Recognition: unknown
VLAA-GUI: Knowing When to Stop, Recover, and Search, A Modular Framework for GUI Automation
Pith reviewed 2026-05-09 22:21 UTC · model grok-4.3
The pith
VLAA-GUI equips GUI agents with a verifier for task completion, a loop breaker for recovery, and a search agent for new workflows to avoid early false stops and repetitive failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
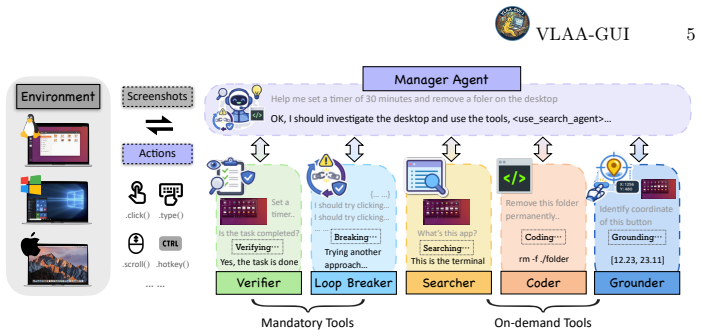
VLAA-GUI is a modular framework built around three mandatory components that tell an agent when to stop, recover, and search. The Completeness Verifier enforces UI-observable success criteria at every proposed finish step and rejects claims lacking direct visual evidence. The Loop Breaker applies multi-tier rules that change interaction mode after repeated failures, force strategy shifts after persistent screen states, and tie reflection to action changes. An on-demand Search Agent queries a capable LLM for unfamiliar workflows and returns results as plain text, while optional Coding and Grounding Agents are invoked only when needed. When added to five top backbones and tested on OSWorld and
What carries the argument
The VLAA-GUI modular framework whose three core components (Completeness Verifier, Loop Breaker, and Search Agent) enforce stopping rules, recovery from repetition, and external knowledge lookup.
If this is right
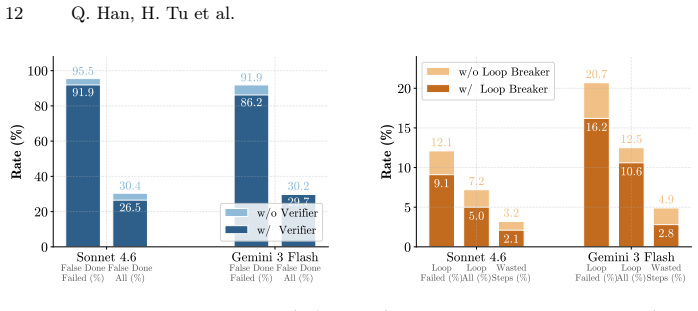
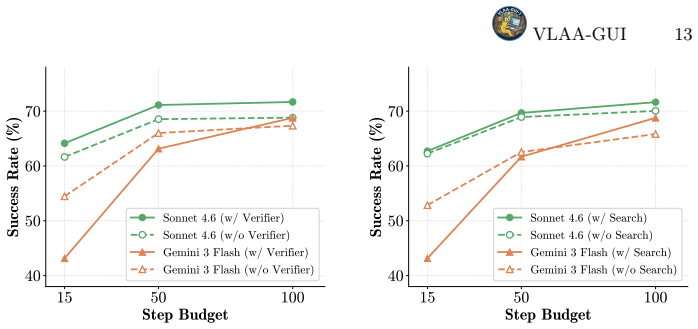
- All three components improve performance on both strong and weaker backbone models.
- Weaker backbones gain more when the step budget is large enough to use the recovery and search tools.
- The Loop Breaker cuts wasted steps by nearly half for models that tend to loop.
- Three of the five tested backbones surpass the reported human performance level on OSWorld in a single pass.
- The same framework works across both Linux and Windows task environments.
Where Pith is reading between the lines
- The same stop-recover-search pattern could be added to agents that control web browsers or mobile apps rather than desktop GUIs.
- Making the search agent optional and text-based lowers the barrier for adding external knowledge without retraining the base model.
- Strong emphasis on visible evidence of success may reduce the need for human review in deployed automation systems.
