Recognition: unknown
Absorber LLM: Harnessing Causal Synchronization for Test-Time Training
Pith reviewed 2026-05-10 00:48 UTC · model grok-4.3
The pith
Absorber LLM absorbs historical contexts into model parameters by synchronizing its behavior with the original full-context model on future predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
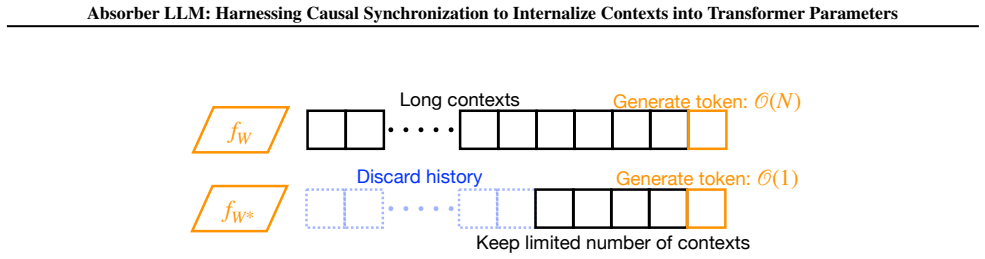
Absorber LLM formulates long-context retention as a self-supervised causal synchronization: after absorbing historical contexts into parameters, a contextless model should match the original model with full context on future generations. This objective is optimized by synchronizing internal behaviors of the updated model with the original one, ensuring context absorption and generalization without breaking the pretrained causal structure.
What carries the argument
The causal synchronization objective that aligns the internal states or behaviors of the parameter-updated contextless model to those of the original context-aware model during prediction of future tokens.
If this is right
- Constant memory usage during inference regardless of context length.
- Improved accuracy on long-context and streaming benchmarks compared to prior parameter-as-memory methods.
- Preservation of the causal effect from the pretrained LLM.
- Ability to handle long-tail dependencies better than fixed-state RNNs or SSMs.
Where Pith is reading between the lines
- Extending this synchronization to multi-turn conversations could enable persistent memory across sessions without growing context windows.
- Applying the method to multimodal models might allow absorbing visual or audio history into parameters for efficient generation.
- Testing whether the synchronized internal behaviors scale with model size would reveal if larger models benefit more from this absorption technique.
Load-bearing premise
That synchronizing internal behaviors of the updated model with the original one after context absorption will ensure both faithful context retention and generalization to future tokens without introducing overfitting or breaking pretrained causal structure.
What would settle it
Observing a significant mismatch in next-token predictions or internal activations between the context-absorbed model and the original full-context model on a sequence of future tokens would falsify the claim that the synchronization achieves faithful retention.
Figures

read the original abstract
Transformers suffer from a high computational cost that grows with sequence length for self-attention, making inference in long streams prohibited by memory consumption. Constant-memory alternatives such as RNNs and SSMs compress history into states with fixed size and thus lose long-tail dependencies, while methods that memorize contexts into parameters, such as Test-Time Training (TTT), are prone to overfitting token-level projection and fail to preserve the causal effect of context in pretrained LLMs. We propose Absorber LLM, which formulates long-context retention as a self-supervised causal synchronization: after absorbing historical contexts into parameters, a contextless model should match the original model with full context on future generations. We optimize this objective by synchronizing internal behaviors of the updated model with the original one, ensuring context absorption and generalization. Experiments on long-context and streaming benchmarks show that Absorber LLM reduces inference memory and improves accuracy over prior parameter-as-memory baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Absorber LLM, a test-time training approach for transformers that absorbs long historical contexts into model parameters via a self-supervised causal synchronization objective. After absorption, a contextless updated model is trained to match the internal behaviors of the original model (with full context) on future generations. This is claimed to enable constant-memory inference while retaining long-range dependencies better than RNNs, SSMs, or prior parameter-as-memory TTT methods, with experiments on long-context and streaming benchmarks showing reduced inference memory and improved accuracy over baselines.
