Recognition: unknown
Conjecture and Inquiry: Quantifying Software Performance Requirements via Interactive Retrieval-Augmented Preference Elicitation
Pith reviewed 2026-05-09 21:16 UTC · model grok-4.3
The pith
IRAP turns vague natural language performance requirements into accurate mathematical functions by retrieving problem-specific knowledge and guiding short stakeholder interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
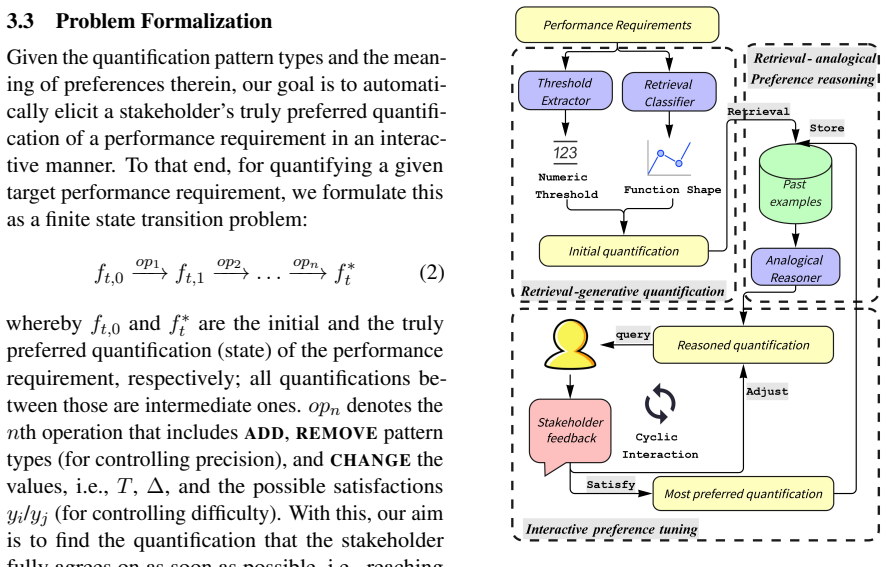
The paper states that quantifying performance requirements requires explicit handling of ambiguity through a process of conjecture and inquiry. IRAP achieves this by retrieving and reasoning over problem-specific knowledge to inform preference elicitation, which in turn directs progressive interactions with stakeholders. The retrieved knowledge both grounds the reasoning and reduces cognitive overhead for participants. This leads to mathematical functions that more accurately represent the intended performance behavior. The method is shown to outperform prior approaches across multiple real-world cases.
What carries the argument
IRAP, the interactive retrieval-augmented preference elicitation method that derives from problem-specific knowledge retrieval to reason preferences and direct stakeholder interactions toward mathematical performance functions.
If this is right
- Accurate quantification becomes feasible with as few as five rounds of interaction.
- The approach yields up to 40 times better results than ten existing methods on four real-world datasets.
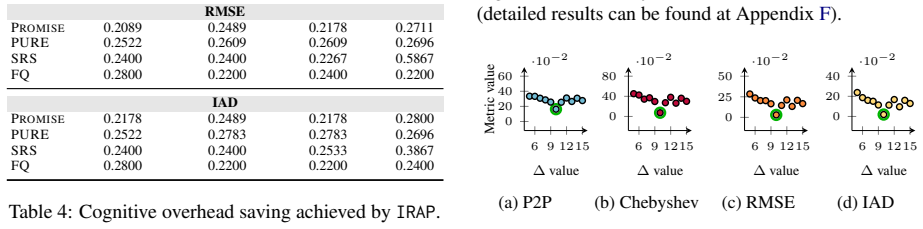
- Cognitive load on stakeholders decreases because retrieved knowledge guides the questions asked.
- The method generalizes across different performance requirement scenarios in software engineering.
Where Pith is reading between the lines
- The same knowledge-retrieval-plus-interaction pattern could extend to quantifying other ambiguous requirements such as security or usability constraints.