- Weaker models paired with these tools might close the gap with stronger models on step-limited tasks.
Load-bearing premise
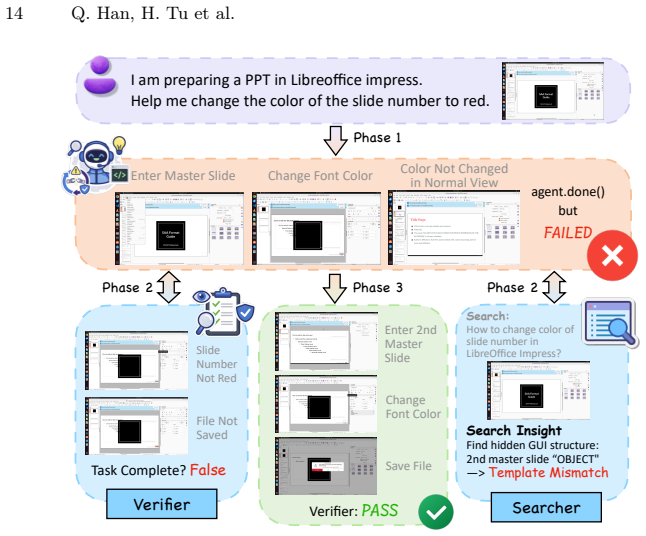
That reliable UI-observable success criteria exist for most real-world GUI tasks and can be checked by the verifier without rejecting valid completions or becoming overly conservative.
What would settle it
Run the Completeness Verifier on a new collection of GUI tasks whose end states have ambiguous visual signals and measure whether it falsely rejects more than a small fraction of actually completed runs.
Figures

read the original abstract
Autonomous GUI agents face two fundamental challenges: early stopping, where agents prematurely declare success without verifiable evidence, and repetitive loops, where agents cycle through the same failing actions without recovery. We present VLAA-GUI, a modular GUI agentic framework built around three integrated components that guide the system on when to Stop, Recover, and Search. First, a mandatory Completeness Verifier enforces UI-observable success criteria and verification at every finish step -- with an agent-level verifier that cross-examines completion claims with decision rules, rejecting those lacking direct visual evidence. Second, a mandatory Loop Breaker provides multi-tier filtering: switching interaction mode after repeated failures, forcing strategy changes after persistent screen-state recurrence, and binding reflection signals to strategy shifts. Third, an on-demand Search Agent searches online for unfamiliar workflows by directly querying a capable LLM with search ability, returning results as plain text. We additionally integrate a Coding Agent for code-intensive actions and a Grounding Agent for precise action grounding, both invoked on demand when required. We evaluate VLAA-GUI across five top-tier backbones, including Opus 4.5, 4.6 and Gemini 3.1 Pro, on two benchmarks with Linux and Windows tasks, achieving top performance on both (77.5% on OSWorld and 61.0% on WindowsAgentArena). Notably, three of the five backbones surpass human performance (72.4%) on OSWorld in a single pass. Ablation studies show that all three proposed components consistently improve a strong backbone, while a weaker backbone benefits more from these tools when the step budget is sufficient. Further analysis also shows that the Loop Breaker nearly halves wasted steps for loop-prone models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VLAA-GUI, a modular framework for GUI agents that addresses premature stopping and repetitive loops via three core components: a Completeness Verifier enforcing mandatory UI-observable success criteria with agent-level cross-examination, a Loop Breaker using multi-tier rules for mode switching and strategy changes, and an on-demand Search Agent for querying LLMs on unfamiliar workflows. It also incorporates optional Coding and Grounding Agents. Evaluations across five LLM backbones on OSWorld and WindowsAgentArena benchmarks report top results of 77.5% and 61.0%, with three backbones exceeding the 72.4% human baseline on OSWorld in single-pass settings; ablations indicate consistent gains from all components, with greater benefits for weaker backbones under sufficient step budgets and the Loop Breaker halving wasted steps for loop-prone models.