Significance. If the causal synchronization mechanism can be rigorously validated, the approach could advance efficient long-context inference in LLMs by integrating context into parameters without the overfitting or causal disruption issues of prior TTT methods. The focus on matching internal behaviors rather than token-level projections is a potentially useful distinction, though its significance hinges on providing the missing technical details to substantiate the benchmark gains.
major comments (2)
- [Abstract] Abstract: The self-supervised causal synchronization objective is described only qualitatively, with no loss formulation, no specification of which internal behaviors (e.g., activations or layers) are synchronized, and no details on the optimization or constraints enforcing causality. This is load-bearing for the central claim, as the abstract explicitly criticizes prior TTT for overfitting token-level projections and failing to preserve causal effects, yet the manuscript provides no mechanism to verify how the proposed method avoids these pitfalls or reduces to a non-trivial fit.
- [Method (no equations provided)] No equations or derivation section: The paper provides no mathematical definition of the synchronization loss or how context absorption into parameters is performed while preserving pretrained causal structure. This directly impacts the ability to assess the skeptic's concern that incomplete synchronization could disrupt causal dependencies or lead to memorization rather than generalizable retention, undermining both the memory reduction and accuracy claims.
minor comments (1)
- [Abstract] Abstract: The phrase 'synchronizing internal behaviors' is used without clarification of the precise components involved, which reduces clarity even at the high level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which correctly identifies gaps in the technical exposition of the causal synchronization mechanism. We agree that explicit mathematical details are necessary to substantiate the claims and will revise the manuscript accordingly to include them.
read point-by-point responses
-
Referee: [Abstract] Abstract: The self-supervised causal synchronization objective is described only qualitatively, with no loss formulation, no specification of which internal behaviors (e.g., activations or layers) are synchronized, and no details on the optimization or constraints enforcing causality. This is load-bearing for the central claim, as the abstract explicitly criticizes prior TTT for overfitting token-level projections and failing to preserve causal effects, yet the manuscript provides no mechanism to verify how the proposed method avoids these pitfalls or reduces to a non-trivial fit.
Authors: We agree that the abstract is qualitative and does not provide the requested specifics. In the revised version, we will update the abstract to briefly indicate that synchronization targets internal activations and attention patterns across layers, with causality enforced via autoregressive masking during context absorption. Due to length constraints, the full loss formulation (as a self-supervised objective matching behaviors on future generations) and optimization details will be moved to an expanded methods section. This revision will directly address how the approach differs from token-level overfitting in prior TTT methods. revision: yes
-
Referee: [Method (no equations provided)] No equations or derivation section: The paper provides no mathematical definition of the synchronization loss or how context absorption into parameters is performed while preserving pretrained causal structure. This directly impacts the ability to assess the skeptic's concern that incomplete synchronization could disrupt causal dependencies or lead to memorization rather than generalizable retention, undermining both the memory reduction and accuracy claims.