- Embedding IRAP outputs directly into performance testing pipelines might enable automatic validation loops.
- Industry adoption could allow teams without deep performance expertise to produce usable specifications.
- Testing the method on requirements for very large or distributed systems would reveal whether the interaction count stays low at scale.
Load-bearing premise
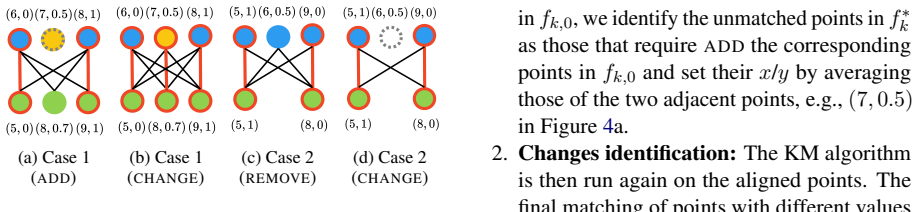
That retrieving and applying problem-specific knowledge during short interactions can convert ambiguous natural language requirements into correct mathematical functions without introducing new interpretation errors or excessive demands on users.
What would settle it
Run IRAP on a new set of documented performance requirements, then measure actual system performance against the output functions and check whether the functions predict behavior within acceptable error margins.
Figures




read the original abstract
Since software performance requirements are documented in natural language, quantifying them into mathematical forms is essential for software engineering. Yet, the vagueness in performance requirements and uncertainty of human cognition have caused highly uncertain ambiguity in the interpretations, rendering their automated quantification an unaddressed and challenging problem. In this paper, we formalize the problem and propose IRAP, an approach that quantifies performance requirements into mathematical functions via interactive retrieval-augmented preference elicitation. IRAP differs from the others in that it explicitly derives from problem-specific knowledge to retrieve and reason the preferences, which also guides the progressive interaction with stakeholders, while reducing the cognitive overhead. Experiment results against 10 state-of-the-art methods on four real-world datasets demonstrate the superiority of IRAP on all cases with up to 40x improvements under as few as five rounds of interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes quantifying vague natural-language software performance requirements into mathematical functions as an open problem due to interpretation ambiguity and human uncertainty. It proposes IRAP, an interactive retrieval-augmented preference elicitation method that retrieves and reasons over problem-specific knowledge to guide progressive stakeholder interactions while aiming to reduce cognitive load. The central claim is that IRAP outperforms 10 state-of-the-art methods on four real-world datasets, achieving up to 40x improvements with as few as five interaction rounds.
Significance. If the empirical superiority holds under controlled conditions, the work addresses a practically important gap in software requirements engineering by offering a low-interaction method to convert ambiguous performance specs into usable mathematical forms. The combination of external knowledge retrieval with preference elicitation could improve accuracy and interpretability over purely automated or purely interactive baselines. No machine-checked proofs or fully reproducible artifacts are described, but the focus on real-world datasets and limited interaction rounds is a positive direction if the attribution of gains is clarified.
major comments (2)
- [Abstract] Abstract: The claim that 'experiment results against 10 state-of-the-art methods on four real-world datasets demonstrate the superiority of IRAP on all cases with up to 40x improvements' supplies no details on the performance metric, dataset sizes/characteristics, statistical tests, or controls, making it impossible to assess whether the data support the stated superiority (soundness concern).
- [Experiments] Experiments section (results description): It is not stated whether the 10 baseline methods received equivalent interaction budgets or stakeholder preference input. If baselines are non-interactive (standard for automated quantification), the reported gains may be attributable primarily to the progressive elicitation step rather than the retrieval-augmented preference modeling, directly threatening the central claim that IRAP's distinctive components drive the improvements.
minor comments (1)
- [Abstract] Abstract: The phrases 'explicitly derives from problem-specific knowledge to retrieve and reason the preferences' and 'reducing the cognitive overhead' are high-level; a brief outline of the retrieval mechanism, preference model, and interaction protocol would improve clarity and reproducibility without altering the core contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and experiments. We address the two major comments point by point below and have made revisions to improve clarity and experimental transparency.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'experiment results against 10 state-of-the-art methods on four real-world datasets demonstrate the superiority of IRAP on all cases with up to 40x improvements' supplies no details on the performance metric, dataset sizes/characteristics, statistical tests, or controls, making it impossible to assess whether the data support the stated superiority (soundness concern).