Significance. If the results hold under rigorous verification, the work provides a practical, backbone-agnostic engineering contribution to reliable GUI automation by directly targeting two common failure modes. Strengths include the multi-backbone evaluation on both Linux and Windows tasks, ablation studies demonstrating component-level improvements, and the explicit reduction in wasted steps, which together offer reproducible evidence for the framework's utility beyond single-model experiments.
major comments (3)
- [Abstract] Abstract and Evaluation section: The headline performance claims (77.5% on OSWorld, three backbones >72.4% human) and component benefits are presented without error bars, statistical significance tests, or quantitative failure-case breakdowns, which weakens the ability to assess whether gains are robust or sensitive to implementation choices.
- [Completeness Verifier] Completeness Verifier description: The claim that the verifier enforces 'UI-observable success criteria' and 'rejects those lacking direct visual evidence' via agent-level cross-examination is load-bearing for the early-stopping solution, yet the manuscript provides insufficient detail on exact decision rules, prompting templates, or thresholds; without this, it is unclear whether criteria are general or inadvertently benchmark-tuned, directly affecting comparability to human baselines and standard task-completion protocols.
- [Ablation studies] Ablation studies and Loop Breaker section: The statement that the Loop Breaker 'nearly halves wasted steps' and that weaker backbones benefit more 'when the step budget is sufficient' requires explicit reporting of the step budgets tested, per-component delta metrics, and the precise multi-tier filtering rules to substantiate the recovery and efficiency claims.
minor comments (2)
- [Abstract] Clarify the exact measurement protocol for the 72.4% human baseline on OSWorld to ensure apples-to-apples comparison with the single-pass agent results.
- [Search Agent] The integration details for the on-demand Search Agent (how queries are formulated and plain-text results are parsed into actions) could be expanded for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing honest responses and indicating revisions where the manuscript will be updated to improve clarity, reproducibility, and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and Evaluation section: The headline performance claims (77.5% on OSWorld, three backbones >72.4% human) and component benefits are presented without error bars, statistical significance tests, or quantitative failure-case breakdowns, which weakens the ability to assess whether gains are robust or sensitive to implementation choices.
Authors: We agree that the lack of error bars, statistical tests, and failure breakdowns limits assessment of robustness. In the revised manuscript, we will add error bars from repeated runs where feasible given computational costs, include a quantitative failure-case breakdown in the Evaluation section, and report statistical significance for key comparisons. We note that single-run evaluations are common in this domain due to expense, but the multi-backbone consistency provides supporting evidence; full multi-run statistics across all settings will be added where possible. revision: partial
-
Referee: [Completeness Verifier] Completeness Verifier description: The claim that the verifier enforces 'UI-observable success criteria' and 'rejects those lacking direct visual evidence' via agent-level cross-examination is load-bearing for the early-stopping solution, yet the manuscript provides insufficient detail on exact decision rules, prompting templates, or thresholds; without this, it is unclear whether criteria are general or inadvertently benchmark-tuned, directly affecting comparability to human baselines and standard task-completion protocols.
Authors: The referee is correct that insufficient detail on decision rules, prompts, and thresholds reduces clarity and raises questions about generality. We will expand the Completeness Verifier section in the revision to include the exact decision rules, full prompting templates for cross-examination, and thresholds. We will also clarify that the criteria rely on general UI-observable elements rather than benchmark-specific tuning, improving comparability to human baselines. revision: yes
-
Referee: [Ablation studies] Ablation studies and Loop Breaker section: The statement that the Loop Breaker 'nearly halves wasted steps' and that weaker backbones benefit more 'when the step budget is sufficient' requires explicit reporting of the step budgets tested, per-component delta metrics, and the precise multi-tier filtering rules to substantiate the recovery and efficiency claims.
