Recognition: unknown
Meta-CoT: Enhancing Granularity and Generalization in Image Editing
Pith reviewed 2026-05-08 04:26 UTC · model grok-4.3
The pith
Meta-CoT decomposes any image edit into a task-target-understanding triplet plus five meta-tasks to raise both granularity and generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
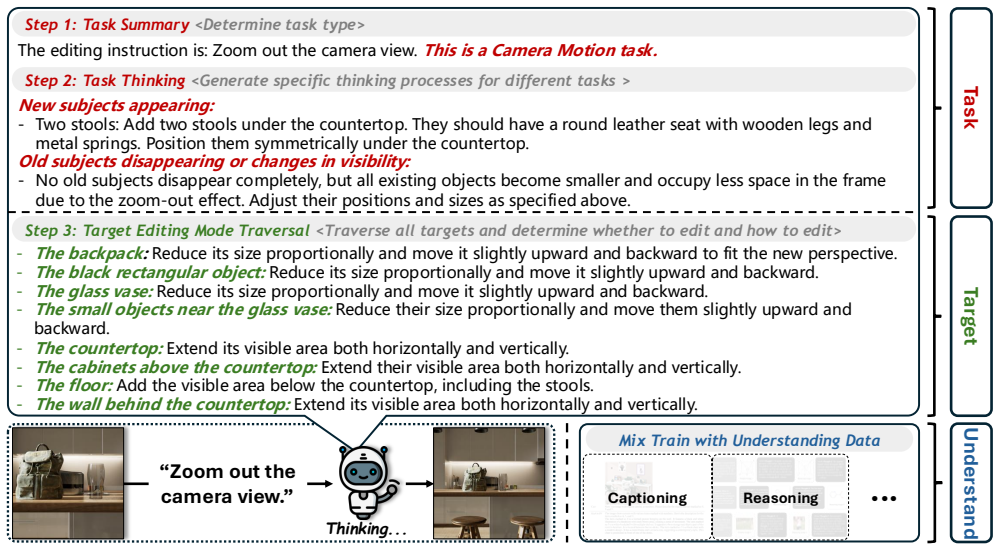
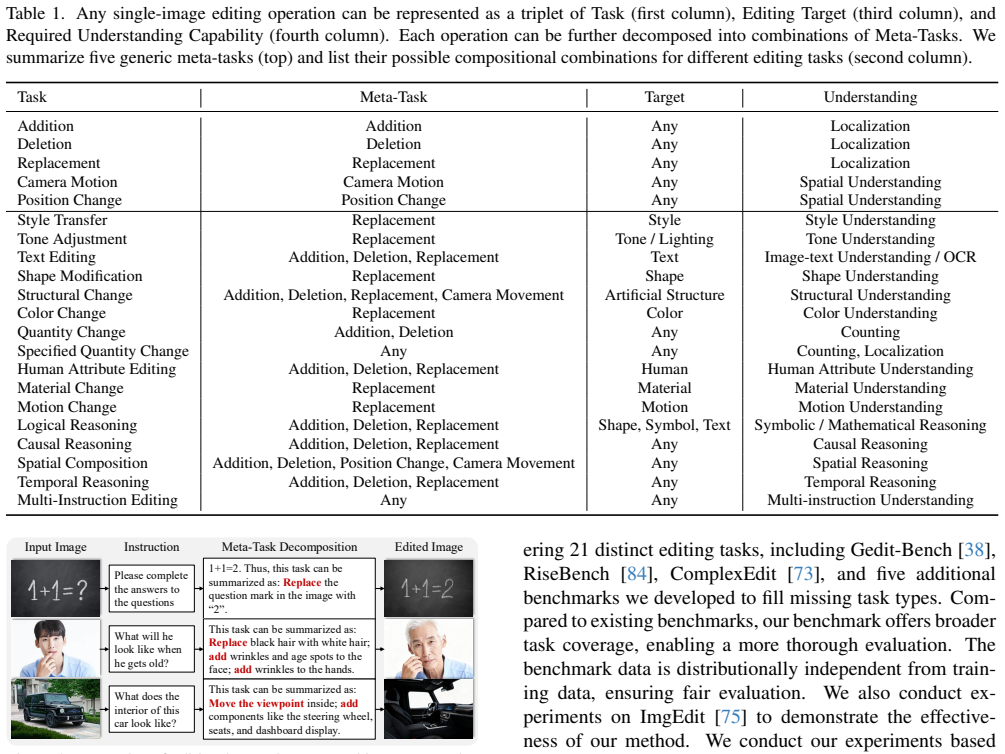
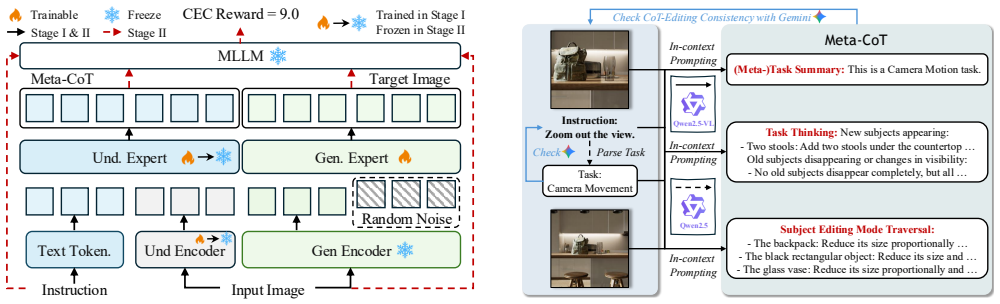
Meta-CoT performs a two-level decomposition of single-image editing. In the first level any editing intention is represented as the triplet (task, target, required understanding ability); task-specific CoT is generated and editing operations are traversed across all targets. In the second level editing tasks are further broken into five fundamental meta-tasks. Training on these five meta-tasks together with the other two triplet elements is stated to be sufficient for strong generalization to diverse unseen tasks. The CoT-Editing Consistency Reward is introduced to align editing behavior with the reasoning trace, producing an overall 15.8 percent improvement across 21 editing tasks.
What carries the argument
The Meta-CoT two-level decomposition that casts editing as the triplet (task, target, required understanding ability) and reduces tasks to five meta-tasks, together with the CoT-Editing Consistency Reward that enforces alignment between reasoning and output edits.
If this is right
- Training on the five meta-tasks together with the triplet elements is sufficient to generalize to diverse unseen editing tasks.
- The decomposition guides the model to learn each element of the triplet separately, raising understanding granularity.
- The consistency reward produces more accurate use of CoT information while performing the edit.
- An overall 15.8 percent improvement is obtained across 21 editing tasks.
Where Pith is reading between the lines
- The same decomposition pattern could be tested on other multi-modal generation tasks to reduce reliance on large task-specific datasets.
- Identifying a small universal set of meta-operations may prove useful for efficient fine-tuning across additional generative domains.
- The explicit triplet representation and reward may make model behavior more interpretable and easier to debug than standard CoT approaches.
Load-bearing premise
That every possible editing intention can be expressed as the specific triplet of task, target, and required understanding ability and that five meta-tasks are enough to generalize to all other edits.
What would settle it
A model trained only on the five meta-tasks performs no better than a baseline on a broad collection of complex unseen editing tasks that require different understanding abilities.