Authors: We agree that the abstract would benefit from greater transparency to allow readers to evaluate the claims. In the revised version we have expanded the abstract to briefly indicate the evaluation metric (quantification error against ground-truth functions), note the real-world dataset characteristics and sizes, and state that results are reported with statistical significance testing. The full experimental protocol, controls, and dataset details remain in Section 5, but the abstract now supplies the minimal context needed to assess the reported superiority. revision: yes
-
Referee: [Experiments] Experiments section (results description): It is not stated whether the 10 baseline methods received equivalent interaction budgets or stakeholder preference input. If baselines are non-interactive (standard for automated quantification), the reported gains may be attributable primarily to the progressive elicitation step rather than the retrieval-augmented preference modeling, directly threatening the central claim that IRAP's distinctive components drive the improvements.
Authors: We acknowledge that the original text did not explicitly address interaction budgets for the baselines. The ten baseline methods are non-interactive automated techniques, as is standard in the literature; they therefore received no interaction rounds or stakeholder preference input. IRAP's reported gains reflect the benefit of its integrated interactive retrieval-augmented elicitation under a strict budget of five rounds. To strengthen attribution, we have revised the Experiments section to state this distinction clearly and have added a short ablation analysis comparing IRAP variants with and without the retrieval component under identical interaction budgets. This revision clarifies that the distinctive retrieval-augmented modeling contributes measurable value beyond generic interaction. revision: yes
Circularity Check
No circularity; derivation relies on external retrieval and stakeholder input
full rationale
The paper formalizes the performance-requirements quantification problem as an independent challenge and introduces IRAP as a method that explicitly retrieves problem-specific knowledge and conducts progressive stakeholder interactions. No equations or steps reduce by construction to fitted parameters, self-definitions, or self-citation chains; the experimental comparisons are performed against external SOTA baselines on real-world datasets. The central claim therefore remains independent of its own outputs and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
Yulong Ye and Tao Chen and Miqing Li , title =. 47th. 2025 , url =. doi:10.1109/ICSE55347.2025.00094 , timestamp =
-
[8]
Youpeng Ma and Tao Chen and Ke Li , title =. 47th. 2025 , url =. doi:10.1109/ICSE55347.2025.00201 , timestamp =
-
[9]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[10]
ACM Transactions on Software Engineering and Methodology , year=
Causally Perturbed Fairness Testing , author=. ACM Transactions on Software Engineering and Methodology , year=
-
[11]
Tao Chen and Ke Li and Rami Bahsoon and Xin Yao , title =. 2018 , url =. doi:10.1145/3204459 , timestamp =
-
[12]
ACM Transactions on Software Engineering and Methodology , year=
Revealing Domain-Spatiality Patterns for Configuration Tuning: Domain Knowledge Meets Fitness Landscapes , author=. ACM Transactions on Software Engineering and Methodology , year=
-
[13]
Jingzhi Gong and Tao Chen and Rami Bahsoon , title =. 2025 , url =. doi:10.1109/TSE.2024.3491945 , timestamp =
-
[14]
Pengzhou Chen and Tao Chen and Miqing Li , title =. 2024 , url =. doi:10.1109/TSE.2024.3388910 , timestamp =
-
[15]