Authors: We acknowledge that the current description lacks the required specificity on step budgets, deltas, and rules. In the revised manuscript, we will explicitly report the step budgets tested, add tables with per-component delta metrics, and detail the precise multi-tier filtering rules (including pseudocode or examples) in the Loop Breaker and Ablation sections to substantiate the claims on wasted steps and differential benefits. revision: yes
Circularity Check
No significant circularity: empirical framework on external benchmarks
full rationale
The paper describes a modular empirical framework (VLAA-GUI) with three components for GUI agents, evaluated directly on public external benchmarks (OSWorld, WindowsAgentArena) using standard success rates and human baselines. No equations, derivations, fitted parameters, or self-referential reductions appear; performance numbers (e.g., 77.5% OSWorld) are reported as measured outcomes against independent backbones and tasks rather than constructed from prior author-defined quantities. Ablations compare component contributions on the same external setups without circular fitting. The work is self-contained against external benchmarks with no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs possess sufficient search and reflection capabilities to power the Search Agent and Loop Breaker when given appropriate prompts
invented entities (3)
-
Completeness Verifier
no independent evidence
-
Loop Breaker
no independent evidence
-
Search Agent
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2410.08164 , year =
Agashe,S.,Han,J.,Gan,S.,Yang,J.,Li,A.,Wang,X.E.:AgentS:Anopenagentic framework that uses computers like a human. arXiv preprint arXiv:2410.08164 (2024)
-
[2]
Agashe, S., Wong, K., Tu, V., Yang, J., Li, A., Wang, X.E.: Agent S2: A com- positional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906 (2025)
-
[3]
Andrade, T., et al.: Self-grounded verification: Detecting hallucinations and bias in MLLM GUI agents. arXiv preprint arXiv:2507.11662 (2025)
-
[4]
anthropic
Anthropic: Developing computer use.https : / / www . anthropic . com / news / developing-computer-use(2024)
2024
-
[5]
Anthropic: Claude opus 4.5.https://www.anthropic.com/news/claude-opus-4- 5(2025)
2025
-
[6]
anthropic
Anthropic: Claude sonnet 4.6.https : / / www . anthropic . com / news / claude - sonnet-4-6(2025)
2025
-
[7]
com/news/claude-sonnet-4-5
Anthropic: Introducing claude sonnet 4.5 (Sep 2025),https://www.anthropic. com/news/claude-sonnet-4-5
2025
-
[8]
Anthropic: Claude opus 4.6.https://www.anthropic.com/news/claude-opus-4- 6(2026)
2026
-
[9]
Screenai: A vision-language model for ui and infographics understanding
Baechler, G., Narayanan, S., et al.: ScreenAI: A vision-language model for UI and infographics understanding. arXiv preprint arXiv:2402.04615 (2024)
-
[10]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Bonatti, R., Zhao, D., Bonacci, F., Dupont, D., Abdali, S., Li, Y., Lu, Y., Wagle, J., Koishida, K., Bucker, A., Jang, L., Hui, Z.: Windows agent arena: Evaluating multi-modal OS agents at scale. arXiv preprint arXiv:2409.08264 (2024)
-
[12]
ByteDance Seed Team: Seed1.8 model card: Towards generalized real-world agency (2025)
2025
- [13]
-
[14]
Why Do Multi-Agent LLM Systems Fail?
Cemri, M., et al.: Why do multi-agent LLM systems fail? a taxonomy of failure patterns in multi-agent LLM systems. arXiv preprint arXiv:2503.13657 (2025)
work page internal anchor Pith review arXiv 2025
-
[15]
arXiv preprint arXiv:2501.01149 (2025)
Chai, Y., et al.: A3: Android agent arena for mobile GUI agents. arXiv preprint arXiv:2501.01149 (2025)