Figures


read the original abstract
Unified multi-modal understanding/generative models have shown improved image editing performance by incorporating fine-grained understanding into their Chain-of-Thought (CoT) process. However, a critical question remains underexplored: what forms of CoT and training strategy can jointly enhance both the understanding granularity and generalization? To address this, we propose Meta-CoT, a paradigm that performs a two-level decomposition of any single-image editing operation with two key properties: (1) Decomposability. We observe that any editing intention can be represented as a triplet - (task, target, required understanding ability). Inspired by this, Meta-CoT decomposes both the editing task and the target, generating task-specific CoT and traversing editing operations on all targets. This decomposition enhances the model's understanding granularity of editing operations and guides it to learn each element of the triplet during training, substantially improving the editing capability. (2) Generalizability. In the second decomposition level, we further break down editing tasks into five fundamental meta-tasks. We find that training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks. To further align the model's editing behavior with its CoT reasoning, we introduce the CoT-Editing Consistency Reward, which encourages more accurate and effective utilization of CoT information during editing. Experiments demonstrate that our method achieves an overall 15.8% improvement across 21 editing tasks, and generalizes effectively to unseen editing tasks when trained on only a small set of meta-tasks. Our code, benchmark, and model are released at https://shiyi-zh0408.github.io/projectpages/Meta-CoT/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Meta-CoT, a paradigm for image editing in unified multi-modal models that performs a two-level decomposition of editing operations. Any single-image editing intention is represented as the triplet (task, target, required understanding ability); the first level decomposes the task and target to produce task-specific CoT while traversing operations on all targets, and the second level further reduces editing tasks to five fundamental meta-tasks. Training on these meta-tasks plus the triplet elements, combined with a new CoT-Editing Consistency Reward, is claimed to improve understanding granularity and yield strong generalization. Experiments report an overall 15.8% improvement across 21 editing tasks and effective generalization to unseen tasks when trained on only the small meta-task set.
Significance. If the empirical claims hold, the work would be significant for the field by offering a structured, meta-task-based training strategy that jointly targets finer-grained CoT reasoning and broader generalization in image editing, potentially reducing reliance on large task-specific datasets. The public release of code, benchmark, and model is a clear strength that supports reproducibility.
major comments (2)
- [Abstract] Abstract (Generalizability paragraph): the central claim that 'training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks' is load-bearing yet lacks either a coverage argument or explicit out-of-distribution tests. If the 21 evaluated tasks are largely recombinations of the five meta-tasks, the reported generalization may not extend to edits requiring novel understanding abilities.
- [Experiments] Experiments section: the 15.8% overall improvement is presented without reference to the precise baselines, evaluation metrics, statistical significance tests, or train/test splits used for the 21 tasks. This information is required to assess whether the gains are robust and attributable to the proposed decomposition and reward.
minor comments (2)
- [Introduction] The triplet definition and its mapping to concrete editing examples could be illustrated earlier (e.g., in the introduction or method overview) to improve readability for readers unfamiliar with the decomposition.
- [Figures] Figure captions describing the two-level decomposition process should explicitly label the five meta-tasks and the CoT-Editing Consistency Reward to make the pipeline self-contained.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications and note the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract (Generalizability paragraph): the central claim that 'training on these five meta-tasks, together with the other two elements of the triplet, is sufficient to achieve strong generalization across diverse, unseen editing tasks' is load-bearing yet lacks either a coverage argument or explicit out-of-distribution tests. If the 21 evaluated tasks are largely recombinations of the five meta-tasks, the reported generalization may not extend to edits requiring novel understanding abilities.
Authors: We acknowledge the referee's point that the generalizability claim in the abstract would be strengthened by additional supporting arguments. The manuscript provides empirical support via experiments showing effective generalization to unseen tasks when trained only on the meta-task set. To directly address the concern, we will revise the abstract and the Generalizability section to include a concise coverage argument detailing how the five meta-tasks span the core understanding abilities, and we will clarify the out-of-distribution aspects of the 21 tasks (which include novel combinations beyond simple recombinations of meta-tasks). revision: partial
-
Referee: [Experiments] Experiments section: the 15.8% overall improvement is presented without reference to the precise baselines, evaluation metrics, statistical significance tests, or train/test splits used for the 21 tasks. This information is required to assess whether the gains are robust and attributable to the proposed decomposition and reward.