Jonas Eckhardt and Andreas Vogelsang and Henning Femmer and Philipp Mager , title =. 24th. 2016 , url =. doi:10.1109/RE.2016.24 , timestamp =
-
[16]
Mohammed Sayagh and Noureddine Kerzazi and Bram Adams and F. Software Configuration Engineering in Practice Interviews, Survey, and Systematic Literature Review , journal =. 2020 , url =. doi:10.1109/TSE.2018.2867847 , timestamp =
-
[17]
Tao Chen and Miqing Li , title =. 2023 , url =. doi:10.1145/3571853 , timestamp =
-
[18]
Requirements Engineering , volume=
An approach for performance requirements verification and test environments generation , author=. Requirements Engineering , volume=. 2023 , publisher=
2023
-
[19]
Pengzhou Chen and Tao Chen , title =. 48th
-
[20]
Gangda Xiong and Tao Chen , title =. 40th
-
[21]
Zezhen Xiang and Jingzhi Gong and Tao Chen , title =. 48th
-
[22]
Jonas Eckhardt and Andreas Vogelsang and Daniel M. Are "non-functional" requirements really non-functional?: an investigation of non-functional requirements in practice , booktitle =. 2016 , url =. doi:10.1145/2884781.2884788 , timestamp =
-
[23]
Jon Whittle and Peter Sawyer and Nelly Bencomo and Betty H. C. Cheng and Jean. Requir. Eng. , volume =. 2010 , url =. doi:10.1007/S00766-010-0101-0 , timestamp =
-
[24]
Luciano Baresi and Liliana Pasquale and Paola Spoletini , title =. 2010 , url =. doi:10.1109/RE.2010.25 , timestamp =
-
[25]
48th IEEE/ACM International Conference on Software Engineering , year =
Wang, Shihai and Chen, Tao , title=. 48th IEEE/ACM International Conference on Software Engineering , year =
-
[26]
Christiano and Jan Leike and Tom B
Paul F. Christiano and Jan Leike and Tom B. Brown and Miljan Martic and Shane Legg and Dario Amodei , editor =. Deep Reinforcement Learning from Human Preferences , booktitle =. 2017 , url =
2017
-
[27]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[28]
arXiv preprint arXiv:2306.07402 , year=
The economic trade-offs of large language models: A case study , author=. arXiv preprint arXiv:2306.07402 , year=
-
[29]
Improving Language Models by Retrieving from Trillions of Tokens , booktitle =
Sebastian Borgeaud and Arthur Mensch and Jordan Hoffmann and Trevor Cai and Eliza Rutherford and Katie Millican and George van den Driessche and Jean. Improving Language Models by Retrieving from Trillions of Tokens , booktitle =. 2022 , url =
2022
-
[30]
Atlas: Few-shot Learning with Retrieval Augmented Language Models , journal =
Gautier Izacard and Patrick Lewis and Maria Lomeli and Lucas Hosseini and Fabio Petroni and Timo Schick and Jane Dwivedi. Atlas: Few-shot Learning with Retrieval Augmented Language Models , journal =. 2023 , url =
2023
-
[31]
Manning and Stefano Ermon and Chelsea Finn , editor =
Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn , editor =. Direct Preference Optimization: Your Language Model is Secretly a Reward Model , booktitle =. 2023 , url =
2023
-
[32]
Proximal Policy Optimization Algorithms
John Schulman and Filip Wolski and Prafulla Dhariwal and Alec Radford and Oleg Klimov , title =. CoRR , volume =. 2017 , url =. 1707.06347 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[33]
Waad Alhoshan and Alessio Ferrari and Liping Zhao , title =. Inf. Softw. Technol. , volume =. 2023 , url =. doi:10.1016/J.INFSOF.2023.107202 , timestamp =
-
[34]
Tobias Hey and Jan Keim and Anne Koziolek and Walter F. Tichy , editor =. NoRBERT: Transfer Learning for Requirements Classification , booktitle =. 2020 , url =. doi:10.1109/RE48521.2020.00028 , timestamp =
-
[35]
Xianchang Luo and Yinxing Xue and Zhenchang Xing and Jiamou Sun , title =. 37th. 2022 , url =. doi:10.1145/3551349.3560417 , timestamp =
-
[36]