Authors: We acknowledge that the submitted manuscript lacks equations and a dedicated derivation section, which limits rigorous evaluation of the claims. We will add a new subsection in the methods with the mathematical definition of the synchronization loss, specifying the internal behaviors synchronized (activations and attention maps), the parameter update procedure for context absorption, and the constraints (e.g., causal masking) used to preserve the pretrained structure. This will allow assessment of whether the objective promotes generalizable retention rather than memorization. revision: yes
Circularity Check
No circularity: objective anchored externally to pretrained model behavior
full rationale
The paper defines its core method as a self-supervised objective in which a contextless updated model is trained to match the original pretrained model's internal behaviors and future generations after parameter absorption. This matching target is the external pretrained model with full context, not a quantity derived from the update itself. No equations appear in the provided text that would make the synchronization loss equivalent to a fitted input or self-defined quantity by construction. No self-citations are invoked to justify uniqueness or import an ansatz. The derivation therefore remains self-contained and externally falsifiable via the matching criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[2]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review arXiv
-
[3]
GPT-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Emergent Abilities of Large Language Models
Emergent capabilities of large language models , author=. arXiv preprint arXiv:2206.07682 , year=
work page internal anchor Pith review arXiv
-
[7]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of artificial general intelligence: Early experiments with gpt-4 , author=. arXiv preprint arXiv:2303.12712 , year=
work page internal anchor Pith review arXiv
-
[8]
Frontiers of Computer Science , volume=
A survey on large language model based autonomous agents , author=. Frontiers of Computer Science , volume=. 2024 , publisher=
2024
-
[9]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
-
[10]
2024 , url=
Carlos E Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik R Narasimhan , booktitle=. 2024 , url=
2024
-
[11]
Proceedings of the ACM on Software Engineering , volume=
Codeplan: Repository-level coding using llms and planning , author=. Proceedings of the ACM on Software Engineering , volume=. 2024 , publisher=
2024
-
[12]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[13]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=
-
[14]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[15]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[18]
International conference on machine learning , pages=
Transformers are rnns: Fast autoregressive transformers with linear attention , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[19]
International Conference on Learning Representations , year=
Rethinking Attention with Performers , author=. International Conference on Learning Representations , year=
-
[20]
The Twelfth International Conference on Learning Representations , year=
RingAttention with Blockwise Transformers for Near-Infinite Context , author=. The Twelfth International Conference on Learning Representations , year=
-
[22]
Advances in neural information processing systems , volume=
Combining recurrent, convolutional, and continuous-time models with linear state space layers , author=. Advances in neural information processing systems , volume=
-
[23]
First conference on language modeling , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. First conference on language modeling , year=
-
[24]
Retentive Network: A Successor to Transformer for Large Language Models
Retentive Network: A Successor to Transformer for Large Language Models , author=. arXiv preprint arXiv:2307.08621 , year=
work page internal anchor Pith review arXiv
-
[25]
Forty-first International Conference on Machine Learning , year=
The Illusion of State in State-Space Models , author=. Forty-first International Conference on Machine Learning , year=
-
[26]
2024 , url=
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , booktitle=. 2024 , url=
2024
-
[27]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
L-eval: Instituting standardized evaluation for long context language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
Neural Computation , volume=
Learning to control fast-weight memories: An alternative to dynamic recurrent networks , author=. Neural Computation , volume=. 1992 , publisher=
1992
-
[29]
Advances in neural information processing systems , volume=
Using fast weights to attend to the recent past , author=. Advances in neural information processing systems , volume=
-
[30]
Learning to (Learn at Test Time):
Yu Sun and Xinhao Li and Karan Dalal and Jiarui Xu and Arjun Vikram and Genghan Zhang and Yann Dubois and Xinlei Chen and Xiaolong Wang and Sanmi Koyejo and Tatsunori Hashimoto and Carlos Guestrin , booktitle=. Learning to (Learn at Test Time):. 2025 , url=
2025
-
[31]
Nested Learning: The Illusion of Deep Learning Architectures , author=
-
[32]