Authors: We agree that explicit details on baselines, metrics, statistical tests, and splits are necessary for proper assessment of the results. We will revise the Experiments section to prominently reference these elements alongside the 15.8% figure, including the specific baselines (standard unified multi-modal models), evaluation metrics, any significance testing performed, and the train/test splits for the 21 tasks. This will make the attribution to the proposed decomposition and reward clearer. revision: yes
Circularity Check
No circularity: empirical training paradigm with no derivation reducing to inputs
full rationale
The paper proposes Meta-CoT as an empirical method: it states an observation that editing intentions decompose into a (task, target, required understanding ability) triplet, breaks tasks into five meta-tasks, and reports that training on them plus the triplet elements yields generalization, validated by 15.8% gains on 21 tasks. No equations, fitted parameters called predictions, or first-principles derivations appear in the provided text. Claims rest on experimental results rather than any chain that reduces by construction to the inputs or self-citations. The approach is therefore self-contained as a training strategy.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023. 4
work page internal anchor Pith review arXiv 2023
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review arXiv 2025
-
[3]
In- structpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. In- structpix2pix: Learning to follow image editing instructions. InCVPR, pages 18392–18402, 2023. 6
2023
-
[4]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Sil- vio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025. 4
work page Pith review arXiv 2025
-
[5]
Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
Jiuhai Chen, Le Xue, Zhiyang Xu, Xichen Pan, Shusheng Yang, Can Qin, An Yan, Honglu Zhou, Zeyuan Chen, Lifu Huang, et al. Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025. 6
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Chengyue Wu, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, and Ping Luo. Janus-pro: Unified mul- timodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[7]
Wenxun Dai, Zhiyuan Zhao, Yule Zhong, Yiji Cheng, Jian- wei Zhang, Linqing Wang, Shiyi Zhang, Yunlong Lin, Runze He, Fellix Song, et al. Chatumm: Robust context track- ing for conversational interleaved generation.arXiv preprint arXiv:2602.06442, 2026. 4
-
[8]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 2, 3, 4, 6
work page internal anchor Pith review arXiv 2025
-
[9]
Dreamllm: Synergistic multimodal com- prehension and creation
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, et al. Dreamllm: Synergistic multimodal com- prehension and creation. InICLR, 2024. 4
2024
-
[10]
GoT-R1: Unleashing Reasoning Capability of MLLM for Visual Generation with Reinforcement Learning
Chengqi Duan, Rongyao Fang, Yuqing Wang, Kun Wang, Linjiang Huang, Xingyu Zeng, Hongsheng Li, and Xihui Liu. Got-r1: Unleashing reasoning capability of mllm for vi- sual generation with reinforcement learning.arXiv preprint arXiv:2505.17022, 2025. 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, et al. Got: Unleashing reasoning capability of multimodal large language model for visual generation and editing.arXiv preprint arXiv:2503.10639, 2025. 2, 4, 6
-
[12]