Gang Li and Chengpeng Zheng and Min Li and Haosen Wang , title =. 2022 , url =. doi:10.1109/ACCESS.2022.3159238 , timestamp =
-
[37]
Manal Binkhonain and Reem Alfayaz , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2509.13868 , eprinttype =. 2509.13868 , timestamp =
-
[38]
Personalized soups: Personalized large language model alignment via post-hoc parameter merging , author=. arXiv preprint arXiv:2310.11564 , year=
-
[39]
The Twelfth International Conference on Learning Representations,
Daixuan Cheng and Shaohan Huang and Furu Wei , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
2024
-
[40]
Retrieval-Augmented Generation for Knowledge-Intensive
Patrick Lewis and Ethan Perez and Aleksandra Piktus and Fabio Petroni and Vladimir Karpukhin and Naman Goyal and Heinrich K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual , year =
2020
-
[41]
URL https://aclanthology.org/2022.naacl-main
Ohad Rubin and Jonathan Herzig and Jonathan Berant , editor =. Learning To Retrieve Prompts for In-Context Learning , booktitle =. 2022 , url =. doi:10.18653/V1/2022.NAACL-MAIN.191 , timestamp =
-
[42]
Soviet physics-doklady , volume=
Binary coors capable or ‘correcting deletions, insertions, and reversals , author=. Soviet physics-doklady , volume=
-
[43]
Harold W. Kuhn , editor =. The Hungarian Method for the Assignment Problem , booktitle =. 2010 , url =. doi:10.1007/978-3-540-68279-0\_2 , timestamp =
-
[44]
Representation Learning with Contrastive Predictive Coding
A. Representation Learning with Contrastive Predictive Coding , journal =. 2018 , url =. 1807.03748 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu and Myle Ott and Naman Goyal and Jingfei Du and Mandar Joshi and Danqi Chen and Omer Levy and Mike Lewis and Luke Zettlemoyer and Veselin Stoyanov , title =. CoRR , volume =. 2019 , url =. 1907.11692 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[46]
2005 , note=
The PROMISE Repository of Software Engineering Databases , howpublished=. 2005 , note=
2005
-
[47]
Alessio Ferrari and Giorgio Oronzo Spagnolo and Stefania Gnesi , editor =. 25th. 2017 , url =. doi:10.1109/RE.2017.29 , timestamp =
-
[48]
Zain Shaukat Shaukat and Rashid Naseem and Muhammad Zubair , editor =. A Dataset for Software Requirements Risk Prediction , booktitle =. 2018 , url =. doi:10.1109/CSE.2018.00022 , timestamp =
-
[49]
Waad Alhoshan and Alessio Ferrari and Liping Zhao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.16768 , eprinttype =. 2504.16768 , timestamp =
-
[50]
Using an llm to help with code understanding,
Carmine Ferrara and Francesco Casillo and Carmine Gravino and Andrea De Lucia and Fabio Palomba , title =. Proceedings of the 46th. 2024 , url =. doi:10.1145/3597503.3639185 , timestamp =
-
[51]
ACM Transactions on Information Systems , volume=
An analysis of fusion functions for hybrid retrieval , author=. ACM Transactions on Information Systems , volume=. 2023 , publisher=
2023
-
[52]
Fei Wang and Xingchen Wan and Ruoxi Sun and Jiefeng Chen and Sercan. Astute. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers),. 2025 , url =
2025
-
[53]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
Wenxuan Zhou and Ravi Agrawal and Shujian Zhang and Sathish Reddy Indurthi and Sanqiang Zhao and Kaiqiang Song and Silei Xu and Chenguang Zhu , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,. 2024 , url =. doi:10.18653/V1/2024.EMNLP-MAIN.475 , timestamp =
-
[54]
Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen
Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen. LoRA: Low-Rank Adaptation of Large Language Models , booktitle =. 2022 , url =
2022
-
[55]
Joint Embedding of Words and Labels for Text Classification , booktitle =