-
[16]
Transactions on Machine Learning Research (2025)
Chen, H., Tu, H., Wang, F., Liu, H., Tang, X., Du, X., Zhou, Y., Xie, C.: Sft or rl? an early investigation into training r1-like reasoning large vision-language models. Transactions on Machine Learning Research (2025)
2025
-
[17]
arXiv preprint arXiv:2602.07008 (2026) VLAA-GUI 17
Chen, R., Sun, S., Guo, X., Zhang, S., Liu, K., Liu, S., Wang, Z., Zhang, Q., Zhang, H., Cao, X.: Where not to learn: Prior-aligned training with subset-based attri- bution constraints for reliable decision-making. arXiv preprint arXiv:2602.07008 (2026) VLAA-GUI 17
-
[18]
Cheng, K., Sun, Q., Chu, Y., Xu, F., Li, Y., Zhang, J., Wu, Z.: SeeClick: Harnessing GUI grounding for advanced visual GUI agents. arXiv preprint arXiv:2401.10935 (2024)
-
[19]
The BrowserGym ecosystem for web agent research.arXiv preprint arXiv:2412.05467,
Chezelles, T.L.S.D., Acero, J., et al.: The BrowserGym ecosystem for web agent research. arXiv preprint arXiv:2412.05467 (2024)
-
[20]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., Schulman, J.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Deka, B., Huang, Z., Franzen, C., Hibschman, J., Afergan, D., Li, Y., Nichols, J., Kumar, R.: Rico: A mobile app dataset for building data-driven design applica- tions. In: UIST. pp. 845–854 (2017).https://doi.org/10.1145/3126594.3126651
-
[22]
In: NeurIPS (2024)
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2web: Towards a generalist agent for the web. In: NeurIPS (2024)
2024
-
[23]
Workarena++: Towards compositional planning and reasoning-based common knowledge work tasks, 2025
Drouin, A., Porlier, R., et al.: WorkArena++: Benchmarking web agents with agentic and procedural knowledge. arXiv preprint arXiv:2407.05291 (2024)
-
[24]
Drouin, A., Porlier, R., et al.: WorkArena: How capable are web agents at solving common knowledge work tasks? arXiv preprint arXiv:2403.07718 (2024)
work page internal anchor Pith review arXiv 2024
-
[25]
Fu, T., Su, A., Zhao, C., Wang, H., Wu, M., Yu, Z., Hu, F., Shi, M., Dong, W., Wang, J., Chen, Y., Yu, R., Peng, S., Li, M., Huang, N., Wei, H., Yu, J., Xin, Y., Zhao, X., Gu, K., Jiang, P., Zhou, S., Wang, S.: Mano technical report. arXiv preprint arXiv:2509.17336 (2025)
-
[26]
Gonzalez-Pumariega, G., Tu, V., Lee, C.L., Yang, J., Li, A., Wang, X.E.: The unreasonable effectiveness of scaling agents for computer use. arXiv preprint arXiv:2510.02250 (2025)
-
[27]
com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf(2025)
Google DeepMind: Gemini 3 flash model card.https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf(2025)
2025
-
[28]
Google DeepMind: Gemini 3 pro model card.https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf(2025)
2025
-
[29]
com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf(2026)
Google DeepMind: Gemini 3.1 pro model card.https://storage.googleapis. com/deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf(2026)
2026
-
[30]
Gur, I., Furuta, H., Huang, A., Safdari, M., Matsuo, Y., Eck, D., Faust, A.: A real-world WebAgent with planning, long context understanding, and program synthesis. arXiv preprint arXiv:2307.12856 (2024)
-
[31]
HCIII Team, Lenovo: Hippo agent.https://github.com/wadang/muscle- mem- agent(2026)
2026
-
[32]
Webvoyager: Building an end-to-end web agent with large multimodal models,
He, Z., Choi, J., et al.: WebVoyager: Building an end-to-end web agent with large multimodal models. arXiv preprint arXiv:2401.13919 (2024)
-
[33]
In: CVPR (2024)
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., Tang, J.: CogAgent: A visual language model for GUI agents. In: CVPR (2024)