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Cor- ring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Floren- cio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding.arXiv preprint arXiv:2501.05452, 2025. 4
-
[13]
Jarvis Guo, Tuney Zheng, Yuelin Bai, Bo Li, Yubo Wang, King Zhu, Yizhi Li, Graham Neubig, Wenhu Chen, and Xi- ang Yue. Mammoth-vl: Eliciting multimodal reasoning with instruction tuning at scale.arXiv preprint arXiv:2412.05237,
-
[14]
Visual program- ming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual program- ming: Compositional visual reasoning without training. In CVPR, pages 14953–14962, 2023. 4
2023
-
[15]
Feng Han, Yang Jiao, Shaoxiang Chen, Junhao Xu, Jingjing Chen, and Yu-Gang Jiang. Controlthinker: Unveiling latent semantics for controllable image generation through visual reasoning.arXiv preprint arXiv:2506.03596, 2025. 4
-
[16]
Freeedit: Mask-free reference-based image editing with multi-modal instruction.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 2025
Runze He, Kai Ma, Linjiang Huang, Shaofei Huang, Jialin Gao, Xiaoming Wei, Jiao Dai, Jizhong Han, and Si Liu. Freeedit: Mask-free reference-based image editing with multi-modal instruction.IEEE Transactions on Pattern Anal- ysis and Machine Intelligence, 2025. 4
2025
-
[17]
Runze He, Yiji Cheng, Tiankai Hang, Zhimin Li, Yu Xu, Zijin Yin, Shiyi Zhang, Wenxun Dai, Penghui Du, Ao Ma, et al. Re-align: Structured reasoning-guided alignment for in-context image generation and editing.arXiv preprint arXiv:2601.05124, 2026. 4
-
[18]
Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.NeurIPS, 37:139348–139379,
Yushi Hu, Weijia Shi, Xingyu Fu, Dan Roth, Mari Osten- dorf, Luke Zettlemoyer, Noah A Smith, and Ranjay Krishna. Visual sketchpad: Sketching as a visual chain of thought for multimodal language models.NeurIPS, 37:139348–139379,
-
[19]
Image editing as programs with diffusion models.arXiv preprint arXiv:2506.04158, 2025
Yujia Hu, Songhua Liu, Zhenxiong Tan, Xingyi Yang, and Xinchao Wang. Image editing as programs with diffusion models.arXiv preprint arXiv:2506.04158, 2025. 6
- [20]
-
[21]
Interleaving reasoning for better text-to-image generation
Wenxuan Huang, Shuang Chen, Zheyong Xie, Shaosheng Cao, Shixiang Tang, Yufan Shen, Qingyu Yin, Wenbo Hu, Xiaoman Wang, Yuntian Tang, et al. Interleaving rea- soning for better text-to-image generation.arXiv preprint arXiv:2509.06945, 2025. 4
-
[22]
Ming-univision: Joint image under- standing and generation with a unified continuous tokenizer
Ziyuan Huang, DanDan Zheng, Cheng Zou, Rui Liu, Xiao- long Wang, Kaixiang Ji, Weilong Chai, Jianxin Sun, Libin Wang, Yongjie Lv, et al. Ming-univision: Joint image under- standing and generation with a unified continuous tokenizer. arXiv preprint arXiv:2510.06590, 2025. 4, 6
-
[23]
Dongzhi Jiang, Ziyu Guo, Renrui Zhang, Zhuofan Zong, Hao Li, Le Zhuo, Shilin Yan, Pheng-Ann Heng, and Hong- sheng Li. T2i-r1: Reinforcing image generation with col- laborative semantic-level and token-level cot.arXiv preprint arXiv:2505.00703, 2025. 4
-
[24]
Ivan Krasin, Tom Duerig, Neil Alldrin, Andreas Veit, Sami Abu-El-Haija, Serge Belongie, David Cai, Zheyun Feng, Vittorio Ferrari, Victor Gomes, Abhinav Gupta, Chen Sun, Gal Chechik, Kevin Murphy, Dhyanesh Narayanan, Saurabh Shetty, Yang Song, Joseph Tighe, Andrea Vedaldi, Sudheendra Vijayanarasimhan, and Oriol Vinyals. Open- images: A public dataset for l...
