developing real- time streaming transformer transducer for speech recognition on large-scale dataset,
X. Chen, Y . Wu, Z. Wang, S. Liu, and J. Li, “Developing real- time streaming transformer transducer for speech recognition on large-scale dataset,”ICASSP, pp. 5904–5908, 2020
2020
-
[13]
Streaming automatic speech recognition with the transformer model,
N. Moritz, T. Hori, and J. L. Roux, “Streaming automatic speech recognition with the transformer model,”ICASSP, pp. 6074–6078, 2020
2020
-
[14]
Stateful conformer with cache-based inference for streaming au- tomatic speech recognition,
V . Noroozi, S. Majumdar, A. Kumar, J. Balam, and B. Ginsburg, “Stateful conformer with cache-based inference for streaming au- tomatic speech recognition,”ICASSP, 2023
2023
-
[15]
Unifying streaming and non- streaming zipformer-based asr,
B. Sharma, K. P. Durai, S. Venkatesan, J. Prakash, S. Ku- mar, M. Chetlur, and A. Stolcke, “Unifying streaming and non- streaming zipformer-based asr,”ACL, 2025
2025
-
[16]
Improving streaming speech recognition with time-shifted contextual attention and dynamic right context masking,
K. Le and D. T. Chau, “Improving streaming speech recognition with time-shifted contextual attention and dynamic right context masking,”Interspeech, 2024
2024
-
[17]
Dynamic chunk convolution for unified streaming and non- streaming conformer asr,
X. Li, G. Huybrechts, S. Ronanki, J. J. Farris, and S. Bodap- ati, “Dynamic chunk convolution for unified streaming and non- streaming conformer asr,”ICASSP, 2023
2023
-
[18]
All-in-one asr: Unifying encoder-decoder models of ctc, attention, and transducer in dual-mode asr,
T. Moriya, M. Mimura, T. Tanaka, H. Sato, R. Masumura, and A. Ogawa, “All-in-one asr: Unifying encoder-decoder models of ctc, attention, and transducer in dual-mode asr,” 2025
2025
-
[19]
Open asr leaderboard: Towards reproducible and transparent multilingual and long-form speech recognition evaluation,
V . Srivastav, S. Zheng, E. Bezzam, E. L. Bihan, N. Koluguri, P. ˙Zelasko, S. Majumdar, A. Moumen, and S. Gandhi, “Open asr leaderboard: Towards reproducible and transparent multilingual and long-form speech recognition evaluation,” 2025
2025
-
[20]
Parakeet tdt 0.6b v2 (en),
NVIDIA, “Parakeet tdt 0.6b v2 (en),” 2025. [Online]. Available: https://huggingface.co/nvidia/parakeet-tdt-0.6b-v2
2025
-
[21]
Nemotron-speech-streaming-en-0.6b,
——, “Nemotron-speech-streaming-en-0.6b,” Jan- uary 2026. [Online]. Available: https: //huggingface.co/nvidia/nemotron-speech-streaming-en-0. 6b/tree/nemotron-speech-streaming-jan2026
2026
-
[22]
Cr-ctc: Consistency regularization on ctc for improved speech recognition,
Z. Yao, W. Kang, X. Yang, F. Kuang, L. Guo, H. Zhu, Z. Jin, Z. Li, L. Lin, and D. Povey, “Cr-ctc: Consistency regularization on ctc for improved speech recognition,”ICLR, 2025
2025
-
[23]
Transducer consistency regularization for speech to text applications,
C. Tseng, Y . Tang, and V . R. Apsingekar, “Transducer consistency regularization for speech to text applications,”SLT, 2024
2024
-
[24]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antigaet al., “PyTorch: An imperative style, high-performance deep learning library,” in NeurIPS, vol. 32, 2019
2019
-
[25]
Triton: an intermediate lan- guage and compiler for tiled neural network computations,
P. Tillet, H.-T. Kung, and D. Cox, “Triton: an intermediate lan- guage and compiler for tiled neural network computations,” in Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, 2019, pp. 10–19
2019
-
[26]
Nemo: a toolkit for building ai applications using neural modules,
O. Kuchaiev, J. Li, H. Nguyenet al., “Nemo: a toolkit for building ai applications using neural modules,” inNeurIPS Workshop on Systems for ML, 2019
2019
-
[27]
Fast Conformer with linearly scalable attention for efficient speech recognition,
D. Rekesh, N. R. Koluguri, S. Kriman,et al., “Fast Conformer with linearly scalable attention for efficient speech recognition,” inAutomatic Speech Recognition and Understanding Workshop (ASRU), 2023
2023
-
[28]
Emmett: Effi- cient multimodal machine translation training,
P. ˙Zelasko, Z. Chen, M. Wang, D. Galvez, O. Hrinchuk, S. Ding, K. Hu, J. Balam, V . Lavrukhin, and B. Ginsburg, “Emmett: Effi- cient multimodal machine translation training,”ICASSP, 2024
2024
-
[29]
N. R. Koluguri, M. Sekoyan, G. Zelenfroynd, S. Meister, S. Ding, S. Kostandian, H. Huang, N. Karpov, J. Balam, V . Lavrukhin, Y . Peng, S. Papi, M. Gaido, A. Brutti, and B. Ginsburg, “Gra- nary: Speech recognition and translation dataset in 25 european languages,”Interspeech, vol. abs/2505.13404, 2025
-
[30]
Neural machine transla- tion of rare words with subword units,
R. Sennrich, B. Haddow, and A. Birch, “Neural machine transla- tion of rare words with subword units,” inProceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016
2016
-
[31]
Label-looping: Highly efficient decoding for transducers,
V . Bataev, H. Xu, D. Galvez, V . Lavrukhin, and B. Ginsburg, “Label-looping: Highly efficient decoding for transducers,” in 2024 IEEE Spoken Language Technology Workshop (SLT), 2024, pp. 7–13
2024
-
[32]
Speed of light ex- act greedy decoding for rnn-t speech recognition models on gpu,
D. Galvez, V . Bataev, H. Xu, and T. Kaldewey, “Speed of light ex- act greedy decoding for rnn-t speech recognition models on gpu,” inInterspeech 2024, 2024, pp. 277–281
2024
-
[33]
Transformers are ssms: Generalized models and efficient algorithms through structured state space duality,
T. Dao and A. Gu, “Transformers are ssms: Generalized models and efficient algorithms through structured state space duality,” ICML, 2024
2024
-
[34]
Canary-qwen-2.5b,
NVIDIA, “Canary-qwen-2.5b,” 2025. [Online]. Available: https: //huggingface.co/nvidia/canary-qwen-2.5b
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.