2024
-
[34]
Kapoor, R., Lu, K., et al.: OmniACT: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. arXiv preprint arXiv:2402.17553 (2024)
-
[35]
Siegel, Nitya Nadgir, and Arvind Narayanan
Kapoor, S., Stroebl, B., Siegel, Z.S., Rajkumar, N., Narayanan, A.: AI agents that matter. arXiv preprint arXiv:2407.01502 (2024)
-
[36]
Language models can solve computer tasks
Kim, G., Petit, P., Toshev, A., Park, T., Zisserman, A., Mao, C., Ibarz, J., Batra, D., Wu, T., Tian, Y.: Language models can solve computer tasks. arXiv preprint arXiv:2303.17491 (2023)
-
[37]
Lee, T., Tu, H., Wong, C.H., Zheng, W., Zhou, Y., Mai, Y., Roberts, J.S., Ya- sunaga, M., Yao, H., Xie, C., et al.: Vhelm: A holistic evaluation of vision language 18 Q. Han, H. Tu et al. models. Advances in Neural Information Processing Systems37, 140632–140666 (2024)
2024
-
[38]
A Zero-Shot Language Agent for Computer Control with Structured Reflection
Li, T., Azizi, D., Papusha, I., Angelopoulos, A.N., Yang, D.: A zero-shot lan- guage agent for computer control with structured reflection. arXiv preprint arXiv:2310.08740 (2023)
-
[39]
In: ICLR (2024)
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. In: ICLR (2024)
2024
-
[40]
doi:10.48550/arXiv.2411.17465 , author =
Lin, K.Q., Li, L., Gao, D., Yang, Z., Wu, S., Bai, Z., Lei, W., Wang, L., Shou, M.Z.: ShowUI: One vision-language-action model for GUI visual agent. arXiv preprint arXiv:2411.17465 (2024)
-
[41]
Liu, E.Z., Guu, K., Pasupat, P., Shi, T., Liang, P.: Reinforcement learning on web interfaces using workflow-guided exploration. arXiv preprint arXiv:1802.08802 (2018)
-
[42]
Autoglm: Autonomous foundation agents for guis.arXiv preprint arXiv:2411.00820, 2024
Liu, X., Qin, B., Liang, D., et al.: AutoGLM: Autonomous foundation agents for GUIs. arXiv preprint arXiv:2411.00820 (2024)
-
[43]
Lu, X., Meng, C., et al.: WebLINX: Real-world website navigation with multi-turn dialogue. arXiv preprint arXiv:2402.05930 (2024)
-
[44]
In: NeurIPS (2023)
Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., Gupta, S., Majumder, B.P., Hermann, K., Welleck, S., Yazdanbakhsh, A., Clark, P.: Self-refine: Iterative refinement with self-feedback. In: NeurIPS (2023)
2023
-
[45]
Screenagent: A vision language model-driven computer control agent
Niu, R., Sharma, Y., Goyal, P., Majumdar, A., et al.: ScreenAgent: A vision language model-driven computer control agent. arXiv preprint arXiv:2402.07945 (2024)
-
[46]
arXiv preprint arXiv:1602.02261 (2016)
Nogueira, R., Cho, K.: End-to-end goal-driven web navigation. arXiv preprint arXiv:1602.02261 (2016)
-
[47]
com / index / introducing - operator(2025)
OpenAI: Introducing operator.https : / / openai . com / index / introducing - operator(2025)
2025
-
[48]
In: COLM (2024)
Pan, J., Zhang, Y., Tomlin, N., Zhou, Y., Levine, S., Suhr, A.: Autonomous eval- uation and refinement of digital agents. In: COLM (2024)
2024
-
[49]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., Zhong, W., Li, K., Li, J., Li, C., Niu, M., Zhang, C., Zheng, Y., Qin, S., Lu, Q., Tang, R., Rajmohan, S., Lin, Q., Zhang, D.: UI-TARS: Pioneering automated GUI interaction with native agents. arXiv preprint arXiv:2501.12326 (2025)
work page Pith review arXiv 2025
-
[50]
Android in the wild: A large-scale dataset for android device control
Rawles, C., et al.: Android in the wild: A large-scale dataset for android device control. arXiv preprint arXiv:2307.10088 (2023)
-
[51]
AndroidWorld: A Dynamic Benchmarking Environment for Autonomous Agents