2017
-
[25]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation.arXiv preprint arXiv:2312.14867, 2023. 5, 6
-
[26]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742,
work page internal anchor Pith review arXiv
-
[27]
Prometheus-vision: Vision-language model as a judge for fine-grained evaluation
Seongyun Lee, Seungone Kim, Sue Park, Geewook Kim, and Minjoon Seo. Prometheus-vision: Vision-language model as a judge for fine-grained evaluation. InFindings of the association for computational linguistics ACL 2024, pages 11286–11315, 2024. 5
2024
-
[28]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 6
work page internal anchor Pith review arXiv 2024
-
[29]
Chengzu Li, Wenshan Wu, Huanyu Zhang, Yan Xia, Shaoguang Mao, Li Dong, Ivan Vuli´c, and Furu Wei. Imag- ine while reasoning in space: Multimodal visualization-of- thought.arXiv preprint arXiv:2501.07542, 2025. 4
-
[30]
Lingen Li, Guangzhi Wang, Zhaoyang Zhang, Yaowei Li, Xiaoyu Li, Qi Dou, Jinwei Gu, Tianfan Xue, and Ying Shan. Tooncomposer: Streamlining cartoon production with gen- erative post-keyframing.arXiv preprint arXiv:2508.10881,
-
[31]
Nvcomposer: Boosting generative novel view synthesis with multiple sparse and unposed images
Lingen Li, Zhaoyang Zhang, Yaowei Li, Jiale Xu, Wenbo Hu, Xiaoyu Li, Weihao Cheng, Jinwei Gu, Tianfan Xue, and Ying Shan. Nvcomposer: Boosting generative novel view synthesis with multiple sparse and unposed images. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 777–787, 2025. 4
2025
-
[32]
arXiv preprint arXiv:2411.04996 , year =
Weixin Liang, Lili Yu, Liang Luo, Srinivasan Iyer, Ning Dong, Chunting Zhou, Gargi Ghosh, Mike Lewis, Wen-tau Yih, Luke Zettlemoyer, et al. Mixture-of-transformers: A sparse and scalable architecture for multi-modal foundation models.arXiv preprint arXiv:2411.04996, 2024. 4
-
[33]
Chao Liao, Liyang Liu, Xun Wang, Zhengxiong Luo, Xinyu Zhang, Wenliang Zhao, Jie Wu, Liang Li, Zhi Tian, and Weilin Huang. Mogao: An omni foundation model for interleaved multi-modal generation.arXiv preprint arXiv:2505.05472, 2025. 4
-
[34]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld-v1: High-resolution seman- tic encoders for unified visual understanding and generation. arXiv preprint arXiv:2506.03147, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[35]
Jarvisart: Liberating human artistic creativity via an intelligent photo retouching agent
Yunlong Lin, Zixu Lin, Kunjie Lin, Jinbin Bai, Panwang Pan, Chenxin Li, Haoyu Chen, Zhongdao Wang, Xinghao Ding, Wenbo Li, et al. Jarvisart: Liberating human artistic creativ- ity via an intelligent photo retouching agent.arXiv preprint arXiv:2506.17612, 2025. 4
-
[36]
Yunlong Lin, Linqing Wang, Kunjie Lin, Zixu Lin, Kaixiong Gong, Wenbo Li, Bin Lin, Zhenxi Li, Shiyi Zhang, Yuyang Peng, et al. Jarvisevo: Towards a self-evolving photo editing agent with synergistic editor-evaluator optimization.arXiv preprint arXiv:2511.23002, 2025. 4
-
[37]
Flow-GRPO: Training Flow Matching Models via Online RL
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via on- line rl.arXiv preprint arXiv:2505.05470, 2025. 3, 5
work page internal anchor Pith review arXiv 2025
-
[38]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chun- rui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025. 3, 5, 6
work page internal anchor Pith review arXiv 2025
-
[39]
Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action
Jiasen Lu, Christopher Clark, Sangho Lee, Zichen Zhang, Savya Khosla, Ryan Marten, Derek Hoiem, and Aniruddha Kembhavi. Unified-io 2: Scaling autoregressive multimodal models with vision language audio and action. InCVPR, pages 26439–26455, 2024. 4
2024
-
[40]
Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS, 35: 2507–2521, 2022
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. Learn to explain: Multimodal reasoning via thought chains for science question answering.NeurIPS, 35: 2507–2521, 2022. 4
2022
-
[41]