Adam: A Method for Stochastic Optimization
A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of COMPSTAT'2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=
Large-scale machine learning with stochastic gradient descent , author=. Proceedings of COMPSTAT'2010: 19th International Conference on Computational StatisticsParis France, August 22-27, 2010 Keynote, Invited and Contributed Papers , pages=. 2010 , organization=
2010
-
[34]
Neural networks: Tricks of the trade: Second edition , pages=
Practical recommendations for gradient-based training of deep architectures , author=. Neural networks: Tricks of the trade: Second edition , pages=. 2012 , publisher=
2012
-
[37]
Neural computation , volume=
Predictability, complexity, and learning , author=. Neural computation , volume=. 2001 , publisher=
2001
-
[38]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Adapting language models to compress contexts , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[39]
Advances in Neural Information Processing Systems , volume=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
Sequence-Level Knowledge Distillation , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
2016
-
[41]
Advances in Neural Information Processing Systems , volume=
Causal abstractions of neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Causal Learning and Reasoning , pages=
Finding alignments between interpretable causal variables and distributed neural representations , author=. Causal Learning and Reasoning , pages=. 2024 , organization=
2024
-
[43]
Proceedings of the IEEE , volume=
Toward causal representation learning , author=. Proceedings of the IEEE , volume=. 2021 , publisher=
2021
-
[44]
2023 , eprint=
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. 2023 , eprint=
2023
-
[45]
SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Gliwa, Bogdan and Mochol, Iwona and Biesek, Maciej and Wawer, Aleksander. SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization. Workshop on New Frontiers in Summarization. 2019
2019
-
[46]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
BLEURT: Learning Robust Metrics for Text Generation , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , year=
-
[47]
Gao, Leo and Biderman, Stella and Black, Sid and Golding, Laurence and Hoppe, Travis and Foster, Charles and Phang, Jason and He, Horace and Thite, Anish and Nabeshima, Noa and Presser, Shawn and Leahy, Connor , journal=. The
-
[48]
NIPS , year=
Character-level Convolutional Networks for Text Classification , author=. NIPS , year=
-
[50]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[51]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[52]
The Fourteenth International Conference on Learning Representations , year=
In-Place Test-Time Training , author=. The Fourteenth International Conference on Learning Representations , year=
-
[53]
Longbench: A bilingual, multitask benchmark for long context understanding, 2023
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y., Tang, J., and Li, J. Longbench: A bilingual, multitask benchmark for long context understanding, 2023
2023
-
[54]
D., Iyer, A., Parthasarathy, S., Rajamani, S., Ashok, B., and Shet, S
Bairi, R., Sonwane, A., Kanade, A., C, V. D., Iyer, A., Parthasarathy, S., Rajamani, S., Ashok, B., and Shet, S. Codeplan: Repository-level coding using llms and planning. Proceedings of the ACM on Software Engineering, 1 0 (FSE): 0 675--698, 2024
2024
-
[55]
Nested learning: The illusion of deep learning architectures
Behrouz, A., Razaviyayn, M., Zhong, P., and Mirrokni, V. Nested learning: The illusion of deep learning architectures. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[56]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[57]
Predictability, complexity, and learning
Bialek, W., Nemenman, I., and Tishby, N. Predictability, complexity, and learning. Neural computation, 13 0 (11): 0 2409--2463, 2001
2001
-
[58]
Analyzing memory effects in large language models through the lens of cognitive psychology
Cao, Z., Schooler, L., and Zafarani, R. Analyzing memory effects in large language models through the lens of cognitive psychology. arXiv preprint arXiv:2509.17138, 2025
-
[59]
Adapting language models to compress contexts
Chevalier, A., Wettig, A., Ajith, A., and Chen, D. Adapting language models to compress contexts. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp.\ 3829--3846, 2023
2023
-
[60]
Generating Long Sequences with Sparse Transformers
Child, R. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[61]
M., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J
Choromanski, K. M., Likhosherstov, V., Dohan, D., Song, X., Gane, A., Sarlos, T., Hawkins, P., Davis, J. Q., Mohiuddin, A., Kaiser, L., Belanger, D. B., Colwell, L. J., and Weller, A. Rethinking attention with performers. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=Ua6zuk0WRH
2021
-
[62]
Flashattention: Fast and memory-efficient exact attention with io-awareness
Dao, T., Fu, D., Ermon, S., Rudra, A., and R \'e , C. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in neural information processing systems, 35: 0 16344--16359, 2022
2022
-
[63]
In-place test-time training