Rawles, C., Clinckemaillie, S., Chang, Y., Walber, J., Toyama, D.: AndroidWorld: A dynamic benchmarking environment for autonomous agents. arXiv preprint arXiv:2405.14573 (2024)
work page internal anchor Pith review arXiv 2024
-
[52]
In: ICML
Shi, T., Karpathy, A., Fan, L., Hernandez, J., Liang, P.: World of bits: An open- source platform for web-based agents. In: ICML. pp. 3135–3144 (2017)
2017
-
[53]
In: NeurIPS (2023)
Shinn,N.,Cassano,F.,Gopinath,A.,Narasimhan,K.,Yao,S.:Reflexion:Language agents with verbal reinforcement learning. In: NeurIPS (2023)
2023
-
[54]
arXiv preprint arXiv:2401.13649 , year=
Singh, A., Yang, J., Sriram, A., et al.: VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. arXiv preprint arXiv:2401.13649 (2024)
-
[55]
arXiv preprint arXiv:2503.00yset (2025)
Song, L., Dai, Y., Prabhu, V., Zhang, J., Shi, T., Li, L., Li, J., Savarese, S., Chen, Z., Zhao, J., Xu, R., Xiong, C.: CoAct-1: Computer-using agents with coding as actions. arXiv preprint arXiv:2503.00yset (2025)
2025
-
[56]
Cradle: Empowering foundation agents towards general computer control,
Tan, W., Zhang, W., et al.: Cradle: Empowering foundation agents towards general computer control. arXiv preprint arXiv:2403.03186 (2024) VLAA-GUI 19
-
[57]
Kimi K2.5: Visual Agentic Intelligence
Team, K., Bai, T., Bai, Y., Bao, Y., Cai, S.H., Cao, Y., Charles, Y., Che, H.S., Chen, C., Chen, G., Chen, H., Chen, J., Chen, J., Chen, J., Chen, J., Chen, K., Chen, L., Chen, R., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Y., Chen, Z., Chen, Z., Cheng, D., Chu, M., Cui, J., Deng, J., Diao, M., Ding, H., Dong, M., Dong, M...
work page internal anchor Pith review arXiv 2026
-
[58]
In: European Conference on Computer Vision
Tu, H., Cui, C., Wang, Z., Zhou, Y., Zhao, B., Han, J., Zhou, W., Yao, H., Xie, C.: How many are in this image a safety evaluation benchmark for vision llms. In: European Conference on Computer Vision. pp. 37–55. Springer (2024)
2024
-
[59]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Tu, H., Feng, W., Chen, H., Liu, H., Tang, X., Xie, C.: Vilbench: A suite for vision-language process reward modeling. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 6775–6790 (2025)
2025
-
[60]
UiPath: Uipath screen agent.https://github.com/xlang- ai/OSWorld/tree/ main/mm_agents/uipath(2025)
2025
-
[61]
Wang, H., Zou, H., Song, H., Feng, J., Fang, J., Lu, J., Liu, L., Luo, Q., Liang, S., Huang, S., Zhong, W., Ye, Y., Qin, Y., Xiong, Y., Song, Y., Wu, Z., Li, A., Li, B., Dun, C., Liu, C., Zan, D., Leng, F., Wang, H., Yu, H., Chen, H., Guo, H., Su, J., Huang, J., Shen, K., Shi, K., Yan, L., Zhao, P., Liu, P., Ye, Q., Zheng, 20 Q. Han, H. Tu et al. R., Xin,...
work page internal anchor Pith review arXiv 2025
-
[62]
Wang, J., Mo, H., Ishii, E., et al.: Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158 (2024)
-
[63]
Frontiers of Computer Science (2024)
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., Chen, Z., Tang, J., Chen, X., Lin, Y., Zhao, W.X., Wei, Z., Wen, J.R.: A survey on large language model based autonomous agents. Frontiers of Computer Science (2024)
2024
-
[64]
In: ICML (2024)
Wang, X., Chen, Y., Yuan, L., Zhang, Y., Li, Y., Peng, H., Ji, H.: Executable code actions elicit better LLM agents. In: ICML (2024)
2024
-
[65]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Wang, X., Wang, B., Lu, D., Yang, J., Xie, T., Wang, J., Deng, J., Guo, X., Xu, Y., Wu, C.H., Shen, Z., Li, Z., Li, R., Li, X., Chen, J., Zheng, B., Li, P., Lei, F., Cao, R., Fu, Y., Shin, D., Shin, M., Hu, J., Wang, Y., Chen, J., Ye, Y., Zhang, D., Du, D., Hu, H., Chen, H., Zhou, Z., Yao, H., Chen, Z., Gu, Q., Wang, Y., Wang, H., Yang, D., Zhong, V., Sun...