Follow your pose: Pose- guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Siran Chen, Xiu Li, and Qifeng Chen. Follow your pose: Pose- guided text-to-video generation using pose-free videos. In Proceedings of the AAAI Conference on Artificial Intelli- gence, pages 4117–4125, 2024. 4
2024
-
[42]
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, Liang Zhao, Yisong Wang, Jiaying Liu, and Chong Ruan. Janusflow: Harmonizing autoregression and rectified flow for unified multimodal understanding and generation.arXiv preprint arXiv:2411.07975, 2024. 4
-
[43]
Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026
Yue Ma, Zhikai Wang, Tianhao Ren, Mingzhe Zheng, Hongyu Liu, Jiayi Guo, Mark Fong, Yuxuan Xue, Zixi- ang Zhao, Konrad Schindler, et al. Fastvmt: Eliminat- ing redundancy in video motion transfer.arXiv preprint arXiv:2602.05551, 2026. 4
-
[44]
Gpt-image-1, 2025
OpenAI. Gpt-image-1, 2025. 6
2025
-
[45]
Introducing 4o image generation, 2025
OpenAI. Introducing 4o image generation, 2025. 4
2025
-
[46]
Transfer between Modalities with MetaQueries
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Ji- uhai Chen, Kunpeng Li, Felix Juefei-Xu, Ji Hou, and Saining Xie. Transfer between modalities with metaqueries.arXiv preprint arXiv:2504.06256, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[47]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 4195–4205,
-
[48]
Du, Zehuan Yuan, and Xinglong Wu
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K Du, Zehuan Yuan, and Xinglong Wu. Tokenflow: Unified image tokenizer for multimodal understanding and generation.arXiv preprint arXiv:2412.03069, 2024. 4
-
[49]
Laion-5b: An open large-scale dataset for train- ing next generation image-text models.NeurIPS, 35:25278– 25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Worts- man, et al. Laion-5b: An open large-scale dataset for train- ing next generation image-text models.NeurIPS, 35:25278– 25294, 2022. 6
2022
-
[50]
Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehen- sive dataset and benchmark for chain-of-thought reasoning. NeurIPS, 37:8612–8642, 2024. 4
2024
-
[51]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathe- matical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[52]
Weijia Shi, Xiaochuang Han, Chunting Zhou, Weixin Liang, Xi Victoria Lin, Luke Zettlemoyer, and Lili Yu. Llamafu- sion: Adapting pretrained language models for multimodal generation.arXiv preprint arXiv:2412.15188, 2024. 4
-
[53]
Emu: Generative pretraining in multimodality
Quan Sun, Qiying Yu, Yufeng Cui, Fan Zhang, Xiaosong Zhang, Yueze Wang, Hongcheng Gao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Emu: Generative pretraining in multimodality. InICLR, 2024. 4
2024
-
[54]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[55]
On the estimation of relationships involving qualitative variables.American Journal of Sociology, 76(1): 103–154, 1970
Henri Theil. On the estimation of relationships involving qualitative variables.American Journal of Sociology, 76(1): 103–154, 1970. 4
1970
-
[56]
Shengbang Tong, David Fan, Jiachen Zhu, Yunyang Xiong, Xinlei Chen, Koustuv Sinha, Michael Rabbat, Yann LeCun, Saining Xie, and Zhuang Liu. Metamorph: Multimodal understanding and generation via instruction tuning.arXiv preprint arXiv:2412.14164, 2024. 4
-
[57]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reason- ing in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review arXiv
-
[58]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arxiv:2409.18869, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[59]
Chain-of-thought prompting elicits reasoning in large lan- guage models.NeurIPS, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large lan- guage models.NeurIPS, 35:24824–24837, 2022. 4
2022
-
[60]
Janus: Decoupling visual encod- ing for unified multimodal understanding and generation
Chengyue Wu, Xiaokang Chen, Zhiyu Wu, Yiyang Ma, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, Chong Ruan, et al. Janus: Decoupling visual encod- ing for unified multimodal understanding and generation. In CVPR, pages 12966–12977, 2025. 4
2025
-
[61]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025. 6