Feng, G., Luo, S., Hua, K., Zhang, G., Huang, W., He, D., and Cai, T. In-place test-time training. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=dTWfCLSoyl
2026
-
[64]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The P ile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020
work page internal anchor Pith review arXiv 2020
-
[65]
Causal abstractions of neural networks
Geiger, A., Lu, H., Icard, T., and Potts, C. Causal abstractions of neural networks. Advances in Neural Information Processing Systems, 34: 0 9574--9586, 2021
2021
-
[66]
Finding alignments between interpretable causal variables and distributed neural representations
Geiger, A., Wu, Z., Potts, C., Icard, T., and Goodman, N. Finding alignments between interpretable causal variables and distributed neural representations. In Causal Learning and Reasoning, pp.\ 160--187. PMLR, 2024
2024
-
[67]
SAMS um Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization
Gliwa, B., Mochol, I., Biesek, M., and Wawer, A. SAMS um corpus: A human-annotated dialogue dataset for abstractive summarization. In Proceedings of the 2nd Workshop on New Frontiers in Summarization, pp.\ 70--79, Hong Kong, China, November 2019. Association for Computational Linguistics. doi:10.18653/v1/D19-5409. URL https://www.aclweb.org/anthology/D19-5409
-
[68]
and Dao, T
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. In First conference on language modeling, 2024
2024
-
[69]
Combining recurrent, convolutional, and continuous-time models with linear state space layers
Gu, A., Johnson, I., Goel, K., Saab, K., Dao, T., Rudra, A., and R \'e , C. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Advances in neural information processing systems, 34: 0 572--585, 2021
2021
-
[70]
RULER : What s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., and Ginsburg, B. RULER : What s the real context size of your long-context language models? In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=kIoBbc76Sy
2024
-
[71]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al. Lora: Low-rank adaptation of large language models. ICLR, 1 0 (2): 0 3, 2022
2022
-
[72]
E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K
Jimenez, C. E., Yang, J., Wettig, A., Yao, S., Pei, K., Press, O., and Narasimhan, K. R. SWE -bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=VTF8yNQM66
2024
-
[73]
Transformers are rnns: Fast autoregressive transformers with linear attention
Katharopoulos, A., Vyas, A., Pappas, N., and Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In International conference on machine learning, pp.\ 5156--5165. PMLR, 2020
2020
-
[74]
Ringattention with blockwise transformers for near-infinite context
Liu, H., Zaharia, M., and Abbeel, P. Ringattention with blockwise transformers for near-infinite context. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WsRHpHH4s0
2024
-
[75]
and Hutter, F
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7
2019
-
[76]
The illusion of state in state-space models
Merrill, W., Petty, J., and Sabharwal, A. The illusion of state in state-space models. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=QZgo9JZpLq
2024
-
[77]
Learning to compress prompts with gist tokens
Mu, J., Li, X., and Goodman, N. Learning to compress prompts with gist tokens. Advances in Neural Information Processing Systems, 36: 0 19327--19352, 2023
2023
-
[78]
S., O'Brien, J., Cai, C
Park, J. S., O'Brien, J., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pp.\ 1--22, 2023
2023
-
[79]
RWKV: Reinventing RNNs for the Transformer Era
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., et al. Rwkv: Reinventing rnns for the transformer era. arXiv preprint arXiv:2305.13048, 2023
work page internal anchor Pith review arXiv 2023
-
[80]
R., Kalchbrenner, N., Goyal, A., and Bengio, Y
Sch \"o lkopf, B., Locatello, F., Bauer, S., Ke, N. R., Kalchbrenner, N., Goyal, A., and Bengio, Y. Toward causal representation learning. Proceedings of the IEEE, 109 0 (5): 0 612--634, 2021
2021
-
[81]
Bleurt: Learning robust metrics for text generation
Sellam, T., Das, D., and Parikh, A. Bleurt: Learning robust metrics for text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2020
2020
-
[82]
Learning to (learn at test time): RNN s with expressive hidden states
Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T., and Guestrin, C. Learning to (learn at test time): RNN s with expressive hidden states. In Forty-second International Conference on Machine Learning, 2025. URL https://openreview.net/forum?id=wXfuOj9C7L
2025
-
[83]
The information bottleneck method
Tishby, N., Pereira, F. C., and Bialek, W. The information bottleneck method. arXiv preprint physics/0004057, 2000
work page Pith review arXiv 2000
-
[84]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozi \`e re, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[85]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[86]
A survey on large language model based autonomous agents
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., et al. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18 0 (6): 0 186345, 2024
2024
-
[87]
J., and LeCun, Y
Zhang, X., Zhao, J. J., and LeCun, Y. Character-level convolutional networks for text classification. In NIPS, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.