-
[66]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Wu, Z., Wu, Z., Xu, F., Wang, Y., Sun, Q., Jia, C., Cheng, K., Ding, Z., Chen, L., Liang, P.P., Qiao, Y.: OS-Atlas: A foundation action model for generalist GUI agents. arXiv preprint arXiv:2410.23218 (2024)
work page internal anchor Pith review arXiv 2024
-
[67]
In: NeurIPS (2024)
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. In: NeurIPS (2024)
2024
-
[68]
Xu, Y., Wang, Z., Wang, J., Lu, D., Xie, T., Saha, A., Sahoo, D., Yu, T., Xiong, C.: Aguvis: Unified pure vision agents for autonomous GUI interaction. arXiv preprint arXiv:2412.04454 (2024)
-
[69]
Xue, T., Peng, C., Huang, M., Guo, L., Han, T., Wang, H., Wang, J., Zhang, X., Yang, X., Zhao, D., Ding, J., Ma, X., Xie, Y., Pei, P., Cai, X., Qiu, X.: EvoCUA: Evolving computer use agents via learning from scalable synthetic experience. arXiv preprint arXiv:2601.15876 (2026)
-
[70]
Yang, B., Jin, K., Wu, Z., Liu, Z., Sun, Q., Li, Z., Xie, J., Liu, Z., Xu, F., Cheng, K., Li,Q.,Wang,Y.,Qiao,Y.,Wang,Z.,Ding,Z.:OS-Symphony:Aholisticframework for robust and generalist computer-using agent. arXiv preprint arXiv:2601.07779 (2026)
-
[71]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
Yang, J., Jimenez, C.E., Wettig, A., Lieret, K., Yao, S., Narasimhan, K., Press, O.: SWE-agent: Agent-computer interfaces enable automated software engineering. arXiv preprint arXiv:2405.15793 (2024)
work page internal anchor Pith review arXiv 2024
-
[72]
Yang, P., Ci, H., Shou, M.Z.: macOSWorld: A multilingual interactive benchmark for GUI agents. arXiv preprint arXiv:2506.04135 (2025)
-
[73]
Yang, Y., Li, D., Dai, Y., Yang, Y., Luo, Z., Zhao, Z., Hu, Z., Huang, J., Saha, A., Chen, Z., et al.: GTA1: GUI test-time scaling agent. arXiv preprint arXiv:2507.05791 (2025) VLAA-GUI 21
-
[74]
Aria-ui: Visual grounding for gui instruc- tions.arXiv preprint arXiv:2412.16256, 2024
Yang, Y., Wang, Y., Li, D., Luo, Z., Chen, B., Huang, C., Li, J.: Aria-UI: Visual grounding for GUI instructions. arXiv preprint arXiv:2412.16256 (2024)
-
[75]
In: NeurIPS (2022)
Yao, S., Chen, H., Yang, J., et al.: WebShop: Towards scalable real-world web interaction with grounded language agents. In: NeurIPS (2022)
2022
-
[76]
In: NeurIPS (2023)
Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T.L., Cao, Y., Narasimhan, K.: Tree of thoughts: Deliberate problem solving with large language models. In: NeurIPS (2023)
2023
-
[77]
In: ICLR (2023)
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., Cao, Y.: ReAct: Synergizing reasoning and acting in language models. In: ICLR (2023)
2023
- [78]
-
[79]
Large language model-brained gui agents: A survey,
Zhang, C., He, S., Li, L., Li, S., Qian, Y., Wang, Y., Ma, M., Kang, Y., Lin, Q., Rajmohan, S., et al.: LLM-brained GUI agents: A survey. arXiv preprint arXiv:2411.18279 (2024)
-
[80]
arXiv preprint arXiv:2402.07939 , year=
Zhang, C., Li, L., He, S., Zhang, X., Qiao, B., Qin, S., Ma, M., Kang, Y., Lin, Q., Rajmohan, S., et al.: UFO: A UI-focused agent for windows OS interaction. arXiv preprint arXiv:2402.07939 (2024)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.