Guoyin Wang and Chunyuan Li and Wenlin Wang and Yizhe Zhang and Dinghan Shen and Xinyuan Zhang and Ricardo Henao and Lawrence Carin , editor =. Joint Embedding of Words and Labels for Text Classification , booktitle =. 2018 , url =. doi:10.18653/V1/P18-1216 , timestamp =
-
[56]
Ke Ma and Tao Zhang and Hengyuan Zhang and Wu Huang , title =. Biomed. Signal Process. Control. , volume =. 2026 , url =. doi:10.1016/J.BSPC.2025.108420 , timestamp =
-
[57]
, author=
Analysis of multiple-choice versus open-ended questions in language tests according to different cognitive domain levels. , author=. Novitas-ROYAL (Research on Youth and Language) , volume=. 2020 , publisher=
2020
-
[58]
15th IEEE international requirements engineering conference (RE 2007) , pages=
On non-functional requirements , author=. 15th IEEE international requirements engineering conference (RE 2007) , pages=. 2007 , organization=
2007
-
[59]
2012 , publisher=
Non-functional requirements in software engineering , author=. 2012 , publisher=
2012
-
[60]
How much can rag help the reasoning of llm?arXiv preprint arXiv:2410.02338,
Jingyu Liu and Jiaen Lin and Yong Liu , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2410.02338 , eprinttype =. 2410.02338 , timestamp =
-
[61]
1981 , publisher=
Approximation theory and methods , author=. 1981 , publisher=
1981
-
[62]
Geoscientific model development , volume=
Root mean square error (RMSE) or mean absolute error (MAE)?--Arguments against avoiding RMSE in the literature , author=. Geoscientific model development , volume=. 2014 , publisher=
2014
-
[63]
Computing the Fr
Alt, Helmut and Godau, Michael , journal=. Computing the Fr. 1995 , publisher=
1995
-
[64]
Helmut Alt and Michael Godau , title =. Int. J. Comput. Geom. Appl. , volume =. 1995 , url =. doi:10.1142/S0218195995000064 , timestamp =
-
[65]
Hinton , title =
Ting Chen and Simon Kornblith and Mohammad Norouzi and Geoffrey E. Hinton , title =. Proceedings of the 37th International Conference on Machine Learning,. 2020 , url =
2020
-
[66]
Sebastian Bruch and Siyu Gai and Amir Ingber , title =. 2024 , url =. doi:10.1145/3596512 , timestamp =
-
[67]
Nixon and Eric Yu and John Mylopoulos , title =
Lawrence Chung and Brian A. Nixon and Eric Yu and John Mylopoulos , title =. 2000 , url =. doi:10.1007/978-1-4615-5269-7 , isbn =
-
[68]
Martin Glinz , title =. 15th. 2007 , url =. doi:10.1109/RE.2007.45 , timestamp =
-
[69]
arXiv preprint arXiv:2306.07402 , year=
Kristen Howell and Gwen Christian and Pavel Fomitchov and Gitit Kehat and Julianne Marzulla and Leanne Rolston and Jadin Tredup and Ilana Zimmerman and Ethan Selfridge and Joseph Bradley , title =. CoRR , volume =. 2023 , url =. doi:10.48550/ARXIV.2306.07402 , eprinttype =. 2306.07402 , timestamp =
-
[70]
Long Ouyang and Jeffrey Wu and Xu Jiang and Diogo Almeida and Carroll L. Wainwright and Pamela Mishkin and Chong Zhang and Sandhini Agarwal and Katarina Slama and Alex Ray and John Schulman and Jacob Hilton and Fraser Kelton and Luke Miller and Maddie Simens and Amanda Askell and Peter Welinder and Paul F. Christiano and Jan Leike and Ryan Lowe , editor =...
2022
-
[71]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[72]
Proceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE) , year =
Shihai Wang and Tao Chen , title =. Proceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE) , year =. doi:10.48550/ARXIV.2511.03421 , eprinttype =. 2511.03421 , note =
-
[73]
Gangda Xiong and Tao Chen , title =. Proceedings of the 40th IEEE/ACM International Conference on Automated Software Engineering (ASE) , year =. doi:10.48550/ARXIV.2509.24694 , eprinttype =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.