work page internal anchor Pith review arXiv 2025
-
[62]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
V?: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V?: Guided visual search as a core mechanism in multimodal llms. InCVPR, pages 13084–13094, 2024. 4
2024
-
[64]
Next-gpt: Any-to-any multimodal llm
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. InForty-first ICML, 2024. 4
2024
-
[65]
Omnigen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image genera- tion. InCVPR, pages 13294–13304, 2025. 6
2025
-
[66]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 4
work page internal anchor Pith review arXiv 2024
-
[67]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show- o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[68]
Yu Xu, Fan Tang, Juan Cao, Yuxin Zhang, Xiaoyu Kong, Jintao Li, Oliver Deussen, and Tong-Yee Lee. Head- router: A training-free image editing framework for mm- dits by adaptively routing attention heads.arXiv preprint arXiv:2411.15034, 2024. 4
-
[69]
Yu Xu, Hongbin Yan, Juan Cao, Yiji Cheng, Tiankai Hang, Runze He, Zijin Yin, Shiyi Zhang, Yuxin Zhang, Jintao Li, et al. Tag-moe: Task-aware gating for unified generative mixture-of-experts.arXiv preprint arXiv:2601.08881, 2026. 4
-
[70]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review arXiv 2024
-
[71]
Uni-paint: A unified framework for multimodal image inpainting with pretrained diffusion model
Shiyuan Yang, Xiaodong Chen, and Jing Liao. Uni-paint: A unified framework for multimodal image inpainting with pretrained diffusion model. InProceedings of the 31st ACM International Conference on Multimedia, pages 3190–3199,
-
[72]
Direct-a-video: Customized video generation with user- directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user- directed camera movement and object motion. InACM SIG- GRAPH 2024 Conference Papers, pages 1–12, 2024. 4
2024
-
[73]
arXiv preprint arXiv:2504.13143 (2025)
Siwei Yang, Mude Hui, Bingchen Zhao, Yuyin Zhou, Nataniel Ruiz, and Cihang Xie. Complex-edit: Cot-like in- struction generation for complexity-controllable image edit- ing benchmark.arXiv preprint arXiv:2504.13143, 2025. 3, 6
-
[74]
Multimodal rewardbench: Holistic evalu- ation of reward models for vision language models.URL https://api
Michihiro Yasunaga, Luke Zettlemoyer, and Marjan Ghazvininejad. Multimodal rewardbench: Holistic evalu- ation of reward models for vision language models.URL https://api. semanticscholar. org/CorpusID, 276482127,
-
[75]
ImgEdit: A Unified Image Editing Dataset and Benchmark
Yang Ye, Xianyi He, Zongjian Li, Bin Lin, Shenghai Yuan, Zhiyuan Yan, Bohan Hou, and Li Yuan. Imgedit: A uni- fied image editing dataset and benchmark.arXiv preprint arXiv:2505.20275, 2025. 3, 6
work page internal anchor Pith review arXiv 2025
-
[76]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InCVPR, pages 26125–26135, 2025. 6
2025
-
[77]
Magicbrush: A manually annotated dataset for instruction- guided image editing.NeurIPS, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction- guided image editing.NeurIPS, 36:31428–31449, 2023. 6
2023
-
[78]
Logo: A long-form video dataset for group action quality assessment
Shiyi Zhang, Wenxun Dai, Sujia Wang, Xiangwei Shen, Ji- wen Lu, Jie Zhou, and Yansong Tang. Logo: A long-form video dataset for group action quality assessment. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2405–2414, 2023. 4
2023
-
[79]
Narrative action evaluation with prompt-guided multimodal interaction
Shiyi Zhang, Sule Bai, Guangyi Chen, Lei Chen, Jiwen Lu, Junle Wang, and Yansong Tang. Narrative action evaluation with prompt-guided multimodal interaction. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18430–18439, 2024. 4
2024
-
[80]
Flexiact: Towards flexible action control in heterogeneous scenarios
Shiyi Zhang, Junhao Zhuang, Zhaoyang Zhang, Ying Shan, and Yansong Tang. Flexiact: Towards flexible action control in heterogeneous scenarios. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–11, 2025. 4
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.